一种面向构件剩余使用寿命预测的模型分析可视化方法
1.本发明涉及信息可视化与可视分析、机器学习技术领域,具体为一种面向构件剩余使用寿命预测的模型分析可视化方法。
背景技术:
2.随着传感器技术和计算机数据存储能力的不断进步,工业设备收集了越来越多的运行监测数据。这些数据不仅揭示了当前机器的运行状况,同时也隐藏着机器的退化模式。在预后和健康管理领域中,有大量基于此数据进行机器剩余使用寿命预测的研究。
3.在制造业领域中,构件的剩余使用寿命(remaining useful life,rul)定义为从当前时间到退化程度超出阈值的时间长度。rul预测问题则是基于构件的运行状态监测数据,通过算法模型实现对剩余使用寿命的预测。全面深入的rul预测和分析可为构件的运维、保养、修理提供有效的建议,从而大大降低安全事故发生的可能性。如何快速构建模型、灵活调整参数、对比和解释模型结果,以提升rul预测模型的精度,是rul预测分析人员的关注焦点。
4.在当前大数据时代背景下,国内外学者已对rul预测问题进行了广泛的研究,提出了大量经典的、基于数据驱动的rul预测方法,如循环神经网络(recurrent network,rnn)、隐马尔可夫模型(hidden markov model,hmm)、卷积神经网络(convolutional neural networks,cnn)和随机森林(random forest,rf)等等。但这些算法大都需要构建网络,对于缺乏专业知识和工程经验的人,配置改进神经元的数量、层的数量、参与训练的特征等相关参数往往需要消耗大量时间。此外,这些算法往往作为黑盒独立运行,分析人员只能获取模型计算的结果,其准确性取决于训练数据的置信水平,没有物理意义,所以难以对结果进行归因解释。
5.可视化与可视分析通过丰富的交互技术和直观的信息表示,能够促进rul预测模型的快速构建、对模型结果的分析和评估,从而提升模型精度和分析结论的可解释性。现有面向rul预测的多模型告警系统封装了预测方法,领域分析人员只能通过系统级提示获取模型计算的集成结果或模型预测的统计性结果,难以对其中的模型开展直观比较,也难以进行实例级数据的归因解释。由于构件实例可能存在复杂的共性特征或个性特征,因此发现在不同模型中预测结果差异较大的特殊实例,对研发特异性模型具有重要意义。现有实例层级的模型交互比较方法难以同时满足rul中概览、组别、实例的多层级比较分析任务,且鲜有研究在对比模型时追踪了模型迭代过程中实例预测结果的变化以及不同模型间预测结果的差异性。
技术实现要素:
6.针对上述问题,本发明的目的在于提供一种面向构件剩余使用寿命预测的模型分析可视化方法,以航空燃气涡扇发动机数据为例,针对rul预测问题中改进的rnn网络即长短期记忆网络(long short-term memory,lstm)、cnn、rf三大经典算法,设计并实现具有交
互能力的特征选择视图、控制面板视图、模型结果视图和模型对比视图,辅助rul预测分析人员灵活构建和调整预测模型,多层级对比、跟踪和解释模型结果,以提升rul预测模型的精度,为模型优化和构件维护提供有效建议。具体技术方案如下:
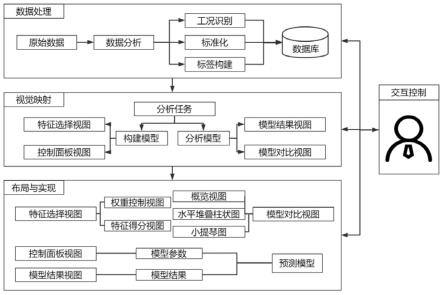
7.一种面向构件剩余使用寿命预测的模型分析可视化方法,包括以下步骤:
8.s1:数据处理
9.获取航空燃气涡扇发动机数据集后,进行数据分析,筛选数据子集,并对原始数据进行工况识别、标准化和标签构建的数据预处理工作;
10.s2:可视化映射
11.通过视觉通道将经步骤s1获得的数据进行可视化映射:
12.设计特征选择视图,用权重控制视图映射用户对特征指标的权重控制,用特征得分视图映射特征在不同评价指标下的重要性得分;
13.设计控制面板视图,用于调整模型中的参数,以对模型做出优化;
14.设计模型结果视图,用于存储展示模型优化的中间结果,以指导用户模型优化的方向;
15.设计模型对比视图,用概览视图展示模型优化历史和汇总的模型计算结果;用水平堆叠柱状图展示模型在不同实例组上预测值与真实值之间的差异,通过像素图和连接水平堆叠柱状图的色带引导用户发现实例在其他模型中的误差位置和差异大小;用小提琴图记录模型的训练过程;
16.s3:可视化布局与实现
17.对s2中完成映射的视觉模块进行可视化布局并实现:在特征选择视图中完成权重控制视图与特征得分视图的布局与实现;在控制面板视图中完成参数控制的布局与实现;在模型结果视图中可视化模型的结果;在模型对比视图中完成概览视图、水平堆叠柱状图和小提琴图的布局与实现;
18.特征选择视图中,上半部分为权重控制视图,自上而下并列放置单调性、可预测性和趋势性三个指标的权重控制面板,每个权重控制面板由滑动条和置于滑动条上方的柱状图组成;下半部分为特征得分视图,由左至右并列呈现特征的总得分、单调性得分、可预测性得分和趋势性得分,每行代表一个特征的得分情况;
19.控制面板视图中,由上至下分别为公有参数、lstm模型参数、rf模型参数和cnn模型参数的调整面板;
