一种基于多尺度特征自适应融合的道路场景语义分割方法
1.本发明属于图像处理领域及图像语义分割方法,涉及一种基于多尺度特征自适应融合的道路场景语义分割方法。
背景技术:
2.图像语义分割是计算机视觉领域中的基础任务之一,其对图像中每一个像素点依据其语义信息和空间信息进行分类,是一种点对点的分类方式。语义分割是实现场景理解的关键步骤,也是机器感知环境的重要技术手段,被广泛应用于自动驾驶、室内导航、情感识别及姿态检测等多个领域。本专利提出了一个可以应用于道路场景下的语义分割技术,而道路场景的语义分割是自动驾驶技术中的重要一环。同时,由于自动驾驶需要系统能够对外界环境变化做出及时响应,其对算法实时性有较高要求。
3.文献“基于注意力机制和有效分解卷积的实时分割算法,计算机应用,2022,1-1”公开了一种基于注意力机制和分解卷积的道路场景分割算法。其利用一维非瓶颈结构(non-bottleneck-1d)构建卷积层以减少卷积操作的运算量;然后将池化操作和注意力模块相结合来捕捉全局上下文信息以提高对较大尺寸物体的分割效果。文献所述方法使用分解卷积来降低卷积层的计算量,虽然可以有效提升速度但显著降低了分割精度;专注于全局上下文信息获取,忽视了道路场景中小尺度物体的分割。
技术实现要素:
4.要解决的技术问题
5.为了避免现有技术的不足之处,本发明提出一种基于多尺度特征自适应融合的道路场景语义分割方法,解决现有实时语义分割算法速度快但精度低、对小尺寸物体分割效果差的问题。
6.技术方案
7.一种基于多尺度特征自适应融合的道路场景语义分割方法,其特征在于步骤如下:
8.步骤1:利用resnet-18神经网络对输入图像进行底层多尺度特征的提取,获得由浅到深4个尺度下的特征图s1、s2、s3、s4;
9.步骤2:在resnet-18神经网络搭建基于双向支路信息融合的主干网路,将特征图s1、s2、s3、s4经过由底向上的左侧支路和由上到下的右侧支路两个支路进行融合,得到各支路的特征图d1、d2、d3、d4和u1、u2、u3、u4,最后将两个支路中同尺度的特征图进行融合得到基于双向支路信息融合主干网路的输出f1、f2、f3、f4;
10.步骤3:利用基于光流估计的逐级上采样模块对步骤2中的输出f1、f2、f3、f4进行逐级上采样;
11.通过光流法计算4个尺度特征图中相邻特征图间即,f1与f2、f2与f3、f3与f4的光流网格。然后利用光流网格通过逐级上采样模块将f2、f3、f4上采样到与f1相同尺寸,得到对齐
后的特征图p1、p2、p3、p4;
12.步骤4:将各尺度下的特征图p1、p2、p3、p4输入分割模块获得各尺度下的分割结果scale1、scale2、scale3、scale4,同时各尺度下的特征图p1、p2、p3、p4输入注意力模块获取各尺度下分割结果的权重weight1、weight2、weight3、weight4,最后,利用权重将各尺度下的分割结果进行线性融合即得到最终的分割结果。
13.所述步骤1中特征图s1、s2、s3、s4的尺寸大小分别为原图像的1/4、1/8、1/16和1/32。
14.有益效果
15.本发明提出的一种基于多尺度特征自适应融合的道路场景语义分割方法,充分利用卷积网络自身所固有的多层次特性,在网络中每一个子网络输出的各层级特征层上进行多尺度推理,并利用注意力机制将各尺度下的预测结果进行自适应融合。本发明通过挖掘卷积网络的固有特性来进行多尺度推理,避免使用卷积分解等操作来降低计算量,从而可以在一个轻量级的主干网络上实现高精度的实时推理;由于主干网络的低层级特征包含细节信息并且具有较高空间分辨率,因此在低层级特征上进行的推理可以提升对小尺寸物体的分割精度。
16.本发明的有益效果是:
17.(1)步骤1~2充分利用卷积网络的固有多尺度特性,从网络不同阶段的子网络中获取多尺度特征融合后用于后续处理,可以弥补浅层轻量级主干网络学习容量不足的问题,从而实现快速且准确的分割;
18.(2)步骤3~4在获取的融合多尺度特征上进行多尺度推理。低层级特征具备细节和纹理信息并且具有较高空间分辨率,适用于小尺度物体的分割。而高层级特征包含语义信息且具备更大的感受野,适用于大尺度物体的分割。各个尺度预测值自适应融合后可以使最终结果在各尺度的物体上都可以具有较高分割精度。
