一种基于上下文信息的轻量图像语义分割方法
1.本发明涉及图像分割领域,具体为一种基于上下文信息的轻量图像语义分割方法。
背景技术:
2.图像语义分割技术是计算机视觉领域的热点问题,语义分割是为给定图像中的每个像素分配一个类, 实现了智能设备场景理解。语义分割广泛应用于无人驾驶、医学图像分析、遥感图像、视频监控等领域。 精确的图像语义分割网络是保证以上应用顺利实施的先决条件。虽然随着深度卷积神经网络的不断改进 和迭代,语义分割网络的分割准确率得到极大地提升,但现有的图像语义分割网络仍然面临以下问题: 常规语义分割网络比较复杂,模型的参数量和计算量大,在训练时占用大量的计算资源和存储空间,限 制了图像语义分割的实际应用和落地。
3.通常,减少分割网络运算量有两种方式:缩小输入图像大小和降低模型复杂度。前者可以最大限度 地减少计算量,但这样做会造成大量的细节损失,使得网络不能对图像的上下文信息进行有效的综合考 虑,从而使模型的准确率大大下降。模型的复杂性会削弱模型的特征抽取能力,进而影响到图像的分割 效果。为了将图像语义分割模型应用于各类场景中以及嵌入到低运算、低存储资源设备上,在保持高分 辨图像和降低模型运算量的同时能获得较高的图像语义分割精度是亟需解决的难题。
技术实现要素:
4.针对上述问题,本发明提出一种基于上下文信息的轻量图像语义分割方法,该方法能在保持高分辨 图像和降低模型运算量同时获得较高的图像语义分割精度。本发明内容如下:
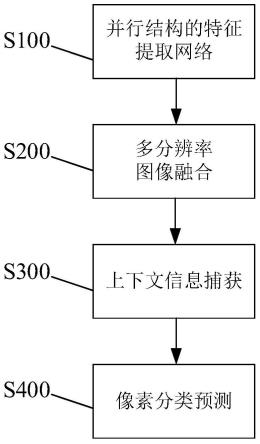
5.s100.采用并行结构的轻量化卷积神经网络提取输入图像的多尺度特征图,得到四个子特征图;
6.s200.将获得的得到四个子特征图输入至多分辨率图像融合模块,得到融合特征图f1;
7.s300.融合特征图f1输入至上下文信息模块,计算目标物体与像素之间的关系,增强上下文特征表 达能力,输出大小为h
×
w的用于图像语义分割的增强特征图f;
8.s400.根据增强特征图f对图像的像素预测分类,最终获得较高质量的图像语义分割结果。
9.本发明具有如下优点:
10.1、本发明的基于上下文信息的轻量图像语义分割方法能在保持高分辨图像和降低模型运算量同时获 得较高的图像语义分割精度;
11.2、本发明提出的上下文信息模块的通用性强,既能与并行结构的特征提取网络组合使用,也能与串 行结构的特征提取网络组合使用,弥补轻量化图像语义分割网络在图像
细节的损失。
附图说明
12.图1是一种基于上下文信息的轻量图像语义分割方法的步骤流程图;
13.图2是并行结构轻量化网络hrnet的结构图;
14.图3是多分辨率图像融合模块结构图;
15.图4是上下文信息模块结构图;
具体实施方式:
16.以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示 的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本 说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
17.图1为本发明一种基于上下文信息的轻量图像语义分割方法的步骤流程图。一种基于上下文信息的 轻量图像语义分割方法,包括如下步骤:
18.s100.采用当前主流的并行结构轻量化网络hrnet(lightweight hrnet,lhrnet)作为特征提取网 络,提取输入图像的多尺度特征图,得到四个子特征图;
19.s200.将获得的得到四个子特征图输入至结构如图3所示的多分辨率图像融合模块,得到融合的特 征图f1;该多分辨率图像融合模块包括四个输入和一个输出,每个输入对应一个分支;输入一对应最高 分辨率的输入特征图,输入二对应次高分辨率的输入特征图,输入三对应次低分辨率的输入特征图,输 入四对应最低分辨率的输入特征图;输出为融合特征图;对输入二、输入三和输入四进行上采样操作, 恢复得到三个与输入一同等分辨率大小的特征图;将输入一与所述恢复得到的三个与输入一同等分辨率 大小的特征图执行拼接操作,然后执行1
×
1卷积操作得到输出的融合特征图。
20.s300.融合后的特征图f1输入至上下文信息模块,计算目标物体与像素之间的关系,增强上下文特 征表达能力,输出大小为h
×
w的用于图像语义分割的增强特征图f;该上下文信息模块的结构如图4 所示,输入的通道数、大小为c
×h×
w的特征图经过1
×
1卷积得到目标类别数、大小为c2
×h×
w的 粗略初始分割图;同时将输入特征图进行3
×
3卷积得到通道数、大小为c1
×h×
