社会场景自动识别及其检查计划动态生成方法与流程
1.本发明属于社会场景自动识别技术领域,尤其是涉及一种社会场景自动识别及其检查计划动态生成方法。
背景技术:
[0002]“综合查一次”系统通过自动计算和匹配场景生成相应场景的“红黄绿”三色预警,根据预警规则触发检查计划,在检查人员添加检查任务后,系统一键生成检查清单,检查清单的内容主要包括每个场景的检查项和相应的检查部门,并自动派发给相关部门,从而避免了随意查和重复查。
[0003]
但是,当前运行系统仍然存在着一些不足,例如现有的运行系统已知场景有限,当输入数据场景不属于已知场景中的一个时,系统将无法识别该未知场景,而系统本身又不利于相关部门及早发现检查新场景和检查新问题,此外,现有运行系统的检查清单格式固定,民众投诉的突出问题对应的检查项未置顶,无法突出重点问题,容易出现合格场景被频繁(多次重复)抽查的问题。
技术实现要素:
[0004]
本发明的目的是针对上述问题,提供一种社会场景自动识别及其检查计划动态生成方法。
[0005]
为达到上述目的,本发明采用了下列技术方案:
[0006]
一种社会场景自动识别及其检查计划动态生成方法,包括以下步骤:
[0007]
s1.接收开放式社会性事件文本;
[0008]
s2.分别抽取每个社会性事件文本中的场景和事件;
[0009]
s3.将场景与场景舱中的已知场景进行匹配,根据匹配结果将相应的场景归类为已知场景或未知场景;
[0010]
s4.将已知场景列入待处理清单,将未知场景列入候选场景列表;
[0011]
s5.将候选场景列表中满足推送条件的场景,或场景及相应事件推送给相关部门以供相关部门添加相应未知场景至场景舱;
[0012]
基于待处理清单动态生成检查清单,并基于检查清单和预警规则向相关部门派发检查工作。
[0013]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s1中,所述的开放式社会性事件文本包括舆情热点和公众诉求;
[0014]
对于舆情热点进行社会性事件甄别,采用网络爬虫从各大新闻载体中爬取娱乐、体育和国际版块以外的新闻报道以筛选出新闻类社会性事件后进入步骤s2;
[0015]
对于公众诉求,根据数据字排除咨询类事件以筛选出民生类社会性事件后进入步骤s2。
[0016]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s1中,通过以下
方式从新闻载体中筛选出新闻类社会性事件:
[0017]
s11.锁定舆情热点,累计相应事件在所有新闻载体中的浏览量、评论数、点赞量、转发量,并基于浏览量、评论数、点赞量、转发量判断是否满足热点条件,若是,则将相应事件作为舆情热点;
[0018]
s12.排除非社会性事件,提取步骤s21中锁定的舆情热点事件,采用经过训练的bert模型判断相应舆情热点是否为娱乐、体育和国际的非社会性事件以排除非社会性事件进而筛选出新闻类社会性事件。
[0019]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s2具体包括:
[0020]
s21.根据百度paddlenlp的中文全词类序列标注工具生成标注序列,形如:t
ner
={(word1,tag1),(word2,tag2),...,(wordm,tagm)},其中tagi的值域为中文全词类的实体标签,wordi为tagi对应到输入文本中的词串;
[0021]
s22.基于数据结构双向链表合并序列t
ner
中相邻同标签、不及物动词和助词、副词和修饰词、场景词和方位词等词串得到新的标注序列t
′
ner
;
[0022]
s23.将序列t
′
ner
分割成t
word
和t
tag
两个序列后,采用多关键词匹配算法 wumanber找到场景词标签在t
tag
序列中的位置,并根据位置将t
word
和t
tag
划分成子句集;
[0023]
s24.从中文全词类序列标注工具的标签结果集中统计出主谓宾、主谓及动宾的事件抽取的模式串;
[0024]
s25采用wumanber算法从t
tag
子串中找出事件模式串的匹配位置,并根据匹配位置在对应的t
word
