对自然语言表述的解译的地理映射的制作方法
对自然语言表述的解译的地理映射
1.本技术是申请日为2017年09月18日、题为“对自然语言表述的解译的地理映射”的中国发明专利申请no.201710843373.9的分案申请。
2.相关申请的引用
3.本技术要求由邢博纳(pranav singh)、莫
·
伯耐(bernard mont-reynaud)、柯秀琼(kheng khov)和普
·
仲朗(jonah probell)于2016年12月23日递交的、题为“geographical mapping of interpretations of natrual language expressions(对自然语言表述的解译的地理映射)”(代理所案卷号meld 1033-1)的美国临时专利申请no.62/438,731和由邢博纳(pranav singh)、莫
·
伯耐(bernard mont-reynaud)、柯秀琼(kheng khov)和普
·
仲朗(jonah probell)于2017年02月06日递交的、题为“geographical mapping of interpretations of natrual language expressions(对自然语言表述的解译的地理映射)”(代理所案卷号meld 1033-2)的美国非临时专利申请no.15/425,099的优先权,上述申请通过引用被完整结合于此。
技术领域
4.本发明涉及创建地区地图的领域,该地区地图指示地图所示位置处的人的思想中所包括的概念的聚合。可以通过使用自然语言理解技术来准确地确定概念。
背景技术:
5.作为特定地理位置的二维图像的地图具有多种形式。存在指示所测绘的空间上的人的活动或人口统计数据的地图。用于表示人的活动和人口统计数据的聚合的信息主要来自公共记录和调查研究,例如,犯罪统计数据、交通模式、居住社会经济研究、人口普查数据、市场调查、纳税评估数据。对于这种地图而言,从互联网挖掘由个体用户贡献的数据是较为新鲜的。此外,先前可得到的信息并不是对未来人们在某一地区中的行为的可靠预测。
6.通过计算机来进行数据挖掘和机器学习已被应用于从设置信用评分到进行投资再到预测犯罪等各个方面。一些系统使用根据广泛使用的人类语言(例如,英语、普通话、日语和德语)的自然语言处理来从原始数据中提取含义和意图。基于个体的表述来将含义与个体相关联,可以是对他们的兴趣、未来行为、甚至是出行方式的准确预测。移动设备和本地化终端允许系统跨过个体所经过的任意地点来处理个体的自然语言含义和意图。但是,这样的系统不会针对特定地点和经过这些地点的各个个体处理自然语言含义和意图。
7.一些实验系统已使用推特(twitter)推文或其他社交媒体消息中的关键字和地理位置标签关键字之间的关联来制作具有遍布城市的声音、气味和情感的趣味地图。这样的系统对数据进行简单分析,并提供仅适用于简单应用的数据。这种系统使用研究人员所标识的特定关键字集。然而,针对关键字挖掘社交媒体消息可能无法提供对用户的思想的准确指示。例如,考虑用户所发推文:“the ball’s in your court(球在你的球场/现在就看您的决定了)”,可能标识体育相关的概念而不是谈判。思想地图的价值可以取决于概念识别的准确度。
8.此外,基于关键字的系统无法提供跨时间维度的有用分析。具体地,这些系统不能辨识时间上的循环模式(例如,在一天中的特定时间段表述、或一周内的几天中的表述),并且不能辨识位置上的循环模式(例如,公共汽车站到公共汽车站或房屋到房屋)。
技术实现要素:
9.本公开涉及将从自然语言表述的言语挖掘的概念映射至位置。位置可被聚集成地区,并且概念-位置关系可进一步与时间指示相关联。也就是说,与位置相关联的概念可能会随着时间(例如,一整天或整周或整月)而改变。
10.本文描述的方法和系统提供了通过用于分析人们的许多自然语言表述的言语(以下称为“自然语言表述”或“表述”)的记录来创建准确的思想地图,其中每个表述与其所在的位置一起被记录。自然语言理解(nlu)技术被用来解译人的文本或口头语言、创建解译数据结构以表示自动确定的表述的语义。人的上下文或一连串单词中单词之间的关系可用于增强对表述的理解。自然语言表述的全部解译数据结构可与相关联的位置数据一起被存储在数据库中。统计技术或其他数据聚集方法可用于分析这些数据库记录,以确定频繁地与所关注的地点关联的概念。一旦一个或多个概念与位置(还可能有时间)相关联,则可以使用数据来发现哪些概念与特定地点相关联。考虑在特定地址购买房屋的人可通过察看该区域的普遍概念来了解邻里动态。替代地,可以使用数据来发现哪些地点与特定概念相关联,这可用于确定投放特定广告的位置。
11.术语
12.思想:关于人们在讲话或书写自然语言时心里在想什么的非技术术语。通过使用表示自然语言表述的语义解译的计算机数据结构来表示思想。
13.地区:能够在地图上显示的地理范围。地区可以通过多种方式来定义,例如,一个或多个经纬度范围、邮政编码、地理政治定义或自定义界限,比如,特定关注点的在视野内或听觉距离内的位置。
14.位置:地区内的最小可分辨区域,例如,地图网格内的网格单元、建筑物或麦克风的听力范围内的区域。
15.地理位置:地区内的特定点,例如,特定纬度-经度对、特定邮政编码或特定关注点。如果与改变位置可能占用的时间量相比地理位置数据最近被更新过,则地理位置数据是最新的。固定设备的地理位置总是最新的。缓慢移动的设备(例如,在绵延山脉中的徒步旅行者的移动电话)的地理位置在很长一段时间内是最新的。快速移动设备(例如,城市上空的飞机)的地理位置,只在短时间内才是最新的。
16.解译:解译是由语义解析器创建的复杂数据结构,并被数据处理系统用来表示自然语言表述的意义。
17.组分:组分是解译的表示单位含义的部分。在语义图中,组分是解译中包括节点和边线的子集的子图;该子图表示共同定义组分的实体以及它们之间的关系。最小的组分包括单个节点(实体)、或通过边线连接的两个节点。例如,组分可表示作为父母的人实体和作为孩子的人实体之间的关系。
18.成分:成分是在层级结构中起单个单位(例如,子句和短语)功能的词或词组。自然语言语法将表述分解为组成部分。自然语言语法主要包括短语结构语法(非上下文相关
(context-free)语法)和依存关系语法。虽然这两种类型的语法的所创建结构是不同的,但却密切相关。
19.所有成分都是原始表述的显式部分;相应的组分是这些成分的语义对应物。
20.话语域(知识域):与图的类别层级相关联的主题区域。例如,食品域可以包括快餐类,快餐类可以包括汉堡包类和法式炸薯条类。
21.概念:抽象观念、与实体或类相关联的通用看法。快餐、汉堡包和炸薯条可以是食品知识域的概念。
22.表述:人们可以使用自然说话来创建口头表述,以及书写、用打字机打、或用手势来表示自然语言表述。麦克风、键盘、触摸屏、相机和其他装置适合用于采集表述。可以以文本形式来创建表述。可以通过自动语音识别(asr)系统来将表述转换为文本格式。
