半导体装置的制作方法
1.本发明涉及一种半导体装置,例如,涉及一种用于执行神经网络的处理的半导体装置。
背景技术:
2.公开了以下列出的技术。
3.[专利文献1]日本未审查专利申请公开号2019-40403。
[0004]
专利文献1公开了一种具有卷积运算处理电路的图像识别设备,卷积运算处理电路用于使用积分系数表进行运算,以便减少cnn(卷积神经网络)中卷积运算的计算量。积分系数表保持n
×
n的数据,并且n
×
n数据中的每个数据由系数和通道号组成。卷积运算处理电路包括乘积计算电路,乘积计算电路用于并行执行n
×
n的输入图像与系数的乘积运算,关于乘积运算结果对每个通道号进行累计加法运算,以及通道选择电路,通道选择电路用于针对每个通道号将加法运算结果存储在输出寄存器中。
技术实现要素:
[0005]
例如,在cnn等神经网络的处理中,将存储在存储器中的图像数据和加权因子数据传输到多个累加器时,期望使用直接存储器访问(dma)控制器来实现高速。另一方面,特别地,加权因子数据的数据量可以非常大。因此,可设想一种方法,其中存储先前压缩在存储器上的加权因子数据,并且其通过解压缩器恢复为未压缩的加权因子数据,然后传送到多个累加器。
[0006]
在这种情况下,作为配置解压缩器的方法,考虑配置在存储器和dma控制器之间的方法、或者配置在dma控制器和多个累加器之间的方法。在前一种方法中,担心不可能充分有效地利用多个累加器。在后一种方法中,由于需要为多个累加器中的每个累加器设置压缩器,因此存在电路面积和功耗增加的可能性。
[0007]
根据本说明书和附图的描述,其他目的和新颖特征将变得清楚。
[0008]
因此,一个实施例的半导体装置用于执行神经网络的处理,并且具有一个或多个存储器、解压缩单元、第一dma控制器、累加器单元以及第一开关电路。一个或多个存储器保持多个像素值和j个压缩的加权因子。解压缩器将j个压缩的加权因子恢复为k(k≥j)个未压缩的加权因子。第一dma控制器从存储器中读取j个压缩的加权因子并将它们传送到解压缩器。累加器单元具有n(n>k)个累加器,其将多个像素值和k个未压缩的加权因子相乘,并将相乘的结果累积地添加到时间序列中。设置在解压缩器和累加器单元之间的第一开关电路基于由第一标识符表示的对应关系来将由解压缩器恢复的k个未压缩的加权因子传送到n个累加器。
[0009]
通过使用一个实施例的半导体装置,可以实现电路面积的减少。
附图说明
[0010]
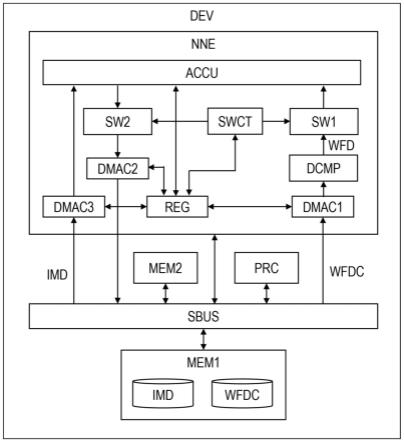
图1是示出根据本发明的第一实施例的半导体装置的主要部分的配置示例的示意图。
[0011]
图2是示出图1中的神经网络引擎的详细配置示例的图。
[0012]
图3是示出图2中的解压缩器周围的运算示例的图。
[0013]
图4是示出图2中的开关电路周围的配置示例的图。
[0014]
图5是示出cnn中所包括的卷积层中的处理内容的示例的示意图。
[0015]
图6是示出图2的神经网络引擎执行图5的处理时的运算示例的示意图。
[0016]
图7是示出在图1和图2的半导体装置中抽取出一部分的配置示例的示意图。
[0017]
图8是示出根据本发明的第二实施例的半导体装置中的神经网络引擎周围一部分的配置示例的示意图。
[0018]
图9是示出根据本发明的第三实施例的半导体装置中的神经网络引擎的一部分的配置示例的示意图。
[0019]
图10是示出根据本发明的第四实施例的半导体装置中的神经网络引擎的详细配置的图。
[0020]
图11是示出用作本发明的可比较示例的半导体装置的配置示例的示意图。
[0021]
图12是示出用作本发明的可比较示例的半导体装置的配置示例的示意图。
具体实施方式
[0022]
