一种加速分布式机器学习的自适应同步机制
international conference on distributed computing systems.
10.[6].hongyi zhang,moustapha cisse,yann n.dauphin,and david lopez-paz.mixup:beyond empirical risk minimization.arxiv preprint arxiv:1710.09412,2017.
[0011]
[7].s.ioffe and c.szegedy.batch normalization:accelerating deep network training by reducing internal covariate shift.in proceedings of icml,pages448
–
456,2015.
[0012]
j.hu,l.shen,and g.sun.squeeze-and-excitation networks.arxiv preprint arxiv:1709.01507,2017。
[0013]
[3][4][5]尝试去改进bsp和asp。文献[3]提出的local-sgd通过减少bsp中通信同步的频率来减少通信等待的时间,但是该方法可能会损害模型精度,而且通信同步的频率阈值难以确定。文献[4]提出的ssp通过指定训练速度最快的工作节点和训练速度最慢的工作节点间的梯度过时不超过某一个阈值来改善asp中存在的梯度过时问题。然而,该方法需要用户指定过时阈值。用户往往不知道如何设置该过时阈值,通常需要频繁的调试才能确定出一个最佳的过时阈值,这是很耗时的。文献[5]提出的dssp将ssp中的过时阈值改为动态变化,从而解决了ssp人为指定过时阈值的问题。然而,该动态阈值是根据工作节点的迭代时间间隔来估计出来的,当网络发生较大变化时,过时阈值的估计可能会产生较大的误差。
[0014]
本发明类似于ssp和dssp,都是控制训练速度最快的工作节点和最慢的工作节点间的过时不能相差太多,不同的是本发明不会强制最快的工作节点停下来等待最慢的工作节点,因为在这段强制等待的过程中,昂贵的计算资源会被闲置。本发明采用了一种自适应同步的方法来避免最快的工作节点和最慢的工作节点间的过时相差过大,具体来说,本发明基于最快的工作节点和最慢的工作节点间的过时值,对训练速度较快的工作节点采用松弛的同步并行训练策略,而对剩余速度较慢的工作节点则采用完全异步并行训练策略。同时,在该松弛的同步并行训练策略中,由于被同步的工作节点间的训练迭代数可能会存在差异,所以在该同步中,不能采用传统的平均的方法聚合梯度,而是应该考虑工作节点间的迭代数的差异进行加权聚合。因此,本发明在该同步的聚合过程中采用了一种差异化加权的梯度聚合方法,有效地降低了慢梯度的影响,提高了模型性能。
[0015]
由于对较快的工作节点采用了松弛的同步并行训练策略,相当于在它们中增加了一个松弛的同步屏障,这样它们的速度会慢下来,由于该同步是松弛的,所以它们的训练速度也不会被减慢很多(以尽量少的同步实现更轻微的梯度过时),而对剩余速度较慢的工作节点采用异步并行训练策略,让它们可以保持较快的速度。该过程是朝着改善梯度过时的目标自适应变化的,且这是一种同步和异步混合的方式,所以可以实现较高的稳定性和较快的训练速度。
技术实现要素:
[0016]
(一)解决的技术问题
[0017]
本发明的目的在于提供了一种加速分布式机器学习的自适应同步机制,达到了提高并行训练效率、改善asp中的梯度过时问题的目的。
[0018]
(二)技术方案
[0019]
本技术提供如下技术方案:一种加速分布式机器学习的自适应同步机制,包括以下步骤:
[0020]
s1、在训练初始阶段各个工作节点采用asp方案进行训练;
[0021]