23.显著性:所表达的概念的局部密度和普遍密度之间的差异。
24.人:自然语言表述的来源。
25.用户:操纵机器、系统或服务(例如,手机、互联网或虚拟助手)的人。
26.消费者:广告的对象。一些实施例处理来自某些人的表述以确定向消费者呈现的广告。在某些情况下,发出自然语言表述的人是消费者。
27.本体:本体至少表示对象类和这些类的实例之间的关系的集合。在一些实施例中,本体包括类的层级。在一些实施例中,关系由指定可以进入关系的实例的类的类型系统来约束。一些实施例将类与称为“脚本”的行为相关联,这些行为(“脚本”)描述了该类的实例能够执行的动作序列。
28.本发明涉及数据结构、数据收集和数据分析的各个方面。这些方面适用于各行各业及各种目的,例如,在人们需要时向他们提供有用信息。所描述和要求保护的本发明的所有实施例中并未示出所有方面。
29.本发明的一方面是采集和处理自然语言表述。一方面是使用音频采集(例如,通过麦克风)来采集数据。一方面是使用移动设备采集音频。一方面是使用对地静止设备来采集音频。一方面是采集遍布在人们所位于和途经的地方的音频。
30.一方面是将自然语言表述与特定位置相关联。一方面是将自然语言表述与特定的时间范围相关联。一方面是将自然语言表述与特定的人相关联。一方面是将自然语言表述与特定的人口统计信息相关联。一方面是将自然语言表述与特定设备相关联。一方面是将自然语言表述与地理位置的准确性的度量相关联。一方面是将自然语言表述与地理位置检测的测量存在时长相关联。一方面是将自然语言表述与运动的速度和方向的度量相关联。
31.一方面是使用计算机来对表述进行自然语言理解,以确定解译。一方面是处理自然语言表述,以确定讲话者的情感。一方面是匹配解释的部分。一方面是忽略解译中的特定实体和属性。
32.一方面是将地理位置信息以一种有益于以不同比例尺呈现地图的表示形式进行存储。一方面是基于与自然语言表述相关联的位置、时间戳、周期阶段、人、设备和其他参数的值或范围来筛选思想。一方面是确定思想来源的位置。一方面是通过使用多次测量的平均值来确定位置。一方面是根据位置测量的精确度来对位置进行加权平均。一方面是通过添加方向向量乘以速度乘以测量存在时长来校正位置测量。另一方面是执行位置的模糊匹配。
33.一方面是预测性地提供有用的信息。一方面是提供位置特定的广告。一方面是提供个人特定的广告。一方面是提供时间特定的广告。一方面是提供促进公共安全的信息。一方面是预测人们未来的行为。一方面是根据地理位置、一天当中的时间、星期几或其他条件查找特定的思想或思想的类别。
附图说明
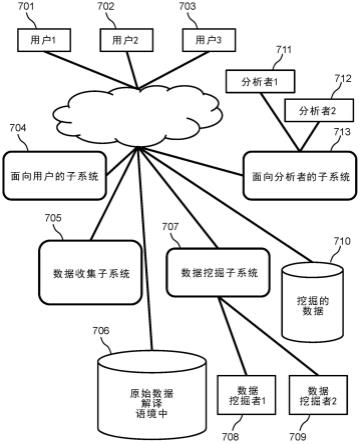
34.图1示出了根据本发明的实施例的系统,在该系统中网络将人、数据挖掘者和分析者连接到服务器。
35.图2是示出了根据实施例的采集和分析数据以创建思想地图的过程的流程图。
36.图3示出了根据实施例的面向人的子系统、以及与数据收集子系统进行通信的实施例。
37.图4示出了根据实施例的表述的解析树。
38.图5示出了根据实施例的相同表述的依存关系树。
39.图6示出了根据实施例的相同表述的解译数据结构。
40.图7示出了根据实施例的数据挖掘和分析子系统的整合实施例。
41.图8示出了根据实施例的地图层,包括地理地图、情感叠加层、经筛选的表述点的叠加层以及概念词的叠加层。
42.图9示出了根据实施例的具有对自然语言表述的位置的指示的地理地图。
43.图10示出了根据实施例的具有概念和其被表述的位置的指示的地理地图。
44.图11示出了根据实施例的被表述的概念的位置。
45.图12示出了根据实施例的针对上午时间范围筛选出的被所表达的概念的位置。
46.图13示出了根据实施例的针对下午时间范围筛选出的所表达的概念的位置。
47.图14示出了根据实施例的针对晚间时间范围筛选出的所表达的概念的位置。
48.图15示出了根据实施例的具有啤酒广告牌和所表达的概念的地理地图。
具体实施方式
49.本发明涉及为地理地区(可选地随着时间的推移)创建思想地图。思想地图的价值取决于来自在正对其进行绘制的地点中的人的自然语言表述的挖掘概念的准确性。
50.图1示出了根据本发明的实施例的系统,在该系统中网络将人、数据挖掘者和分析者连接到服务器。自然语言表述是从移动设备用户701和702、以及具有已知固定位置的设备的用户703收集的。已知位置通常从ip地址、软件注册、信号塔接近度或其他已知方法而获知。面向用户的服务器子系统704通过网络接收用户表述,并将这些表述传递到数据收集子系统705中的服务器。在一些实施例中,面向用户的子系统704解析和解释表述以生成解译,并且在一些实施例中,数据收集子系统705解析和解释表述以生成解译。数据收集子系统705将记录添加到数据库706,这些记录包括来自表述的原始数据、表述的语境及解译。数据挖掘子系统707内的服务器,按照数据挖掘器708和709的指示,处理原始数据以创建挖掘的数据710的数据库。分析者711和712使用面向分析者的子系统713内的服务器来访问挖掘的数据。各种实施例具有任何数目的用户、数据挖掘者和分析者。
51.数据挖掘子系统可主动地将数据库706中的原始数据转换成更容易用于分析目的
的格式并将其存储在挖掘的数据710中。可替代地,面向分析者的子系统可从数据库706中的原始数据着手,而不是使用预先挖掘的数据。
52.在一个实施例中,提供数据收集子系统705的机构可与提供数据挖掘子系统707的机构不同。而且,不同的第三机构可提供面向分析者的子系统713。在其他实施例中,单个机构可提供这些子系统中的两者或全部。同理,有些人可能会同时扮演数据挖掘者和分析者的角色,而有些人可能会扮演一个角色而非另一角色。图1的实施例的许多变体对于普通技术从业人员将是显而易见的。
53.图2是示出了根据本发明的实施例的创建思想地图的过程的流程图。位于关注的地区的人对着麦克风说话,或者在诸如电话之类的设备上输入自然语言短语。这些自然语言表述可由本地计算设备(例如,采集语音或文本的设备)来处理。可替代地,表述可被发送到该地区之外的数据中心以进行处理。自然语言理解(nlu)系统95接收表述以及表述被采集的位置指示符,并创建解译,解译是每个表述的语义表示。nlu系统95将解译数据结构与相关联的位置一起存储在数据库中,例如内容解译的原始数据库93。
54.数据挖掘子系统91分析原始数据库93中的数据以针对所表示的每个不同位置确定每个表述中的概念,并且聚合跨用户的概念。数据挖掘子系统91在解译数据结构中搜索感兴趣的概念。这些感兴趣的概念被存储在一个或多个知识域概念图中。
55.数据挖掘可主动在配置的区间中运行,或者可以由指定一个或多个知识域的数据挖掘请求来按需触发。示例聚合是计算概念跨与特定位置相关联的所有解译中出现的次数,或者计算包括概念的至少一个实例的解译的数量。