在以下各实施例中,为方便起见,将通过分为多个部分或实施例进行描述,但除特别指示外,它们不彼此独立,一个部分与其他部分或全部的修改示例、细节、补充描述等有关。在以下各实施例中,元素数量等(包括元素数量、数值、数量、范围等)不限于具体数量,但可以不小于或等于具体数量,除非特别指示数量并原则上明确限定于特定数量。此外,在以下各实施例中,不言而喻,构成元素(包括元素步骤等)不一定是必要的,除非在它们被具体指定的情况和原则上它们被认为是明显必要的情况下。类似地,在以下各实施例中,当提及部件等的形状、位置关系等时,假定该形状等与该形状等基本近似或相似,具体指定的情况和原则上认为是明显的情况等除外。这同样适用于上述数值和范围。
[0023]
在用于解释各实施例的所有附图中,具有相同功能的构件用相同的附图标记表示,并且省略对其的重复描述。在以下各实施例中,除特别需要外,原则上不再重复相同或相似部分的说明。
[0024]
(第一实施例)
[0025]
(半导体装置的示意图)
[0026]
图1是示出根据本发明的第一实施例的半导体装置的主要部分的配置示例的示意图。图1所示的半导体装置dev例如是由一个半导体芯片等构成的片上系统(soc)。这种半导体装置dev通常被安装在交通工具的ecu(车辆的电子控制单元)等之上,以提供adas(高级驾驶员辅助系统)的功能。
[0027]
图1所示的半导体装置dev具有神经网络引擎nne、诸如中央处理单元(cpu)的处理器prc、一个或多个存储器mem1和mem2、以及系统总线sbus。神经网络引擎nne执行由cnn表示的神经网络的处理。存储器mem1是动态随机存取存储器(dram)等,并且存储器mem2是用
于高速缓存等的静态随机存取存储器(sram)。系统总线sbus将神经网络引擎nne、存储器mem1、mem2和处理器prc彼此连接。
[0028]
存储器mem1保持包括多个像素值的图像数据imd和压缩权重因子数据wfdc。这里,权重因子数据中的数据量可以非常大。因此,未压缩的加权因子数据wfd在被转换为使用压缩软件等预先压缩的加权因子数据wfdc之后被存储在存储器mem1中。存储器mem2用作神经网络引擎nne的高速缓存存储器。例如,存储器mem1中的图像数据imd被预先复制到存储器mem2中。
[0029]
神经网络引擎nne包括多个dma控制器dmac1-dmac3、寄存器reg、解压缩器dcmp、多个开关电路sw1和sw2、开关控制电路swct和累加器单元accu。dma控制器dmac1从存储器mem1中读取压缩的加权因子数据wfdc,并将其传送到解压缩器dcmp。解压缩器dcmp将压缩的加权因子数据wfdc恢复为未压缩的加权因子数据wfds。
[0030]
在解压缩器dcmp和累加器单元accu之间设置开关电路sw1。尽管稍后将详细描述,开关电路sw1基于预定的对应关系,将包含在由解压缩器dcmp恢复的未压缩的加权因子数据wfd中的多个加权因子在累加器单元accu中传送到多个累加器。dma控制器dmac3从存储器mem2中读取图像数据imd并将其传送到累加器单元accu。
[0031]
累加器单元accu包括用于执行乘积和运算的多个累加器、乘积和运算以及来自图像数据imd的未压缩的加权因子数据wfd和来自dma控制器dmac3的开关电路sw1。在累加器单元accu和dma控制器dmac2之间设置开关电路sw2。开关电路sw2将在后面详细描述,基于预定的对应关系,并且将来自累加器单元accu中的多个累加器的输出传送到dma控制器dmac2中的多个通道。
[0032]
开关控制电路swct基于寄存器reg中存储的设定数据,控制开关电路sw1、sw2。具体地,开关控制电路swct控制上述各开关电路sw1、sw2的对应关系。寄存器reg还存储dma控制器dmac1至dmac3的地址范围的设定数据、累加器单元accu的设定数据等。
[0033]
(神经网络引擎的细节)
[0034]
图2是示出图1中的神经网络引擎的详细配置示例的图。图3是示出图2中的解压缩器周围的运算示例的图。图4是示出图2中的开关电路周围的配置示例的图。在图2中,dma控制器dmac1基于预设的读取地址范围,在每个控制周期从存储器mem1中读取如图3所示的加权因子数据集wfds。即,图1的存储器mem1在读取地址范围的每个地址处预先保持如图3所示的加权因子数据集wfds。
