基于注意力引导的多尺度上下文信息交互的语义分割方法
1.本发明属于数字图像处理技术领域,具体涉及一种基于注意力引导的多尺度上下文信息交互的语义分割方法。
背景技术:
2.图像语义分割的研究目标是获取图像中的每个像素的类别标签,它是场景理解的先验任务,而场景理解则是基于分割,获取图像内所有像素的类别标签。面向街道场景的图像语义分割在智能驾驶、智慧交管等领域都表现出极其重要的应用价值。基于深度学习的语义分割只需要输入数据,就可以通过输入和输出的非线性映射与反向传播机制自动提取图像中的各层特征,通过网络学习到的特征表达能力更强。图像中从底层特征到高层特征的所有特征都利于语义分割,但是深度学习方法受限于模型深度,因此同时提取边缘信息和强结构信息比较困难,提取特征时难免顾此失彼,尤其使在面向街道场景的语义分割中出现小尺度目标丢失、相似性目标难以精准分割的问题。
技术实现要素:
3.本发明的目的是提供一种基于注意力引导的多尺度上下文信息交互的语义分割方法,解决了现有技术中存在的街道场景语义分割中的多尺度分割受限和单一的串行连接导致的类内分割不一致问题。
4.本发明所采用的技术方案是,基于注意力引导的多尺度上下文信息交互的语义分割方法,具体按照以下步骤实施:
5.步骤1、将公共数据集camvid中所有图像数据划分为训练集、验证集及测试集,然后对训练集的所有图像数据进行数据增强和预处理操作;
6.步骤2、使用残差结构构造resnet50网络模型;使用注意力机制和深度可分离卷积构造注意力引导模块,使用全局平均池化构造池化单元;
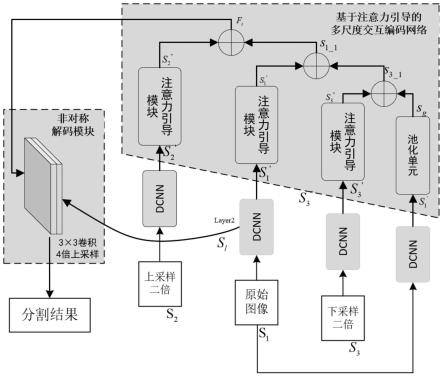
7.步骤3、首先将城市场景图像s1上采样二倍和下采样二倍,得到图像s2和s3,然后使用resnet50模型提取s1,s2,s3的深度特征,记为s1′
,s2′
,s3′
,提取s1的第三层特征记为s
l
,最后使用基于注意力引导的多尺度交互编码网络提取图像的多尺度特征fs;
8.步骤4、将多尺度特征fs与s1的第三层特s
l
依次进行拼接、卷积和四倍上采样积操作,逐渐恢复图像分辨率,最终输出语义分割的结果;
9.步骤5、使用训练集和验证集对模型进行训练,在测试集上验证模型的分割效果。
10.本发明的特点还在于,
11.步骤1具体按照以下步骤实施:
12.步骤1.1、将camvid数据集的图像数据按照4∶1∶3的比例划分为训练集、验证集及测试集;
13.步骤1.2、对于验证集和测试集的所有图像数据首先使用随机裁剪和随机旋转的方法进行数据增强,然后缩使用双线性插值对图像预处理,将图像缩放到513
×
513像素。
14.步骤2具体按照以下步骤实施:
15.步骤2.1、构造残差模块:首先使用64个1
×
1的卷积和relu函数降维,然后使用3
×
3的卷积和relu函数提取特征,最后使用256个1
×
1的卷积和relu函数恢复维度;
16.步骤2.2、resnet50的结构表,首先使用64个7
×
7、步长为2的卷积提取特征,然后使用16个残差模块,其中残差结构使特征矩阵隔层相加;
17.步骤2.3、使用深度卷积单元和注意力头单元构造注意力引导模块,深度卷积单元首先使用全局平均池化层提取resnet50输出特征图x的通道维的平均值x',然后使用两组深度可分离卷积单元提取x'的深度特征x”,深度可分离卷积单元的组成依次为3
×
3逐深度卷积层、批归一化层、relu激活层、3
×
3逐点卷积层、批归一化层、relu激活层,最后对x”使用二倍上采样得到特征x”';
18.步骤2.4、注意力引导模块中的注意力头单元首先使用两组注意模块计算x'的通道注意力图y,注意模块组成为3
×
3卷积层、批归一化层、relu激活层,然后对通道注意力图y使用1
×
1卷积和sigmoid激活得到特征y',最后将特征y'和步骤2.3中的特征x”逐元素相乘得到注意力引导模块的输出特征;
19.步骤2.5、构造池化单元,对输入的特征图x依次使用全局平均池化、1
×
1卷积、批归一化、relu激活得到输出特征图xg。
20.步骤2.1、2.3、2.4、2.5中,relu激活函数的定义如公式(1)所示:
21.relu(x)=max(0,x)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
22.其中,x表示输入数据,max()函数返回输入数据中的最大值;
23.步骤2.4中sigmoid激活函数定义如式(2)
[0024][0025]