56.数据挖掘过程的输出被存储在挖掘的数据94的数据库中。该数据提供足够的信息来绘制感兴趣的地区的思想地图。然而,面向分析者的子系统92可响应于创建来用于答复分析者请求的查询来撷取数据。例如,分析者可以请求前100个最频繁表达的概念的频率的直方图。在另一示例中,分析者可以请求年龄范围是21至35岁的人所表达的10个最常见概念的列表。在另一示例中,分析者可以请求位置内特定概念的显著性。
57.在各种实施例中,本发明涉及自然语言表述的处理,以满足多个群体的需要,例如移动设备的用户、数据挖掘者、分析者和广告商。
58.图3示出了面向移动设备用户子的系统及其与数据收集子系统的通信的实施例。可使用诸如蜂窝电话之类的移动设备中的麦克风或者安装在关注的位置的固定麦克风来说出和采集自然语言表述。任何采集语音音频信号的方式都可被使用。声信号可通过网络向面向用户子系统704传输。可替代地,当采集语音的麦克风被连接到处理器时,处理器可在设备本地将采集的语音转录,并且所得到的文本转录可通过网络被发送到面向用户子系统704。自然语言表述可被输入为文本,而不需要语音到文本的转录。
59.在面向用户子系统704内,语音辨识器81将语音转换为文本。语义解析器82分析来自人的表述的文本以创建相应的解译。文本可来自语音辨识器81的输出、来自与扬声器(例如,移动设备)共址的语音转录器、或者来自直接以文本形式来表达思想的人。语义解析器使用语境信息(包括一个或更多个地理位置、时间和用户身份等信息)来提高其解析能力。以下提供了关于语境信息的更详细的解释。
60.在一些实施例中,对于一些表述,表述运行模块83使用解译来构建针对用户的响应。
61.响应于接收到表述,面向用户的子系统汇集包括一个或多个表述音频、表述文本、每个表述的解译、解译中的概念、和表述语境信息的信息包。子系统将信息包发送到数据收集系统84。各种实施例在信息包中包括不同的内容。在一些实施例中,信息包具有丰富的结构。一些实施例当在子系统之间传输信息包时串行化信息包。在一些实施例中,使用专用格式来表示经串行化的信息包。一些这样的格式使用自定义的实现方式。有些使用诸如基于javascript语言的轻量级的数据交换格式(json)之类的模式。在一些实施例中,串行化和解串行化不是必需的,这是因为面向用户系统和数据收集系统由相同的服务器托管并且可共享内部数据结构。
62.数据收集系统84接收信息包,并将信息包的内容存储在数据库85中。许多可选格式可能用于在原始数据库中存储记录。将要存储的一些数据(例如,时间、位置或用户id)具有固定的大小。其他信息片段(例如,表述音频、表述文本或某些成分)可作为变量字符串被存储。(“[[ed]wants[to impress[[the]girl[with[[a][pearl]necklace]]]]]([[艾德]想[打动[[这位][佩戴[[一条][珍珠]项链的女孩]]]]])”)是一种用于表示依存关系树的简单字符串格式。在一些实施例中,可以注释这样的字符串以使树节点与诸如成分之类的语义数据或通过唯一标识符对成分的引用相关联。在一些实施例中,使用三元组来存储解译。一些实施例在向原始数据库添加记录时主动索引数据库。其他实施例在之后创建索引。
[0063]
语境信息
[0064]
各种语境信息可与包括位置、个性化和时间的自然语言表述一起被采集。语境信息可用于提高构建解释或从解译挖掘概念的准确性。解译记录也可以被存储为由语境信息进行索引,以能够快速撷取与创建特定种类的思想地图相关的解译记录。
[0065]
存在许多表示地理位置的注解,包括纬度+经度、地区坐标(geohash)、三词地址(what3words)、街道地址、和邮政编码。一些实施例将地理位置数据与数据库记录中的解译一起存储。一些实施例通过地理位置来索引数据库。由于geohash编码结合了其扩展性和易于搜索的特性,位置的geohash编码引起了人们的特别关注。geohash将二维矩形的纬经值范围表示为小写字符串;代码的长度决定单元格的分辨率。geohash编码将空间细分为单元的层级网格。geohash编码中的每个附加字符将当前单元格划分为32个子单元格,可选4
×
8或8
×
4个子单元格,以使得在每个阶段中,“纵向(portrait)”单元格与“横向(landscape)”单元格交替。相反,从geohash编码结尾开始移除字符会使精度逐渐减低。另一种被称为四叉树的编码具有类似的层级属性,但使用二进制字符串来进行编码。
[0066]
许多系统可有助于确定地理位置;这些系统包括卫星星座系统(例如,全球定位系统(gps)、伽利略定位系统(galileo)、格洛纳斯卫星导航系统(glonass)和北斗卫星导航系统(beidou))、远程导航系统(loran)、信号塔接近度和三角测量定位系统、以及低功耗蓝牙。一些系统还可以确定每个位置测量的准确度。有些系统只会不时地测量位置,并在撷取到位置值时报告测量存在时长(age)。一些系统还测量运动速度。速度和时期合在一起可用来估算与测量时刻不同的时间点处的地理位置。
[0067]
一些实施例将一个或多个地理位置、位置测量精度、测量存在时长和速度通过每次记录存储到数据库中。一些实施例以小于测量准确度的精度来测量或提供地理位置信息。这有利于模糊所测量的位置。一些这样的实施例将坐标值四舍五入或直接截断,这会在表示中引起条带效应(banding)。一些实施例将小范围内的随机值添加到测量结果中以降
低精度。
[0068]
采集用户的表述的用户设备还可提供标识发出表述的人的个性化数据。这仅在可将人唯一地标识出的系统中才有可能,例如,个人移动设备或诸如自动取款机(atm)之类的需要用户认证的系统。如果系统在公共场所(例如,购物亭或自动售货车)或者在由许多人共享的设备(例如,办公设备系统)上采集表述,则不可使用唯一的用户id。
[0069]
一些实施例,无论它们是否识别发出表述的讲话者,都识别听众。一些这样的实施例利用数据库中的记录来存储已知在场的听众的个人id的列表(若存在)。识别听众的一些实施例维护单独的“听众”数据库,并且包括可能被该人听到的按日期排序的记录列表。这有助于通过采集表述、确保听众不会误听所采集的表述、并将其记录在个人知识库中以用于将来的搜寻和召回,来帮助人们感知和记忆。一些这样的系统与个人认知增强设备接口连接。
[0070]
一些实施例利用数据库中的每条记录来存储关于讲话者的人口统计信息。人口统计信息包括性别、年龄、婚姻状况、种族、政治倾向、教育水平和经济状况等信息。一些这样的实施例通过一种或多种类型的人口统计信息来索引解译数据库。这样可以更好地预测人们的兴趣、需求和可能的活动,从而使各种设备能够提供更好的服务。还实现了广告的定位和法律的实施。
[0071]
在实施例中,数据库中的每个表述记录可与标识该表述被发出的时间的时间戳一起被存储。在这样的实施例中,数据库记录可由时间戳进行索引。这有助于按时间段有效地筛选记录。
