一种基于居民出行特征的交通小区的划分方法
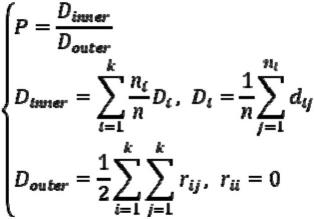
1.本发明主要涉及智能交通技术领域,具体涉及一种基于居民出行特征的交通小区的划分方法。
背景技术:
2.公路交通是目前规模最大、与生产生活联系最为紧密的交通方式。而公路上出现的交通拥堵、交通混乱等现象正是快速增长的交通需求与已有交通供给不匹配的矛盾表现,若不对交通开展合理的规划调整,这一问题将日益凸显。
3.划分交通小区是交通规划中交通需求预测的首要任务。交通小区指交通规划中根据交通源的出行相似性划分所得的集计分析单元,该单元是交通规划中交通调查数据的载体和预测工作的基础,对最终交通规划模型的构建存在着重要的影响。
4.传统交通小区划分多以社会经济属性、人口、土地利用等调查数据为依据,缺乏对交通小区内居民出行特性的考虑。随着大数据及计算机技术的发展,划分交通小区时,相关改进技术逐步将居民出行特征纳入考量,如基于公交刷卡数据获取出行特征,并根据出行相似性进行进行划分的技术等。但此类技术的聚类单元基本都是格网,所划分的交通小区边界与实际城市路网及布局有较大差异,不利于后续交通规划模型的构建。
5.综上,现有交通小区划分主要存在的缺点为:
6.(1)没有考虑交通源的出行特性;
7.(2)划分的交通小区边界与实际道路及行政区划存在较大差异,对后续交通规划模型的构建产生影响。
技术实现要素:
8.针对上述问题,本发明提供一种基于居民出行特征的交通小区划分方法,本方法以路网与行政边界划分聚类单元,结合单元内居民出行特征划分交通小区,在兼顾交通需求主体特性的同时,保证所划的交通小区的边界与实际路网及行政边界相吻合,以满足后续交通规划模型的构建。
9.为实现上述目的,本发明所采取的技术方案为一种基于居民出行特征的交通小区的划分方法,具体步骤如下:
10.步骤1:获取行政区划边界和分等级路网矢量数据,并进行数据预处理;
11.步骤2:基于路网和行政区划划分基本聚类单元;
12.步骤3:建立聚类指标体系,并结合步骤2的聚类单元,通过手机信令获取单元内居民出行特征;
13.步骤4:根据聚类单元所在行政区位置,采用k-means聚类算法初步聚类,得到各聚类数对应的聚类结果及聚类中心;
14.步骤5:针对步骤4所得各聚类数的聚类结果,计算聚类有效性指标;
15.步骤6:比较各聚类数的聚类有效性指标,确定合适聚类数;
16.步骤7:依据步骤6确定的聚类数,通过fcm聚类算法进行最终聚类划分;
17.步骤8:结合主要等级道路,对步骤7所得聚类结果进行修正,完成交通小区划分。
18.优选地,所述步骤1中,基于获取的基础数据,通过arcgis专业软件完成基础的数据处理,包括路网拓扑处理、交叉路口简化等。
19.优选地,所述步骤2中,运用路网对行政区划进行分割,划分出后续步骤中的街道尺度的基本聚类单元。
20.优选地,所述步骤4中,在使用k-means算法进行聚类之前,需要根据区县内居民出行距离分布确定聚类数范围。
21.聚类算法通过代价函数来描述聚类进程,代价函数为:
[0022][0023]
其中,n为样本数,c为划分的簇个数,xi为第i个数据样本,cj为第j个簇的中心,u
ij
表示样本i归属簇j的隶属度,d(xi,cj)为第i个样本到第j个簇的中心的“距离”。考虑聚类单元作为地理空间对象,该“距离”除基本的属性距离外,还应兼顾空间距离,表达式如下,
[0024][0025]
式中,为样本与簇中心的空间距离,其中若样本与簇相邻接,其值为0,否则为样本质心到簇中心质心的空间距离;α为空间效应系数;为样本到簇中心的属性距离,表达式如下,
[0026][0027]
式中,x
im
为样本i的第m个聚类因子,c
jm
为簇j的第m个聚类因子,wm为第m个聚类因子的权重,为样本i与簇j的属性距离。
[0028]
优选地,所述步骤5中,使用综合考虑组内相似性和组间差异性的指标来评价聚类结果,聚类有效性指标表达式如下:
[0029][0030]
其中,d
ij
表示聚类单元j到簇i中心的距离,ni表示第i个簇聚类单元的个数,di表示第i个簇内部到聚类中心的平均距离,n为全部聚类单元数,d
inner
用于表征聚类簇内聚类单元的相似性。r
ij
为簇i聚类中心到簇j中心的距离,d
