一种基于精英遗传聚类算法的学生成绩分析方法及系统
1.本发明属于数据分析技术领域,尤其涉及一种基于精英遗传聚类算法的学生成绩分析方法及系统。
背景技术:
2.学生考试成绩是学生学习情况优劣的重要评价指标,为教师和学生的安排部署,以及进一步调整教学工作提供了重要依据。在教学管理中,通常根据学生成绩进行学生分类,进而制定针对性教学策略。常规分类方法仅根据学生总成绩将学生分成优良中差等若干等级,但是这种机械式的划分方法导致同一类别的学生各科成绩通常并不相似,难以充分反应学生特点。
3.发明人发现,近些年来,根据聚类分析原理,部分学者进行了基于各科成绩相似性对学生成绩进行聚类划分的研究;聚类算法由于其简单高效的特性,在文档聚类,市场细分,图像分割,特征学习等方面得到了广泛的应用;但是聚类算法聚类结果并不稳定,其聚类效果往往依赖初值的选取,针对初值问题,一种解决思路根据算法属于原理,选取的初值尽量优,部分学者提出根据数据集的密度,选取密度大的数据对象作为初始聚类中心,提出根据数据对象的距离,选择距离最远的数据对象作为初始聚类中心,根据数据对象的轮廓系数,选择优秀个体作为初始聚类中心,等等;另一种解决思路是结合优化算法,选取的初值尽量多,部分学者提出将聚类算法和萤火虫算法、森林优化算法、遗传算法等算法相结合,增加初值的丰富度的同时,提高了算法跳出局部最优的能力,将聚类算法和智能优化算法相结合,以时间成本为代价,有效增强了聚类效果的稳定性。但是,比如以遗传算法为代表的智能优化算法本身存在易早熟、陷入局部最优等问题;同时,当前研究鲜有采用遗传聚类算法进行学生成绩分析,成绩聚类分析需进一步流程化、标准化。
技术实现要素:
4.本发明为了解决上述问题,提出了一种基于精英遗传聚类算法的学生成绩分析方法及系统,本发明尽可能多的保留上一代的优秀个体,进化到下一代。
5.为了实现上述目的,本发明是通过如下的技术方案来实现:
6.第一方面,本发明提供了一种基于精英遗传聚类算法的学生成绩分析方法,包括:
7.获取学生成绩数据;
8.剔除无效数据,并计算学生成绩数据的特征值;
9.依据特征值,对学生成绩数据进行归一化处理;
10.基于精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,得到聚类结果。
11.进一步的,剔除无效数据是指剔除缺考学生的成绩数据。
12.进一步的,学生成绩数据的特征值包括最大值、最小值、中位数、均值和方差。
13.进一步的,归一化后的成绩等于归一化前的成绩减去最小值的差,与最大值与最
小值的差的比值。
14.进一步的,对归一化处理后的学生成绩数据进行聚类,包括:
15.令聚类中心k=1;
16.k=k+1,遗传算法代数g=1;
17.种群初始化,初始中心随机选择学生成绩;
18.采用k均值聚类算法更新计算聚类中心;
19.判断是否满足遗传算法,若满足,则g=g+1,进行精英遗传操作;若不满足,则判断是否满足聚类算法,若满足,则跳回k=k+1,遗传算法代数g=1处;若不满足,则输出聚类结果。
20.进一步的,精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,每次遗传操作后随机生成r
newp
个个体替换掉适应度最差的个体,计算公式如下:
21.r
newp
=(α0+α1μ
pop
)r
pop
[0022][0023]
式中:α0和α1表示常数;μ
pop
表示种群优劣评价指标;f
max
、f
ave
和f
min
分别表示种群最大适应度、平均适应度和最小适应度;r
pop
表示种群个体数量。
[0024]
进一步的,精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,采用组合交叉,包括整合交叉和常规交叉,两个体交叉时,剔除成绩相同科目后,再进行常规交叉;
[0025]
当相似度大于预设的阈值时采用整合交叉,否则采用常规交叉;
[0026]
比较父适应度和子适应度大小,若子代个体不如父代个体,则保留父代个体,进入下一代种群;否则,子代个体顺利进入下一代。
[0027]
第二方面,本发明还提供了一种基于精英遗传聚类算法的学生成绩分析系统,包括:
[0028]
获取学生成绩数据;
[0029]
剔除无效数据,并计算学生成绩数据的特征值;
[0030]
依据特征值,对学生成绩数据进行归一化处理;
[0031]
基于精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,得到聚类结果。
[0032]
第三方面,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了第一方面所述的基于精英遗传聚类算法的学生成绩分析方法的步骤。
[0033]