子串中查找主谓宾、主谓及动宾词串以抽取场景和事件;
[0025]
s26当事件抽取模板对当前句子抽取失效时,采用依存句法分析器抽取文本的主谓宾三元组作为事件抽取的补充。
[0026]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s3中的匹配为相似度匹配,先对步骤s2中抽取出来的主谓宾、主谓及动宾词串进行同义词替换,比如将“乱停车”和“不按规定停放车辆”统一为“乱停车”,便于准确统计场景事件的发生次数,然后与场景舱中的已知场景进行相似度匹配。
[0027]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s3具体包括:
[0028]
将属于同一场景的事件归入相应场景得到格式为场景x[事件1,事件 2,...,事件n]的场景事件集;
[0029]
将每个场景x依次与场景场景舱中的已知场景进行相似度匹配,根据最大相似度值将场景x判断为已知场景或未知场景;若场景x判断为已知场景则为该场景增加“相似场景名称”属性。
[0030]
具体方式为:将每个场景x依次与场景舱中的已知场景[y1,y2,...,yn] 进行相似度匹配:
[0031]
先用腾讯词向量将场景x以及yi,i∈[1,2,...,n]转换成词嵌入形式,然后采用余弦夹角公式依次计算x和yi的相似度,得到数组 [sim(x,y1),sim(x,y2),...,sim(x,yn)],如果max(sim(x,yi)),i∈ [1,2,...,n]大于设定的阈值,就将场景x判断为已知场景,否则为未知场景。若判断为已知场景,同时将max(sim(x,yi))对应的场景yi作为场景x 的“相似场景名称”属性添加到场景x的属性字段中,便于在后续检查清单动态生成过程中无需计算,直接减少重复计算根据该字段从场景仓中调用相应的检查清单。
[0032]
步骤s4具体包括:
[0033]
将已知场景x及其事件集列入待处理清单,将未知场景x及其事件集列入候选场景列表。
[0034]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s5具体包括:
[0035]
对候选场景列表中各未知场景x累加事件数量,当未知场景x的事件数量n达到设定数量值时,将相应场景x或及其事件集推送给相关部门,由相关部门协同领域专家将新场景x添加至场景舱作使其为已知场景。
[0036]
在上述的社会场景自动识别及其检查计划动态生成方法中,所添加的新场景的内容包括场景名称和相应场景的检查清单,及检查清单中新增检查项与检查问题的映射关系。一个检查清单通常有多个检查项目,一个检查项目可以映射到多个检查问题,一个检查问题也可以映射到多个检查项目。
[0037]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s5还包括:对各未知场景x中的各事件进行新颖性判断,对一个未知场景x协同事件累计数和事件新颖性判断其是否满足推送条件。
[0038]
在上述的社会场景自动识别及其检查计划动态生成方法中,步骤s5中,检查清单动态生成方法包括:
[0039]
s51.从场景舱中匹配待处理清单中所有已知场景x的场景名;
[0040]
s52.根据场景名从场景舱中调取相应的检查清单,并将检查清单中的所有检查项条目的分值均设为m;
[0041]
s53.对场景x的各事件分别识别检查问题;
[0042]
s54.对于识别出来的每个检查问题,根据检查问题和检查项映射表,将检查清单中对应的检查项累加所映射检查问题的发生次数;
[0043]
s55.根据分值按值倒叙排列检查清单的检查项目以形成动态检查清单。
[0044]
本发明的优点在于:
[0045]
本方案以社会治理领域场景和事件要素为基础,多渠道多方式采集事件,将事件进行预处理并筛选出社会性事件,通过系列算法将权重高的未知场景反映给相关部门,便于有关部门及时为社会性事件增加新场景和编写新场景的检查清单,从而保障社会长期稳定有序发展。而已知场景动态检查计划生成能够实现场景突出问题重点检查重点提醒,并且弱化检查长期合格的检查项目,有力地践行“综合查一次”的便民宗旨。
附图说明