附图说明
19.图1是网络整体结构图。
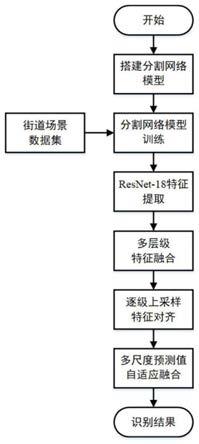
20.图2是方法流程图。
21.图3是cityscapes数据集下测试结果图。
具体实施方式
22.现结合实施例、附图对本发明作进一步描述:
23.本发明解决其技术问题所采用的技术方案:一种基于多尺度特征自适应融合的道路场景语义分割方法,其特点是包括下述步骤:
24.步骤1、利用resnet-18神经网络进行底层多尺度特征的提取。resnet-18网络在初始网络层通过池化操作快速降低输入图像的尺寸,并且通过较少的网络层来搭建整体网络,相比其他网络更加快速、高效,广泛被用于搭建实时的语义分割网络。本发明也在resnet-18的基础上搭建网络,通过移除最后一个残差模块后的所有网络层(包括池化层和全连接层)进行简化,简化后的resnet-18包含1个7x7卷积层、1个最大池化层和8个残差模块。根据各模块输出的特征图尺寸的不同,将8个残差模块分为4个子网络(图1(a)中的阶段
1~4)。特征图每经过一个子网络,尺寸减小1/2。这样,可以获得由浅到深4个尺度下的特征图s1、s2、s3、s4(尺寸大小分别为原图像的1/4、1/8、1/16和1/32)。
25.步骤2、在步骤1中构建的简化版resnet-18的基础上,搭建基于双向支路信息融合的主干网路(图1(a))。分别通过将特征图s1、s2、s3、s4经过由底向上(图1(a)中的左侧支路)和由上到下(图1(a)中的右侧支路)两个支路进行融合,得到各支路的特征图d1、d2、d3、d4和u1、u2、u3、u4,最后将两个支路中同尺度的特征图进行融合得到基于双向支路信息融合主干网路的输出f1、f2、f3、f4。
26.步骤3、利用基于光流估计的逐级上采样模块对步骤2中的输出f1、f2、f3、f4进行逐级上采样。通过光流法计算4个尺度特征图中相邻特征图间(即,f1与f2、f2与f3、f3与f4)的光流网格。然后利用光流网格通过逐级上采样模块将f2、f3、f4上采样到与f1相同尺寸,得到p2、p3、p4(由于f1不需要进行上采样,因此直接得到p1)。
27.步骤4、利用分割模块获取各尺度下的分割结果,并利用注意力机制进行各尺度下分割结果的自适应融合。在各尺度下的特征图p1、p2、p3、p4的基础上,利用分割模块获得各尺度下的分割结果scale1、scale2、scale3、scale4,然后利用注意力模块获取各尺度下分割结果的权重weight1、weight2、weight3、weight4。最后,利用权值将各尺度下的分割结果进行线性融合即可得到最终的分割结果。
28.具体实施例:
29.下面结合对城市街道下的语义分割数据集cityspaces的识别实例说明本发明的具体实施方式,但本发明的技术内容不限于所述的范围。
30.本发明提出一种基于多尺度特征自适应融合的道路场景语义分割方法,包括以下步骤:步骤1:利用简化后的resnet-18神经网络获取不同尺度下的特征图;步骤2:构建基于双向支路信息融合的主干网络,进行多尺度特征图间的高效融合;步骤3:利用基于光流估计的逐级上采样模块对不同尺度的特征图进行上采样;步骤4:构建基于注意力机制的自适应多尺度融合模块,将不同尺度特征图下的分割结果进行自适应融合;步骤5:利用数据集对搭建的神经网络模型进行训练。
31.步骤一、利用简化后的resnet-18神经网络获取不同尺度下的特征图。
32.由于resnet-18网络模型在初始网络层通过池化操作快速降低输入图像的尺寸并且网络层数较少,适于搭建实时的语义分割模型。通过移除最后一个残差模块后的所有网络层对resnet-18网络进行简化,简化后的resnet-18包含1个7x7卷积层、1个最大池化层和8个残差模块。根据各模块输出的特征图尺寸的不同,可以将8个残差模块分为4个子网络(图1(a)中的阶段1~4)。然后将cityspaces数据集中的图片样本输入resnet-18网络进行特征提取。由于每经过一个子网络,特征图尺寸减小1/2。这样,可以获得由浅到深4个尺度下的特征图s1、s2、s3、s4。