w深层像素表示特征图, 其中,c,c1表示通道数,h、w分别表示特征图的高宽,c2表示目标类别数;然后,采用softmax函数 对所述的初始分割图进行归一化,与所述的深层像素表示特征图相乘得到目标类别区域特征图c1
×
c2; 第三,通过对所述深层像素表示特征图与所述目标类别区域特征图进行1
×
1卷积处理,获得特征图q, 所述目标类别区域特征图进行1
×
1卷积处理得到特征图k,所述目标类别区域特征图进行1
×
1卷积处理 得到特征图v,按照公式(1)计算特征图q、k、v之间的关联性得到关联矩阵x,式中,dk为通道数, 其与卷积得到特征图k的通道数相同;利用关联矩阵x对目标区域特征进行加权求和,得到目标上下文 特征图,之后拼接所述的目标上下文特征图和所述的深层像素表示特征图得到增强特征图,以预测每一 个像素的语义类别。
21.22.s400.根据增强特征图f对图像的像素预测分类,最终获得较高质量的图像语义分割结果。
23.实例:
24.为了证明基于上下文信息的轻量图像语义分割方法的性能和效率具有优势,本发明通过以下实验进 行验证与分析。
25.a、实验数据
26.本发明在pascal voc 2012,cityscapes和ade20k三个数据集上进行实验。cityscapes是一个城 市街道的驾驶场景数据集,ade20k是一个场景丰富的数据集,单张场景图中物体多,有不同的场景布 局。pascal voc 2012是一个普通的场景数据集。cityscapes包含5000张精细注释的图像,图像分辨率为 1024
×
2048。它们被分成979,500和1,525张图像的训练集、验证集和测试集。cityscapes共有30个类, 其中19个类用于语义分割的训练和评估。ade20k包含室内室外的图像,总共包含25000张图像,其 中2万张用于训练,2000张用于验证,2000张用于测试。数据集中有150个类。pascal voc 2012包括 20个对象类别和一个背景类别。它包含1464张用于训练的图像和1449张用于验证的图像,1456张用于 测试的图像。
27.b、实验平台
28.硬件:cpu intel xeon e5-2650v3,内存64g,tesla t4gpu,显存16g,硬盘4tb 7200转/分。
29.软件:操作系统ubuntu 16.04,实验平台pytorch1.5.0,标准统一的语义分割框架mmsegmentation。
30.c图像语义分割评估标准
31.平均交并比(mean intersection over union,miou)、模型参数量和计算量(floating point operations, flops),以用于评估模型分割精度、模型空间复杂度和模型时间复杂度。
32.d.实验细节
33.在实验中,将cityscapes数据集的原始图像裁剪到512
×
1024尺寸大小,pascal voc2012aug和 ade20k数据集的原始图像裁剪到512
×
512尺寸大小作为网络的输入图像。
34.选取交叉熵函数训练和优化网络,交叉熵函数表达式如下所示:
[0035][0036]
网络训练优化算法选取梯度下降算法sgd(stochastic gradient descent),其公式如下:
[0037]wt
=w
t-1
+momentum
×
v-lr
×
δw
ꢀꢀꢀ
(3)
[0038]
式(3)w
t-1
是网络上一次迭代得到的权重值,momentum是动量,设置为0.9,lr是网络学习率, 实验设置为0.001,δw表示一阶导数,v表示初始速度,w
t
表示网络迭代后的新权重值。此优化算法能 很好地贴合训练损失函数下降的趋势,能加快模型的训练速度,现大多数深度学习网络模型都是采用 sgd作为模型的优化器。
[0039]
e.实验结果
[0040]
(1)上下文信息模块的通用性与有效性对比实验
[0041]
①
与主流上下文模块aspp、psp的对比实验
[0042]
为了验证本发明提出的上下文信息模块(ours)的性能,在cityscapes、ade20k和pascalvoc2012三个数据集上将本发明提出的上下文信息模块与主流的上下文模块aspp[38]和psp[33]进行了 性能比较。实验中,选取目前最强串行骨干网络resnet101作为图像特征提取器。从表1、2和3结果看 出,本发明的上下文信息模块在很大程度上优于其他两种上下文模块。在三个数据集上相对于psp(aspp) 分割准确率的增长为1.75%(0.97%),1.74%(1.2%),1.39%(1.06%),而且本发明提出的上下文模块 复杂度最低,在大规模分割数据集上分割效果比其他两种上下文模块更好。这是因为本发明提出的模块 善于学习特征图的全局上下文信息,以获得对图像的全局理解。同时也说明本发明的上下文信息模块可 以插入到串行骨干网络,在多个数据集中各个方面表现优异,具有良好的实用性。