20.模型结果视图中,以列表的形式存储模型结果,从左至右分别代表序号、模型、rmse分数、s-score分数和模型参数信息,每行代表一个模型一次预测的结果;
21.模型对比视图中,根据预测模型的数量将可视区域等分,等分后的每个区域由上至下分别呈现概览视图、水平堆叠柱状图和小提琴图,水平堆叠柱状图内为实例级显示;区域之间由色带进行连接;
22.s4:交互设计
23.在特征选择视图中提供重配和选择交互操作:重配根据实际需要调整单调性、可预测性、趋势性和总得分的排序方式;在权重控制视图中,拖动滑动条的游标选择每个指标的权重;在特征得分视图中,结合实际场景在多选框中选择参与预测的特征;
24.在模型对比视图中提供提示、过滤和重配交互操作:提示交互包括鼠标点击像素
图中的具体实例时出现的色带和鼠标悬浮在某个元素上出现提示信息,过滤用于模型快照的删除与恢复,重配操作旨在将实例组映射的柱形图重配为实例映射的像素图。
25.进一步的,在步骤s1中,数据数据获取具体为:从商业模块化航空推进系统模拟生成航空燃气涡扇发动机数据集,包含训练集和测试集;训练集包含所有发动机从初始状态运行到完全故障的数据,但在测试集中仅包含发动机完整运行周期中的前一段数据;并选用运行环境包含六种工况和两类故障模式的数据子集进行分析。
26.更进一步的,在步骤s1中,数据预处理操作具体包括:
27.对数据集进行工况识别、标准化和标签构建的数据预处理操作,具体为:
28.s11:工况识别:使用k-means聚类算法,根据高度、马赫数、海平面温度3种操作条件,将每个时间下的监测数据划分为6种工况;
29.s12:标准化:针对不同工况下的数据采用z-score标准化,计算公式如下:
[0030][0031]
式中:m表示工况类别;d表示第d个传感器特征;x
′
(m,d)
表示标准化后的数据;x
(m,d)
表示原始数据;μ
(m,d)
表示第d个传感器的m工况的平均值;σ
(m,d)
表示第d个传感器的m工况的标准差;
[0032]
s13:标签构建:使用分段线性rul目标函数构建标签,将构件最大rul设置为一个常数,在使用一段时间后开始线性退化;具体计算公式如下:
[0033][0034]
式中:常数τ
max
为常数;t表示构件运行时间;u表示第u个构件;l(u)表示第u个构件的当前rul值。
[0035]
更进一步的,在步骤s2中,可视化映射具体为:
[0036]
s21:对特征选择视图中的权重控制视图进行位置、高度、颜色映射:滑动条的浮标位置表示每个指标的权重大小,滑动条上方的柱状图高低代表该权重的推荐指数,用柱状图不同的颜色区分是否选中的状态;对特征选择视图中的特征得分视图进行颜色、长度映射:水平柱状图的颜色代表特征的单调性、可预测性、趋势性得分三个指标种类,特征标识的背景色深浅代表特征的总得分的高低,水平柱状图的长度映射当前指标在该维度上的得分;
[0037]
s22:对控制面板视图进行颜色映射:用不同颜色的标题分别对应公有参数调节区域、lstm模型的参数调节区域、rf模型的参数调节区域和cnn模型的参数调节区域;
[0038]
s23:对模型结果视图进行颜色映射:视图通过颜色将列表划分为三个区域,分别对应三种模型的训练结果,即用与控制面板视图一致的颜色映射来映射lstm模型的训练结果、rf模型的训练结果和cnn模型的训练结果;
[0039]
s24:对模型对比视图中的概览视图进行空间位置、颜色、高度、长度、面积和形状映射:
[0040]
根据构件的生命周期长度对构件进行分组,使用水平堆叠柱状图展示模型在不同实例组上预测值与真实值之间的差异;通过快照的方式生成小提琴图对训练过程进行记
录,同时在视图顶端展示模型优化历史和汇总的模型计算结果;使用色带连接水平堆叠柱状图,引导用户发现该实例在其他模型中的误差位置,同时在色带中加入颜色和透明度映射差异的大小;
[0041]
空间位置:根据模型数量将视图分为对应数量的区域,每个区域展示同一模型的信息;
[0042]
颜色:概览视图与小提琴图颜色用于表示分类信息,采用不同色系映射模型类别,与模型结果视图中的颜色映射一致;按照构件生命周期长度将构件分类,选定基础色系,用柱状图颜色深浅映射生命周期长度;在构件像素图中,正方形的颜色映射该构件在不同模型上预测结果的差异大小,颜色越深,预测差异越大;在色带中,颜色和透明度映射差异的大小;
[0043]
高度、面积:概览视图中,高度映射模型的均方根误差分数的大小,圆形面积的大小映射模型的评分函数分数;
[0044]
长度:在水平堆叠柱状图中,每一柱形的水平长度对应着该分组内的构件数量;
[0045]
形状:在模型快照中,利用由箱线图和密度图组成的小提琴图来显示模型预测结果的统计信息;即密度图的形状显示预测差异值的分布,其中流的宽度表示位于相应范围内的数据点的数量;箱线图的形状指示相关阈值,包含上四分位数、中位数、下四分位数、平均值。
[0046]
更进一步的,在步骤s3中,所述特征选择视图的可视化布局与实现的具体过程如下:
[0047]
s31a:根据用户调节权重次数的记录,计算权重的推荐指数,在滑动块调节处将该次数映射成柱状图的高度,完成权重控制视图的实现;