s2、服务器在每一个epoch中检测最快工作节点和最慢工作节点间的过时值s,当s大于1个epoch时,服务器对排名前s名工作节点采用松弛的bsp方案,与bsp不同,松弛的bsp方案允许服务器松弛同步条件,即允许服务器等待一定迭代次数后,可以直接对已收到的梯度做聚合,而不需要等待收到所有梯度才进行聚合,且在该松弛的bsp方案中采用差异化加权的梯度聚合方法聚合梯度,而对于剩余的工作节点,因为它们的排名靠后,训练速度较慢,服务器对它们采用asp方案;
[0022]
s3、在训练的每一轮中检测s,根据s以及工作节点训练速度的变化,针对各个工作节点自适应地采用不同并行训练方案(松弛的bsp或asp)。
[0023]
优选的1,实现自适应同步机制的步骤如下:
[0024]
s11、工作节点的实现步骤:
[0025]
(1)各个工作节点独立加载一部分数据集,并计算损失(cost)、准确度(accuracy)以及梯度(gradient);
[0026]
(2)工作节点通过tcp通信协议推送梯度到参数服务器中;
[0027]
(3)等待接收来自参数服务器返回的最新的模型参数;
[0028]
(4)将最新的模型参数替换本地的模型参数,从而进行下一次迭代训练,即循环执行(1)(2)(3)(4)步骤。
[0029]
s11、参数服务器的实现分为两个阶段:初始阶段和自适应同步阶段,参数服务器的运行由初始阶段起始,其后逐步过渡到自适应同步阶段,且根据梯度过时的严重程度,初始阶段和自适应同步阶段会自适应地相互切换:
[0030]
初始阶段:
[0031]
(1)等待接收来自工作节点的梯度,同时记录其迭代次数和训练轮数(训练轮数是指epoch,一次数据集的完整遍历记为一个epoch);
[0032]
(2)依据迭代次数,参数服务器检测是否所有工作节点都已经完成了一个完整的epoch,如果否,执行以下1)和2)步骤后,然后返回初始阶段步骤(1);
[0033]
1)参数服务器直接使用收到的梯度更新全局的模型参数,更新的方法使用随机梯度下降(sgd,stochastic gradient descent),随机梯度下降如公式(1)所示:
[0034]wt+1
=w
t-decay_α*giꢀꢀ
(1)
[0035]
其中,w
t+1
表示保存在参数服务器中第t+1次迭代的全局模型参数,decay_α表示衰减的学习率,gi表示来自第i个工作节点的梯度;
[0036]
2)将最新的全局模型参数w
t+1
单播给对应的第i个工作节点;
[0037]
继上述步骤(2),如果是(即所有工作节点都已经完成了一个完整epoch),参数服务器依据记录的训练epoch对所有工作节点进行排名,并计算最快工作节点和最慢工作节点的epoch差值s,其中:
[0038]
3)如果s<=1,参数服务器直接执行1)和2)步骤,然后返回初始阶段步骤(1);如果s>1,服务器将排名前s名的工作节点放入同步组,而将剩余的工作节点放入异步组,接
着执行(2)中的1)和2)步骤后,参数服务器进入自适应同步阶段:
[0039]
自适应同步阶段:
[0040]
(3)等待接收来自工作节点的梯度,在继承初始阶段的同时,继续记录工作节点的迭代次数和训练轮数(epoch);
[0041]
(4)如果此时聚合列表(即优选的2中所述的聚合列表)中已存在至少一份梯度,参数服务器启动松弛计数器,每收到一份梯度则松弛计数器计数加1;
[0042]
(5)判断接收到的梯度是否来自于同步组中的工作节点;
[0043]
(6)如果该份梯度来自于同步组中的工作节点,则按下面优选的2、3、4、5和6所述过程执行;
[0044]
(7)如果该份梯度是来自于异步组中的工作节点,则执行初始阶段中的步骤1)和2);
[0045]
(8)循环执行步骤(3)(4)(5)(6)(7),直到工作节点训练结束。
[0046]
优选的2,继自适应同步阶段步骤(5),如果该份梯度来自于同步组中的工作节点,则执行以下操作:
[0047]
1)参数服务器不会立刻更新全局模型参数,而是将这份梯度添加到一个聚合列表。
[0048]
2)如果聚合列表中梯度份数不等于同步组中所有工作节点个数或者松弛计数器计数小于或等于预设的松弛因子,返回到自适应同步阶段的步骤(3)。
[0049]