[0035]
图3所示的加权因子数据集wfds包括压缩的加权因子数据wfdc和报头hd。加权因子数据wfds包括j个压缩的加权因子p(1)-p(j)和映射数据mpd。报头hd包含两个未压缩的标识符id1和id2。作为示例,权重因子p(1)到p(j)由8位组成,并且“j”为11。映射数据mpd由28位组成。两个标识符id1和id2中的每一个都由6位组成。在这种情况下,加权因子数据集wfds由128位组成。
[0036]
dma控制器dmac1将包含在加权因子数据集wfds中的压缩的加权因子数据wfdc,即映射数据mpd和j个压缩的加权因子p(1)-p(j)传送到解压缩器dcmp,如图2和图3所示。此外,如图2所示,报头hd,即包括在加权因子数据集wfds中的标识符id1和id2被存储在寄存器reg中。
[0037]
解压缩器dcmp将压缩的加权因子数据wfdc恢复为未压缩的加权因子数据wfds,如
图2和图3所示。具体地,加权因子数据wfdc例如是使用零行程长度方法等的压缩数据。解压缩器dcmp基于由映射数据mpd表示的非零系数的位置,将压缩的j个加权因子p(1)-p(j)恢复为k(k≥j)个未压缩的加权因子w(1)-w(k)。作为示例,加权因子w(1)-w(k)中的每一个由8位组成,并且“k”最多为28等。
[0038]
在图2中,开关控制电路swct基于存储在寄存器reg中的报头hd,控制开关电路sw1和sw2。具体地,开关控制电路swct基于包括在图3的加权因子数据集wfds中的标识符id1生成开关控制信号ss1,并且使用开关控制信号ss1控制开关电路sw1的对应关系。类似地,开关控制电路swct基于包括在加权因子数据集wfds中的标识符id2生成开关控制信号ss2,并且使用开关控制信号ss2控制开关电路sw2的对应关系。
[0039]
如图2和图4所示,在解压缩器dcmp和包括在累加器单元中的n(n》k)个累加器acc(1)-acc(n)之间设置了开关电路sw1。开关电路sw1,基于开关控制信号ss1,因此识别id1所表示的对应关系,并且将解压缩器dcmp恢复的k个未压缩的加权因子w(1)-w(k)传送到n个累加器acc(1)-acc(n)。
[0040]
开关电路sw1例如是如图4所示的交叉开关等,包括“k
×
n”个开关s(1,1)-s(k,n)。开关s(1,1)-s(k,n)分别被设置在k条布线lnd(1)-lnd(k)和n条布线lna(1)-lna(n)的交叉点处。k条布线lnd(1)-lnd(k)分别从解压缩器dcmp传送k个加权因子w(1)-w(k)。n条布线lna(1)-lna(n)分别被连接到n个累加器acc(1)-acc(n)。
[0041]
开关控制电路swct针对标识符id1的每个值,预先设定开关s(1,1)-s(k,n)的开/关的组合。开关控制电路swct接收标识符id1并且通过分别生成“k
×
n”开关控制信号ss(1,1)-ss(k,n)来控制开关s(1,1)-s(k,n)的开/关。尽管未示出,图2的开关电路sw2例如由与图4相同的交叉开关等构成。
[0042]
在图2中,dma控制器dmac3包括n个通道ch(1)-ch(n)。n个通道ch(1)-ch(n)中的每个通道从图1的存储器mem2读取图像数据imd中的像素值,并且基于单独设置的读取地址范围将它们传送到n个累加器acc(1)-acc(n)。
[0043]
n个累加器acc(1)-acc(n)中的每个累加器例如具有一个乘法器和一个累计加法器。另外,n个累加器acc(1)-acc(n)中的每个累加器例如可以具有神经网络处理中所需的偏置加法器或激活函数计算器。对于每个控制周期,n个累加器acc(1)-acc(n)将来自dma控制器dmac3的n个像素值和从开关电路sw1传送的k个未压缩的加权因子w(1)-w(k)相乘。