[0072]
一些实施例利用数据库中的每个记录来存储时期阶段信息。这有助于基于事件周期内的时间段(例如,几天内的小时数、几周内的天数、几年内的天数或几年内的月数)来筛选记录。一些实施例在读取数据库后从时间戳计算阶段。一些实施例将阶段记录在数据库中。
[0073]
创建解译
[0074]
本节介绍接收自然语言表述并创建解译以存储在原始数据库93中的nlu系统95。
[0075]
人们使用自然语言表述、使用讲话或文字来交流思想。计算机系统可使用提供可计算的含义表示的数据结构来表示人的思想。这种语义表示数据结构被称为表述的解译。解译可以以各种数据结构格式进行存储。常见的解译格式包括框架(如马文
·
明斯基(marvin minsky)1974年的文章“a framework for representing knowledge(表示知识的架构)”中所描述的)、语义存储器三元组《实体,属性,值》(eav三元组)和一阶逻辑。用于表示意义的各种格式大体上相同并且在很大程度上可以相互转换,尽管它们可以具有不同的优点和不同的表达能力。在本公开中,示例解译在语义存储器中使用三元组来表示。其他语义表示也适用于实施本发明。
[0076]
三元组由实体、指定的属性、以及该属性的一个或多个值组成。实体是域的本体论中的类的实例,表示话语的对象,例如,有生命对象、无生命对象或抽象对象。诸如人、事物、地点和时间等以自然语言表述形式出现的实体可以用名词(n)(例如,“乌兰巴托(ulaanbaatar)”)或词组(例如,“蒙古之都(the capital of mongolia)”)来指定。
[0077]
定义类层级结构是本体的重要组成部分。例如,在虚拟助手的日历域中,女人是人,并且人具有诸如姓名、电话号码、地址、性别等属性。而在普通生物学域中,人是人类,人
类是灵长类动物,灵长类动物是哺乳动物,以此类推。这是一个简单的分类法。例如,哺乳动物具有“性别”属性,并且所有哺乳动物的子类都具有继承自哺乳动物类的性别属性。在一些实施例中,本体指定至少类层级结构、适用于每个类的一组属性、以及这些属性的值的约束条件(例如,类型)。
[0078]
给定表述的解译通常包括若干实体,并且每个实体可具有多个已知属性。例如,吃饭的行为可能涉及进食者和对所进食食物的描述。人是具有名称的实体,其在各种实施例中可以由字符串、复杂数据结构和用户标识符(uid)中的一者或多者来表示。地理位置和一天中的时间也可与表述的解译相关联来作为一个整体。
[0079]
类型为物(thing)(即,物理对象)的实体可以具有许多属性;只有其中一些属性适用于物的每个子类。物的可能属性包括大小、材料和部件清单。这些部件是其他物实体的实例。在一些实施例中,解译数据结构只是将值为未知的属性省略。地点实体可以具有诸如地址、纬度、经度和名称之类的属性。时间实体可以具有年、月、时、分、秒和时区。
[0080]
实体的每个实例具有一个或多个属性,每个属性具有在任意给定时间可被分配或不分配的值。大多数值都具有类型;一些类型有范围限制。例如,年龄值可以是从0到122的年数。性别值是从离散选项的列表中选择的值,以及名称值是一个或多个单词。
[0081]
对于另一示例,其中考虑到人(person)实体可能具有引用衬衫实体的“衬衫”属性,衬衫实体(正如服装的任意子类)支持“制造地”属性,其值是国家实体,并且国家具有“名称”属性。因此,在“她”所指的人被识别出之后,系统可以回答该问题:“她的衬衫是在哪里制造的?”[0082]
不管实施例中的特定知识如何表示,解译提供了披露表述的结构的方式。一些实施例将解译构造为解析树、语法树、或依存关系树。一些实施例使用语义信息来增加节点和边线。一些实施例使用属性列表来表示语义结构。
[0083]
在一些实施例中,自然语言表述的解译由语义解析器来创建。在一些实施例中,语义解析器根据语法(例如,依存关系语法)来提取表述的句法结构(例如,依存关系树)。如果表述给定,语法创建成分的层级结构,并且语义解析器将每个成分与相应的语义组分相关联。成分是自然语言表述的一部分,并且组分是该表述的语义解译的部分。在一些实施例中,语义解析器基于局部解析技术。一些这样的实施例使用词性(pos)标签来标识一些但非全部成分和相关联的语义。一些实施例进行局部解析。一些实施例进行全面解析。
[0084]
图4示出了根据短语结构语法的表述“ed wants to impress the girl with a pearl necklace(艾德想打动这个佩戴一条珍珠项链的女孩/艾德想用一条珍珠项链打动这个女孩)”的可能解析树。图5示出了针对同一表述的根据依存关系语法的依存关系树。“成分”是整个表述或由任何带标记的子树生成的表述,其中子树由节点加上由该节点支配的所有节点组成。比较图4和图5显示两个树结构中大多数但非全部成分是相同的。例如,“the girl with a pearl necklace(用一条珍珠项链
……
这个女孩/佩戴一条珍珠项链的女孩)”是在两棵树中都存在的成分,而“女孩”是仅在短语结构语法中的成分。从构建语义解译的角度来看,基本成分是依存成分。在本公开中,使用模拟依存关系树的方括号来文本地传达依存关系语法成分的层级结构:
[0085]
[[ed]wants[to impress[[the]girl[with[[a][pearl]necklace]]]]]([[艾德]想[打动[[这个][佩戴[[一条][珍珠]项链的女孩]]]]])。
impress(打动)”从管理辅助动词“想”继承其主体,并且具有对象,该对象为要被打动的人,其由实体唯一id为p00394(附图标记36)的子结构表示。这个实体没有名字,但它代表成分“佩戴珍珠项链的女孩”,并在图中被释义为“佩戴配饰t00123(附图标记37)的女性”。该图指定t00123(附图标记37)是珍珠项链类的实例,并且系统(通过域本体)还会知晓珍珠项链是珍珠项链类的子类。图6中所示的语义网络阐述了与涉及此示例的应用相关的关键关系。其他实施例通过不同的方式来表示关系。
[0102]
在一些实施例中,共指关系分辨(co-reference resolution)技术被用来来试图将p00175(附图标记32)(“艾德”)或p00394(附图标记36)(“这个佩戴珍珠项链的女孩”)等同于先前已知的实体。基于可用的语境执行共指关系分辨。语境可以包括先前的表述、关于环境的知识或其他相关事实。任意共指关系分辨技术都适用。
[0103]
所有成分是原始表述的显式部分;相应的组分是那些成分的语义对应物。在一些实施例中,组分是具有头节点的复杂的子结构,例如,子图;例如,“打动这个佩戴珍珠项链的女孩”的头节点是p00394(附图标记36)。
[0104]
