一种基于子图划分的图检索方法
1.本发明属于图相似性计算领域,尤其涉及一种基于子图划分的图检索方法。
背景技术:
2.近年来,互联网的不断发展导致各种各样数据日益增多,尤其是图数据,存在于现实生活的方方面面,如人际交往网络、化学分子、生物信息等。目前,与图相关的应用越来越成为研究人员的研究热点,其中一个基本的应用是在数据库中查询给定图的相似图,即图检索。图相似性计算是图检索任务中的关键步骤,用以衡量一对图数据之间的的相似性。传统的图相似性计算以图编辑距离(graph edit distance,即ged)或最大公共子图(maximum common subgraph,即mcs)为相似性度量,但是传统的方法计算两个任意大小图之间的相似性需要付出巨大的计算代价,且已有的研究表明传统的方法很难在有效的时间内精确计算出节点数大于16的图之间的相似性。
3.目前已经有研究使用图神经网络(graph neural network,即gnn)模型来计算两图之间的相似性程度,gnn模型将输入图映射到向量空间当中,相似的图在向量空间中距离相近,不相似的图则相互远离。gnn模型通过迭代操作聚合节点邻域表示,重复进行多次可以利用每个节点的多跳领域内的信息,将学习到的节点表示用于后续的处理。针对gnn学习到的节点表示可以直接用于节点分类、链路预测或池化成图表示用于图分类,例如:通过构建siamese网络框架学习一对图的相似性,通过学习到两个图的表示,根据两个图表示进行相似性预测,但这种方法显然只考虑了全局的图表示,没有考虑节点、子图等不同层次间的细粒度信息。gnn模型本质上是扁平的,只能根据图的边传播信息,无法利用子图推理和聚合信息,因此单纯的依靠gnn模型是无法充分利用图中的子图结构等细粒度信息。
4.传统方法计算两图之间的ged或mcs是np完全问题,计算代价大,无法扩展到节点数量多的图数据中。现有的gnn模型有的不能很好捕捉两图间的交互信息,有的不能很好利用图中的子图结构信息,缺乏图中的细粒度信息。
技术实现要素:
5.针对现有技术的不足,本发明设计一种基于子图划分的图检索方法。
6.一种基于子图划分的图检索方法,具体包括以下步骤:
7.步骤1:将节点和边组成的图数据作为训练数据集,对训练数据集进行预处理,统计训练数据集中的数据特征,将训练数据集中的图进行一对一匹配,构造训练图对数据集用于后续模型的训练;
8.训练图对的基本单元是(g1,g2,y),图g=(v,e),其中v是图的节点集,e是图的边集,v的节点数为n=|v|;节点初始特征x={x1,x2,x3,
…
,xn},如果训练数据中未包含节点的初始特征,则根据one-hot编码生成节点的初始特征;对节点的度dv进行one-hot编码,并将其拼接到节点的初始特征上,作为后续训练所用的节点特征,生成可以用于训练的图对数据集;
9.步骤2:构建基于gnn的节点卷积网络,对步骤1中训练图对中的节点特征进行训练,根据充分利用不同距离信息的思想,拼接聚合节点不同距离大小的领域信息,生成新的节点的特征;
10.节点卷积网络采用改进的图同构网络即gin对节点特征进行训练,其计算公式如下:
[0011][0012]
其中,mlp
(k)
是多层感知机,k表示第k层网络,表示第k层的节点v的特征,∈是一个可学习的参数,表示节点v的邻域节点集合中的一个节点u;
[0013]
由边集e构造图的一阶邻接矩阵a1,从而计算出图的二阶邻接矩阵a2,其计算公式如下:
[0014]
t=a1·
a1[0015][0016]
拼接通过a1训练得到的节点特征和通过a2训练得到的节点特征,将节点的一阶邻接性和二阶邻接性结合起来,扩展卷积网络的感受域以提取更多的节点特征;
[0017]
步骤3:构建图对间交互模块,将步骤2得到的节点特征通过交叉图注意力机制计算节点注意力系数,实现图对之间的相互交互,生成包含交互信息的新的节点特征;
[0018]
图对g1和g2间的交互,对于g1中的每一个节点,计算其与g2中所有节点的余弦相似性评分,其计算公式如下:
[0019][0020]
其中,是g1中节点i特征,是g2中节点j特征,n2是g2的节点数;
[0021]
然后利用上述的相似性评分计算图g2对图g1中节点i的影响,其计算公式如下:
[0022][0023]
其中,[α
i,j
]
+
=max(α
i,j
,0),是图g1中节点i经过与图g2的交互后生成的节点特征;
[0024]
将图g1和图g2进行互换,得到图g1对图g2的影响,通过一个多视角匹配余弦匹配函数来计算输出的节点特征,其计算公式如下:
[0025][0026]
其中,x
in
是交互部分输入的节点特征矩阵,是图对之间相互交互后的节点特征矩阵,w是学习的参数矩阵;
[0027]
步骤4:构建子图划分模块,根据步骤3得到的节点特征以及图的结构信息,通过端到端的方式为节点学习分配矩阵,以适应不同的图神经网络体系结构的层次结构,划分相应的子图;
[0028]
通过使用单独的图卷积网络即gcn来生成图节点分配矩阵s,利用节点的特征矩阵
x和图的一阶邻接矩阵a1将节点划分到相应的子图中,其计算公式如下:
[0029]
s=softmax(gcn(a1,x))
[0030]
其中,softmax按行进行计算的;分配矩阵s的输出维度为数据集中图的最大节点数nmax,然后对分配矩阵s进行进一步的池化操作,根据每行计算得到节点归属对应子图的隶属度,只保留隶属度较大的子图分配,一个节点可以被多个子图拥有,该部分参数是模型预定义的超参数;
[0031]
步骤5:构建子图卷积网络,根据步骤4划分得到的子图,对子图内的节点进行卷积计算强化子图内节点的关联性,进一步得到包含着子图信息的节点特征;
[0032]
使用超图神经网络即hgnn对划分好的子图进行卷积计算,将一个子图作为一个超边进行计算,其计算公式如下:
[0033][0034]
其中,σ()是非线性激活函数,dv是超图中节点度的对角矩阵,de是超图中超边度的对角矩阵,w是超图中的超边权重矩阵,θ是可训练参数矩阵;将同一子图中的节点看作位于同一超边之上,超图中节点度等价于节点出现在不同超边中的次数,超图中超边度是指超边中包含的节点数;
[0035]
步骤6:利用步骤5得到的节点特征构建图对之间的相似矩阵,搭建基于卷积神经网络即cnn的深度学习网络,将相似性计算转换成模式识别问题,利用多尺度特征获取更多图相似性的特征信息;
[0036]
将图对节点的特征矩阵分别扩展到nmax*128,扩展的部分用0进行填充,然后图g1的节点特征矩阵乘以图g2的节点特征矩阵,计算图对之间所有节点特征之间的内积,其结果作为图对的相似矩阵,将其作为cnn部分的输入;
[0037]
构建多层cnn,将上述的相似矩阵视为一副图像,将图相似性计算转化为图像处理问题;
[0038]
步骤7:通过注意力读出函数,将步骤3和步骤5得到的节点特征分别计算生成图表示;利用注意力机制将节点特征转化为图表示,其计算公式如下:
[0039][0040]
其中,σ()为sigmod函数,w
att
是可训练的注意力权重矩阵,n是图的节点数,xn是节点n的特征;
[0041]
步骤8:将步骤7计算得到图表示,与步骤6中cnn部分的输出结果一起进行相似性得分计算,得到图对的相似性得分;
[0042]
把步骤7中根据步骤3和步骤5生成相应的图表示,与步骤6中cnn部分的输出结果连接起来,输入到具有sigmoid激活函数的多层感知器即mlp中,计算最后的相似性得分;
[0043]
步骤9:根据步骤8得到的相似性得分,查询图数据库中与给定图相似的结果;
[0044]
步骤2和步骤5的节点卷积网络中网络层维度设置为nhid,采用adam优化器,如果在指定的周期验证损失没有减少,就停止训练;步骤6中cnn部分由多层二维卷积层组成;步骤8中mlp由多层全连接的神经元组成,最后一层的神经元设置为1;在图数据库中查询给定
图的相似图,得到需要数量的结果。
[0045]