[0044]
这里,n个累加器acc(1)-acc(n)和k(k《n)个加权因子w(1)-w(k)之间的对应关系由开关电路sw1确定。此时,开关电路sw1将k个加权因子w(1)-w(k)中的至少一个并行传输到n个累加器acc(1)-acc(n)中的两个或更多个累加器。然后,n个累加器acc(1)-acc(n)中的每个累加器在多个控制周期中将如此获得的像素值与加权因子的乘法结果累加并添加到时间序列中。作为示例,对于k=28,n可以约为100到1000。
[0045]
dma控制器dmac2包括m个通道ch(1)-ch(m)。m个通道ch(1)-ch(m)中的每个通道基于单独设定的写地址,对于每个控制周期,将n个累加器acc(1)-acc(n)的输出传送到存储器(例如图1的存储器mem2)的写地址。
[0046]
在n个累加器acc(1)-acc(n)和dma控制器dmac2之间设置开关电路sw2。开关电路sw2,根据来自开关控制电路swct的开关控制信号ss2,并因此基于标识符id2所表示的对应关系,将n个累加器acc(1)-acc(n)的输出传送到dma控制器dmac2中的m个通道ch(1)-ch
(m)。
[0047]
(神经网络处理的具体示例)
[0048]
图5是示出cnn中所包括的卷积层中的处理内容的示例的示意图。在图5中,图像数据imd中的某个二维区域a由像素值数据xda组成,该像素值数据xda由i个像素值xa(1)-xa(i)组成。类似地,图像数据imd中的另一个二维区域b由像素值数据xdb组成,该像素值数据xdb由i个像素值xb(1)-xb(i)组成。
[0049]
另一方面,在cnn中,k个加权因子数据wfd(1)-wfd(k),也称为核心,根据k个输出通道使用。输出通道(1)的加权因子数据wfd(1)由i个加权因数w(1,1)-w(1,i)组成。类似地,输出通道(k)的加权因子数据wfd(k)也由i个加权因数w(k,1)-w(k,i)组成。
[0050]
在卷积层,根据k个输出通道生成k个特征图fmp(1)-fmp(k)。在输出通道(1)的特征图fmp(1)中,图像数据imd中与二维区域a对应的像素的特征量va(1),通过将像素值数据xda和输出通道(1)的加权因子数据wfd(1)进行乘积和运算而计算得到。类似地,在特征图fmp(1)中,图像数据imd中与二维区域b对应的像素的特征量vb(1)通过将像素值数据xdb和输出通道(1)的加权因子数据wfd(1)进行乘积和运算而计算得到。
[0051]
此外,在输出通道(k)的特征图fmp(k)中,图像数据imd中与二维区域a对应的像素的特征量va(k),通过将像素值数据xda和输出通道(k)的加权因子数据wfd(k)进行乘积和运算而计算得到。类似地,在特征图fmp(k)中,图像数据imd中与二维区域b对应的像素的特征量vb(k),通过将像素值数据xdb和输出通道(k)的加权因子数据wfd(k)进行乘积和运算而计算得到。顺便提及,每个特征量,诸如乘积和运算结果,加上每个输出通道的偏置值,可以通过激活函数的运算被进一步计算。
[0052]
图6是示出图2的神经网络引擎执行图5的处理时的运算示例的示意图。在图6的示例中,累加器acc(1),...,acc(r),...,acc(q),...分别计算图5中的特征量va(1),...,vb(1),...,va(k),...。
[0053]
在这种情况下,开关电路sw1针对多个累加器acc(1)至acc(r),在i个控制周期中依次并行传送输出通道(1)中的i个加权因子w(1,1)至w(1,i)。类似地,开关电路sw1针对多个累加器acc(q),在i个控制周期中依次并行传送输出通道(k)中的i个加权因子w(k,1)至w(k,i)。
[0054]