概念是抽象观念、与实体或类(例如,水果)、动作(采摘水果)或整个场景或“脚本”(正式婚礼)相关的通用看法。概念属于知识域。一些概念通过表述中的词或短语直接地表达。例如,在提到“苹果”时表达了“苹果”的概念。但是也调用了概念“水果”,“水果”在域本体中是“苹果”的父类。域本体的使用包括将本体类从更具体的类上升至更通用的类。请注意,本体不是严格的层级结构。person(人)类是人类(human)的子类,human类本身是哺乳动物、动物等的子类,但person类也是联系方式的子类,联系方式还有业务的子类。本体的更高级的使用是基于将脚本与表述的含义相关联进行的。例如,表述“蒙面男子通过屋顶闯入了美国富国银行”调用底层的脚本robbing_a_bank_(抢劫_一家_银行),它是robbery_本体(抢劫_本体)脚本的子脚本。概念的言语表现使用概念词,在这种情况下,概念词是“抢劫”和“银行”或“银行抢劫”;这些词仅仅部分反映如robbing_a_bank_script(抢劫_一家_银行_脚本)的概念。
[0105]
为了简化沟通,通常将概念词(概念的言语表现)视为概念本身;本质上,这个概念能够是对沟通和展示提出挑战的复杂的数据结构。
[0106]
另一论域中的另一示例是概念“测量患者血压”。其他概念包括“测量血压”和“压力测量”,但是“测量血液”并不是概念;这是因为血液不能被测量,只有它的压力可被测量。测量血液在语义上不是自洽的、通用的和广泛适用的概念。概念的基本属性是它可以形成语义解译的一部分,并且它可被言语化。
[0107]
以上给出的解译的具体表示仅仅是对自然语言表述的完整句法和语义处理的说明。
[0108]
解析树(图4)、依存树(图5)和解译图(图6)的表示通常使用内部指针来提高效率,但是它们可被序列化,以便被传输到较大的系统的单独的部分,并由接收系统模块进行反序列化。常用于序列化/反序列化的语言包括json和可扩展标示语言(xml)。
[0109]
情感负荷和情感
[0110]
一些实施例针对情感负荷(emotional charge)分析自然语言表述,它们存储在解译内或与解译相关联。有各种各样的情绪分析方法。一些实施例以单个数字的形式向概念分配情感负荷。这种情感负荷的表示形式可以是从高度消极到高度积极的一系列值。例如,“杀戮”和相关概念具有高度消极负荷,而“爱”则具有高度积极负荷。也可根据依赖于属性值的因素来标称情感负荷。例如,如果学校考试的分数属性的值为“中”,则这个概念稍有些消极。如果分数为“良”,则这个概念稍许积极。如果分数是“优”,则这个概念非常积极。一些实施例计算表述的情感负荷。一些实施例使用关于人们及其环境的语境信息来标称情感负荷。例如,“金钱”对不同的人为不同的情感负荷,“深度”在游泳方面的情感负荷不同于铲雪方面的情感负荷。一些实施例通过众包和机器学习的方式来训练情感负荷与概念或标称功能之间的关联。在训练之后,情感负荷的值可至少部分从所训练的关联推导出来。
[0111]
一些情绪分析功能仅简单地用1星至5星的标度来表示情感。一些情绪分析功能将情感表示为极值(polarity value)和幅度值(magnitude value)。存在用于表示情感值的各种系统。一些系统将诸如愤怒、厌恶、恐惧、幸福、悲伤和惊喜之类的情感的值量化;其他系统使用二维、三维或更多维来在维度空间上表示情感。各种实施例处理解译或相关联的概念集来确定情感值。一些实施例使用所采集的语音的属性(例如,包括语速和节奏、重音、强调和基频曲线的韵律)来计算或标称情感值。一些实施例将情感值与解译一起存储在数据库记录中。
[0112]
超越关键字的概念的优点
[0113]
从表述提取关键字是琐碎的。关键字描述对词的顺序并不敏感。例如,“请问你的国家可以为你做什么”和“请问你可以为你的国家做什么”的表述有相同的关键字,但是它们的含义不同。类似地,“a little too big(有点太大)”有两个关键字“litte(点)”和“big(大)”,但意义与大相关。在中文中,“上海的自来水”和“水来自的海上”有相同的字符集,但是具有不同的含义。在法语中,“l'amour fait passer le temps(爱使时间流逝)”和“le temps fait passer l'amour(时间使爱流逝)”具有相同的关键字,但是它们有不同的含义。对于许多表述,需要解析自然语言才能确定想要表达的含义。
[0114]
与简单提取关键字相反,将自然语言转换成语义解释的语义解析器是复杂的,但是能够更准确地表示思想,并且能够更好地理解表述的意图。“说d’oh的小伙子”是漫画人物霍默
·
辛普森(homer simpson),尽管“霍默(homer)”不是表述中的关键字。用于解译的适当的系统通过解析、语义学和琐碎的知识来确定这一点。
[0115]
考虑人们轮流谈判或者进行项目工作的地点,他们经常说:“the ball's in your court(现在就看您的决定了)”。基于关键字的映射会给出与运动相关的概念的假积极结果。
[0116]
考虑某些人谈论着装的地方,人们经常说“i like that on you.(我喜欢你穿这件)”。基于关键字的映射将无法标识着装的概念。
[0117]
在情感分析中使用基于关键字的自然语言的解译的好处是可能确定特定实体的情绪,而不是简单地在特定位置。例如,确定了幼儿园里的孩子喜欢艾莫(elmo)玩偶、高中生嘲笑艾莫背包、还有办公楼里的人们被网络浏览器中的艾莫弹出广告惹恼,可以帮助广告商决定放置艾莫广告牌的位置、如何在广告牌上显著突出艾莫的特征、以及对使用艾莫的形象来广告产品的商标权的出价金额。
[0118]
根据本发明的、使用解译的系统可以识别非关键字所隐含的概念,并且摒弃诸如从惯用语得出的错误概念之类的错误概念。因此,通过解译进行的映射会产生比传统关键字方法更准确的思想地图。
[0119]
数据库组织
[0120]
一些实施例(例如,需要进行实时分析的实施例)提供信息、识别紧急情况、或响应于动态改变的情况而采取行动。这样做需要进行快速的数据访问和分析。这样的实施例可以使用有索引的实时数据库,例如,局限于单个服务器的结构化查询语言(sql)数据库,。使用单个服务器避免了服务器之间的通信的延迟。
[0121]
一些实施例能够存储比可以比单个服务器上的所能够存储的更多的记录。在各种实施例中,解译记录具有不同的大小,并且通常每个记录在几千字节的范围内。一些实施例能够存储数万亿的解译。在一些实施例中,语音识别、解译或在存储之前的其他处理需要数秒的处理器时间。这样的系统需要广泛分布的存储和处理。非索引分布式数据库记录的框架(例如,海杜普(hadoop)或其他映射归约(mapreduce)类型的系统)可能是合适的。在某些情况下,从这样的分布式系统读取、筛选和处理记录可能需要数小时。
[0122]