33.步骤二、利用基于双向支路信息融合的主干网络对4个尺度的特征图进行融合。
34.(1)利用由下向上的融合支路(图1(a)中的左侧支路)进行特征融合。由于下层特征尺寸较大,因此下层特征层需要先经过下采样然后与上层特征进行融合。每次融合时,通过前一尺度的融合特征图d
n-1
经过双线性插值下采样后与当前尺度的特征图sn进行相加,然后利用3x3的卷积进行融合,这样输出的融合特征图dn就包含了第n和n+1尺度下的特征,通过递归操作依次获得多个尺度下的融合特征图d1、d2、d3、d4:
[0035][0036]
其中,conv_3x3表示卷积核大小为3x3的卷积操作,用于特征融合;conv_1x1表示卷积核大小为1x1的卷积操作,用于特征图深度维度的调整;down表示双线性插值下采样操作。
[0037]
(2)利用由上到下的融合支路(图1(a)中的右侧支路)进行特征融合。由于上层特征尺寸较小,上层特征图需要经过上采样后与下层特征图融合,其他操作于由下到上的融合支路相同,通过递归操作依次得到融合特征图u4、u3、u2、u1:
[0038][0039]
其中,up表示双线性上采样操作。
[0040]
(3)将两个支路中通尺度的特征图进行融合得到基于双向支路信息融合主干网路的输出f1、f2、f3、f4:
[0041]fn
=conv_3x3(dn+un),n=1,2,3,4
[0042]
步骤三、利用基于光流估计的逐级上采样模块将步骤二中的输出f2、f3、f4上采样到与f1相同尺寸,以将各尺度特征图间的空间位置进行对齐。
[0043]
(1)利用光流法计算4个尺度特征图中相邻特征图间(即,f1与f2、f2与f3、f3与f4)间的空间扭曲网格:
[0044]
首先利用相邻两个尺度的特征图计算光流场δ
n-1
:
[0045]
δ
n-1
=conv_3x3(concat(f
n-1
,up(fn)))
[0046]
其中,concat表示将特征图沿深度维度进行拼接;δ
n-1
表示与f
n-1
同尺寸且深度为2的光流场。
[0047]
然后,用g
n-1
表示f
n-1
的空间网格ω
n-1
中的位置点,则fn相对于f
n-1
的空间扭曲网格ωn中的偏移量offsetn可以表示为:
[0048][0049]
其中,n为2,3,4时,分表表示f1与f2、f2与f3、f3与f4间的空间扭曲网格。
[0050]
(2)利用空间扭曲网络进行逐级上采样,将f2、f3、f4分别上采样到与f1相同尺寸,得到上采样后的特征图p2、p3、p4(由于f1不需要进行上采样,因此直接得到p1)。该递归过程可以表示为:
[0051][0052]
up
l
表示利用扭曲网格中的偏移量offset
l
对特征图f进行双线性插值上采样。该过程可以表示为:
[0053][0054]
其中,n(ω
l
)表示空间扭曲网格ωn中的4个领域(左上、左下,右上,右下);wi表示利用ωn中的偏移量offset
l
计算的双线性核的权重。
[0055]
步骤四、在各尺度下的特征图p1、p2、p3、p4的基础上,利用分割模块获取各尺度下的分割结果,并利用注意力机制进行各尺度下分割结果的自适应融合。
[0056]
(1)利用分割模块获得各尺度下的分割结果scale1、scale2、scale3、scale4,然后利用注意力模块获取各尺度下分割结果的权重weight1、weight2、weight3、weight4,分割模块和注意力模块都利用3x3的卷积核来构建:
[0057]
scalen=conv_3x3(pn),n=1,2,3,4
[0058]
weightn=conv_3x3(pn),n=1,2,3,4
[0059]
(2)利用权值将各尺度下的分割结果进行线性融合即可得到最终的分割结果:
[0060][0061]
其中,output表示最终的分割结构;
⊙
表示矩阵点乘。
[0062]
最后,利用权值将各尺度下的分割结果进行线性融合即可得到最终的分割结果。
[0063]
步骤五、利用数据集对搭建的神经网络模型进行训练。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1