其中,x表示输入数据。
[0026]
步骤3具体如下:
[0027]
步骤3.1、首先将城市场景图像s1上采样二倍和下采样二倍,得到图像s2和s3;然后使用resnet50模型提取s1,s2,s3的深度特征,记为s'1,s'2,s'3,提取s1的第三层特征记为s
l
;最后对深度特征s'1使用池化单元得到特征sg;
[0028]
步骤3.2、将深度特征s'1,s'2,s'3分别使用所述步骤2的注意力引导模块计算通道注意力权重,得到特征s”1
,s”2
,s”3
;然后将特征sg与特征s”3
逐元素相加得到特征s
3_1
,将特征s
3_1
与特征s”1
逐元素相加得到特征s
1_1
,最后将s
1_1
与s”2
逐元素相加得到多尺度特征fs。
[0029]
步骤4具体如下:
[0030]
首先将多尺度特征fs与城市场景图像s1的第三层特征s
l
按照通道维度拼接得到特征fs',然后对特征fs'使用3
×
3卷积和四倍上采样得到语义分割的结果。
[0031]
步骤5具体如下:
[0032]
使用camvid数据集的训练集的图像数据训练模型,共训练110100次,每训练367次使用平均交并比miou评估验证集的精度;训练模型使用交叉熵损失函数l
ce
,初始学习率设置为0.0005,采用多项式衰减策略。经过训练,本方法在cityscapes测试集上的平均交并比为74.02%。
[0033]
步骤5中,交叉熵损失函数l
ce
的定义如式(3):
[0034][0035]
其中,n表示类别总数12;n表示当前类别,n∈{0,1,...,11};p是当前像素每种类别的模型输出的概率值;代表当前像素的真实标签值;
[0036]
使用的平均交并比miou的定义如(4):
[0037][0038]
其中,k是除背景外其余类别个数,p
ij
表示类别i但被推断为类别j的像素数量,k=11,i,j∈{0,1,...,k}。
[0039]
本发明的有益效果是,基于注意力引导的多尺度上下文信息交互的语义分割方法,通过一种链式连接结构使网络关注于相邻尺度特征的相对注意力,而不是同时计算所有尺度的注意力,这样可以减轻训练时的负担,便于模型收敛;本发明方法使用了一种注意力引导模块在不同尺度上对像素特征编码,有利于多尺度对象分段,通过捕获远距离的依赖从而提高类内一致性,该模块可以视为小型编码解码结构增加网络深度,提高模型学习能力。因此,本发明方法可以有效解决街道场景图像中多尺度对象难以分割和同一类别内部分割不一致的问题。
附图说明
[0040]
图1是本发明注意力引导的非对称语义分割方法的流程图;
[0041]
图2是本发明注意力引导的非对称语义分割方法中使用的注意力引导模块结构的示意图;
[0042]
图3是本发明注意力引导的非对称语义分割方法中使用的注意力头单元的实现细节;
[0043]
图4是本发明注意力引导的非对称语义分割方法中使用的池化单元的示意图;
[0044]
图5本发明实施例中测试集中随机取得的第一幅原图像和第二幅原图像与分割结果的对比图。
具体实施方式
[0045]
下面结合附图和具体实施方式对本发明进行详细说明。
[0046]
本发明基于注意力引导的多尺度上下文信息交互的语义分割方法,流程图如图1所示,具体按照以下步骤实施:
[0047]
步骤1、将公共数据集camvid中所有图像数据划分为训练集、验证集及测试集,然后对训练集的所有图像数据进行数据增强和预处理操作;
[0048]
步骤1具体按照以下步骤实施:
[0049]
步骤1.1、将camvid数据集的图像数据按照4∶1∶3的比例划分为训练集、验证集及测试集;
[0050]
步骤1.2、对于验证集和测试集的所有图像数据首先使用随机裁剪和随机旋转的方法进行数据增强,然后缩使用双线性插值对图像预处理,将图像缩放到513
×
513像素。
[0051]
步骤2、使用残差结构构造resnet50网络模型;使用注意力机制和深度可分离卷积构造注意力引导模块,使用全局平均池化构造池化单元;
[0052]
结合图2~图4,步骤2具体按照以下步骤实施:
[0053]
步骤2.1、构造残差模块:首先使用64个1
×
1的卷积和relu函数降维,然后使用3
×
3的卷积和relu函数提取特征,最后使用256个1
×
1的卷积和relu函数恢复维度;
[0054]
步骤2.2、resnet50的结构表,如表1所示,首先使用64个7
×
7、步长为2的卷积提取特征,然后使用16个残差模块,其中残差结构使特征矩阵隔层相加;是一种短路连接。