一些实施例既支持实时数据存储和访问也支持大规模分布的数据存储和访问。一些这样的系统将最近采集的记录存储在有索引的实时缓存数据库中,并在一段时间后将记录写入分布式数据库。在一些这样的系统中,当从分布式数据存储装置撷取到解译时,从分布式数据库加载具有相同或相似解译的其他记录。一些这样的系统响应于在一个地理位置中采集到表述,加载在该地理位置的特定距离内的历史表述。为了更快地确定将加载到缓存中的记录,一些系统将请求限制在地理上在本地的数据中心、与特定用户id相关联的数据中心、或根据其他环境信息选择的数据中心。一些这样的系统维护缓存数据库中每个记录的分数。分数取决于记录访问的时间、记录采集位置与一个或多个人的位置的接近度、记录的采集时间的相位(phase)、以及各种其他相关信息。当来自分布式数据库的新记录达到时,缓存数据库会将分数最低的记录驱逐。
[0123]
一些实施例基于位置存储解译。这样可在访问速度方面有好处。地理地区沿着一个经度范围被划分成条带,其中所选择的条带宽度允许足够小的数据集快速访问选定条带。解译可基于它们沿着各自的条带的位置进行分类。每个条带单独地存储,例如,在分开的存储介质上。对跨多个条带的地区的搜索可以同时从条带存储阵列中的每一者读取条带内的适当范围的解译数据。如果位置范围恰好跨越条带之间的边界,则对小于条带的地区的搜索可以从单个条带内的连续范围或从两条条带获得搜索的全部数据。在一些实施例中,条带包括经度的范围。在一些实施例中,这些范围是不相等的并且被选择为确保在每个范围内解译数量大致一致。这通常对应于每个经度条带中采集的讲话者的人口数量。一些这样的实施例通过将解译数据从一条带移动到另一条带而间或地重新平衡存储分配。添加了新解译的条带可以重新进行分类。一些这样的实施例利用实际数目的存储设备和互联网带宽、基于数十亿个所存储的表述解译,使得向数十亿人提供实时广告和虚拟助理成为可能。
[0124]
一些实施例在单元网格上表示位置,并为每个网格单元提供单独的数据存储。因此,对于小于单个网格单元的搜索范围,基于该范围是没有跨越网格单元边界、跨越水平或垂直网格单元边界中的一者、还是同时跨越水平和垂直网格单元边界,搜索功能可能需要从一个、两个或四个网格单元库进行读取。一些实施例使用不同大小的网格单元,针对具有较低表述密度的地区使用较大的单元,以使得存储组具有大致一致的数据量。一些实施例将大网格单元构成为邻接的小网格单元的集合。
[0125]
使用条带或基于网格的存储的一些实施例可以按地区来划分数据,例如按各个城市来划分。针对特定位置存储数据的存储设备可以被放置在靠近数据所表示的位置的数据中心中,从而最小化访问延迟和长距离网络带宽。
[0126]
一些实施例将数据划分在由中心点发散的径向段中。因此,条带是特定宽度的环。如同纵向条纹,环的宽度不需要一致,但是有规律的宽度可以简化并从而加快关于在哪个环存储解译数据以及从哪个环撷取解译数据的计算。一些实施例存储环的宽度与距中心的距离成比例的环。环的好处在于,通过将中心放置在密集地区的中心,宽度一致的环自然趋向于具有相似的数据量。一些实施例在城市区域以及周围使用环,但是对于落在任意城市环之外的位置,数据按纵向条带分类。这对大多数访问来说可保持快速计算,只是仅在远离城市区域的特殊用例下需要进行更复杂的计算。
[0127]
数据挖掘
[0128]
对原始数据库记录的处理可发生在不同的时间,包括当采集到新的表述时、当分析者创建思想地图时、以及在中间时间。中间处理步骤消耗原始数据库中的数据,并将其转换为数据挖掘数据库中的数据。本节介绍数据挖掘子系统91的功能。数据挖掘子系统从原始数据库撷取记录、对数据执行索引、聚合和关联,并将所得到的转换后的数据存储在数据挖掘数据库中以供分析者使用。
[0129]
并非所有存储在原始数据库中的记录都被用来创建挖掘的数据。一些实施例将地理位置不确定度超过显示大小的某一部分的数据库记录忽略,因为这样的解译的地理位置记录没有意义。一些实施例将时间度量超过某一时间限制的测量记录忽略或丢弃,因为旧的度量也不准确。由于世界不断变化,表述解译的信息价值随着时间的推移而下降,变得陈旧。一些实施例将测量存在时长与速度测量相结合:移动越快测量必须越近期,以被定认为是有用的。某些类型的值根据诸如衰减之类的已知摊销(amortization)方案逐渐消失,其中衰减的速率取决于信息的类型。其他实施例根据固定的到期日来移除值,有效性的持续时间取决于信息的类型。
[0130]
一些实施例自主地执行数据挖掘。大多数这样的数据挖掘活动依赖于主动地和无条件地执行对原始数据的某些分析脚本或程序。一些实施例定期地进行分析或响应于事件而进行分析。一些这样的实施例在获取到原始数据后逐步执行分析。
[0131]
原始数据库记录的自主处理的示例包括根据诸如位置、时间、句法构造或语义概念的呈现、以及解译的任意其他方面的值来索引原始数据库。它们还包括收集数据的统计信息,例如事件计数和直方图、概念、位置范围数据、时间范围数据、交叉分析两个或更多个维度的多变量直方图、多变量直方图密度估计和多个测量的各种其他联合统计信息(包括上述数据的均值和方差)。
[0132]
在一些实施例中,数据挖掘专家驱动数据挖掘操作,例如,上述那些数据挖掘操作和更专业化的其他操作。挖掘的数据可以通过来自数据挖掘者的命令或自动的脚本从原始数据导出。该实施例在结果的数据库中收集挖掘的数据94。一些实施例在诸如使用postgis格式的空间数据库之类的空间数据库中存储地理信息,其中存在诸如距离、面积、并集、交集和特殊几何数据类型的函数,并且可被添加到数据库。空间数据库可用于存储和撷取表示在几何空间中定义的对象的数据。postgis是postgresql数据库管理系统的开源和可免费使用的空间数据库的扩展。
[0133]
一些实施例计算特定概念的显著性来作为其本地相关性的指示。显著性指示概念在关注的地方相对于其他地方的相关性。显著性可用作筛选映射结果的值。它允许分析者和数据挖掘者将他们的工作重点放在最有价值的概念和位置上。
[0134]
一些实施例从如下的2d密度数据导出显著性。系统获得是两个密度之间的差值的概念的显著性度量,例如,由相关性权重加权的直方图计数。小规模(在小范围内平均)的概念的密度被称为窄密度。大规模(在大范围内平均)的概念的密度被称为宽密度。在一些实施例中,概念的显著性是窄密度和宽密度之间的差。这对应于“中央环绕”筛选器的使用。这种设计的许多变体是可行的。一些实施例采用两个密度的比率,而不是它们的差。这样做的一个原因是,对于根据阈值做决策而言,概念的绝对密度不如其相对于背景的密度那么重要。使用比率与使用密度的对数密切相关。这就会出现关于近零密度的问题。当使用比率时,最好在相除前向分子(窄密度)和分母(宽密度)添加偏差项,以避免小分母带来的问题,小分母使得比率激增。使用较大偏差会导致比率计算的结果与差值计算的结果接近。中间偏差值是最佳的,例如由数据的全局统计量化的值,如加权显著性的中值。
[0135]
