一种带准备时间分布式柔性作业车间调度方法及系统
1.本发明属于分布式柔性作业车间调度技术领域,涉及一种分布式柔性作业车间调度方法及系统,具体涉及一种基于混合麻雀算法的带准备时间分布式柔性作业车间调度方法及系统。
背景技术:
2.随着全球化趋势不断加剧,导致市场频繁变化、新技术不断涌现、竞争对手数量在全球范围激增。分布式生产孕育而生,分布式生产可以使得企业更接近客户和供应商,更有效地生产和销售产品,快速应对市场变化,降低管理难度和风险,节约成本,提高资源利用率。
3.分布式柔性作业车间主要涉及三个子问题,工件分配至哪个车间,每个车间内工件的工序如何排序,每道工序选择哪一台机器。由于柔性作业车间调度问题已被证实为np-hard问题,所以分布式柔性作业车间也是np-hard问题。解决分布式柔性作业车间调度问题,需要一种高效的智能优化算法。
4.分布式车间有以下几种情况:对于工厂来说,有两种分类,即同构车间,所有车间的生产环境完全一样;异构车间,车间的生产环境不完全相同。对于工件加工来说,有两种可能性,即工件的所有工序均在同一车间内加工;或者工件可以在不同车间内加工。对于机器而言,又可分为同速并行机和异速并行机。
5.国内外学者针对不同情形下的分布式柔性作业车间,通过改进混合智能优化算法,已达到求解速度和精度、质量提高。如:insgaii,goga,ga-ts
…
。
6.麻雀算法通过模仿麻雀的觅食行为和反捕食行为,具有很好的平衡全局搜索和局部搜索能力。算法能很好综合种群特性,使得种群向全局最优解靠近。
7.模拟退火算法的优势在于算法前期能很好的跳出局部最优解,使得搜索范围更大;遗传算法的优势在于全局搜索能力强。这两种算法能很好的和其他算法融合,完成种群进化。
技术实现要素:
8.针对现有算法求解分布式柔性作业车间效率低,解集质量差等特点。本发明提出了一种基于混合麻雀算法的带准备时间分布式柔性作业车间调度方法及系统,满足准备时间约束,同时设计了三层领域结构,融合了模拟退火算法和遗传算法,提升麻雀算法性能。
9.本发明的方法所采用的技术方案是:一种带准备时间分布式柔性作业车间调度方法,包括以下步骤:
10.步骤1:构建带准备时间的分布式柔性作业车间调度模型,包括最大完工时间、最大碳排放量、最大延迟时间和约束条件;
11.所述最大完工时间为:
12.min c
max
=max(ci),i∈[1,n];
[0013][0014]
所述最大碳排放量为:
[0015][0016]
所述最大延迟时间为:
[0017]
min l
max
=max{|c
i-gi|z
il
},i∈[1,n];
[0018]
所述约束条件为:
[0019][0020][0021][0022][0023][0024][0025][0026][0027]
上各式中,n为工件数量,i为工件编号,ci为工件i的完工时间;j为工序编号,l为车间编号,k为机器编号,q为车间数量,m
l
为车间的机器数量,为工件i的第j道工序在车间l第k台机器上的加工时间,为工件i的第j道工序在车间l的准备时间;如果则工件i的第j道工序在车间l中加工;否则,则工件i的第j道工序在车间l中加工;否则,如果则工件i的第j道工序由车间l第k台机器加工;否则,tc为所有机器的碳排放总量,ef为加工时间和能耗转换系数,cef为能耗转换和碳排放转换系数,l
max
为所有工件的最大延迟时间,c
max
为所有工件的的最大完工时间;gi为工件i的计划完工时间;如果则工件i的完工时间大于计划完工时间;否则,工时间大于计划完工时间;否则,为工件i的第j道工序在车间l第k台机器上的开始加工时间,为工件i的第j道工序在车间l第k台机器上的加工结束时间;i为一个无穷大的数;e为标号为e的工件,f为工件e的第f道工序,pe为工件e的总工序数;
[0028]
步骤2:将步骤1中的n、q、m
l
、ef、cef、gi、每个工件的工序数、麻雀算法的发现者比例、警戒者比例输入混合麻雀算法中;算法根据步骤1所确立的约束和目标函数迭代计算,直至达到迭代次数,输出一段近似最优的工序序列为最优调度方案。具体包括以下子步骤:
[0029]
步骤2.1:初始化种群大小、确定最大迭代次数和麻雀算法发现者和警戒者比例、
明确步骤1中n、q、m
l
、ef、cef、gi、和每个工件的工序数数值,从而初始化麻雀种群;
[0030]
步骤2.2:计算每个麻雀个体的适应度值;
[0031]
步骤2.3:对初始麻雀种群进行非劣排序,共有n个等级;
[0032]
步骤2.4:计算每个等级中麻雀个体的拥挤度值;
[0033]
步骤2.5:麻雀种群优先根据等级排序,其次根据拥挤度排序;根据排序结果,前n%个体设置为发现者,剩下的个体为跟随者;其中,n为预设值;