第四方面,本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了第一方面所述的基于精英遗传聚类算法的学生成绩分析方法的步骤。
[0034]
与现有技术相比,本发明的有益效果为:
[0035]
1、本发明首先剔除无效数据,并计算学生成绩数据的特征值;然后依据特征值,对学生成绩数据进行归一化处理;最后基于精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类;采用精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,尽可能多的保留上一代的优秀个体,进化到下一代,实现了成绩聚类分析的流程化和的标准化;
[0036]
2、本发明每次遗传操作后随机生成r
newp
个个体替换掉适应度最差的个体,避免了因学生成绩通常数据规模较大,容易出现早熟的问题;
[0037]
3、学生成绩往往相似度高,聚类分析时,经常出现两个甚至多个学生某科甚至多科成绩相同的情况,常规交叉,将出现无效交叉现象;因此,本发明中规定阈值,当相似度高于阈值时采用整合交叉,否则采用常规交叉。
附图说明
[0038]
构成本实施例的一部分的说明书附图用来提供对本实施例的进一步理解,本实施例的示意性实施例及其说明用于解释本实施例,并不构成对本实施例的不当限定。
[0039]
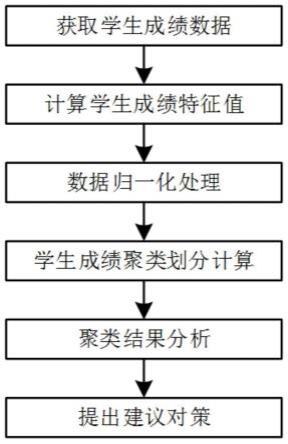
图1为本发明实施例1的流程图;
[0040]
图2为本发明实施例1的k均值聚类算法计算流程图;
[0041]
图3为本发明实施例1的精英遗传算法计算流程图;
[0042]
图4为本发明实施例1的精英遗传聚类算法计算流程图;
[0043]
图5为本发明实施例1的不同聚类次数下的最大ch指标;
[0044]
图6为本发明实施例1的不同k值下的ch指标。
具体实施方式:
[0045]
下面结合附图与实施例对本发明作进一步说明。
[0046]
应该指出,以下详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0047]
实施例1:
[0048]
本实施例提供了一种基于精英遗传聚类算法的学生成绩分析方法,包括:
[0049]
s1、获取学生成绩数据,剔除缺考学生成绩数据;
[0050]
s2、计算学生成绩数据的特征值;特征值可以包括最大值、最小值、中位数、均值和方差等;
[0051]
s3、依据特征值,对学生成绩数据进行数据min-max归一化处理;
[0052]
s4、基于精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,得到聚类结果;
[0053]
s5、聚类结果分析;结合学生成绩特征值,对比分析不同类学生成绩占比及成绩分布特征;
[0054]
s6、依据得到聚类结果,提出建议对策;根据学生成绩特征,对不同类学生提出针对性建议,及时调整学习策略,提高学习成绩。
[0055]
步骤s3中,进行数据min-max归一化处理,计算公式如下:
[0056][0057]
式中:xj和分别表示标准化前后第j个科目的成绩;x
j,max
和x
j,min
分别表示第j个科目的成绩最大和最小值。
[0058]
步骤s4中,对归一化处理后的学生成绩数据进行聚类划分计算包括以下步骤:
[0059]
s4.1、计算开始,输入数据,设定参数,令聚类中心k=1;
[0060]
s4.2、k=k+1,遗传算法代数g=1;
[0061]
s4.3、种群初始化,初始中心随机选择现有学生成绩;
[0062]
s4.4、采用常规聚类方法更新计算聚类中心;
[0063]
s4.5、判断是否满足遗传算法继续进行判据,若满足,则进行下一步;若不满足,则跳到步骤s4.7;
[0064]
s4.6、g=g+1,进行精英遗传操作;
[0065]
s4.7、判断是否满足聚类算法,若满足,则跳回步骤s4.2;若不满足,则进行下一步;
[0066]
s4.8、计算结束,输出聚类结果。
[0067]
步骤s4.4中,采用的常规聚类方法可以为k均值聚类算法(k-means算法),k-means算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大;该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标;常用公式定义如下:
[0068]
欧式距离,欧式距离表示两学生成绩间的相似度,距离越小,两成绩相似度越大;任意两学生成绩距离计算公式如下:
[0069][0070]
式中:xa和xb分别表示i=a和i=b时的学生成绩数据对象;n表示学生成绩科目数;wj表示第j个科目的权重;x
aj
和x
bj
分别表示xa和xb的第j个科目的成绩。
[0071]
类内聚合度,类内聚合度表示类内数据对象的相似度,类内聚合度越小,类内相似度越大;计算公式如下:
[0072][0073]
式中:k表示学生成绩数据对象的聚类中心个数;x表示学生成绩数据对象;ch和ch分别表示第h个类所包含的数据对象和第h个类的中心。
[0074]
类间聚合度,类间聚合度表示类间对象的相似度,类间聚合度越大,类间相似度越小;计算公式如下:
[0075][0076]
式中:表示第h个类所包含的学生的数量;co表示所有学生的平均成绩。
[0077]
ch(calinski-harabasz)指标,ch指标是基于类内聚合度和类间分离度定义的聚类评价指标,ch指标越大,类间相似度越小,类内相似度越大,聚类效果越好;计算公式如下:
[0078][0079]
式中:m表示所有学生的个数。
[0080]
所述k-means聚类算法步骤如下:
[0081]
s4.4.1、计算开始,输入数据,令聚类中心数k=1;
[0082]
s4.4.2、k=k+1,随机生成k个聚类中心;
[0083]
s4.4.3、计算各对象与各聚类中心的欧式距离;
[0084]
s4.4.4、根据距离最小原则,更新对象所在类;
[0085]
s4.4.5、计算各类均值,更新各聚类中心;
[0086]
s4.4.6、判断ch值是否发生变化,若是,则跳回步骤s4.4.3;若否,则进行下一步不;
[0087]
s4.4.7、判断是否满足聚类算法继续进行判据,即k是否≤m1/2,若是,则跳回步骤s4.4.2;若否,则进行下一步;
[0088]
s4.4.8、计算结束,输出聚类结果。
[0089]
遗传算法虽然具有全局寻优能力强、收敛性好等优点,被广泛应用于复杂的规划领域。为解决传统聚类算法存在的初始中心点敏感、局部收敛等问题,其中的常用的一个解决办法就是将遗传算法和聚类算法相结合。虽然遗传算法能够在一定程度上改善聚类算法的不足,但是遗传算法本身也存在着早熟、局部收敛等问题,为了解决这些问题,本实施例中采用一种精英遗传策略;精英策略就是尽可能多的保留上一代的优秀个体,进化到下一代。
[0090]
所述精英策略在一定程度上提高了遗传算法的全局收敛性,为应用至学生成绩聚类分析,对精英遗传算法做进行改进如下:
[0091]
进化团队,学生成绩通常数据规模较大,容易出现早熟问题,设计进化团队,即每次遗传操作后随机生成r
newp
个个体替换掉适应度最差的个体,计算公式如下:
[0092]rnewp
=(α0+α1μ
pop
)r
pop
[0093][0094]
式中:α0和α1为常数,表示设定参数;μ
pop
表示种群优劣评价指标;f
max
、f
ave
和f
min
分别表示种群最大适应度、平均适应度和最小适应度;r
pop
表示种群个体数量。
[0095]
组合交叉,组合交叉包括整合交叉和常规交叉;整合交叉即两个体交叉时,剔除其成绩相同科目后,再进行常规交叉。
[0096]
定义两个体的相似度如下:
[0097][0098]
式中:n
sam
表示两个体成绩相同的科目数;n表示学生成绩科目数。
[0099]
学生成绩往往相似度高,聚类分析时,经常出现两个甚至多个学生某科甚至多科成绩相同的情况,常规交叉,将出现无效交叉现象;因此,规定阈值当时采用整合交叉,否则采用常规交叉。
[0100]
自适应交叉变异,为保证种群整体进化方向趋于最优解,减少精英个体交叉变异率,设计与个体适应度和进化代数相关的自适应交叉率pc和变异率pm,计算公式如下:
[0101][0102][0103]
式中:α3~α8分别为常数,表示设定参数,且有0《α5《α4《α3《1、0《α8《α7《α6《1;f
pre
表示当前即将交叉或变异的个体适应度;g和g分别表示当前代数和总代数。
[0104]
精英保留,遗传算法交叉变异后,经常出现子代个体适应度甚至不如父代个体适应度的情况。为保留父代精英基因,操作如下:比较父子适应度大小,若子不如父,则保留父代个体,进入下一代种群;否则,子代个体顺利进入下一代。
[0105]
所述精英遗传算法包括以下步骤:
[0106]
计算开始,设定参数,令算法代数g=1;
[0107]
生成初始种群,计算种群适应度;
[0108]
判断是否满足聚类算法继续进行判据,即g是否≤g,其中,g表示预设的最大迭代次数;若是,则进行下一步;若否,则计算结束;
[0109]
g=g+1;
[0110]
生成进化团队替换适应度差的个体;
[0111]
自适应混合交叉;
[0112]
自适应变异;
[0113]
计算种群适应度,保留父代精英个体;
[0114]
计算结束,输出优化结果。
[0115]
本实施例中,在传统遗传聚类算法的基础上,采用精英策略,保证了优秀个体顺利进入下一代;设计了进化团队,避免了算法早熟问题,给出了组合交叉方法,提高算法计算效率,相对于传统k-means聚类算法和遗传算法,本实施例中的精英遗传聚类算法聚类结果得到了有效提高,并在学生成绩分析领域得到了良好的应用。