[0048]
s31b:分别计算特征的单调性、可预测性和趋势性三个重要性指标,并结合权重控制视图中的权重计算特征的总得分;
[0049]
1)单调性表征构件退化时特征的趋势,计算如下:
[0050][0051]
式中:n表示样本数量;表示b号构件第a个特征的测量值;表示特征变化轨迹正导数的个数;表示特征变化轨迹负导数的个数;表示构件特征测量值的变化;表示b号构件第a个特征在t时间的测量值;m越靠近1表明传感器是单调的并且对rul预测是有用的,越接近于0表明传感器是不单调的,在预测中应不考虑该特征;
[0052]
2)可预测性计算公式如下:
[0053][0054]
式中:σ
failure
为每台机器的故障方差,μ
failure-μ
healthy
表示传感器在其整个生命周
期内的平均变化,prognosability越接近1表明故障阈值相似且传感器参数可预测;
[0055]
3)趋势性是与时间之间的相关属性,提供在多次运行失败实验中测量的特征轨迹之间的相似性度量,计算公式如下:
[0056][0057]
式中:k表示构件个数,xk表示第k个构件从运行开始到生命周期结束过程中的特征值组成的向量,tk表示第k个构件的生命周期长度;
[0058]
4)特征总得分计算公式如下:
[0059][0060]
式中:wm、w
p
、w
t
分别表示单调性、可预测性和趋势性的权重;vm、v
p
、v
t
分别表示单调性、可预测性和趋势性的原始值;
[0061]
s31c:将重要性指标计算结果映射为水平柱状图的长度,水平柱状图的长度进一步采用分段线性比例尺方法计算;将特征的总得分映射为特征标识的背景色,完成特征得分视图的实现。
[0062]
更进一步的,在步骤s3中,所述控制面板视图的可视化布局与实现的具体过程如下:
[0063]
s32a:分别调用sklearn库中对应的模块实现cnn模型、lstm模型、rf模型;
[0064]
s32b:设置cnn、lstm、rf模型可调节的参数并进行可视化映射,完成控制面板视图的实现。
[0065]
更进一步的,在步骤s3中,所述模型结果视图的可视化布局与实现的具体过程如下:
[0066]
s33a:根据公式分别计算模型预测结果的rmse、s-score评价指标;
[0067][0068]
式中:n表示样本数量;rul
predict,c
表示测试样本c的预测rul值;rul
true,c
表示测试样本c的真实rul值;hc表示预测rul值与真实rul值之间的差;rmse越大,柱状图高度越低,表示模型的效果越差;
[0069]
s-score的计算公式如下:
[0070][0071]
式中:s-score分数越大,圆形面积越小,表示模型的效果越差;
[0072]
s33b:将rmse、s-score的计算结果,以及模型的名称、模型的参数信息、序号共同
映射为模型结果视图中的一条记录,完成模型结果视图的实现。
[0073]
更进一步的,在步骤s3中,所述模型对比视图的可视化布局与实现的具体过程如下:
[0074]
s34a:对于整体布局,根据预测模型的数量n将可视区域分为n个部分,然后根据位置计算公式计算每个视图的位置信息;位置计算公式如下:
[0075]
positionxq=paddingleft+(q-1)
·
(bandwidth+viswidth)
[0076]
式中:paddingleft表示左边距;bandwidth表示视图间距;viswidth表示视图宽度,q表示第q个部分;
[0077]
s34b:对于单个模型的视图,按照生命周期长短,将构件分为j个集合,根据模型预测结果与真实值的差异大小将误差分为i段;
[0078]
s34c:在概览视图中,采用序数比例尺对不同模型的结果进行颜色映射,并将模型优化结果评价指标rmse、s-score采用线性比例尺分别映射为柱状图高度以及圆半径,完成概览视图的实现;
[0079]
颜色映射函数如下:
[0080]
color
p
=modelcolorlist[p]
[0081]
式中:p表示模型类别编号,modelcolorlist[
·
]表示封装模型的颜色列表通过类别编号索引;
[0082]
柱状图高度的计算公式如下:
[0083][0084]
式中:barheight
min
表示堆叠柱状图的起始高度,barheight
max
表示堆叠柱状图的终止高度,s
rmse_min
表示模型的最小rmse分数,s
rmse_max
表示模型的最大rmse分数;α表示模型当前rmse分数映射到概览视图中的高度比例;
[0085]
s34d:在水平堆叠柱状图中,使用公式计算每个柱形图的位置,然后由初始柱形图位置生成像素图的位置;每个像素点的值由该模型的结果与其他模型的偏差决定,然后通过线性比例尺映射为像素点的颜色;色带采用三次贝塞尔曲线绘制,完成水平堆叠柱状图的实现;
[0086]
每个柱形图的位置计算公式如下:
[0087][0088]
式中:i表示第i段误差对应的柱形图,j表示柱形图内第j个构件集合,pwidth
