一种基于指针网络的刑事案情实体关系联合抽取方法与流程
1.本发明属于自然语言处理领域,涉及到一种基于指针网络的刑事案情实体关系联合抽取方法。
背景技术:
2.现代信息技术正在推动司法领域的深刻变革,以人工智能司法应用、司法大数据为核心的“智慧法院建设”被置于同司法体制改革并行的地位。人工智能在案例智能推送、裁判结果预测、裁判文书自动生成等方面的应用,已成为地方法院探索人工智能司法 应用最活跃的领域。国务院发布的《新一代人工智能发展规划》将“智慧法院建设”纳入其中,这标志着人工智能司法应用已上升为国家战略。着眼当前,基层执法办案依然面临“案多人少”、执法能力与社会需求、执法公正与执法效率等一系列矛盾。若把大数据、人工智能与司法体制改革结合起来,将会给司法工作注入前所未有的创造力。
3.信息抽取作为一种人工智能相关技术,能够将非结构化文本转成人们所需要的结构化文本信息,在智慧司法领域应用广泛。而实体关系抽取作为信息抽取一项关键任务,也是自然语言处理研究的热门之一。目前,实体关系抽取分为pipeline方式和联合抽取方式两种。pipeline方式即先进行实体识别,再进行关系分类,两个过程是分开、没有交互的。联合抽取方式则通过实现实体识别和关系分类这两个过程的参数共享,使这两个过程的信息能够交互,从而提高抽取性能。
4.在司法领域应用实体关系抽取,其中一个重要方向是梳理案件情节信息,主要从询问笔录、起诉书、起诉意见书、刑事判决书等不同类型文书抽取出相关实体以及实体间的关系信息,帮助检察办案人员快速了解案件脉络。针对司法领域案件数据特征,特别涉及人数众多的复杂案件,其中的案件人物关系错综复杂,存在相同实体存在多种关系、不同实体存在相同关系的情况,即“一对多”的关系重叠问题、“多对一”的实体重叠问题。
5.因此,需要一种基于指针网络的刑事案情实体关系联合抽取方法,有效依据司法领域案件数据特点解决实体关系抽取问题。
技术实现要素:
6.本发明主要解决的技术问题在于在刑事案件审判过程中,存在案情复杂、案件涉及人物众多时,人物关系难以梳理等问题,同时针对司法领域“案多人少”问题,本发明提供一种基于指针网络的刑事案情实体关系联合抽取方法。
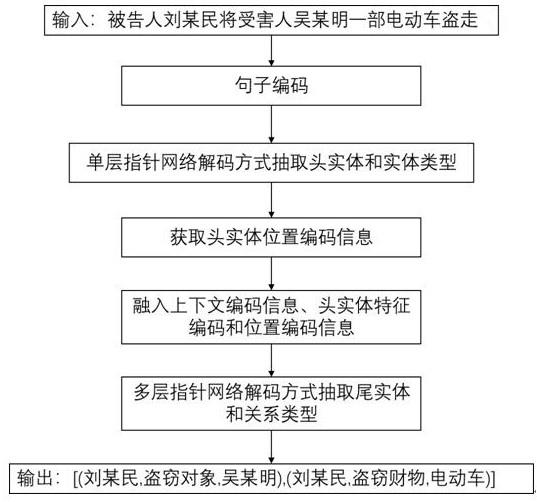
7.为达到上述目的,本发明的技术方案如下:将刑事案情实体关系抽取看作三元组抽取问题,即先抽取头实体,在通过头实体相关信息抽取尾实体和关系,具体先对法律文书中对案情描述部分的目标文本进行编码,再通过单层指针网络解码方式抽取头实体;接着融入上下文编码信息和头实体位置编码信息,最后通过多层指针网络解码方式抽取尾实体和关系。
8.本发明的一种基于指针网络的刑事案情描述实体关系联合抽取方法,包括如下步
骤:1)获取刑事案件裁判文书原始语料,提取案情描述文本并进行标注;2)采用预训练模型对案情描述文本进行特征编码;3)利用单层指针网络解码方式抽取头实体;4)利用多层指针网络解码方式抽取尾实体和关系。
9.作为本发明的一种改进,所述步骤1)中,首先从原始刑事案件裁判文书中提取案情描述相关文本信息;接着设置实体关系标注规则,依据规则对案情描述文本进行数据标注,具体步骤是先标记出头实体和头实体标签,接着根据每一个头实体分别标记出对应的尾实体和对应关系。最后将标注好的数据划分训练集和测试集,用于后续模型训练。
10.作为本发明的一种改进,所述步骤2)中,采用bert预训练模型对待抽取的文本数据进行特征编码,编码结果对头实体抽取、尾实体和关系抽取两个任务共享。其中采用共享编码参数的联合抽取方式能够缓解非联合抽取方式带来的误差传播的问题。
11.作为本发明的一种改进,所述步骤3)中,用单层指针网络解码方式抽取头实体,抽取结果以(entity1,tag1)实体对的形式输出,其中entity1表示头实体名称,tag1表示头实体类型,具体步骤如下:3.1预测头实体开始位置,头实体开始位置和位置标签计算如公式如下:(1)其中表示位置的字符属于实体开始位置的概率,在此步骤中实体具体表示为头实体;表示案情描述文本特征编码;表示字符的标签信息,此步骤中标签信息具体表示头实体类型;表示待带学习参数;为设置的阈值;3.2预测头实体结束位置,头实体结束位置和位置标签计算如公式如下:(2)其中表示位置的字符属于实体结束位置的概率,在此步骤中实体具体表示为头实体;表示融合了实体开始位置信息的文本特征编码,具体表示为,其中计算公式如(3):