本发明有益技术效果:
[0046]
本发明的目的是提供一种基于子图划分的图检索方法,结合节点的一阶邻接性和二阶邻接性以及图对间的交互信息为节点生成特征表示,通过子图划分提取图中子图结构信息,关联输入图对之间的节点、结构信息,计算出输入的图对之间的相似性,从而检索出相似的图。
[0047]
采用本发明所述图检索方法,使用深度学习的方法实现了图相似性计算,在多个图数据集上进行测试,结果表明该方法在不同的图数据上,能够较为准确地计算图相似性,完成图检索任务,运算速度满足实时性要求。本发明实现方法简单,运算速度快,结果准确性高,且处理过程不需要人工交互,达到了应用的要求。
[0048]
本发明与三个传统方法(beam、vj、hungarian)和三个图神经网络(simgnn、gmn、graphsim)分别对输入的化学化合物和程序依赖图数据集进行图检索,输出相似性靠前的查询结果。
[0049]
传统方法beam是指michel neuhaus等人在“fast suboptimal algorithms for the computation of graph edit distance”中提出的一种ged计算方法,简称beam。
[0050]
传统方法vj是指stefan fankhauser等人在“speeding up graph editdistance computation through fast bipartite matching”中提出的一种ged计算方法,简称vj。
[0051]
传统方法hungarian是指kaspar riesen等人在“approximate graph edit distance computation by means of bipartite graph matching”中提出的一种ged计算方法,简称hungarian。
[0052]
图神经网络simgnn是指yunsheng bai等人在“simgnn:a neural network approach to fast graph similarity computation”中提出的一种计算图相似性的网络,简称simgnn。
[0053]
图神经网络gmn是指yujia li等人在“graph matching networks for learning the similarity of graph structured objects”中提出的一种计算图相似性的网络,简称gmn。
[0054]
图神经网络graphsim是指yunsheng bai等人在“learning-based efficient graph similarity computation via multi-scale convolutional set matching”中提出的一种计算图相似性的网络,简称graphsim。
附图说明
[0055]
图1本发明实施例流程图;
[0056]
图2本发明实施例子图划分样例图;
[0057]
图3本发明实施例图检索结果样例图;其中左侧为查询图,右侧为查询结果。
具体实施方式
[0058]
下面结合附图和实施例对本发明做进一步说明;
[0059]
本发明提供一种基于子图划分的图检索方法,在节点领域聚合的时候考虑节点的一阶邻接性和二阶邻接性,通过交叉图注意力机制交互两图的信息,结合节点特征和图结
构对图进行子图划分,既考虑了图的全局信息,又考虑了不同图分层间的细粒度交互,实现了图的相似性计算,完成在数据库中检索与查询图相似的结果。
[0060]
本发明提出基于子图划分的图检索方法,考虑节点的一阶邻接性和二阶邻接性,通过交叉图注意力机制关联连图对间的差异,并通过子图划分提取图中子图结构,汇集图中的结构信息,计算出输入的成对图之间的相似性,从而检索出与查询图相似的结果。
[0061]
一种基于子图划分的图检索方法,如附图1所示,具体包括以下步骤:
[0062]