outer
为全部簇中心两两距离的和,用于表征聚类簇之间的差异性。
[0031]
优选地,所述步骤6中,基于绘制各聚类数、聚类有效性指标图,参考“手肘法”选取最佳聚类数。
[0032]
优选地,所述步骤7中,采用引入模糊概念的fcm算法进行二次聚类,其中隶属度
[0033]uij
∈[0,1],且
[0034]
优选的,所述步骤8中,对聚类结果的修正即筛选等级道路网络中的主干道路,并据此对步骤7中的聚类结果进行二次分割,得到最终的交通小区划分结果。
[0035]
本发明的有益效果体现在:
[0036]
首先,本发明基于路网划分聚类单元,确保了交通小区划分结果边界与实际路网相吻合,更有利于后续交通规划模型的构建与运用。其次,借助于大数据实现聚类单元内居民出行特征的提取,将居民出行特征纳入交通小区划分考量中,满足交通小区内具有相似出行特征这一原则。最后,通过对聚类算法的耦合,一方面解决了传统聚类算法中聚类数难以确定的问题,另一方面提高了交通小区划分结果的鲁棒性。基于本方法划分的交通小区,可支撑后续交通规划模型的构建。
附图说明
[0037]
图1:为本发明的流程框图;
[0038]
图2:为本发明实施例中聚类数-聚类有效性值折线示意图;
[0039]
图3:为本发明实施例中宁波市各区县聚类后结果示意图;
[0040]
图4:为本发明实施例中宁波市最终交通小区划分结果分布示意图。
具体实施方式
[0041]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
本发明的第一实施例具体如下:
[0043]
s1.数据获取与预处理,本实施例获取的是宁波市11个区县的行政区划边界,以及宁波市范围内的包括高速公路、快速路、一级道路、二级道路、三级道路、乡镇级道路和其他道路在内的路网数据。通过arcgis对路网进行交叉路口简化、双线道路转为单线道路、重构拓扑等预处理,使得路网数据满足后续分析的需要。
[0044]
s2.聚类单元划分,通过arcgis分别对宁波市11个区县以路网对各行政区划进行分割,得到以路网或行政区边界为边界的聚类单元。本实施例中,将宁波市共分割为9426个聚类单元,各区县聚类单元数如下表1所示。
[0045]
表1 各区县聚类单元数表
[0046][0047]
s3.居民出行特征获取,在获取居民出行特征前,需要建立聚类指标体系以便在获取数据时有目的性的获取并处理相应数据,同时还需要对各指标赋予相应的权重,用于后续聚类中加权距离的计算。建立聚类指标体系时根据聚类单元的空间特征与出行特征,选取了质心距离、出行次数、出行距离、出行时耗、早、晚高峰和平峰时段出行占比共7项指标,其中空间特征指标可以保证聚类结果中交通小区的连续性,出行特征遵循交通小区内交通源具有相似的交通特征的交通小区的划分原则。其中,早高峰时段定义为6:30-9:30,平峰时段定义为9:30-17:00,晚高峰时段定义为17:00-20:00,各时段出行占比定义如下,
[0048][0049]
式中,ratei表示i时段的出行占比,pi表示i时段的出行人数,p表示全天的出行人数。结合专家系统,针对不同指标对聚类的重要性赋予不同的权重,例如相邻的聚类单元优先考虑聚类,对其空间特征赋予最高权重。具体聚类指标类型及其权重如表 2所示。
[0050]
表2 聚类指标体系及权重表
[0051][0052]
s4.初步聚类,结合s3中获取的各项聚类指标及权重,通过python设计实现k-means 聚类算法,以此对本实施例中s2划分聚类单元按其所属区县进行聚类。在进行聚类前需要确定各区县聚类簇的数目范围,本发明结合各区县中居民出行距离的分布情况,将各区县聚类簇的数目范围设定为[k
min
,k
max
],本实施例中宁波市各区县的聚类数范围如下表3所示。
[0053]
表3 各区县聚类上下限
[0054]
[0055]
s5.聚类数的确定,基于s4中得到的各聚类数对应的聚类结果,依据聚类有效性指标公式,计算各聚类结果的聚类有效性值。
[0056]
s6.确定合适聚类数,根据s5计算的各聚类数对应的聚类有效性值,绘制聚类数-聚类有效性值折线图,本实施例中以江东区为例,其折线图参见附图2,参考“手肘法”确定最佳聚类数k值,得到各区县最佳聚类数,如下表4所示。