优选的3,继优选的2中步骤2),如果满足聚合列表中的梯度份数等于同步组中所有工作节点个数或者满足松弛计数器计数大于预设的松弛因子,此时对聚合列表中梯度做聚合,执行
①②③④
步骤:
[0050]
①
采用一种差异化加权的梯度聚合方法用于聚合梯度,该方法如公式(2)(3)所示:
[0051][0052][0053]
其中,iterationi表示第i个工作节点的迭代次数,s
′
表示参数服务器已收到的需要进行同步聚合的梯度份数,其中s
′
≤s,s为最快的工作节点和最慢工作节点间的epoch差值,weighti表示第i个工作节点基于迭代次数计算的差异化加权比例,gi表示第i个工作节点的梯度,g表示聚合后的梯度;
[0054]
②
聚合后的梯度g会被用于更新全局的模型参数,更新的方法如公式(1)所示,并且更新后的全局模型参数被发送给对应的s个工作节点;
[0055]
③
松弛计数器计数重置为0;
[0056]
④
依据迭代次数检测是否所有工作节点都已经完成了一个完整的epoch。
[0057]
优选的4,继优选的3中步骤
④
,如果是(即所有工作节点都已经完成了一个完整的epoch),则执行:参数服务器依据记录的训练epoch对所有工作节点进行排名,并计算最快工作节点和最慢工作节点的epoch差值s。
[0058]
优选的5,继优选的4,如果s>1,则更新同步组、异步组,将排名前s名的工作节点
放入同步组、剩余的工作节点放入异步组,反之s<=1,返回初始阶段步骤(1)。
[0059]
优选的6,继优选的3中步骤
④
,如果存在工作节点没有完成一个完整的epoch,则返回自适应同步阶段步骤(3)。
[0060]
优选的7,松弛机制,我们观察到,假如对快worker采用完全同步(即bsp)策略,ps通常需要在该同步等待中耗费很多时间,以致于排名较前的慢worker反客为主成为了最快的worker,并拉开了与最慢worker的差距,为了协调worker间的速度,避免不必要的等待,以尽量少的同步实现更轻微的梯度过时,我们对快worker采用松弛的同步策略,即依据实验观察,我们人为设定了一个适合的松弛因子,在参数服务器至少收到一份同步组的梯度后,启动松弛计数器开始计数,当该计数大于预设的松弛因子后,可以直接对已收到的梯度做聚合,而不需要等待收到所有快worker的梯度才进行聚合。实验观察发现,当松弛因子为3或5时,可以取得最佳的训练速度和精度。
[0061]
优选的8,模型性能评估机制,采用等式(4)、(5)、(6)比较bsp、asp和自适应同步机制的性能,实质是根据准确度在前后两个epoch的差值的滑动平均值,来评估分布式训练方案的收敛准确度和收敛时间,
[0062]
δacci=acc
i-acc
i-1
ꢀꢀ
(4)
[0063]
movei=β*move
i-1-(1-β)*δacciꢀꢀ
(5)
[0064]
biased_acci=movei/1-βiꢀꢀ
(6)
[0065]
其中,acci表示第i个epoch时的准确度,β用于控制滑动窗口的长度,movei和biased_acci分别是准确度的滑动平均和修正偏差。当biased_acci非常小的时候,意味着模型已经收敛了。
[0066]
优选的9,学习率的动态调整机制,按等式(7)动态衰减学习率α,
[0067][0068]
其中,α为初始学习率,decay_rate为衰减速率,该值小于1,其值越大,初始学习率衰减越快;e
min
取值为工作节点中最小的训练轮数;decay_α表示衰减的学习率,用于指导每一轮中模型参数的更新比例。
[0069]
优选的10,自适应同步屏障机制,其技术原理如下:在每一个epoch中,依据训练的epoch数,对所有工作节点进行排名,并计算最快工作节点和最慢工作节点之间的训练epoch差值,记该差值为s。若s>1,则在下一个训练epoch内,对排名前s名的工作节点(快workers)采用松弛的同步并行训练方案(松弛的bsp),且在该同步中,采用了差异化梯度聚合方法聚合梯度;对除前s名之外的工作节点(慢workers),则采用异步并行训练方案(asp)。
[0070]