ij
表示构件集合的起始宽度位置,pheight
ij
表示构件集合的起始高度位置,barheight表示每个柱形图的高度,bandheight表示柱形图间的间距;
[0089]
偏差的计算公式如下:
[0090][0091]
式中:s表示模型的个数,r表示第r个像素点,s表示第s个模型,表示第r个像素点在当前模型中预测的rul值,表示像素点在第s个模型中预测的rul值,valuer表示第r个像素点的值;
[0092]
s34e:在小提琴图中,视觉映射的实现过程如下:
[0093]
se1:分别计算正负测试集中的概率密度函数:
[0094][0095]
式中:h表示带宽,l表示构件总数,w表示预测值,xz表示实际的rul值,x表示模型预测的rul值,k(w)表示服从正态分布的w的密度函数,kh(w)表示带宽h下w的密度函数,表示概率密度函数的最终表达式;
[0096]
se2:然后逆时针旋转坐标轴90度,根据概率密度函数绘制对应的曲线;
[0097]
se3:根据模型对应的颜色,对曲线内部进行色彩填充;
[0098]
se4:将预测结果统一汇总,计算数据的上四分位点、下四分位点、中位数、平均数、最大值和最小值;
[0099]
se5:建立坐标轴,在中位数处画一条横线,平均数处绘制一个圆点,在下四分位数与上四分位数之间绘制一个矩形,最后从下四分位点画一条线到最小值点,从上四分位点画一条线到最大值点,完成小提琴图的实现。
[0100]
本发明的有益效果是:
[0101]
1)本发明弥补了现有方法在快速构建模型和灵活调整参数方面的不足。传统基于数据驱动的rul预测模型的构建需要配置参与训练的特征、设计模型的层数等参数,对于缺乏专业知识和工程经验的人,在这一步中需要耗费大量的时间,研发成本高。本方法设计了特征选择视图,提供特征得分视图帮助用户理解特征在不同评价指标下的重要性得分,提供权重控制视图帮助用户根据实际需要调整不同指标的权重,进而得到不同权重下的特征总得分,辅助用户进行特征筛选。本方法设计了控制面板视图,允许用户分别调整rul预测问题中lstm、rf、cnn三个经典模型的参数。通过直观的特征选择视图和控制面板视图,完成模型的快速构建和参数的灵活调整。
[0102]
2)本发明弥补了现有方法在模型对比和实例级数据的归因解释方面的不足。现有面向rul预测的多模型告警系统封装了预测方法,但是领域分析人员只能通过系统级提示获取模型计算的集成结果或模型预测的统计性结果,难以对其中的模型开展直观比较,也难以进行实例级数据的归因解释。本方法设计了模型对比视图,同时满足rul中概览、组别、
实例的多层级比较分析任务,并在对比模型时追踪了模型迭代过程中实例预测结果的变化以及不同模型间预测结果的差异性。本方法还设计了模型结果视图,存储展示每次模型优化的中间结果。通过模型对比视图和模型结果视图,完成rul预测模型的多层级对比分析和对实例级数据的归因解释。
附图说明
[0103]
图1是本发明的整体流程框架示意图。
[0104]
图2是本发明中特征选择视图示意图。
[0105]
图3是本发明中控制面板视图示意图。
[0106]
图4是本发明中模型结果视图示意图。
[0107]
图5是本发明中模型对比视图示意图。
[0108]
图6是本发明中两类线性比例尺计算方案示意图;(a)水平柱状图长度的计算;(b)柱状图高度或圆半径的计算。
[0109]
图7是本发明中模型对比视图布局设计示意图。
[0110]
图8是本发明中水平堆叠柱状图的布局设计和色带绘制示意图;(a)柱形图的位置计算;(b)基于贝塞尔曲线的色带绘制示意图。
具体实施方式
[0111]
下面结合附图和具体实施方式对本发明做进一步详细说明。
[0112]
本发明通过可视化与可视分析方法,结合多视图联动策略、灵活丰富的交互手段,实现对构件剩余使用寿命预测模型的构建、调整和对比分析,帮助rul预测分析人员减少模型构建成本,在概览、组别、实例层级上对比、跟踪和解释模型结果。技术方案包括:数据处理,可视化映射,可视化布局与实现,交互设计。具体步骤如下:
[0113]
步骤一:数据处理
[0114]
1、数据获取
[0115]
本方法使用的数据集来自美国宇航局nasa开发的商业模块化航空推进系统(c-mapss)模拟生成的航空燃气涡扇发动机数据集,包含训练集和测试集。训练集包含所有发动机从初始状态运行到完全故障的数据,但在测试集中仅包含发动机完整运行周期中的前一段数据,分析目标为根据测试集中发动机前一段生命周期的数据预测最终的rul值。其中每台机器初始状态都有不同程度的磨损,磨损的严重程度用户无法获取。
[0116]
每台机器在每个时间步内拥有3个操作条件(高度、马赫数、海平面温度)和21个传感器测量值。传感器测量数据的物理意义包含:风扇入口总温度、低压压缩机温度、高压压缩机温度、低压涡轮温度、风扇入口压力、旁路输送管压力、高压压缩机气压、物理风扇转速、物理核心转速、发动机压力比、高压压缩机静态压、燃油量与高压涡轮静压比、校正风扇转速、校正核心转速、旁通比、燃烧室内燃料空气比、排气阀热含量、需求风扇转速、校正的需求风扇转速、高压涡轮冷却剂排放、低压涡轮冷却剂排放,分别对应为:t2、t24、t30、t50、p2、p15、p30、nf、nc、epr、ps30、phi、nrf、nrc、bpr、farb、htbleed、nf_dmd、pcnfr_dmd、w31、w32。