[0034]
步骤2.6:发现者和跟随者进行更新,并将更新后的解依次进行车间层变邻域搜索、工序层变邻域搜索和机器层变邻域搜索,成为新解;若新解支配旧解,则以一定概率接受新解,随着迭代次数的增加,接受概率增大;若旧解支配新解,则不接受新解;若新解和旧解互不支配,则以50%的概率接受新解;
[0035]
步骤2.7:将更新后的发现者和跟随者各随机抽取10%,成为警戒者,进行更新;更新后,进行交叉变异;将抽取的个体从发现者和跟随者中删除;
[0036]
步骤2.8:将更新后的发现者和跟随者、警戒者合并在一起,构成新种群;判断当前代数是否大于最大迭代次数,若大于,则输出一段近似最优的工序序列;否则,回转执行步骤2.2。
[0037]
本发明的系统所采用的技术方案是:一种带准备时间分布式柔性作业车间调度系统,包括以下模块:
[0038]
模块1,用于构建带准备时间的分布式柔性作业车间调度模型,包括最大完工时间、最大碳排放量、最大延迟时间和约束条件;
[0039]
所述最大完工时间为:
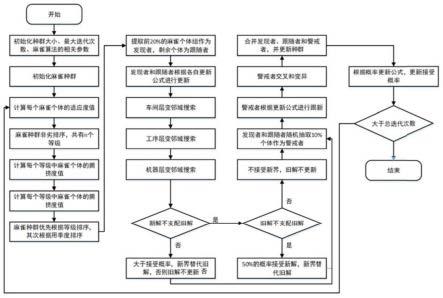
[0040]
min c
max
=max(ci),i∈[1,n];
[0041][0042]
所述最大碳排放量为:
[0043][0044]
所述最大延迟时间为:
[0045][0046]
所述约束条件为:
[0047][0048][0049][0050][0051]
[0052][0053][0054][0055]
上各式中,n为工件数量,i为工件编号,ci为工件i的完工时间;j为工序编号,l为车间编号,k为机器编号,q为车间数量,m
l
为车间的机器数量,为工件i的第j道工序在车间l第k台机器上的加工时间,为工件i的第j道工序在车间l的准备时间;如果则工件i的第j道工序在车间l中加工;否则,则工件i的第j道工序在车间l中加工;否则,如果则工件i的第j道工序由车间l第k台机器加工;否则,tc为所有机器的碳排放总量,ef为加工时间和能耗转换系数,cef为能耗转换和碳排放转换系数,l
max
为所有工件的最大延迟时间,c
max
为所有工件的的最大完工时间;gi为工件i的计划完工时间;如果则工件i的完工时间大于计划完工时间;否则,工时间大于计划完工时间;否则,为工件i的第j道工序在车间l第k台机器上的开始加工时间,为工件i的第j道工序在车间l第k台机器上的加工结束时间;i为一个无穷大的数;e为标号为e的工件,f为工件e的第f道工序,pe为工件e的总工序数;
[0056]
模块2,将模块1中的n、q、m
l
、ef、cef、gi、每个工件的工序数、麻雀算法的发现者比例、警戒者比例输入混合麻雀算法中;算法根据模块1所构建的约束和目标函数迭代计算后,输出一段工序序列。具体包括以下子模块:
[0057]
模块2.1,初始化种群大小、确定最大迭代次数和麻雀算法发现者和警戒者比例、明确模块1中n、q、m
l
、ef、cef、gi、每个工件的工序数数值,从而初始化麻雀种群;
[0058]
模块2.2,用于计算每个麻雀个体的适应度值;
[0059]
模块2.3,用于对初始麻雀种群进行非劣排序,共有n个等级;
[0060]
模块2.4,用于计算每个等级中麻雀个体的拥挤度值;
[0061]
模块2.5,用于麻雀种群优先根据等级排序,其次根据拥挤度排序;根据排序结果,前n%个体设置为发现者,剩下的个体为跟随者;其中,n为预设值;
[0062]
模块2.6,用于发现者和跟随者进行更新,并将更新后的解依次进行车间层变邻域搜索、工序层变邻域搜索和机器层变邻域搜索,成为新解;若新解支配旧解,则以一定概率接受新解,随着迭代次数的增加,接受概率增大;若旧解支配新解,则不接受新解;若新解和旧解互不支配,则以50%的概率接受新解;
[0063]
模块2.7,用于将更新后的发现者和跟随者各随机抽取10%,成为警戒者,进行更新;更新后,进行交叉变异;将抽取的个体从发现者和跟随者中删除;
[0064]
模块2.8,用于将更新后的发现者和跟随者、警戒者合并在一起,构成新种群;判断当前代数是否大于最大迭代次数,若大于,则输出一段近似最优的工序序列;否则,回转执行模块2.2。
[0065]
本发明的优点在于:
[0066]
(1)针对分布式柔性作业车间模型,及采用的三层编码方式,解集空间巨大,采用
了metropolis准则和交叉变异策略,增大算法全局搜索能力;
[0067]
(2)设计了三层变邻域结构,大大的增强了算法的局部搜索能力;
[0068]
(3)多种混合初始化策略的使用,种群质量得到了提高.