在这种处理之前,例如,解压缩器dcmp在第一控制周期中还接收压缩的j个加权因子p(1,1)至p(j,1),并且通过解压缩输出k个输出通道的加权因子w(1,1)至w(k,1)。如图3所示,报头hd被添加到该压缩的加权因子p(1,1)至p(j,1)。开关控制电路swct基于该报头hd中的标识符id1生成开关控制信号ss1。
[0055]
开关电路sw1从解压缩器dcmp接收k个输出通道的加权因子w(1,1)-w(k,1),并且基于来自开关控制电路swct的开关控制信号ss1,将加权因子w(1,1)-w(k,1)中的每一个并行传送到多个累加器。即,例如,在图4中,开关控制电路swct生成开关控制信号ss1,以接通连接到布线lnd(1)的多个开关s(1,1)-s(k,n)以获得加权因子w(1)。
[0056]
另一方面,在dma控制器dmac3中,通道ch(1)和ch(q)依次从存储器mem2中读取i个像素值xa(1)到xa(i),并且在i个控制周期中按此顺序分别将它们传送到累加器acc(1)和acc(q)。另外,通道ch(r)从存储器mem2中依次读取i个像素值xb(1)-xb(i),并在i个控制周期中按此顺序将它们传送到累加器acc(r)。因此,图5中示出了累加器acc(1),...,acc
(r),...,acc(q),...、乘积和运算。
[0057]
在dma控制器dmac2中的每个通道中,图5所示的输出通道所对应的特征图fmp(1)-fmp(k)与存储器(例如图1的存储器mem2)的写地址的对应关系是预先确定的。开关电路sw2、累加器acc(1),...,acc(r),...,acc(q),...、来自开关控制电路swct的开关控制信号ss2的输出,因此基于标识符id2,并且传送到dma控制器dmac2中的各个通道。然后,dma控制器dmac2中的每个通道将来自开关电路sw2的输出写入预置存储器的写地址。
[0058]
(第一实施例的主要效果)
[0059]
图7是示出在图1和图2的半导体装置中抽取出一部分的配置示例的示意图。图11和图12是示出用作本发明的可比较示例的半导体装置的配置示例的示意图。在图7中,示出了神经网络引擎nne中的存储器mem1和dma控制器dmac1、解压缩器dcmp、开关电路sw1、寄存器reg、开关控制电路swct和累加器单元accu。
[0060]
另一方面,图11所示的比较示例半导体装置包括神经网络引擎nne'a和存储器mem1,神经网络引擎nne'a包括累加器单元accu和dma控制器dmac1。然后,在dma控制器dmac1和存储器mem1之间设置解压缩器dcmp。
[0061]
在图11的配置中,dma控制器dmac1的控制可能很复杂,因为解压缩器dcmp的输入和输出之间的数据数量不同。因此,对于累加器单元accu中的n个累加器acc(1)-acc(n),可能无法有效地从解压缩器dcmp传送未压缩的加权因子。即,n个累加器acc(1)-acc(n)的资源可能无法有效利用。
[0062]
图12所示的比较示例包括神经网络引擎nne'b,包括n个累加器acc(1)-acc(n)、n个解压缩单元dcmp(1)-dcmp(n)和dma控制器dmac1、以及存储器mem1。如图7所示,在dma控制器dmac1和累加器单元accu之间设置解压缩器dcmp(1)-dcmp(n)。
[0063]
然而,在图12的配置示例中,n个解压缩器dcmp(1)-dcmp(n)被设置为有效地利用n个累加器acc(1)-acc(n)。然后,n个解压缩器dcmp(1)-dcmp(n)中的每一个将未压缩的加权因子传送到n个累加器acc(1)-acc(n)。然而,在这种情况下,电路面积随着n个解压缩器dcmp(1)-dcmp(n)可能会增加,因此功耗也可能会增加。
[0064]
另一方面,不同于图12的配置示例,在图7的配置示例中,开关电路sw1被设置在累加器单元accu和解压缩器dcmp之间。在如图4和图6等所示的开关电路sw1中,可以将一个加权因子从解压缩器dcmp传送到多个累加器。因此,在图7的配置中,由于设置单个解压缩器dcmp就足够了,因此可以减小电路面积,从而可以降低功耗。