步骤1:将节点和边组成的图数据作为训练数据集,对训练数据集进行预处理,统计训练数据集中的数据特征,将训练数据集中的图进行一对一匹配,构造训练图对数据集用于后续模型的训练;
[0063]
训练图对的基本单元是(g1,g2,y),图g=(v,e),其中v是图的节点集,e是图的边集,v的节点数为n=|v|;节点初始特征x={x1,x2,x3,
…
,xn},如果训练数据中未包含节点的初始特征,则根据one-hot编码生成节点的初始特征;对节点的度dv进行one-hot编码,并将其拼接到节点的初始特征上,作为后续训练所用的节点特征,生成可以用于训练的图对数据集;
[0064]
步骤2:构建基于gnn的节点卷积网络,对步骤1中训练图对中的节点特征进行训练,根据充分利用不同距离信息的思想,拼接聚合节点不同距离大小的领域信息,生成新的节点的特征;
[0065]
节点卷积网络采用改进的图同构网络(graph isomorphism network,即gin)对节点特征进行训练,其计算公式如下:
[0066][0067]
其中,mlp
(k)
是多层感知机,k表示第k层网络,表示第k层的节点v的特征,∈是一个可学习的参数,表示节点v的邻域节点集合中的一个节点u;
[0068]
由边集e构造图的一阶邻接矩阵a1,从而计算出图的二阶邻接矩阵a2,其计算公式如下:
[0069]
t=a1·
a1[0070][0071]
拼接通过a1训练得到的节点特征和通过a2训练得到的节点特征,将节点的一阶邻接性和二阶邻接性结合起来,扩展卷积网络的感受域以提取更多的节点特征;
[0072]
步骤3:构建图对间交互模块,将步骤2得到的节点特征通过交叉图注意力机制计算节点注意力系数,实现图对之间的相互交互,生成包含交互信息的新的节点特征;
[0073]
图对g1和g2间的交互,对于g1中的每一个节点,计算其与g2中所有节点的余弦相似性评分,其计算公式如下:
[0074][0075]
其中,是g1中节点i特征,是g2中节点j特征,n2是g2的节点数;
[0076]
然后利用上述的相似性评分计算图g2对图g1中节点i的影响,其计算公式如下:
[0077][0078]
其中,[α
i,j
]
+
=max(α
i,j
,0),是图g1中节点i经过与图g2的交互后生成的节点特征;
[0079]
将图g1和图g2进行交互,得到图g1对图g2的影响,通过一个多视角匹配余弦匹配函数来计算输出的节点特征,其计算公式如下:
[0080][0081]
其中,x
in
是交互部分输入的节点特征矩阵,是两图相互交互后的节点特征矩阵,w是学习的参数矩阵;
[0082]
步骤4:构建子图划分模块,根据步骤3得到的节点特征以及图的结构信息,通过端到端的方式为节点学习分配矩阵,以适应不同的图神经网络体系结构的层次结构,划分相应的子图;子图划分样例如图2所示;
[0083]
通过使用单独的图卷积网络(graph convolutional networks,即gcn)来生成图节点分配矩阵s,利用节点的特征矩阵x和图的一阶邻接矩阵a1将节点划分到相应的子图中,其计算公式如下:
[0084]
s=softmax(gcn(a1,x))
[0085]
其中,softmax按行进行计算的;分配矩阵s的输出维度为数据集中图的最大节点数nmax,然后对分配矩阵s进行进一步的池化操作,根据每行计算得到节点归属对应子图的隶属度,只保留隶属度较大的子图分配,一个节点可以被多个子图拥有,该部分参数是模型预定义的超参数;
[0086]
步骤5:构建子图卷积网络,根据步骤4划分得到的子图,对子图内的节点进行卷积计算强化子图内节点的关联性,进一步得到包含着子图信息的节点特征;
[0087]
使用超图神经网络(hypergraph neural nerworks,即hgnn)对划分好的子图进行卷积计算,将一个子图作为一个超边进行计算,其计算公式如下:
[0088][0089]