附图说明
[0069]
图1为本发明实施例的方法流程图;
[0070]
图2为本发明实施例中混合麻雀算法求解某算例得到的两工厂甘特图;
[0071]
图3为本发明实施例中混合麻雀算法求解某算例得到的三工厂甘特图;
[0072]
图4为本发明实施例中混合麻雀算法和4种对比算法在10个算例上求解解集的空间分布;
[0073]
图5为本发明实施例中混合麻雀算法和4种对比算法在10个算例上求解解集的igd三维箱型图。
具体实施方式
[0074]
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
[0075]
请见图1,本发明提供的一种带准备时间分布式柔性作业车间调度方法,包括以下步骤:
[0076]
步骤1:带准备时间的分布式柔性作业车间调度模型构建;
[0077]
步骤1.1:带准备时间的分布式柔性作业车间调度模型做出必要的假设;
[0078]
步骤1.2:相关参数设置;
[0079]
步骤1.3:设置约束条件;
[0080]
步骤1.4:目标函数确定;
[0081]
步骤2:混合麻雀算法设计与实现;
[0082]
步骤2.1:种群个体的编解码种群个体的编解码;
[0083]
步骤2.2:种群初始化方式;
[0084]
步骤2.3:计算每个个体的适应度,利用pareto法对初始种群进行非劣排序和拥挤度计算,并进行排序;
[0085]
步骤2.4:根据排序结果,前20%个体设置为发现者,剩下的个体为跟随者;
[0086]
步骤2.5:发现者和跟随者根据不同公式进行更新,并将更新后的解进行三层变邻域搜索,成为新解,若新解支配旧解,则以一定概率接受新解,随着迭代次数的增加,接受概率增大;若旧解支配新解,则不接受新解;若新解和旧解互不支配,则以50%的概率接受新解;
[0087]
步骤2.6:将更新后的发现者和跟随者各随机抽取10%,成为警戒者,进行更新,更新后,进行交叉变异;将抽取的个体从发现者和跟随者中删除。
[0088]
步骤2.7:将更新后的发现者和跟随者、警戒者合并在一起,构成新种群;判断当前代数是否大于最大迭代次数,若大于,则输出结果,否则,循环2.3至2.6。
[0089]
本发明所构建的考虑准备时间分布式柔性作业车间调度模型做出如下假设:
[0090]
(1)工件可以选择在不同车间加工,一旦分配给某个车间,该工件所有工序必须在该车间内加工。
[0091]
(2)每个工件的每道工序都至少有一台机器可供选择。
[0092]
(3)不同工件的加工路线不相同,同一个工件的不同工序之间具有加工顺序约束。
[0093]
(4)所有工件首道工序和机器首道加工工序都可以从零时刻加工。
[0094]
(5)每个工厂内的每一台机器在同一时刻只能加工一个工件。
[0095]
(6)同一时刻同一工件只能在一台机器上加工。
[0096]
(7)只考虑机器在加工阶段产生的碳排放。
[0097]
(8)每个车间都可以加工任一工件。每个车间内的机器性能不相同。每个车间都可以加工任一工件。每个车间内的机器性能不相同。
[0098]
(9)工件一旦加工则不能中止。
[0099]
(10)不考虑运输时间、辅助时间等。
[0100]
本发明所构建的考虑准备时间分布式柔性作业车间调度模型参数设置如下:n:工件数量;
[0101]
q:车间数量;
[0102]
i:工件编号;
[0103]
j:工序编号;
[0104]
l:车间编号;
[0105]
k:机器编号;
[0106]
e:标号为e的工件;
[0107]
f:工件e的第f道工序;
[0108]
pe:工件e的总工序数;
[0109]ml
:车间的机器数量;
[0110]ji
:第i号工件;
[0111]
pi:工件ji的工序数;
[0112]
i:一个无穷大的数;
[0113]oij
:工件i的第j道工序;
[0114]fl
:第l号车间;
[0115]mlk
:车间l中第k台机器;
[0116]ml
:车间l中的机器数量;
[0117]
ms
l
:车间l中的机器集;
[0118]
工件i的第j道工序在车间l中第k台机器上加工;
[0119]mij
:工件i的第j道工序的可选机器集;
[0120]
工件i的第j道工序在车间l第k台机器上的加工时间;