[0065]
此外,与图11的配置示例相比,通过利用图3的报头hd中的标识符id1适当地定义开关电路sw1中的对应关系,可以有效地利用n个累加器acc(1)-acc(n)的资源。结果,可以加快神经网络的处理速度。此外,在另一方面,标识符id1被预先适当确定,并作为图3的加权因子数据集wfds被存储在存储器mem1中,从而可以灵活地支持各种配置的神经网络。这种灵活性对于标识符id2同样有效。
[0066]
(第一实施例)
[0067]
(神经网络引擎周围的配置)
[0068]
图8是示出根据本发明的第二实施例的半导体装置中的神经网络引擎周围一部分的配置示例的示意图。不同于图7的配置,图8所示的神经网络引擎nnea包括多组解压缩器dcmp、开关电路sw1、开关控制电路swct和累加器单元accu。
[0069]
在图7的配置示例中,如图3所示,例如,1个解压缩器dcmp,输出可达28个未压缩的加权因子w(1)-w(k)。然后,加权因子w(1)-w(k)通过开关电路sw1适当地传送到累加器acc(1)-acc(n),诸如累加器单元accu中的大约数100到1000个。然而,在图7的配置示例中,例如,当输出通道数目大于28时,可能需要进行时分处理。
[0070]
因此,如图8所示的多组解压缩器dcmp,开关电路sw1,通过提供开关控制电路swct和累加器单元accu,即使输出通道的数目很大,也可以并行执行多个输出通道的处理。结果,可以加快神经网络的处理速度。在这种情况下,例如,图3的加权因子数据集wfds的位宽可以扩展到多次,或者可以设置多个dma控制器dmac1。
[0071]
(第三实施例)
[0072]
(神经网络引擎周围的配置)
[0073]
图9是示出根据本发明的第三实施例的半导体装置中的神经网络引擎的一部分的配置示例的示意图。与图7的配置示例相比,在图9所示的神经网络引擎nneb中,删除了从dma控制器dmac1到寄存器reg的报头hd的输出路径。相反,形成从处理器prc到寄存器reg的报头hd输出路径。
[0074]
即,当dma控制器dmac1将如图3所示的压缩的加权因数数据wfdc传送到解压缩器dcmp时,处理器prc将标识符id1输出到寄存器reg并且因此经由系统总线sbus输出到开关控制电路swct。具体地,处理器prc在与神经网络引擎nneb的处理相对应的定时生成图3的报头hd,并且将包括在报头hd中的标识符id1和id2输出到开关控制电路swct。通过使用这种配置,可以减少报头hd所需的存储器mem1的存储容量。
[0075]
(第四实施例)
[0076]
(神经网络引擎的细节)
[0077]
图10是示出根据本发明的第四实施例的半导体装置中的神经网络引擎的详细配置示例的图。与图2的配置相比,图10所示的神经网络引擎在dma控制器dmac3和累加器单元accu之间设置有解压缩单元du3。
[0078]
解压缩单元du3包括与解压缩单元du1相同的配置,将与上述加权因子的处理相关联的开关控制电路swct、解压缩器dcmp、开关电路sw1和寄存器reg作为解压缩单元du1。即,存储器mem1保持预压缩的图像数据。然后,解压缩单元du3在解压缩的同时将压缩的图像数据传送到累加器单元accu。
[0079]
通常,由于数据量小于加权因子数据wfd,所以图像数据imd以存储在存储器mem2中用于缓存的状态作为未压缩的数据使用。然而,例如,如果图像数据imd的输入通道数目增加,则可能难以充分确保与存储器mem2中的图像数据imd相关联的存储容量。因此,通过使用如图10所示的配置示例,即使在图像数据imd的数据量大的情况下也可以对应。
[0080]
尽管已经基于实施例具体描述了本发明人做出的发明,但是本发明不限于上述实施例,并且不必说可以进行各种修改而不脱离其主旨。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1