[0116]
为了进一步说明上述聚类方,本实施例进行了案例分析;
[0117]
本实施例中,可以选取iris数据集,分别采用方法1:聚类算法、方法2:遗传聚类算法、和方法3:精英遗传聚类算法进行聚类计算,对3种算法性能进行对比验证。
[0118]
为保证结果有效性,聚类有效性评价指标均采用ch指标,最佳聚类数获取方法均采用本实施例中的方法。遗传聚类算法和精英遗传聚类算法的种群规模均设置为50,迭代次数50。
[0119]
将各个方法分别计算10次,结果表明,各方法最优聚类数均为3;k=3时,各方法得到的ch指标见表1。
[0120]
表1三种方法结果对比
[0121][0122]
可以看到,方法3均值为4983.58,明显优于方法1和方法2,方法2最小值与方法1相等,说明方法2跳出局部最优能力依旧不足。
[0123]
改变聚类次数,统计各个方法最优聚类结果随聚类次数变化曲线如图5。可以看到,方法3最优聚类结果基本保持不变,具有极强的寻优能力;方法2相较于方法1,波动性较小,但稳定性仍稍显不足。
[0124]
因此,相较于方法1和方法2,本实施例中的精英聚类遗传算法寻优能力强,稳定性高。
[0125]
本实施例中,以某小学某年级103名学生成绩为例,研究本文所提遗传聚类算法有效性。学生成绩包括语文、数学、英语和综合四科,各科成绩权重依次为0.3、0.3、0.2和0.2。学生原始成绩见附表1。
[0126]
经计算,该年级学生成绩特征值见表2。
[0127]
表2学生成绩特征值(单位:分)
[0128][0129]
利用遗传聚类算法对学生成绩进行聚类计算后,得到ch指标值随聚类中心个数(k∈[2,10])变化曲线如图6。可以看到,k=5时,ch指标最大;故最优聚类个数为5,此时学生各聚类中心成绩见表3。
[0130]
表3学生各聚类中心成绩(单位:分)
[0131][0132]
可以看到,第1类学生总成绩最高,达到了93.36分,共5人,该类学生各科成绩均较高,基本都在最高分左右,不存在弱势科目;第2类学生总成绩较高,共16人,但综合成绩较低,仅77.25分,甚至低于均值82.09分,偏科严重;第3类学生总成绩较高,共29人,但语文成绩较低,仅83.38分,处于全年级平均水平,稍微有些偏科,且相较于第1、2类,英语成绩有待进一步加强;第4类学生总成绩一般,各科均在80-90分之间,但又普遍略低于全班平均水平;第5类学生总成绩最差,仅78.61分,各科成绩严重低于平均成绩,基本都处于垫底水平。
[0133]
因此,针对第1类学生,应继续保持当前学习状态的同时,力争成绩更进一步;针对第2类学生,应有针对性地加强综合能力的培养,注重培养个人兴趣爱好,充分发挥课余时间,加强体育锻炼,提高自己的总成绩;针对第3类学生,应着重语文成绩的提高,同时,英语应根据自身实际情况做进一步提高,语文、英语都是偏积累性的学科,平时应注重多读多看多积累;针对第4类学生,应有计划的、逐步的提高个人各科成绩,或可尝试改变现有学习方法,此类学生各科中庸,最容易受到教师忽视,学生想提高个人成绩,自觉性尤为重要;针对第5类学生,应深入了解其成绩差的原因,力争获取家长支持,学校家庭共同努力,全方位引导激发其学习兴趣,逐步提高其学习过程中的参与感和幸福感,早日摆脱垫底现状。
[0134]
附表4某小学某年级学生成绩(单位:分)
[0135]
[0136]
[0137][0138]
实施例2:
[0139]
本实施例提供了一种基于精英遗传聚类算法的学生成绩分析系统,包括:
[0140]
获取学生成绩数据;
[0141]
剔除无效数据,并计算学生成绩数据的特征值;
[0142]
依据特征值,对学生成绩数据进行归一化处理;
[0143]
基于精英遗传聚类算法,对归一化处理后的学生成绩数据进行聚类,得到聚类结果。
[0144]
所述系统的工作方法与实施例1的基于精英遗传聚类算法的学生成绩分析方法相同,这里不再赘述。
[0145]
实施例3:
[0146]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了实施例1所述的基于精英遗传聚类算法的学生成绩分析方法的步骤。
[0147]
实施例4:
[0148]
本实施例提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了实施例1所述的基于精英遗
传聚类算法的学生成绩分析方法的步骤。
[0149]
以上所述仅为本实施例的优选实施例而已,并不用于限制本实施例,对于本领域的技术人员来说,本实施例可以有各种更改和变化。凡在本实施例的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本实施例的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1