与现有技术相比,本技术提供了一种加速分布式机器学习的自适应同步机制,以尽量少的同步实现更轻微的梯度过时,具备以下有益效果:
[0071]
(1)、本发明是一种自适应方法,在每一轮训练中,哪些工作节点采用bsp、哪些工作节点采用asp是自适应变化的,无需人为设定。
[0072]
(2)、本发明吸收了bsp和asp的优点、规避了各自的问题,训练速度比bsp更快,稳定性比asp更高。
[0073]
(3)、本发明可以像asp那样加速分布式训练,且不会引发严重的梯度过时问题。
[0074]
(4)、本发明提出了一种自适应同步机制,该机制是一种混合并行的训练方案,其
针对具有不同训练速度的工作节点采用不同的并行训练方案(松弛的bsp或asp),提高了并行训练效率。
[0075]
(5)、本发明改善了asp中的梯度过时问题,其中,为降低快梯度的影响,一个自适应同步屏障被增加到训练速度较快的工作节点中;而一种差异化加权的梯度聚合方法被提出用于降低同步屏障中慢梯度的影响。
[0076]
应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本技术。
附图说明
[0077]
图1为本发明自适应同步机制总体示意图;
[0078]
图2为本发明四个工作节点的自适应同步机制运行时示意图。
具体实施方式
[0079]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。
[0080]
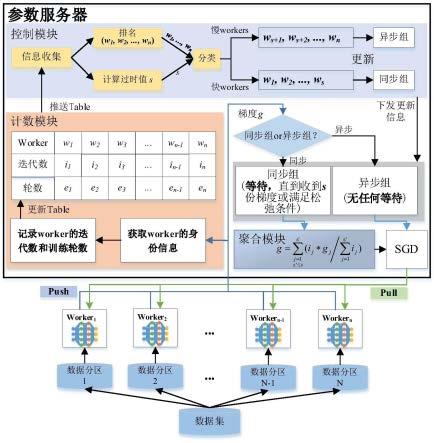
如图1-2所示,为吸收bsp和asp优点、规避各自问题,本发明基于参数服务器架构下提出一种自适应同步机制,该机制的系统总体设计如图1所示。首先,在训练初始阶段各个工作节点采用asp方案进行训练。然后,参数服务器在每一个epoch中都会检测最快工作节点和最慢工作节点间的过时值s,当s大于1个epoch时,参数服务器对排名前s名工作节点采用松弛的bsp方案,与bsp不同,松弛的bsp方案允许服务器松弛同步条件,即允许服务器等待一定迭代次数后,可以直接对已收到的梯度做聚合,而不需要等待收到所有梯度才进行聚合,且在该bsp方案中采用差异化加权的梯度聚合方法聚合梯度,而对于剩余的工作节点,因为它们的排名靠后,训练速度较慢,参数服务器对它们采用asp方案。最后,参数服务器在训练的每一轮中都会检测s,根据s以及工作节点训练速度的变化,针对各个工作节点自适应地采用不同并行训练方案(松弛的bsp或asp)。
[0081]
本技术提供了一种加速分布式机器学习的自适应同步机制,包括以下步骤:
[0082]
s1、在训练初始阶段各个工作节点采用asp方案进行训练;
[0083]
s2、服务器在每一个epoch中检测最快工作节点和最慢工作节点间的过时值s,当s大于1个epoch时,服务器对排名前s名工作节点采用松弛的bsp方案,与bsp不同,松弛的bsp方案允许服务器松弛同步条件,即允许服务器等待一定迭代次数后,可以直接对已收到的梯度做聚合,而不需要等待收到所有梯度才进行聚合,且在该bsp方案中采用差异化加权的梯度聚合方法聚合梯度,而对于剩余的工作节点,因为它们的排名靠后,训练速度较慢,服务器对它们采用asp方案;
[0084]
s3、在训练的每一轮中检测s,根据s以及工作节点训练速度的变化,针对各个工作节点自适应地采用不同并行训练方案(松弛的bsp或asp)。
[0085]
进一步的,实现自适应同步机制的步骤如下:
[0086]
s11、工作节点的实现:
[0087]
(1)各个工作节点独立加载一部分数据集,并计算损失(cost)、准确度(accuracy)以及梯度(gradient);
[0088]
(2)工作节点通过tcp通信协议推送梯度到参数服务器中;
[0089]
(3)等待接收来自参数服务器返回的最新的模型参数;
[0090]
(4)将最新的模型参数替换本地的模型参数,从而进行下一次迭代训练,即循环执行(1)(2)(3)(4)步骤;
[0091]