[0117]
整个数据集被划分为四个子数据集:fd001、fd002、fd003和fd004,四个子数据集
中操作模式和故障模式差异明显。为探究本方法的可扩展性,选用运行环境最为复杂(包含六种工况和两类故障模式)的fd004数据集进行分析。
[0118]
2、数据预处理:包含工况识别、标准化和标签构建。
[0119]
(1)工况识别
[0120]
由于设备在不同工况之间的切换会打破机器学习所依赖的独立同分布假设,因此需要对工况进行识别,根据工况对数据标准化,在前期消除工况不同对模型造成的负面影响。
[0121]
工况的状态由高度、马赫数、海平面温度3种操作条件决定,据此利用k-means对工况进行聚类。聚类属于无监督学习算法,是根据数据中的模式将数据分成多个集群的过程。k-means是最普及的聚类算法之一。该算法的主要流程为:1)指定k,即将数据分为k个类别;2)随机从数据中选取k个点作为每个集群的质心;3)通过某种距离计算方法衡量数据点与质心的距离(本方法采用欧式距离),将数据点划分给最近的聚类质心;4)重新计算每个集群的质心;5)如果满足新形成的集群的质心不再改变、点保持在同一个集群中、达到最大迭代次数三个条件之一,则结束迭代,否则重复第3步到第5步。
[0122]
选取k=6,根据操作条件将每个时间下的监测数据划分到工况下,便于后续通过不同工况对数据单独标准化,以消除工况不同对模型造成的负面影响。
[0123]
(2)标准化
[0124]
针对不同工况下的数据采用z-score标准化,计算公式如下:
[0125][0126]
式中:m表示工况类别;d表示第d个传感器特征;x
′
(m,d)
表示标准化后的数据;x
(m,d)
表示原始数据;μ
(m,d)
表示第d个传感器的m工况的平均值;σ
(m,d)
表示第d个传感器的m工况的标准差。
[0127]
(3)标签构建
[0128]
传统方法构建rul标签时,常使得rul随时间线性减小,即系统的健康状况随时间线性下降。但在实际应用中,在开始阶段构件的退化情况可以忽略不计,在寿命即将结束时退化更加明显。为了更好的模拟rul随时间的变化,本方法使用分段线性rul目标函数构建标签,将构件最大rul设置为一个常数,在使用一段时间后开始线性退化。具体计算公式如下:
[0129][0130]
式中:常数τ
max
为常数;t表示构件运行时间;u表示第u个构件;l(u)表示第u个构件的当前rul值。
[0131]
步骤二:可视化映射
[0132]
经过数据获取与处理后,对本发明中的特征选择视图(如图2所示)、控制面板视图(如图3所示)、模型结果视图(如图4所示)和模型对比视图(如图5所示)进行可视化映射方案设计。本方法以rul预测问题中lstm、rf、cnn三个经典模型为例进行分析。
[0133]
1、特征选择视图
[0134]
特征选择视图包括权重控制视图(图2上半部分)和特征得分视图(图2下半部分)。
[0135]
(1)权重控制视图
[0136]
位置:滑动条的浮标位置表示每个指标的权重大小。
[0137]
高度:滑动条上方的柱状图高低代表了该权重的推荐指数。
[0138]
颜色:灰色表示未选中状态,绿色表示选中状态。
[0139]
(2)特征得分视图
[0140]
特征得分视图以列表的形式呈现结果,每行代表一个特征的得分,从左至右分别代表特征标识、特征的单调性得分、特征的可预测性得分、特征的趋势性得分。其中,特征标识列内的文字内容,为前述所提到的传感器测量数据的物理意义对应的标识符。
[0141]
颜色:水平柱状图的颜色代表特征的单调性得分、特征的可预测性得分、特征的趋势性得分三个指标种类。特征标识的背景色代表特征的总得分,得分越高,颜色越深。
[0142]
长度:水平柱状图的长度映射当前指标在该维度上的得分。
[0143]
2、控制面板视图
[0144]
控制面板视图的主要作用为调整模型中的参数,以对模型做出优化。
[0145]
颜色:粉色标题表示公有参数调节区域,红色标题对应lstm模型的参数调节区域、蓝色标题对应rf模型的参数调节区域、绿色标题对应cnn模型的参数调节区域。
[0146]
3、模型结果视图
[0147]
在模型调整优化的过程中,需要对模型优化的中间结果进行存储展示,以指导用户模型优化的方向。模型结果视图以列表的形式存储模型结果,从左至右分别代表序号、模型、rmse(root mean squared error,rmse均方根误差)分数、s-score(评分函数)分数、模型参数信息。
[0148]
颜色:视图通过颜色将列表划分为三个区域,分别对应三种模型的训练结果。即红色对应lstm模型的训练结果、蓝色对应rf模型的训练结果、绿色对应cnn模型的训练结果。