[0046]
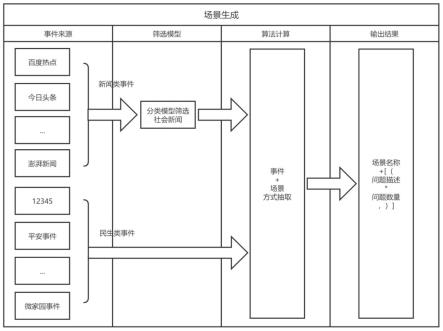
图1为本发明社会场景自动识别及其检查计划动态生成方法中基于开放数据生成场景事件集的过程示意图;
[0047]
图2为本发明社会场景自动识别及其检查计划动态生成方法中未知场景识别流程图;
[0048]
图3为本发明社会场景自动识别及其检查计划动态生成方法中检查清单动态生成流程图。
具体实施方式
[0049]
下面结合附图和具体实施方式对本发明做进一步详细的说明。
[0050]
本实施例提供的一种社会场景自动识别及其检查计划动态生成方法主要包括以下步骤:
[0051]
1、收集开放式社会性事件,如图1第1、2列所示,本方案中开放式社会性事件数据搜集方式分为以下两种:一是新闻类事件,采用网络爬虫程序从各大新闻载体爬取,包括新闻门户网站、微博等,新闻门户网站主要有头条地区性事件排行榜、当地新闻热点网站论坛、百度新闻、澎湃新闻等,微博主要有新浪微博等;二是民生类事件。新闻网站爬取的新闻类事件数据需要进行社会性事件甄别将娱乐、体育、国际等事件排除,得到新闻类社会性事件;民生类事件主要是咨询和投诉类事件,排除咨询类事件后余下默认为民生类社会性事件,可以直接进行使用处理,根据数据表字段排除咨询类后余下默认为民生类社会性事件。
[0052]
具体地,本实施例通过经过训练的bert预训练模型筛选媒体报道中的社会性事件,bert预训练模型是google发布的一款基于transformer框架的双向编码器语言表征模型,广泛适用于自然语言处理任务,具体方式为:
[0053]
舆情热点计算,累计相应事件在所有新闻载体中的浏览量、评论数、点赞量、转发量,并基于浏览量、评论数、点赞量、转发量判断是否满足热点条件,若是,则将相应事件作为舆情热点;是否满足热点条件的规则由技术人员根据实际情况确定,例如可以将所有事件设定有统一的热点判断标准,也可以根据报道事件的标题,将事件分为几大类,每一类事件都有各自的热点判断标准,如“交通”相关的事件热点标准是浏览量超过50 万或评论数超过1万,“医疗”相关的事件热点标准是浏览量超过100万或评论数超过2万或转发量超过2万等等。
[0054]
去除舆情热点文本中文字信息以外的内容形成训练语料集s,并人工标注训练语料集的预测变量,娱乐、游戏、体育、国际等类的新闻报道作为负样本,使用yi=-1表示文本为非社会性事件文本,yi=+1表示新闻类社会性事件;
[0055]
将语料集s按照8:2分为s
train
和s
test
,对s
train
和s
test
中的每个句子文本通过bert模型的分字工具berttokenizer进行编码,将文本序列转化为基于字的向量表示vs;
[0056]
将向量形式的语料标注和作为bert预训练模型的输入,输送至 bert模型进行二元分类,这里yi∈{+1,-1},且i∈(1,2,...,m)∪(1,2,...,n)。
[0057]
本实施例采用bert预训练模型的二分类算法将社会性事件过滤并存储于数据库,用于下一步场景事件提取使用,将娱乐、体育、国际等事件排除,得到新闻类社会性事件,有利于下一步事件分析。
[0058]
2、场景、事件提取,如图1第3列所示,将筛选得到的开放式社会性事件文本按照百度paddlenlp标注场所和组织机构类标签进行句子切割以抽取场景和事件。
[0059]
paddlenlp是聚合众多百度自然语言处理领域自研算法以及社区开源模型,其功能包括中文全词类实体识别、情感分析等。具体地,以上按照百度paddlenlp标注场所和组织机构类标签进行句子切割的具体方式为:
[0060]
根据百度paddlenlp的中文全词类序列标注工具生成标注序列 t
ner
={(word1,tag1),(word2,tag2),...,(wordm,tagm)},其中tagi的值域为中文全词类的66个实体标签,
wordi为tagi对应到输入文本中的词串, i=1,2,...,m;
[0061]
基于数据结构双向链表合并序列t
ner
中相邻同标签、不及物动词和助词、副词和修饰词、场景词和方位词等词串得到 t
′
ner
={(word1,tag1),(word2,tag2),...,(wordn,tagn)},用于减少tag匹配模式串库的规模;