s12、参数服务器的实现分为两个阶段:初始阶段和自适应同步阶段,参数服务器的运行由初始阶段起始,其后逐步过渡到自适应同步阶段,且根据梯度过时的严重程度,初始阶段和自适应同步阶段会自适应地相互切换:
[0092]
初始阶段:
[0093]
(1)等待接收来自工作节点的梯度,同时记录其迭代次数和训练轮数(epoch);
[0094]
(2)依据迭代次数检测是否所有工作节点都已经完成了一个完整的epoch,如果否,执行以下1)和2)步骤后,然后返回初始阶段步骤(1);
[0095]
1)参数服务器直接使用收到的梯度更新全局的模型参数,更新的方法使用随机梯度下降,随机梯度下降如公式(1)所示:
[0096]wt+1
=w
t-decay_α*giꢀꢀ
(1)
[0097]
其中,w
t+1
表示保存在服务器中第t+1次迭代的全局模型参数,decay_α表示衰减的学习率,decay_α的计算如公式(7)所示,gi表示来自第i个工作节点的梯度。
[0098]
2)将最新的全局模型参数w
t+1
单播给对应的第i个工作节点;
[0099]
继步骤(2),如果是(即所有工作节点都已经完成了一个完整的epoch),则依据记录的训练epoch对所有工作节点进行排名,并计算最快工作节点和最慢工作节点的epoch差值s,其中:
[0100]
3)如果s<=1,服务器直接执行1)和2)步骤,然后返回初始阶段步骤(1);如果s>1,服务器将排名前s名的工作节点放入同步组,而剩余的工作节点放入异步组,接着执行(2)中的1)和2)步骤后,服务器进入自适应同步阶段:
[0101]
自适应同步阶段:
[0102]
(3)等待接收来自工作节点的梯度,在继承初始阶段的同时,继续记录工作节点的迭代次数和训练轮数(epoch);
[0103]
(4)如果此时聚合列表(即自适应同步阶段步骤(6)中所述的聚合列表)中已存在至少一份梯度,参数服务器启动松弛计数器,每收到一份梯度则松弛计数器计数加1;
[0104]
(5)判断接收到的梯度是否来自于同步组中的工作节点;
[0105]
(6)如果该份梯度来自于同步组中的工作节点,则执行以下操作:
[0106]
1)服务器不会立刻更新全局模型参数,而是将这份梯度添加到一个聚合列表;
[0107]
2)如果聚合列表中梯度份数不等于同步组中所有工作节点个数或者松弛计数器计数小于或等于预设的松弛因子,返回到自适应同步阶段的步骤(3);否则,此时对聚合列表中梯度做聚合,执行
①②③④
步骤:
[0108]
①
采用一种差异化加权的梯度聚合方法用于聚合梯度,该方法如公式(2)(3)所示:
[0109]
[0110][0111]
其中,iterationi表示第i个工作节点的迭代次数,s
′
表示参数服务器已收到的需要进行同步聚合的梯度份数,其中s
′
≤s,s为最快的工作节点和最慢工作节点间的epoch差值,weighti表示第i个工作节点基于迭代次数计算的差异化比例,gi表示第i个工作节点的梯度,g表示聚合后的梯度;
[0112]
②
聚合后的梯度g会被用于更新全局的模型参数,更新的方法如公式(1)所示,并且更新后的全局模型参数被发送给对应的s个工作节点;
[0113]
③
松弛计数器计数重置为0;
[0114]
④
依据迭代次数检测是否所有工作节点都已经完成了一个完整的epoch。
[0115]
继(6)中步骤
④
,如果是,即所有工作节点都已经完成了一个完整的epoch,则执行:依据记录的训练epoch对所有工作节点进行排名,并计算最快工作节点和最慢工作节点的epoch差值s,其中:如果s>1,则更新同步组、异步组,将排名前s名的工作节点放入同步组、剩余的工作节点放入异步组;反之s<=1,返回初始阶段步骤(1)。
[0116]
继(5)中步骤
④
,否则:返回自适应阶段步骤(3)。
[0117]
(6)如果该份梯度是来自于异步组中的工作节点,则执行初始阶段中的步骤1)和2);
[0118]
(7)循环执行步骤(3)(4)(5)(6)(7),直到工作节点训练结束。
[0119]