[0149]
4、模型对比视图
[0150]
首先根据构件的生命周期长度对构件进行分组,使用水平堆叠柱状图(图5(b))展示模型在不同实例组上预测值与真实值之间的差异。为了记录单个模型优化的过程,通过快照的方式生成小提琴图(图5(c))对训练过程进行记录,同时在视图顶端展示了模型优化历史和汇总的模型计算结果(图5(a))。为了显示不同模型对于实例的预测差异,用户通过交互可将柱状图中的柱形替换为像素图(图5(d)),视图中使用色带连接水平堆叠柱状图,引导用户发现该实例在其他模型中的误差位置,同时在色带中加入颜色和透明度映射差异的大小。
[0151]
空间位置:根据模型数量将视图分为对应数量的区域,每个区域展示同一模型的预测结果、快照等信息。如图5所示,本方法从左到右分别记录了lstm、rf、cnn三个模型的结果。
[0152]
颜色:概览视图与小提琴图颜色仅用于表示分类信息,以区分不同的模型,各分组的颜色与模型结果视图中行颜色保持一致。采用红、蓝、绿三种对比度明显的色系映射模型类别。在水平堆叠柱状图中,按照构件生命周期长度将构件分为5类。选用橙色作为基础色系,生命周期长度越长,柱状图颜色越深。在构件像素图中,正方形的颜色映射该构件在不同模型上预测结果的差异大小,颜色越深,预测差异越大。在色带中,颜色和透明度映射差
异的大小。
[0153]
高度:概览视图中,高度映射模型的均方根误差(rmse)分数,rmse越大,柱状图高度越低。
[0154]
长度:在水平堆叠柱状图中,每一柱形的水平长度对应着该分组内的构件数量,采用堆叠设计可以横向对比在同一误差范围中不同分组的数量,同时也可纵向对比同一分组在不同误差范围下的分布。柱形的垂直宽度并无实际含义,由该视图的宽度决定。
[0155]
面积:概览视图中,圆形面积的大小映射模型的s-score分数,s-score分数越大,圆形面积越小。
[0156]
形状:在模型快照中,利用由箱线图和密度图组成的小提琴图来显示模型预测结果的统计信息,即密度图的形状显示了预测差异值的分布,其中流的宽度表示位于相应范围内的数据点的数量;箱线图的形状指示相关阈值,包含上四分位数、中位数、第下四分位数、平均值。
[0157]
步骤三:可视化布局与实现
[0158]
在特征选择视图中完成权重控制视图与特征得分视图的布局与实现(如图2所示);在控制面板视图中完成参数控制的布局与实现(如图3所示);在模型结果视图中可视化模型的结果(如图4所示);在模型对比视图中完成概览视图、水平堆叠柱状图和小提琴图的布局与实现(如图5所示)。
[0159]
1、特征选择视图可视化布局与实现
[0160]
本方法选用应用范围最广的单调性、可预测性和趋势性三个指标来对传感器参数进行特征选择。主要包括权重控制视图和特征得分视图。
[0161]
特征选择视图中,上半部分为权重控制视图,自上而下并列放置单调性、可预测性和趋势性三个指标的权重控制面板,每个权重控制面板由滑动条和置于滑动条上方的柱状图组成;下半部分为特征得分视图,由左至右并列呈现特征的总得分、单调性得分、可预测性得分和趋势性得分,每行代表一个特征的得分情况。
[0162]
(1)权重控制视图
[0163]
权重控制视图主要用于调节每个指标的权重,以获取符合实际情况的特征排名。其视图实现主要分为以下几个部分:
[0164]
数据定义:三个指标的推荐权重根据用户调节的次数得到,系统在用户每次设置权重时,会记录下当前设置的权重,根据所设置的权重频次进行排序,以指导后续分析人员的快速设置。滑动条的值的范围为0到1。
[0165]
柱状图高度:系统收集了用户每次调节的权重频次,在滑动块调节处将频次映射成柱状图的高度,用户在对权重进行调整时,可参考原先的调节比重。
[0166]
(2)特征得分视图
[0167]
特征得分视图主要用于辅助rul预测分析人员进行特征分析和选择,其视图设计主要分为以下几个部分:
[0168]
数据定义:
[0169]
1)单调性:单调性表征了构件退化时特征的趋势。一般认为,特征应与构件的退化趋势相同,即具有单调增加或单调减少的趋势,计算公式如下所示:
[0170][0171]
式中:n表示样本数量;表示b号构件第a个特征的测量值;表示特征变化轨迹正导数的个数;表示特征变化轨迹负导数的个数;表示构件特征测量值的变化;表示b号构件第a个特征在t时间的测量值;m越靠近1表明传感器是单调的并且对rul预测是有用的,越接近于0表明传感器是不单调的,在预测中应不考虑该特征。
[0172]
2)可预测性:可预测性由每台机器的故障方差σ
failure
除以传感器在其整个生命周期(μ
failure-μ
healthy
)内的平均变化,计算公式如下所示:
[0173][0174]
式中:σ
failure
为每台机器的故障方差,μ
failure-μ
healthy
表示传感器在其整个生命周期内的平均变化,prognosability越接近1表明故障阈值相似且传感器参数可预测。
[0175]