[0055]
表1 resnet50的结构信息表
[0056][0057]
步骤2.3、使用深度卷积单元和注意力头单元构造注意力引导模块,深度卷积单元首先使用全局平均池化层提取resnet50输出特征图x的通道维的平均值x',然后使用两组深度可分离卷积单元提取x'的深度特征x”,深度可分离卷积单元的组成依次为3
×
3逐深度卷积层、批归一化层、relu激活层、3
×
3逐点卷积层、批归一化层、relu激活层,最后对x”使用二倍上采样得到特征x”';
[0058]
步骤2.4、注意力引导模块中的注意力头单元首先使用两组注意模块计算x'的通道注意力图y,注意模块组成为3
×
3卷积层、批归一化层、relu激活层,然后对通道注意力图
y使用1
×
1卷积和sigmoid激活得到特征y',最后将特征y'和步骤2.3中的特征x”逐元素相乘得到注意力引导模块的输出特征;
[0059]
步骤2.5、构造池化单元,对输入的特征图x依次使用全局平均池化、1
×
1卷积、批归一化、relu激活得到输出特征图xg。
[0060]
步骤2.1、2.3、2.4、2.5中,relu激活函数的定义如公式(1)所示:
[0061]
relu(x)=max(0,x)
ꢀꢀꢀꢀꢀꢀꢀ
(5)
[0062]
其中,x表示输入数据,max()函数返回输入数据中的最大值;
[0063]
步骤2.4中sigmoid激活函数定义如式(2)
[0064][0065]
其中,x表示输入数据。
[0066]
步骤3、首先将城市场景图像s1上采样二倍和下采样二倍,得到图像s2和s3,然后使用resnet50模型提取s1,s2,s3的深度特征,记为s1',s2',s3',提取s1的第三层特征记为s
l
,最后使用基于注意力引导的多尺度交互编码网络提取图像的多尺度特征fs;
[0067]
步骤3具体如下:
[0068]
步骤3.1、首先将城市场景图像s1上采样二倍和下采样二倍,得到图像s2和s3;然后使用resnet50模型提取s1,s2,s3的深度特征,记为s'1,s'2,s'3,提取s1的第三层特征记为s
l
;最后对深度特征s'1使用池化单元得到特征sg;
[0069]
步骤3.2、将深度特征s'1,s'2,s'3分别使用所述步骤2的注意力引导模块计算通道注意力权重,得到特征s”1
,s”2
,s”3
;然后将特征sg与特征s”3
逐元素相加得到特征s
3_1
,将特征s
3_1
与特征s”1
逐元素相加得到特征s
1_1
,最后将s
1_1
与s”2
逐元素相加得到多尺度特征fs。
[0070]
步骤4、将多尺度特征fs与s1的第三层特s
l
依次进行拼接、卷积和四倍上采样积操作,逐渐恢复图像分辨率,最终输出语义分割的结果;
[0071]
步骤4具体如下:
[0072]
首先将多尺度特征fs与城市场景图像s1的第三层特征s
l
按照通道维度拼接得到特征fs',然后对特征fs'使用3
×
3卷积和四倍上采样得到语义分割的结果。
[0073]
步骤5、使用训练集和验证集对模型进行训练,在测试集上验证模型的分割效果。
[0074]
步骤5具体如下:
[0075]
使用camvid数据集的训练集的图像数据训练模型,共训练110100次,每训练367次使用平均交并比miou评估验证集的精度;训练模型使用交叉熵损失函数l
ce
,初始学习率设置为0.0005,采用多项式衰减策略。经过训练,本方法在cityscapes测试集上的平均交并比为74.02%。
[0076]
步骤5中,交叉熵损失函数l
ce
的定义如式(3):
[0077][0078]
其中,n表示类别总数12;n表示当前类别,n∈{0,1,...,11};p是当前像素每种类别的模型输出的概率值;代表当前像素的真实标签值;
[0079]
使用的平均交并比miou的定义如(4):
[0080][0081]
其中,k是除背景外其余类别个数,p
ij
表示类别i但被推断为类别j的像素数量,k=11,i,j∈{0,1,...,k}。
[0082]
图5是本方法在公开数据集camvid的测试集上的语义分割结果。从场景1中可以看出,本方法实现了目标的精细分割,例如分割结果图像的车身轮廓边缘与轮胎边缘分割地较为精准;场景2中可以看出本方法实现了小目标的细节准确预测,例如完整地分割了路灯杆的细节与远处车辆的结构。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1