以上便是本发明自适应同步机制的详细实现步骤,为更好理解它的运行机制,本发明在图2中给出了自适应同步机制4个工作节点运行时的例子。如图2所示,初始阶段4个工作节点(对应图中的worker)都是从斜条纹矩阵块开始,这表示它们执行asp方案,对应步骤(1)(2)。当服务器检测到最快的工作节点worker1的训练epoch比最慢的工作节点worker4大于1(图中worker1比worker4多运行了3个epoch),此时前3名的工作节点(worker1为6个epoch、worker2为5个epoch、worker3为4个epoch)被增加同步屏障,即执行松弛的bsp方案,所以它们从斜条纹矩阵块转变为竖条纹矩阵块,该过程对应步骤(3)(4)(5)。而剩余训练速度慢的worker4(运行了3个epoch)则执行asp,所以worker4依旧是斜条纹矩阵块,对应步骤(6)。由于较快的worker被增加了同步屏障,所以它们的速度会慢下来,而较慢的worker执行asp,所以在同一时间内它可以比快worker运行更多的迭代。所以,可以看到,经过多次迭代,worker4和worker1的差距被拉近了,从相差3个epoch变为2个epoch。这个过程是自适应变化的,每一轮哪些worker执行bsp、哪些worker执行asp是根据最快worker和最慢worker间的epoch差值以及worker的排名自适应变化的,无需人为设定。
[0120]
自适应同步机制的运行过程:
[0121]
(1)根据所设置的mini-batch大小(人为设定),将数据集随机划分为若干份。
[0122]
(2)每个工作节点独立读取mini-batch的1/n,并计算梯度、损失等,n为工作节点的数量。
[0123]
(3)工作节点发送梯度到参数服务器,然后等待,直到参数服务器返回最新的模型参数。
[0124]
(4)参数服务器接收梯度,按前文提及的两个阶段进行相应的工作。
[0125]
(5)工作节点接收参数服务器返回的最新的模型参数,并用该最新的模型参数替
换本地模型参数,以进行下一次迭代训练。
[0126]
(6)迭代训练:运行过程(2)(3)(4)(5)共training-set-size/mini-batch-size次后返回过程(1),直到模型满足收敛条件后结束训练,其中training-set-size为训练集大小,mini-batch-size为mini-batch的大小。
[0127]
实验验证:
[0128]
(1)硬件设置
[0129]
本发明在openstack机器集群上进行了实验,openstack机器集群由3台曙光i840-g30服务器搭建而成。其中一台服务器作为控制节点,另外两台服务器作为计算节点。控制节点的配置为8核2.1ghz cpu、16gb ram和1tb disk。每个计算节点有8核2.1ghz cpu、64gb ram和1.8tb disk。计算节点1和计算节点2之间的物理链路总带宽为10gbps。在openstack机器集群中,我们使用nfv技术虚拟化了一个k=4的fat-tree网络拓扑,9台主机连接到该拓扑,其中一台主机作为参数服务器,另外8台主机作为工作节点。fat-tree网络拓扑中每个router配置1vcpu、512mb ram、2gb disk,9台主机配置4vcpu、10.5gb ram、128gb disk。
[0130]
(2)数据集
[0131]
本发明使用mnist、cifar10和cifar100数据集进行图像分类任务。mnist数据集有55000张训练图像(训练集),5000张验证图像(验证集),10000张测试图像(测试集),mnist为10分类的图像分类任务;而cifar10和cifar100两个数据集都有50000张训练图像和10000张测试图像。cifar10有10个类,而cifar100有100个类。为了提高模型的泛化能力,我们对cifar10和cifar100两个训练数据集都采用了mixup[6]数据增强方法。
[0132]
(3)基准
[0133]
本发明使用当前主流的分布式训练方案bsp、asp、ssp和dssp作为比较的基准,其中,ssp和dssp中的超参数设置均按照原论文中给出的最佳的超参数进行设置,ssp的过时阈值设置为3,dssp的过时范围设置为[3,12]。