3)趋势性:趋势性是与时间之间的相关属性,该指标提供了在多次运行失败实验中测量的特征轨迹之间的相似性度量。
[0176][0177]
式中:k表示构件个数,xk表示第k个构件从运行开始到生命周期结束过程中的特征值组成的向量,tk表示第k个构件的生命周期长度。
[0178]
4)特征总得分计算公式如下:
[0179][0180]
式中:wm、w
p
、w
t
分别表示单调性、可预测性和趋势性的权重;vm、v
p
、v
t
分别表示单调性、可预测性和趋势性的原始值。
[0181]
矩形长度:为了更高的区分度,水平柱状图的长度采用分段线性比例尺方法进行计算,如图6(a)所示。将特征的总得分映射为特征标识的背景色,完成特征得分视图的实现。
[0182]
2、控制面板视图可视化布局与实现
[0183]
本研究使用rul预测问题中常见的模型:cnn、lstm和rf进行实验,分别调用sklearn库中对应的模块实现cnn模型、lstm模型、rf模型。控制面板视图提供三种模型的参数调整功能。
[0184]
cnn模型允许调节的参数包括窗口大小window_length,步长step、选取的特征feature、cnn层数layers。
[0185]
lstm模型允许调节的参数与cnn一致。
[0186]
rf模型允许调节的参数包括窗口大小window_length,步长step、决策树数量n_estimators、最佳分割考虑的特征数量max_features。
[0187]
3、模型结果视图可视化布局与实现
[0188]
模型结果视图用于存储展示模型优化的中间结果,以指导用户模型优化的方向。该视图以列表的形式存储模型结果,从左至右分别代表序号、模型、rmse分数、s-score分数、模型参数信息。
[0189]
rmse的计算公式如下:
[0190][0191]
式中:n表示样本数量;rul
predict,c
表示测试样本c的预测rul值;rul
true,c
表示测试样本c的真实rul值;hc表示预测rul值与真实rul值之间的差;rmse越大,柱状图高度越低,表示模型的效果越差。
[0192]
s-score的计算公式如下:
[0193][0194]
式中:s-score分数越大,圆形面积越小,表示模型的效果越差。
[0195]
模型的参数信息与控制面板视图中各个模型允许调节的参数信息一致。将rmse、s-score的计算结果,以及模型的名称、模型的参数信息、序号共同映射为模型结果视图中的一条记录,完成模型结果视图的实现。
[0196]
4、模型对比视图可视化布局与实现
[0197]
(1)布局实现
[0198]
根据预测模型的数量n将可视区域分为n个部分,其中,每个视图布局方式如图7所示,位置计算公式如下:
[0199]
positionxq=paddingleft+(q-1)
·
(bandwidth+viswidth)
[0200]
式中:paddingleft表示左边距;bandwidth表示视图间距;viswidth表示视图宽度,q表示第q个部分。
[0201]
此外,paddingright表示右边距,canvasheight和canvaswidth分别表示画布的高度和宽度。针对同一模型,最多允许生成4个快照,每个快照所占宽度violinwidth由快照数量等分viswidth。概览视图高度overviewheight、堆叠柱状图高度barheight、快照视图高度violinheight按照1:4:1划分。
[0202]
(2)视觉编码实现
[0203]
模型对比视图的视觉编码需要完成模型预测统计结果、模型预测分布、实例预测结果等映射,主要分为以下几个部分:
[0204]
1)数据定义
[0205]
单个模型预测得到的rmse得分为s
rmse
,s-score得分为s
score
,按照生命周期长短,将构件分为j个集合,根据模型预测结果与真实值的差异大小将误差分为i段,则落在误差范围r内生命周期长度为v的构件个数为sum
rv
。对于单个构件,其真实的rul为ture
rul
,预测得到的rul为predict
rul
。
[0206]
2)概览视图视觉映射
[0207]
在概览视图中,采用序数比例尺对不同模型的结果进行颜色映射,并将模型优化结果评价指标rmse、s-score采用线性比例尺分别映射为柱状图高度以及圆半径,完成概览视图的实现。具体实施例如下:
[0208]
为区分不同模型的预测结果,采用序数比例尺对模型进行颜色映射,颜色映射函数如下:
[0209]
color
p
=modelcolorlist[p]
[0210]
式中:p表示模型类别编号,modelcolorlist[
·
]表示封装模型的颜色列表通过类别编号索引。
[0211]
模型优化结果采用线性比例尺映射为柱状图高度以及圆半径,如图6(b)所示。
[0212]
柱状图高度的计算公式如下:
[0213][0214]
式中:barheight
min
表示堆叠柱状图的起始高度,barheight
max
表示堆叠柱状图的终止高度,s
rmse_min
表示模型的最小rmse分数,s