[0062]
将序列t
′
ner
分裂成t
word
={word1,word2,...,wordn}和 t
tag
={tag1,tag2,...,tagn}两个序列,场景词标签包括场所类:交通场所、景点、楼盘住宅、世界地区类、住宿场所、餐饮场所等,以及组织机构类:国家机关、企事业单位、教育组织机构、居民服务机构、医疗卫生机构、体育组织机构、金融组织机构等。将场景词标签作为关键词匹配算法 wumanber的查询项,构造shift和hash这两张hash表,搜索出所有匹配项在t
tag
序列中的位置坐标,根据位置坐标将t
word
和t
tag
分别划分为子序列集合:和其中其中
[0063]
从中文全词类序列标注工具的标签结果集中学习出主谓宾、主谓及动宾等事件抽取的标签模式串,诸如“物体类修饰词场景事件”、“物体类场景事件物体类”、“物体类感官特征修饰词”、“场景事件”、“物体类场景事件”等;
[0064]
将事件抽取标签模式串作为wumanber算法(多模式匹配算法)的查询项,从各个子句中抽取出匹配到的事件模式串在中的位置坐标,并根据位置坐标从序列中找到对应的主谓宾、主谓及动宾词串以抽取场景和事件;
[0065]
考虑到事件抽取模板定义的有限性,当事件抽取模板对当前句子抽取失效时,引入依存句法分析器(spacy)作为抽取任务的补充,其作用是通过分析句子中词语间的依存关系来提取当前句子的主语、谓词、宾语作为事件三元组。
[0066]
3、未知场景自动生成,场景分为已知场景和未知场景。已知场景是相关部门凭借历年工作经验事先定义的,譬如:“游泳馆”一件事、“餐馆”一件事和“商超”一件事等,并且不同的场景设置不同的检查项目,未知场景是已知场景范围以外的场景。如图1第四列所示,本方案将抽取的事件结果按照场景进行组织,输出形式为:场景x[事件1,事件2,......,事件n],x表示相应场景名称,事件i:=《主、谓、宾》三元组。将属于同一场景x的事件并入该场景过程中,优选定义有同义词词表,采用前缀树 trie树算法将同义词词表索引,对抽取出来主谓宾、主谓及动宾的词串进行同义词替换,用以标准化事件词串;基于词向量word2vec+kmeans的词聚类算法建立无关词过滤表,用以过滤无意义的事件词串。如图2所示,对于每个场景x,采用腾讯词向量和余弦夹角公式依次计算场景x与场景舱中每个已知场景yi,i∈[1,2,...,n]的相似度值,得到数组 [sim(x,y1),sim(x,y2),...,sim(x,yn)],将max(sim(x,yi))与设定的阈值比较,若满足阈值则将场景x判定为已知场景,并列入待处理清单;不满足阈值的则判定为未知场景,并列入候选场景列表。同时,对于判定为已知场景的场景x,将max(sim(x,yi))对应的场景yi作为场景x的“相似场景名称”属性添加到场景x的属性字段中。
[0067]
将候选场景列表中满足推送条件的未知场景或者连同它的n个事件推送给相关部门进行人工确认将其添加到系统的场景舱,循环往复从而扩充已知场景的类别。相关部门协同领域专家审核确认的n个未知场景添加到“综合查一次”场景舱后,场景舱中的场景数
码更新至60+n,从而实现场景动态更新功能,为“综合查一次”能够始终随着时代的发展而更新提供方便且可行的技术支持。在添加新场景的同时,相关部门需组织领域专家编写相应新场景的检查清单,检查清单包括若干检查项和检查部门,同时需编写检查项和检查问题的映射关系等知识库。
[0068]
进一步地,在投入使用时可以对事件进行归类,也可以不对事件进行归类,当对事件进行归类时,通过主谓宾等词性抽取、同义词替换、关键词匹配等方式将相同事件归为一类,并将场景x[事件1,事件2,......,事件n]的场景事件集替换为场景x[{事件1,频率1},{事件2,频率 2},......,{事件n,频率n}]。
[0069]
具体地,这里的推送条件可以是场景x的事件累积发生数,例如当场景x的事件n的n值为达到设定值时视相应的未知场景满足推送条件。推送条件也可以指其他指标,例如场景x中的事件新颖性指标,如果场景x 中有一个事件i新颖性程度较高,如第一次出现,则视相应的未知场景满足推送条件。或者各种指标按照权重计算权重值,如每个事件数量权重均为1,当一个事件第一次出现时,将其权重置为5,当一个未知场景的权重值达到一定值时视相应的未知场景满足推送条件。
