一种基于全局注意力的自监督单目深度估计算法
1.本发明提出一种基于全局注意力的自监督单目深度估计算法,解决卷积只能计算局部像素相关性的问题,提高了对于特征图的深度预测的准确性。属于数字图像处理领域。
背景技术:
2.在数字图像处理中,深度图是研究的关键问题之一。在自动驾驶等领域中,预测行人等周边环境距离车辆的远近是至关重要的,因此也突显出了本研究的重要性。
3.对于不具有大的无语义区域的图片,常规的深度估计方法可以取得很好的估计精度。但是对于具有大的无语义区域以及无清晰的边界的图片,以往的精度都不太理想。这些方法在kitti、make3d等数据集上的检测结果来看,对于其中的上述图片产生的深度图较为模糊,精度较低。由此可以说明此前方法对于边界以及大的无语义区域缺少更精确的估计。边界和无语义区域成为制约单目深度估计的关键问题,越来越多的学者对此展开了研究,通过研究卷积神经网络低层特征和高层特征的信息特点,使用不同层的特征输出其深度图,得出了不同特征层具有不同的贡献的结论,即高层特征可以表达整幅图像的语义环境和物体的边界等信息,而低层特征经过卷积之后,可以表达一些说不清的更抽象化的特征。本文发明主要针对编解码器之间的语义差距过大,以及传卷积网络无法建立远程相关性问题,提出了基于全局空间注意力自监督网络,是网络产生的深度图更具有全局性和一致性,提高了深度预测精度。
技术实现要素:
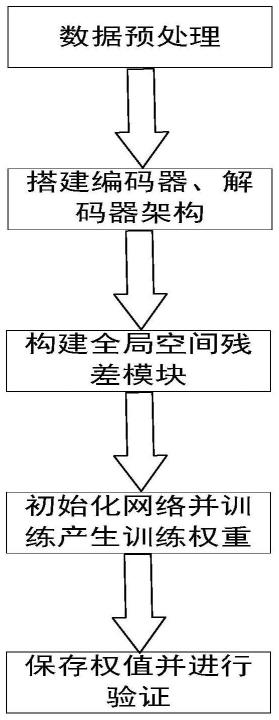
4.针对上述问题,本发明的是一种基于全局注意力的自监督单目深度估计算法,通过使用空间注意力网络改进原始u-net网络编解码器语义差距过大问题,增强网络对于不同层次特征的利用,增强了网络对于边界等区域等的预测精确度,发明基本流程如图1所示。
5.本发明采取如下技术方案:一种基于改进u-net的自监督单目深度估计算法包括如下步骤:
6.1)构建由卷积层和池化层所组成的编码器来提取不同分辨率图像特征,充分利用不同尺度的特征信息;
7.2)构建由卷积层、上采样层组成的解码器来利用接收到的编码器层特征,从而生成精密的深度图;
8.3)通过将编码器的不同分辨率信息通过基于全局空间注意力模块,从而构建编解码器之间的联系,以减少语义差距;
9.4)通过逐像素平滑度损失和图像重投影损失结合来优化模型。
10.本发明由于采取以上方法,其具有以下优点:
11.1、通过使用全局空间注意力模块增强重要像素的全局信息;
12.2、改进原有的编码器和解码器的连接方式,降低了网络的复杂度。
13.3、在保证速度的同时有效提高检测精度,尤其是对语义边界不明显的图片。
附图说明
14.图1本发明基本流程图;
15.图2改进的u-net结构;
16.图3全局空间注意力模块结构图;
17.图4本发明网络整体改进后实验效果;
具体实施方式
18.下面结合说明书附图通过一个实例对本发明做进一步说明,本实例仅为本发明其中的一种应用实例。
19.步骤1)获取kitti数据集的44234张图像,其中分为训练集39810张和测试集4424张,对所有图像使用相同的处理,将相机的主点设置为图像中心,焦距设置为kitti中所有焦距的平均值。对于立体和混合训练(单目加立体),将两个立体帧之间的转换设置为纯固定长度的水平平移。
20.本发明的编码器解码器网络是在u-net的基础上改进,如图2所示,具体步骤为:
21.s11)将输入大小为640
×
192的特征图输入到编码器网络中,通过第一层3
×
3卷积,通道数变为64,图像大小变为320
×
96;通过第二层卷积通道数变为64,图像大小变为160
×
48;通过第三层卷积通道数变为128,图像大小变为80
×
24;通过第三层卷积通道数变为256,图像大小变为40
×
12;通过第四层卷积通道数变为512,图像大小变为20
×
6。
22.s12)如果输入为多张图片,即当采用单目视频序列时,图片数量为三张,分别为第0帧、第1帧和第2帧,当采用立体图像对为输入时,图片数量为两张,分别是左右图像对。此时初始输入通道数由3变为3
×
图片数量,并通过一层卷积核大小为7的卷积层。
23.步骤2)首先接收来自解码器端的大小为20
×
6,通道数为512的特征图;经过第一层卷积和上采样层通道数变为256,图像大小为40
×
12;经过第二层卷积和上采样层通道数变为128,图片大小为80
×
24;经过第三层卷积层和尚采样层通道数变为64,图片大小变为160
×
48;经过第四层卷积和上采样层通道数变为64,图片大小变为320
×
96;在经过两层卷积层和一层上采样层,输出和原图大小相同的深度图。
24.s31)因为考虑到浅层特征有更清晰的边界和边缘信息,而深层特征具有更明确的语义信息,因此采用了基于全局空间注意力的网络架构方式。
25.s32)全局空间注意力模块参考了transformer的思想设计而成,首先将接收到的特征图分别经过三个并联的卷积,其中两个特征图通道数变为原来的 1/8,再将其reshape成(b,-1,h*w),再将这两个特征图进行矩阵相乘,从而构建全局性像素相关性,将生成的全局相关性矩阵经过softmax函数,将其转换为注意力特征图,最后再将生成的注意力特征图与生成的第三个特征图进行矩阵乘法,经过上述操作后,特征图中的每个像素都具有了全局相关性,最终再将其与输入的特征图相加,构建残差连接。
26.s41)通过采用边缘逐像素平滑度损失让边缘处的像素数值呈梯度式的下降,从而降低了边缘处的误差。
27.s42)采用图像重投影损失,即训练过程中首先将当前帧图像输入深层卷积神经网
络,通过网络得到预测的深度图,然后利用网络得到的深度图和输入的上一帧图像重建出当前帧图像,并计算重建当前帧与真实的当前帧之间的损失函数。
28.在pytorch上实现我们的模型,并在一台tesla v100s显卡上训练它们。我们使用adam optimizer,β1=0.9,β2=0.999。deepthnet和posenet被训练了20个纪元,每批12个。两种网络的初始学习速率均为1
×
10-3,并在15 个周期后以10的倍数衰减。训练序列由三幅连续图像组成。我们将ssim权重设为α=0.85,平滑损失权重设为λ=1
×
10-3。
29.通过整合以上所有改进,形成了本文的网络,本发明的实验对比了 monodepth2网络在kitti数据集上的实验效果,通过abs rel,sq rel,mse, rmse
log
,δ《1.25,δ《1.252,δ《1.253评价指标评估本发明提出的改进网络的性能,如图4所示。
30.本发明的保护范围也并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1