[0121]
ef:加工时间和能耗转换系数;
[0122]
cef:能耗转换和碳排放转换系数;
[0123]
工件i的第j道工序在车间l的准备时间;
[0124]
工件i的第j道工序在车间l第k台机器上的开始加工时间;
[0125]
工件i的第j道工序在车间l第k台机器上的加工结束时间;
[0126]ci
:工件i的完工时间;
[0127]gi
:工件i的计划完工时间;
[0128]
li:工件i的延迟时间;
[0129]
l
max
:所有工件的最大延迟时间;
[0130]cmax
:所有工件的的最大完工时间;
[0131]
tc:所有机器的碳排放总量;
[0132]
如果则工件i的第j道工序在车间l中加工;否则,
[0133]
如果则工件i的第j道工序由车间l第k台机器加工;否则,
[0134]
如果则在之前加工;否则,
[0135]
如果则工件i的完工时间大于计划完工时间;否则,
[0136]
本发明所构建的考虑准备时间分布式柔性作业车间调度模型约束条件设置如下:
[0137]
同一时刻,工件只能在一台机器上加工,公式如下:
[0138][0139]
工件在加工过程中,中止加工不允许发生,公式如下:
[0140][0141]
工件在加工过程中有顺序要求,且每一道工序在加工前都有准备时间,公式如下:
[0142][0143]
工件一旦分配给某个车间,其所有工序都必须在该车间内加工,公式如下:
[0144][0145]
工件首道工序、机器首道工序和工厂都能从零时刻开始加工,公式如下:
[0146][0147]
同一工厂的同一机器在同一时刻只能加工一道工序,公式如下:
[0148][0149]
本发明所构建的考虑准备时间分布式柔性作业车间调度模型目标函数设置如下:
[0150]
最小最大完工时间:
[0151]
min c
max
=max(ci),i∈[1,n],
[0152]
最小最大碳排放:
[0153][0154]
最小最大拖期:
[0155][0156]
混合的麻雀算法具体实现步骤如下:
[0157]
初始化参数,包括种群规模,算法最大迭代次数,车间数量,麻雀算法中发现者比例,跟随者比例以及警戒者比例;
[0158]
其中,种群规模设置为100;车间数量设置为2和3;最大迭代次数设置为200;发现者比例设置为20%;警戒者所占比例设置为10%;
[0159]
第一步:构建结构体,结构体有6个属性,分别是position、cost、dominatedcount、dominationset、rank、crowdingdistance,依次代表工序序列、目标值、支配解的个数,被支配解的集合,等级级别和拥挤度。
[0160]
第二步:首先确定工件数量、每个工件的工序数、车间数量、每个车间的机器数,从而初始化麻雀种群;其次根据步骤1构建的约束和目标函数计算出每个麻雀个体的6个属性值;最后麻雀种群依据每个麻雀个体的等级级别和拥挤度进行非劣排序。
[0161]
第三步:首先根据设置好的发现者比例,将麻雀种群分为发现者和跟随者,发现者更新公式如下:
[0162][0163]
其中代表t代种群中第i个发现者,α为[0.1]内一随机数;iter
max
为最大迭代次数;r2为警戒值(r2∈[0,1][,st为安全值(st∈[0.5.1][;q是一个服从正态分布的随机数;l是一个1xd的矩阵,其中每个元素都为1。
[0164]
跟随者更新公式如下:
[0165][0166]
其中代表t代种群中第i个跟随者;n代表当前种群中跟随者总数;代表当前发现者所发现的最好位置;代表当代种群中最差个体;a是一个1xd矩阵,其中每个元素随机赋值1或-1。
[0167]
其次发现者和跟随者分别进行车间、工序、机器部分的变邻域搜索。选择出完工时间最大的车间作为关键车间,并将关键车间内的任一工件取出放入其他车间,完成车间部分的变邻域搜索;其次,从每个车间的调度方案中挑选出最长工序段,此工序段在时间上必须是连续且段尾工序是最后一道工序,由此选出的工序集作为关键路径,并将关键路径分成若干个关键工序块,首工序块仅交换块首两道工序,尾工序块仅交换块尾两道工序,其余工序块首尾两道工序都进行交换;最后,每道工序针对可选机器集,依次遍历不同的机器。
[0168]