(3)其中表示当前位置;表示头实体开始位置;c为常数;表示字符的标签信息,在此步骤中标签信息具体表示为头实体类型;表示待带学习参数;为设置的阈值;3.3获取头实体和头实体类型,通过公式(1)和(2)获取头实体的开始、结束位置以及对应头实体类型,遍历所有的,当时,对应位置间的文本内容及为头实体,最终结果输出为,其中表示头实体,表示头实体标签。采用单层指针网络解码方式获取头实体,可以有效解决头实体重叠问题,即存在多个头实体且头实体之间存在部分重合。
12.作为本发明的一种改进,所述步骤4)中,采用多层指针网络解码方式抽取尾实体和关系,输出形式仍是,其中表示尾实体, 表示关系类型,具体步骤如下:4.1获取头实体位置编码信息,本发明采用三角函数式位置编码方式,计算公式如下:(4)pe是二维矩阵,其中行表示词,列表示词向量;分别表示在每个词的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此完成位置编码的计算,其中表示头实体在文本中的位置;表示词向量的第维;表示词向量维度;4.2获取尾实体和关系类型,依据步骤3)中获取的头实体,从步骤2)中得到的案情描述文本特征编码中抽取头实体的特征编码,再融入上下文特征编码,即案情描述文本特征编码、头实体位置编码,最终得,具体表示为,将代入公式(1)获取实体开始位置概率和对应标签信息,此步骤中实体具体表示尾实体、标签信息具体表示对应关系类型;再根据公式(2)获取实体结束位置概率和对应标签信息,此步骤中
实体具体表示尾实体、标签信息具体表示对应关系类型,遍历所有的,当时,对应位置间的文本内容及为预测的尾实体,最终输出形式为,其中表示尾实体, 表示关系类型;在针对头实体抽取对应尾实体和关系时,采用了上下文编码、头实体特征编码和头实体位置编码多种方式加强了对当前头实体的感知能力,能够有效地提高尾实体和关系抽取地准确性。采用多层指针网络解码方式获取尾实体和关系类型,即每一层是一个关系对应的尾实体,能够解决使用单层指针网络解码方式无法抽取多种关系的问题,即一对多(单一的头尾实体对对应多种关系)问题;4.3损失函数计算,通过指针网络的解码方式获取到头实体、尾实体和关系类型,在模型训练过程中,损失函数定义为头实体和头实体类型抽取、尾实体和关系类型抽取两个任务的加权求和,计算公式如下:(5)其中,表示任务在时刻的权重;表示任务的损失。
13.对不同任务损失函数赋值可动态调节的权重,进行加权求和的方式有效解决刑事案件中存在的关系类别不均衡问题。
14.相对于现有技术,本发明的优点如下:1. 传统实体关系抽取是采用pipeline的方式,即先抽取实体,再抽取关系,pipeline的方式忽略了这两个任务的内在关联关系,同时存在没有关系的候选实体对所带来的冗余信息问题,增加计算复杂度且提升错误率。而本发明提出的实体关系联合抽取方法,对两个任务进行统一建模,共享参数,利用两个任务间的潜在关联信息,有效缓解误差传播;2.传统的实体关系抽取先识别实体,再对识别出来的实体进行关系分类,且一般采用bilou的序列标注框架,此方法每个token只能属于一种类型,不能有效的处理实体重叠、多对一(多个头尾实体对应一种关系)或一对多(单一的头尾实体对对应多种关系)等问题。而本发明提出的基于指针网络的解码方式,将实体抽取转化为两个n元softmax分类预测实体的首尾指针位置,解决了实体重叠问题;同时本发明提出的将实体关系联合抽取看成spo问题,先抽取头实体s再抽取尾实体o和关系p,能够解决一对多和多对一的问题;3.传统实体关系联合抽取模型中损失函数为两个任务的损失和,如此会导致多任务学习会被某个任务所主导或学偏,本发明提出将模型中的损失定义为动态可调节的,可以有效解决因数据中关系类别不均衡所导致的学习效果差的问题。
附图说明
15.图1是基于指针网络的刑事案情实体关系联合抽取方法流程图;图2是实体关系标注规则示意图;
图3是实体关系联合抽取模型结构图。
具体实施方式
16.为了加深对本发明的认识和理解,下面结合附图详细的介绍本方案。