如上所述,显著性是必须被定义的两个标度(窄标度和宽标度)的函数。一些实施例允许分析者指定标度值。另一方法是分别分配指定的乘数给窄标度和宽标度,例如,所显示地图大小的5%和30%。因此,缩放自动调整要显示的窄标度和宽标度。在给定窄标度和宽标度的情况下,在处于这些标度的矩形、圆或其他地区上求局部平均值。一些实施例补偿边缘效应。
[0136]
实时应用的一些实施例(例如,移动电话上的动态广告)利用迅速撷取使用快速算法来访问和分析大型数据集。一些实施例将数据组织到分区内。一些这样的实施例将数据以parquet格式存储在hadoop中以更快地进行撷取。apache parquet是hadoop的基于列的存储格式。一些数据集有很多列,但是使用子集而不是整个记录来进行操作。parquet优化这种类型的操作。此外,parquet可以使用快速压缩技术或可替代的压缩技术来压缩数据。这样减少了对存储空间的需求和访问延迟。带有parquet的apache spark和spark-sql支持并行和分布式访问。例如,与使用文本相比,parquet可以将spark sql性能提升10倍。这是由于低级别阅读器筛选器、有效的运行计划和良好的扫描吞吐量。与使用文本相比,使用带有压缩的parquet通常降低75%的数据存储空间。
[0137]
分析者请求和响应
[0138]
在一些实施例中,基于挖掘的数据进行分析。在一些实施例中,除了由数据挖掘者执行的挖掘之外,分析者还为了特殊目的进行数据挖掘。图7示出了呈现可供数据挖掘者和分析者使用的统一接口的实施例。数据挖掘子系统101提供对数据库102的访问。数据库102包括解译及其语境的数据库103。数据库102还包括挖掘的数据的数据库104。在该综合系统中,数据挖掘者和分析者之间的区别是数据挖掘者可为数据提供者工作,而分析者是数据提供者的客户。在一些实施例中,分析者可用的功能是数据挖掘者可用的功能的子集。图7的实施例将所有数据(原始数据库和挖掘的数据)聚集在单个联合数据库102中。
[0139]
在各种实施例中,分析从原始数据库挖掘的数据包括查找、筛选、撷取数据子集、聚合撷取的数据的各方面、计数、匹配、比较、排序、百分比计算、建立直方图、近似分布、显示聚集的数据与地区的关系、以及其他数据处理功能。关于分析类型的示例是针对一组地区中的每个地区计数具有特定属性的解译或概念。一个这样的属性是特定实体的存在。例
api。
[0149]
在一些实施例中,解译是使用地理上位于它们的表述的中心的词来显示的,但却是基于力导向绘图算法放置的。在一些实施例中,用于显示由解译导出的文本的字体大小取决于其在表述解译中相对于其他表述解译中的加权使用频率的使用频率。在一些实施例中,文本矩形的大小是基于频率的,并且调整字体大小以使其矩形按比例缩放。
[0150]
一种类型的热图示出了表述的情感负荷,情感负荷可以被表达为灰色透明度地图着色层,其中深灰色级别传达了表述中概念的情感负荷的消极度。一种类型的热图显示有关表述的情感内容的信息。一些实施例将情感内容映射到颜色标度并将其呈现为地图着色层,例如,喜欢=黄色、悲伤=蓝色、厌恶=绿色、恐惧=紫色、愤怒=红色,正如在皮克斯电影“头脑特工队(inside out)”那样。
[0151]
不直接在表述中表达的暗含概念(例如,“the ball’s in your court(现在就看您的决定了)”)出现在地图上。如果分析者调整筛选器中的概念强度阈值的级别,则直接表达的概念会被显示出。一些实施例允许分析者列出感兴趣的特定概念,在这种情况下,减少一般概念强度来确定呈现哪个特定概念,并且与直接表达的概念具有显著强的图形连接权重的概念在显示中被凸显出。
[0152]
图10示出了根据实施例的具有对概念和概念被表达的位置的指示的地理图。图11示出了图10的概念层,而没有示出基本地理地图。一些实施例允许分析者基于时间范围来筛选显示的结果。一些实施例允许基于一天中的时间进行筛选。图12示出了在上午表达的概念,而图13示出了在下午表达的概念,以及图14显示了在晚上表达的概念。
[0153]
另一类型的思想地图是地区地图,地区地图基于所采集的具有某些属性的表述的数目而被高亮显示的地区。例如,如果分析者应用针对关于食品的表述的筛选器,则地图将显示在地图地区中每个网格单元内的这种表述的密度。一些实施例针对每个位置显示具有最大显著性的概念。一些实施例针对每个概念显示出该概念显著性最大的位置。具有最高显著性的表述性质靠近它们的具有最高显著性的位置。例如,如果分析者查询在显示的地图地区内表达的最常见的概念,则地图显示可以示出表示最频繁表达的概念的词。在一些实施例中,当可显示的性质趋向重叠或变得拥挤时,可视化系统仅使具有较大显著性的性质或概念可见。当分析者改变缩放级别时,系统重新计算热图层、密度、显著性和所有可见性决策。
[0154]
一些实施例针对所表达的概念与指定的筛选概念相匹配的每个位置显示标记,例如,呈现出点。一些系统允许放大和缩小点以及比特定分辨率级别挨得更近的点合并。一些系统允许将诸如由计算机鼠标控制的指针之类的指针放在表述标记上;响应于这样的悬停,这样的系统弹出显示,其显示由标记指示的一个或多个表述的文本或揭示所选择的解译的方面。一些系统基于表述中的指定实体或实体属性和情感的值来使用不同颜色和形状来呈现标记。一些系统覆盖不同类型的信息,例如,不同的颜色和文本。
[0155]
图8示出了示例性显示中的地图层的实施例。基层61显示诸如从谷歌地图获得的地理地图之类的地理地图。第二层62将情感热图显示为覆盖在第一层上的半透明叠加层。第三层63是点叠加层,该层示出已经采集的经解译的表述的地点。该显示仅显示解译和相关联的数据与指定筛选器匹配的地点,例如,在晚上收集的表述,这些表述的概念涉及饮食或饮酒,并且表达关于饮食或饮酒场所的问题或意见。顶层64是被选为代表解译概念的概
念词的叠加层。
[0156]
诸如图8那样的显示中的每一层对标度敏感。一个明确的理由是可以打包在每个显示层中的信息密度受到其易读性的限制。有用且重要的是,针对特定的目的和标度,不仅要限制显示层上的数据量,还要仔细选择要显示哪些数据。如果目的是提供是-否筛选器,那么只考虑被筛选的数据。如果目的是提供相关性的逐级度量,则统计数据(例如,人气的度量)将通过相关性被加权。
[0157]
思想地图不需要根据地球地理学来表示位置。一些实施例将思想地图表示为地标图。地标图是一种每个节点表示地标且每条边线表示其连接的节点之间的线性距离的图。一些实施例可视地显示图,以利用表示较长距离的边线被绘制为长于表示较近距离的边线来显示标度。一些实施例用距离度量来标注边线。
[0158]
在一个示例图中,一个节点表示特定的大树,另一连接的节点表示特定的停止标志,对于旅客来说,这个停止标志应当被注意到,因为破坏者在该停止标志处挖了个洞。表示有洞的停止标记的节点连接到表示特定自动售货机的节点。
[0159]