[0070]
4、已知场景检查清单动态生成,如图3所示,已知场景检查清单动态生成的前提为:已知场景的检查清单都已存在并经过社会治理领域专家确认,而且检查清单中的检查项和检查问题都已建立映射关系。本方案采用基于关键词表和多标签分类技术相结合的方法识别处理文本中的检查问题,此处的检查问题概念引用cj/t 214—2007《城市市政综合监管信息系统管理部件和事件分类、编码及数据要求》中的事件概念:人为或自然因素导致城市市容环境和环境秩序受到影响或破坏,需要城市管理专业部门处理并使之恢复正常的现象和行为,比如油烟扰民、渣土运输、施工噪音等。
[0071]
对于待处理清单中的每个场景x,根据“相似场景名称”属性,根据相似场景名称属性从场景舱中调取相应的检查清单,并将检查清单中的所有检查项条目的分值均设为1,也可以设为其他数值,如2,3...,然后采用基于关键词表和多标签分类技术相结合的方法识别处理文本中的检查问题,对于识别出来的每个检查问题,根据检查问题和检查项映射表,将对应的检查项累加该检查问题的发生次数,最后根据分值按值倒叙排列检查清单的检查项目,从而形成当时当下的动态检查清单。
[0072]
检查问题的识别同样可以采用bert预训练模型进行实现:
[0073]
s721根据cj/t 214—2007定义的检查问题类别,以及基于聚类算法canopy-kmeans算法的公众诉求文本聚类结果,建立面向社会综合治理领域的检查问题分类体系;
[0074]
s722基于检查问题分类体系,人工标注语料建立多标签分类器的训练和测试语料;
[0075]
s723将训练和测试语料的每个事件内容通过bert模型进行编码,转化为基于字的向量形式,将预测标签转成成one-hot的向量形式;
[0076]
s724训练和测试的向量语料作为bert预训练模型的输入,输送至 bert预训练模型进行多标签分类。
[0077]
5、派发检查工作,检查清单根据预警规则触发检查计划,如当检查清单的各检查项累加值和达到设定值,或者单一检查项的累加值达到设定值时触发检查计划。
[0078]
本方案首先将数据源开源化,不仅获取服务热线的数据,还爬取开源新闻数据,服
务热线是群众表达自身诉求、提出意见建议和投诉举报的重要渠道,是了解社会动态、监督职能部门及其工作人员、保护公众利益、舒缓干群矛盾的一种重要方式。随着服务平台逐年使用,已积累形成了海量的公众诉求数据,这些数据来自基层,具有数据鲜活,“接地气”等特点,是“综合查一次”智能系统处理数据的优质来源。而置身于信息洪流时代,新闻门户网站、新浪微博等新闻载体是人们获取信息的主要来源。新闻门户网站提供的浏览、评论、点赞和转发功能,能够让人们快速地反馈接收到的信息,从而推动信息在网络中大范围传播并形成舆情事件;新浪微博拥有的庞大用户群体使得微博成为突发舆情事件产生、发酵、演变和传播的核心阵地和重要的开源情报来源。舆情热点反映了社会动态和民生意愿,通过对舆情热点事件的场景及其事件要素的挖掘,能够方便相关部门及早地发现检查新场景和检查新问题,为编制“综合查一次”新场景检查清单提前做好预案。
[0079]
其次,本方案将事件进行预处理并筛选出社会性事件,通过系列算法将满足一定条件的未知场景反映过相关部门,便于相关部门及时为社会性事件增加新场景和编写新场景的检查清单,为相关部门扩充综合查一次运行系统的已知场景提供技术支持和数据支持,从而为社会长期稳定有序发展保驾护航。
[0080]
此外,本方案对每个场景的检查清单进行智能动态排序,能够事先场景突出问题重点检查重点提醒,并且弱化检查长期合格的检查项目,有力地践行“综合查一次”的便民宗旨。
[0081]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
[0082]
尽管本文较多地使用了社会性事件、新闻类事件、民生类事件、场景、事件等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1