17.实施例1:一种基于指针网络的刑事案情实体关系联合抽取方法,方法流程图如图1所示,具体包括如下步骤:1.获取刑事案件裁判文书原始语料,提取案情描述文本并进行标注,数据预处理是模型训练的第一步,获取刑事案件裁判文书原始语料并提取案情描述文本后,设置实体关系标注规则,并按此规则对数据中实体关系进行标注,标注规则示意图如图2所示。实体关系标注分为两步,第一步先标记出头实体位置和头实体标签,第二步标记尾实体位置和对应关系。
18.第一步中,生成大小的空矩阵,其中为待抽取文本长度,第一维中在实体的开始位置处标记头实体标签信息t,其余位置标记o,即在“刘某民”中“刘”的位置标记t,t表示“被告人”实体类型;第二维中在实体的结束位置处标记头实体标签信息t,其余位置标记o,即在“刘某民”中“民”的位置标记t。同理第二步中,针对关系类型r1,r1表示盗窃对象,在“吴某明”中“吴”的位置标记r1,在“吴某明”中“明”的位置标记r1;针对关系类型r2,r2表示盗窃财物,在“电动车”中“电”的位置标记r2,在“电动车”中“车”的位置标记r2。
19.2.采用预训练模型对案情描述文本进行特征编码;首先用序列表示原始文本句子,其中到表示句子中第1到第个字的id,表示案情描述长度;接着用bert预训练模型对句子进行编码,隐藏层输出向量表示案情描述文本特征编码,如图3中表示的embedding;3.利用单层指针网络解码方式抽取头实体,3.1 预测头实体开始位置,如公式(1)所示:(1)其中表示位置的字符属于实体开始位置的概率,在此步骤中实体具体表示为头实体;表示案情描述文本特征编码;表示字符的标签信息,此步骤中标签信息具体表示头实体类型;表示待带学习参数;为设置的阈值;3.2预测头实体结束位置,如公式(2)所示:
(2)其中表示位置的字符属于实体结束位置的概率,在此步骤中实体具体表示为头实体;表示融合了实体开始位置信息的文本特征编码,具体表示为,其中计算公式如(3):(3)其中表示当前位置;表示头实体开始位置;c为常数;表示字符的标签信息,在此步骤中标签信息具体表示为头实体类型;表示待带学习参数;为设置的阈值;3.3获取头实体和头实体类型,通过公式(1)和(2)获取头实体的开始、结束位置以及对应头实体类型,遍历所有的,当时,对应位置间的文本内容及为头实体,最终抽取结果以实体对的形式输出,其中表示头实体,表示头实体标签,如图3所示,具体输出(刘某民,被告人),其中“刘某民”是头实体,“被告人”是头实体类型;4.利用多层指针网络解码方式抽取尾实体和关系,4.1获取头实体位置编码信息,本发明采用三角函数式位置编码方式,计算公式如下:(4)pe是二维矩阵,其中行表示词,列表示词向量;分别表示在每个词的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此完成位置编码的计算,其中表示头实体在文本中的位置;表示词向量的第维;表示词向量维度;4.2获取尾实体和关系类型,
依据步骤3)中获取的头实体,从步骤2)中得到的案情描述文本特征编码中抽取头实体的特征编码,再融入上下文特征编码,即案情描述文本特征编码、头实体位置编码,最终得,具体表示为,将代入公式(1)获取实体开始位置概率和对应标签信息,此步骤中实体具体表示尾实体、标签信息具体表示对应关系类型;再根据公式(2)获取实体结束位置概率和对应标签信息,此步骤中实体具体表示尾实体、标签信息具体表示对应关系类型,遍历所有的,当时,对应位置间的文本内容及为预测的尾实体,最终输出形式为,其中表示尾实体, 表示关系类型,如图3所示,具体输出(吴某明,盗窃对象),其中“吴某明”是尾实体,“盗窃对象”是关系类型。
20.在模型测试阶段,整合步骤3.3和步骤4.2的输出结果,即可以获取刑事案情实体关系联合抽取结果(刘某民,盗窃对象,吴某明);4.3损失函数计算,通过指针网络的解码方式获取到头实体、尾实体和关系类型,在模型训练过程中,损失函数定义为头实体和头实体类型抽取、尾实体和关系类型抽取两个任务的加权求和,计算公式如下:(5)其中,表示任务在时刻的权重;表示任务的损失。
21.需要说明的是上述实施例仅仅是本发明的较佳实施例,并没有用来限定本发明的保护范围,在上述技术方案的基础上做出的等同替换或者替代,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1