[0057]
表4 各区县最佳聚类数
[0058][0059][0060]
s7.依据s6中确定的各区县的聚类数,采用python实现fcm聚类算法,同样以s3中获取的聚类指标体系及权重分别对各区县进行二次聚类,得到最终交通小区聚类结果,本实施例中宁波市各区县聚类后结果参见附图3。
[0061]
s8.聚类结果修正,为对聚类结果做进一步优化,将等级道路(高速公路、快速路、一级道路、二级道路和三级道路)与行政区边界作为交通小区的边界,本实施例以等级道路对 s7中得到的聚类结果进行二次分割修正,最终完成交通小区划分。宁波市各区县交通小区数如下表5所示,宁波市最终交通小区划分结果分布图参见附图4。
[0062]
表5 各区县交通小区数表
[0063]
[0064]
本发明的第二实施例具体如下:
[0065]
步骤1:获取行政区划边界和分等级路网矢量数据,并进行数据预处理;
[0066]
所述步骤1中,基于获取的基础数据,通过arcgis专业软件完成基础的数据处理,包括路网拓扑处理、交叉路口简化等。
[0067]
步骤2:基于路网和行政区划划分基本聚类单元;
[0068]
所述步骤2中,运用路网对行政区划进行分割,划分出后续步骤中的街道尺度的基本聚类单元。
[0069]
步骤3:建立聚类指标体系,并结合步骤2的聚类单元,通过手机信令获取单元内居民出行特征;
[0070]
步骤4:根据聚类单元所在行政区位置,采用k-means聚类算法初步聚类,得到各聚类数对应的聚类结果及聚类中心;
[0071]
所述步骤4中,在使用k-means算法进行聚类之前,需要根据区县内居民出行距离分布确定聚类数范围。
[0072]
聚类算法通过代价函数来描述聚类进程,代价函数为:
[0073][0074]
其中,n为样本数,c为划分的簇个数,各区县的样本数及划分簇数取值如表6 所示,xi为第i个数据样本,cj为第j个簇的中心,u
ij
表示样本i归属簇j的隶属度,d(xi,cj)为第i个样本到第j个簇的中心的“距离”。
[0075]
表6 各区县样本数(n)及簇数范围(c)
[0076][0077]
考虑聚类单元作为地理空间对象,该“距离”除基本的属性距离外,还应兼顾空间距离,表达式如下,
[0078]
[0079]
式中,为样本与簇中心的空间距离,其中若样本与簇相邻接,其值为0,否则为样本质心到簇中心质心的空间距离;α=0.7为空间效应系数;为样本到簇中心的属性距离,表达式如下,
[0080][0081]
式中,x
im
为样本i的第m=6个聚类因子,c
jm
为簇j的第 m=6个聚类因子,wm为第m=6个聚类因子的权重,为样本 i与簇j的属性距离。
[0082]
步骤5:针对步骤4所得各聚类数的聚类结果,计算聚类有效性指标;
[0083]
所述步骤5中,使用综合考虑组内相似性和组间差异性的指标来评价聚类结果,聚类有效性指标表达式如下:
[0084][0085]
其中,d
ij
表示聚类单元j到簇i中心的距离,ni表示第i个簇聚类单元的个数,di表示第i个簇内部到聚类中心的平均距离,n为全部聚类单元数,d
inner
用于表征聚类簇内聚类单元的相似性。r
ij
为簇i聚类中心到簇j中心的距离,d
outer
为全部簇中心两两距离的和,用于表征聚类簇之间的差异性。
[0086]
步骤6:比较各聚类数的聚类有效性指标,确定合适聚类数;
[0087]
所述步骤6中,基于绘制各聚类数、聚类有效性指标图,参考“手肘法”选取最佳聚类数。
[0088]
步骤7:依据步骤6确定的聚类数,通过fcm聚类算法进行最终聚类划分;
[0089]
所述步骤7中,采用引入模糊概念的fcm算法进行二次聚类,其中隶属度u
ij
∈[0,1],且
[0090]
步骤8:结合主要等级道路,对步骤7所得聚类结果进行修正,完成交通小区划分。
[0091]
所述步骤8中,对聚类结果的修正即筛选等级道路网络中的主干道路,并据此对步骤7 中的聚类结果进行二次分割,得到最终的交通小区划分结果。
[0092]
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
[0093]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1