[0134]
(4)模型结构
[0135]
本发明搭建了lenet-5、vgg-net-small和resnet-18-small神经网络结构来评估bsp、asp、ssp、dssp和自适应同步机制。本发明在表1中展示了vgg-net-small和resnet-18-small的模型结构(lenet-5为经典的网络,在此不再展示),其中,convx-y表示卷积核的大小为x、卷积核的数量为y;bn表示batch normalization[7],se表示se-net[8];avgpool和maxpool分别表示为平均池化层、最大池化层;在resnet-18-small中,每隔2个卷积层就有一个shortcut连接到下一层
[0136]
表1vgg-net-small和resnet-18-small的模型结构
[0137]
[0138][0139]
(5)收敛判断方法
[0140]
本发明利用等式(4)(5)(6)计算测试集准确度的前后两个epoch的差值的滑动平均值来评估分布式训练方案的收敛准确度和收敛时间,
[0141]
δacci=acc
i-acc
i-1
ꢀꢀ
(4)
[0142]
movei=β*move
i-1-(1-β)*δacciꢀꢀ
(5)
[0143]
biased_acci=movei/1-βiꢀꢀ
(6)
[0144]
其中,acci表示第i个epoch时的准确度,β用于控制滑动窗口的长度,movei和biased_acci分别是准确度的滑动平均和修正偏差。当biased_acci非常小的时候,意味着模型已经收敛了。实验中β设置为0.9,这意味着大约可以观察到10个epoch测试集准确度的波动情况,movei和biased_acci分别是测试集准确度的滑动平均和修正偏差。当biased_acci非常小的时候,这意味着模型已经收敛了,因为在大约10个epoch中,测试集准确度的波动都很小。传统的方法通常是提前设置一个非常大的训练epoch来保证模型的收敛性。然而,这种方法不是最优的,因为模型有可能在早期就收敛了,额外的epoch会增加训练时间。此外,如果训练时间过长,也容易导致模型过拟合。本收敛判断方法根据模型精度的趋势更好地对模型的收敛性做出更精确的判断,能够节约训练时间、避免过拟合。
[0145]
(6)学习率和批量大小设置
[0146]
本次所有实验均采用初始学习率0.9、工作节点读入的批量大小为125。且按等式(7)衰减学习率,
[0147][0148]
其中,α为初始学习率,即0.9;decay_rate为衰减速率,设为0.99,该值越大,学习率衰减越快;e
min
取值为工作节点中最小的训练轮数;decay_α用于指导每一轮中模型参数的更新比例,通过学习率的动态调整,能够使训练更稳定地过渡到收敛状态。
[0149]
(7)实验结果
[0150]
本发明分别在表2、表3、表4以及表5中给出了实验结果,实验中,本发明自适应同步机制记为a2s。实验结果表明,自适应同步机制(a2s)的收敛精度和收敛速度均优于当前主流的分布式并行训练方案(bsp、asp、ssp和dssp)。
[0151]
表2在biased_acci>0.002条件下,在mnist数据集上训练lenet-5的实验结果(a2s松弛因子设置为8)
[0152][0153][0154]
表3在biased_acci>0.002条件下,在cifar10数据集上训练vgg-net-small的实验结果(a2s松弛因子设置为5)
[0155][0156]
表4在biased_acci>0.002条件下,在cifar100数据集上训练vgg-net-small的实验结果(a2s松弛因子设置为5)
[0157]
[0158][0159]
表5在biased_acci>0.002条件下,在cifar10数据集上训练resnet-18-small的实验结果(a2s松弛因子设置为3)
[0160]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1