[0043]
表1 cityscapes数据集的分割检测结果
[0044][0045]
表2 ade20k数据集的分割检测结果
[0046][0047]
表3 pascal voc2012数据集的分割检测结果
[0048][0049]
②
上下文信息模块在并行骨干网络中的对比实验
[0050]
本实验在三个数据集上验证本发明上下文模块与新兴的并行结构特征提取网络的适用性和有效性。 选取并行结构hrnet网络作为骨干网络,以证明本模块与并行骨干网
络也具有适用性和有效性。从表4、 5和6结果可以看出本发明的上下文信息模块与并行骨干网络的结合也能达到好的分割效果,同时因并 行骨干网络一直保持高分辨率特征图,使得网络无需构造更深的骨干网络以实现高分割精度,减少了网 络的参数量和运算量。与同类型并行网络相比,虽然lhrnet网络在分割性能上不是最佳,但是在显存 占用、速度和复杂度上是最优的,且基于本发明的上下文信息模块构成的网络属于高分割性能网络。实 际应用角度来说,在显存占用、速度以及精度三个方面综合考虑,本发明方法是最佳选择。实验结果表 明,本发明提出的模块具有通用性且可以应用于不同结构的骨干网络。
[0051]
表4 cityscapes数据集的分割检测结果
[0052][0053]
表5 ade20k数据集的分割检测结果
[0054][0055]
表6 pascal voc2012数据集的分割检测结果
[0056][0057]
(2)与主流图像语义分割方法的对比实验
[0058]
将本发明的基于上下文信息的轻量图像语义分割方法(为方便说明,简称为lscm)与现有主流语 义分割算法在三个数据集上作对比实验,如表7、8和9所示。从表7显示的结果可以看出,本发明的基 于上下文信息的轻量图像语义分割方法在cityscapes数据集上分割结果、推理速度和复杂度三个方面综 合来说最优的。与deeplabv3、semantic fpn和apcnet模型相比参数量以及计算量是最少的。与setr 相比,虽然分割精度低了3.5%,但是在推理速度和参数量分别高了10.15fps、300.16m,模型复杂度和 速度方面是远远高于setr。这是因为setr网络的特征提取网络vit,单一采用vit作为骨干网络能提 高分割率却
会极大地增加网络的复杂度,网络所需的计算资源也相应大幅度增长。从表8和9显示的结 果可以看出,本发明的基于上下文信息的轻量图像语义分割方法在大型复杂场景ade20k数据集和大型 pascal voc2012数据集上模型复杂度最低且具有较好的分割准确率,本发明模型能极大地节约计算资 源,便于更好应用和研究发展。在ade20k数据集上,本发明模型与deeplabv3、ann、danet和gcnet 模型相比参数量以及计算量是最少的。与最高分割率deeplabv3相比,虽然分割精度低了5.23%,但是 在推理速度、运算量以及参数量三个方面分别高了14.21fps、250.89g和61.73m,模型复杂度和速度方 面是远远超于deeplabv3。在pascal voc2012数据集上,本发明网络与deeplabv3、ann、danet 和gcnet模型相比参数量以及计算量是最少的。与gcnet相比,虽然分割精度低了1.41%,但是在推理 速度、运算量以及参数量三个方面分别高了8.2fps、153.51g和43.25m,模型复杂度和速度方面是高于 gcnet。从在三个数据集上的实验结果可以看出本发明网络是高分割性能网络且计算量小。
[0059]
表7 cityscapes数据集语义分割网络实验结果
[0060][0061]
表8 ade20k数据集语义分割网络实验结果
[0062][0063]
表9 pascal voc2012数据集语义分割网络实验结果
[0064][0065]
将本发明的基于上下文信息的轻量图像语义分割方法与轻量语义分割算法进行对比,如表10所示, 可以看出本发明方法具有高分割性能同时也具有较低的参数量。本发明网络在保证低参数量情况下,一 直保留高分辨率的细节特征图,同时融合低高层的特征,更好地学习到来自网络不同分辨率图上的语义 和位置信息,从而获得了好的分割效果。
[0066]
表3. 10 cityscapes数据集轻量语义分割网络实验结果
[0067][0068]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在 本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1