rmse_max
表示模型的最大rmse分数;α表示模型当前rmse分数映射到概览视图中的高度比例。
[0215]
圆半径的计算公式与柱状图高度的计算公式类似,将其中的rmse分数替换为s-score分数即可。
[0216]
3)水平堆叠柱状图视觉映射
[0217]
在水平堆叠柱状图中,使用公式计算每个柱形图的位置,然后由初始柱形图位置生成像素图的位置;每个像素点的值由该模型的结果与其他模型的偏差决定,然后通过线性比例尺映射为像素点的颜色;色带采用三次贝塞尔曲线绘制,完成水平堆叠柱状图的实现。具体实施例如下:
[0218]
如图8(a)所示,每个柱形图的位置计算公式如下:
[0219][0220]
式中:i表示第i段误差对应的柱形图,j表示柱形图内第j个构件集合,pwidth
ij
表示构件集合的起始宽度位置,pheight
ij
表示构件集合的起始高度位置,barheight表示每个柱形图的高度,bandheight表示柱形图间的间距。
[0221]
像素图的位置由初始的柱形图位置生成,经过实验确定纵向排列数为4时最佳。每个像素点的值由与其他模型的偏差决定,该偏差的计算公式如下:
[0222][0223]
式中:s表示模型的个数,r表示第r个像素点,s表示第s个模型,表示第r个像素点在当前模型中预测的rul值,表示像素点在第s个模型中预测的rul值,valuer表示第r个像素点的值。
[0224]
然后通过线性比例尺映射为像素点的颜色,颜色越深,代表该实例在模型之间的预测差异越大,越值得被关注。
[0225]
为展示单个实例在模型间的预测差异,使用色带对实例所处的柱状图进行连接,色带采用三次贝塞尔曲线绘制,贝塞尔曲线包含四个点,即:起始点spoint、终止点epoint以及两个控制点cpoint1、cpoint2,如图8(b)所示。其中,两个控制点的坐标计算方式如下:
[0226][0227][0228]
式中:spoint
x
表示起始点的x轴坐标;epoint
x
表示终止点的x轴坐标;epointy表示终止点的y轴坐标;spointy表示起始点的y轴坐标。
[0229]
4)小提琴图视觉映射
[0230]
小提琴图包含箱型图与核密度图,传统的核密度图左右对称,由于rul问题预测提前与预测滞后有很大的区别,该可视化方法采用左侧对应预测滞后的构件统计,右侧对应预测提前的构件统计,绘制步骤如下:
[0231]
第一步,分别计算正负测试集中的概率密度函数,计算公式如下:
[0232][0233]
式中:h表示带宽,l表示构件总数,w表示预测值,xz表示实际的rul值,x表示模型预测的rul值,k(w)表示服从正态分布的w的密度函数,kh(w)表示带宽h下w的密度函数,表示概率密度函数的最终表达式。
[0234]
第二步,逆时针旋转坐标轴90度,根据概率密度函数绘制对应的曲线。
[0235]
第三步,根据模型对应的颜色,对曲线内部进行色彩填充。
[0236]
第四步,由于箱线图的统计无法区分正负,将预测结果统一汇总,计算得到数据的上四分位点、下四分位点、中位数、平均数、最大值和最小值。
[0237]
第五步,建立坐标轴,在中位数处画一条横线,平均数处绘制一个圆点,在下四分
位数与上四分位数之间绘制一个矩形,这个矩形代表了数据中的50%,最后从下四分位数画一条线到最小值点,从上分位数画一条线到最大值点。
[0238]
步骤四:交互设计
[0239]
在控制面板视图中可直接使用鼠标选择、键盘输入需要设置的参数信息;而模型结果视图是对模型调整结果的记录,可直接查看相关信息;因此,本方法的交互设计主要体现在特征选择视图和模型对比视图中,具体如下:
[0240]
1、特征选择视图
[0241]
重配:重配通过改变空间排列为用户提供观察数据集的不同视角,常常被用于表格可视化中。可根据实际需要调整单调性、可预测性、趋势性和总得分的排序方式。
[0242]
选择:在权重控制视图中,可拖动滑动条的游标选择每个指标的权重;在特征得分视图中,可结合实际场景在多选框中选择参与预测的特征。
[0243]
2、模型对比视图
[0244]
提示:提示操作包含“悬浮+高亮”的交互方式。当鼠标点击像素图中的具体实例时,同时通过色带对模型进行连接。当鼠标悬浮在某个元素上时,会给出相应的提示信息,此交互有助于用户直观地看到当前实例或实例组的属性详细信息。
[0245]
过滤:由于模型调参是一个多次重复的操作,在这个过程中会生成大量的模型快照,在有限的屏幕尺寸内无法对快照进行很好的保留,当视图发生拥挤时,用户可以通过双击快照,对快照进行删除。若想要恢复删除的快照,可在辅助视图中的模型结果视图中选择恢复。
[0246]
重配:重配操作旨在通过改变元素在空间中的编码方式从而提供观察数据的不同视角。柱形图是一个实例组的映射,用户无法通过该视图选择到实例级别。通过重配方式,在用户点击后,重配为像素图,像素图中的每个点为一个实例,该交互可帮助用户对比实例间的差异。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1