然后采用精英选择策略:新解支配旧解,则以一定概率接受新解,随着迭代次数的增加,接受概率增大;若旧解支配新解,则不接受新解;若新解和旧解互不支配,则以50%的
概率接受新解。
[0169]
最后根据警戒者比例,从发现者和跟随者中随机抽取10%个体,组成警戒者,并从发现者和跟随者中删除被选中的个体,警戒者更新公式如下:
[0170][0171]
其中代表t代种群中第i个警戒者;代表当代种群中最好个体;fg,fw分别代表当代种群中最好和最差适应度值;fi表示第i个警戒者的适用度值;ε是一个较小常数,避免分母为0;β为步长控制参数,是服从标准正态分布的一个随机数。k表示[-1,1]中一个随机数,表示麻雀移动方向同时也是步长控制参数。
[0172]
更新之后的警戒者在交叉阶段,工序层采用pmx交叉算子,机器层和车间层采用uc交叉算子;在变异阶段,三层均采用高斯变异算子。将更新之后的发现者、跟随者和警戒者合成新麻雀种群替代原麻雀种群。
[0173]
第四步:判断迭代次数是否大于总迭代次数,若大于,终止循环,输出近似最优工序序列,否则,循环第三步。
[0174]
本发明所设计的混合麻雀算法:
[0175]
(1)本发明采用ops三层编码方式,分别是工序层,机器层,车间层,一个个体编码为工序层-机器层-车间层。每一层长度都是d。
[0176]
(2)本发明采用的初始化策略为:30%个体随机生成,30%个体采用spt调度规则生成,剩余的40%个体采用混沌映射初始化策略生成。
[0177]
(3)本发明采用的三层变邻域搜索过程如下:首先,选择出关键车间(完工时间最大的车间[,并将关键车间内的任一工件取出放入其他车间,完成车间部分的变邻域搜索;其次,从每个车间的调度方案中挑选出最长工序段,此工序段在时间上必须是连续且段尾工序是最后一道工序,由此选出的工序集作为关键路径,并将关键路径分成若干个关键工序块,首工序块仅交换块首两道工序,尾工序块仅交换块尾两道工序,其余工序块首尾两道工序都进行交换;最后,每道工序针对可选机器集,依次遍历不同的机器。
[0178]
(4)本发明在交叉阶段,工序层采用pmx交叉算子,机器层和车间层采用uc交叉算子;在变异阶段,三层均采用高斯变异算子。
[0179]
(5)本发明采用metropolis准则,发现者和跟随者在更新后,新解会以一定概率替代旧解,并随着者迭代次数增加,概率会增大。
[0180]
为验证算法的有效性,选取了10个算例和3个指标、4种对比算法,10个算例均是brandimarte标准算例的扩展算例,4个指标为igd,sp,gd,4种算法分别是nsgaii,mopso,igwo,sca。
[0181]
表1记录了混合麻雀算法(hssa[和4种对比算法的igd值。分别用a1表示hssa,a2表示nsgaii,a3表示mopso,a4表示igwo,a5表示sca;
[0182]
表1
[0183][0184]
表2记录了混合麻雀算法(hssa[和4种对比算法的sp值;
[0185]
表2
[0186][0187]
表3记录了混合麻雀算法(hssa[和4种对比算法的gd值;
[0188]
表3
[0189][0190]
从表1中可以看出混合麻雀算法在求解10个算例得到的igd值更小,并且通过图5可以看出混合麻雀算法求解出的igd值分布更加均匀。这都说明了混合麻雀算法求得解集得综合质量高。
[0191]
从表2中可以看出混合麻雀算法求解10个算例得到得sp值基本最小,说明混合麻雀算法求得解集空间多样性更高。
[0192]
从表3中可以看出混合麻雀算法在求解10个算例得到得gd更小,说明混合麻雀算法求得解集收敛性更好。
[0193]
图2展示了hssa求解j30c11m15-2算例的最优值所对应的甘特图。图3展示了hssa求解j30c11m15-3算例的最优解所对应的甘特图。图4展示了hssa,nsgaii,mopso,igwo,sca在求解10个算例下,最优解集的空间分布,因本专利所选最大完工时间,最大碳排放,拖期均是越小越优,所以验证了hssa在求解dfjsp问题上的优势性和有效性。
[0194]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1