其中,σ()是非线性激活函数,dv是超图中节点度的对角矩阵,de是超图中超边度的对角矩阵,w是超图中的超边权重矩阵,θ是可训练参数矩阵;将同一子图中的节点看作位于同一超边之上,超图中节点度等价于节点出现在不同超边中的次数,超图中超边度是指超边中包含的节点数;
[0090]
步骤6:利用步骤5得到的节点特征构建图对之间的相似矩阵,搭建基于卷积神经网络(convolutional neural networks,即cnn)的深度学习网络,将相似性计算转换成模式识别问题,利用多尺度特征获取更多图相似性的特征信息;
[0091]
将图对节点的特征矩阵分别扩展到nmax*128,扩展的部分用0进行填充,然后图g1的节点特征矩阵乘以图g2的节点特征矩阵,计算图对之间所有节点特征之间的内积,其结果作为图对的相似矩阵,将其作为cnn部分的输入;
[0092]
构建多层cnn,将上述的相似矩阵视为一副图像,将图相似性计算转化为图像处理
问题;
[0093]
步骤7:通过注意力读出函数,将步骤3和步骤5得到的节点特征分别计算生成图表示;利用注意力机制将节点特征转化为图表示,其计算公式如下:
[0094][0095]
其中,σ()为sigmod函数,watt是可训练的注意力权重矩阵,n是图的节点数,xn是节点n的特征;
[0096]
步骤8:将步骤7计算得到图表示,与步骤6中cnn部分的输出结果一起进行相似性得分计算,得到图对的相似性得分;
[0097]
把步骤7中根据步骤3和步骤5生成相应的图表示,与步骤6中cnn部分的输出结果连接起来,输入到具有sigmoid激活函数的多层感知器(multilayer perceptron,即mlp)中,计算最后的相似性得分;
[0098]
步骤9:根据步骤8得到的相似性得分,查询图数据库中与给定图相似的结果;图检索结果样例图如附图3所示;
[0099]
步骤2和步骤5模型中网络层维度设置为128,采用adam优化器,学习速率的初始值设为0.0001,批大小(batchsize)设为256,迭代次数设为10000次,如果100个周期验证损失没有减少,就停止训练;步骤6中cnn部分共4层,分别是8*3*3,16*3*3,32*3*3,64*3*3;步骤8中mlp由4层全连接的神经元组成,每层的神经元分别设置为256,128,64,1。在图数据库中查询给定图的相似图,得到需要数量的结果。
[0100]
实验图数据说明如下表1所示:
[0101]
表1实验图数据说明示意表
[0102]
数据集图的数量平均节点数平均边数图对数量aids7008.908.80490000linux10007.586.941000000
[0103]
aids是nci/nih73的“发展治疗计划”中抗病毒筛选化学化合物的集合。linux是由linux内核生成的程序依赖图(pdg)组成,每个节点表示一条语句,每条边表示两条语句之间的依赖关系。
[0104]
本发明的评价指标是通过将检索到的前10个结果与真实的前10名结果的交集除以10进行计算(p@10),spearman’s排序关联系数(ρ)和计算出的相似度与真实相似度之间的平均平方差(mse)。
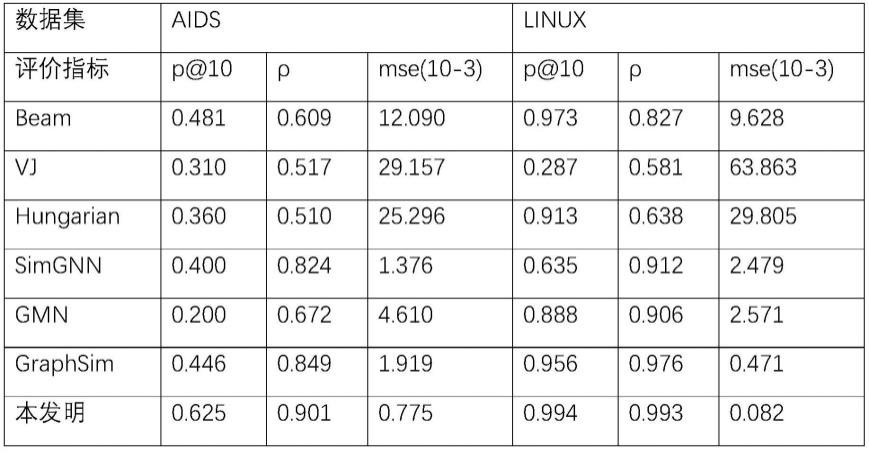
[0105]
表2为本发明所提供的方法与传统方法beam、vj、hungarian以及深度学习方法simgnn、gmn、graphsim在aids和linux数据集上的测试结果对比,对比结果如表2所示:
[0106]
表2beam、vj、hungarian、simgnn、gmn和graphsim与本发明提出的基于子图划分的图检索方法在多种评价指标上的结果比较;
[0107][0108]
由上表可以看出,本发明方法相较于其他方法能在两个图数据集上三个评价指标上都获得最好的结果。这证明本发明提出了一种基于子图划分的图检索方法可以有效地提升图检索的精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1