一些实施例可根据乘客向驾驶员给出的指示的表述构建另一示例图,例如,在图9中的地图上显示的城镇中行驶时。一个节点表示乘客说“转到金色大街(gold street)”的位置。该节点连接到表示乘客说“转向凯瑟琳大街(catherine street)”的位置的节点。该节点连接到乘客说“转向n taylor大街”的位置。该节点连接到乘客说“转到霍普大街(hoppe street)”的位置。该节点连接到乘客说“转向莫法特大街(moffat street)”的位置。基于乘客做出表述的顺序连接节点,形成驾驶行动点的图。图形边线表示每个节点之间的时间量,这样的时间量通过分析不同乘客的指引方向的表述之间的时间得出的。
[0160]
对于某些应用,通过节点/边线图表示的位置可以比表示地理位置的地图更有用。例如,对于在在移动电话上显示广告的应用,重要的是要知道从一节点向另一节点移动的消费者何时可能很快地到达特定营业所附近的节点。这样的系统会在消费者到达之前不久显示广告。如果使用严格的地理位置地图来提供具有如此准确的及时性的广告,系统则必须知道轨迹、速度以及速度和轨迹的预期变化,以便估算显示广告的最佳时间。
[0161]
数据的使用
[0162]
在一些实施例中,数据分析者利用在挖掘的数据中找到的结果来实现特殊的目的。存储在数据库中的原始数据和挖掘的数据可以包括比数据的特定用处所需的信息的更多的信息。如果不需要诸如个人信息(例如,特定人的姓名和电话号码)、时间或情感内容之类的解译的属性,可以忽略它们。
[0163]
在一些实施例中,数据分析者是广告公司的代理,他们寻求选择投放对特定产品或服务的广告的广告牌的最佳位置。
[0164]
挖掘的数据的另一用途是预测用户行为。一些实施例,在采集表述不久之后,解译该表述;标识一个或多个可标识的行为;并将解译和行为作为记录存储在数据库中。一些实施例在每个数据库记录中标识和存储多个行为。一些实施例采集运动行为,例如,由加速度计检测到的运动方向和幅度,或由卫星地理定位系统检测到的位置或速度的变化。一些实施例采集跟随表述的购买行为。
[0165]
一些实施例将最近从特定用户接收到的解译与先前存储的许多用户的解译进行比较以进行众包预测。通过这样做(而非仅仅根据用户以前的行为来预测该用户行为),系
统可以其他人跟随类似表述的行为来预测用户行为。一些实施例将相关的用户id随解译记录一起存储在数据库中以将表述与特定用户相关联。这样的实施例从数据库中筛选解译以进行比较,从而个性化针对各个用户的预测。如果系统具有可用的个性化行为历史,则由于各个用户具有独特的行为模式,通过个性化预测而不是众包预测,系统可以更准确地预测个体的行为。
[0166]
标识解译序列可用于进行预测思想序列的分析。一些实施例存储从最近采集的表述得出的解译,该解译具有到从先前采集的表述得出的解译、从下一被采集的表述得出的解译、或这两者的链接。标识个人的想法序列的允许系统进行预测及客户化定制以向用户提供帮助或广告。例如,如果用户倾向于在表达关于从托儿所接孩子的想法不久之后表达关于烹饪晚餐的想法,那么当检测到关于托儿所的表述时,系统便可以预测用户将很快考虑烹饪晚餐。标识人们(例如,从事会话式对话的人)之间的思想序列的模式提供了对人类的心理行为的分析以及特定表述对听众思想的影响。
[0167]
顺带地,标识解译的序列还有助于消除具有多个合理解译的表述(例如“ed wanted to impress the girl with the pearl necklace(艾德想打动这个佩戴一条珍珠项链的女孩/艾德想用一条珍珠项链打动这个女孩)”)的歧义。
[0168]
在另一示例中,电子广告牌检测特定人群的趋近以及在它们到达之前的改变。由许多人共享的公共场所中的这样的广告牌在对每个人的最近的表述的解译之间检测出共性,并根据共同的兴趣选择广告。
[0169]
在另一示例中,公共安全系统检测与解译和相关联的情感地图的危险和强度有关的解译。当多个这样的表述在极近的范围内出现时,系统基于做出表述的人的位置和移动方向来识别危险的可能来源。这例如在发生枪击案时、在地震的震中附近、或发生严重的车祸时是有利的。
[0170]
例如,概念地图中与车祸或缓慢交通概念相关的局部密度峰值可以允许公共安全系统在呼叫者能够足够准确地描述位置之前识别事故位置以进行响应。关于认购黑市物品或物质(例如,某些毒品)的表述指示警察巡查能够最有效地提高社区安全的特定地点、当日时间。
[0171]
一些实施例对传染病学是有用的。筛选针对明确指示疾病症状的表述的解译或隐含与疾病症状相关的概念允许在地图上绘出传染性疾病的密度和蔓延。这可以指导药品的分发和医生的出行模式,并指导资源的应用来标识改善卫生设施或确定环境危害的来源。
[0172]
时间段筛选允许分析全年传播的复发性疾病。对变化的密度数据进行的信号处理按学校片区来指示最大的周波动。这表明疾病(例如,流行性感冒)扩散最频繁并且卫生设施需要改善的学校或工作场所。
[0173]
根据一些实施例,一种预测疾病爆发的方法是在有疾病症状的明确指示之前分析历史表述解译。
[0174]
在可用其他方式检测的疾病指示之前将个人的识别信息丢弃并且对个体解译进行平均,这样允许所预测的表述的标识和加权。虽然在个体的基础上检测这样的想法是对即将来临的健康问题的非常不准确的预测,但是检测跨相近地理位置内的大量人群的表述中的变化的概念并且进行控制以对当前事件产生影响可以指示即将发生疫情的可能性增加。时事可以对表述产生非常大的影响。例如,播放关于鲨鱼的电视节目将导致所有与水生
和海洋相关表述的普遍增加。但是,时事可能会使概念解译之间可识别关系中出现高频尖峰,而对概念的频率中的改变进行低通滤波表明在人口条件下更广义的流行病学趋势。
[0175]
使用地标图(如上所述)的一些实施例对于导航是有用的。即使是诸如全球定位系统(gps)、伽利略(galileo)、格洛纳斯(glonass)、北斗之类的基于卫星星座的地理定位系统也不可用来进行室内地点(例如,地下商场、拥堵或军事袭击等)的导航,但是思想地图可以提供精确导航。例如,系统对解译进行筛选来选出特别针对当前位置的解译。例如,“我在猎曲奇兵(soundhound)”会被包括在内,而“我要去计算机历史博物馆”会被忽略。扬声器向系统指示目的地和当前位置的本地地标。接着,系统向用户指示行进方向以及几个预期沿该路线的可识别的地标。当用户请求进行下一步时,系统指示下一组地标。这比诸如谷歌地图之类的直接使用数据源的简单的基于地标的导航更为出色,因为这种地图只能提供有限的信息,例如关于业务场所和特定的关注地点的信息。大型的解译数据库有许多来自过去的表述(例如,“好大一棵树啊”、“看!妈妈,有人在那个停止标志上打了个洞”、以及“这个【自动贩卖机】吞了我的美元”)的细致的位置识别线索。孩子是地标数据的非常好的来源。由于他们倾向于说出他们对世界的了解,所以他们提供了许多很少有成年人评论的关于显著地标的表述。通过收集具有地理相关性的表述,地标图提供表述和地点之间的关联,其中地点由特定对象来表示。
[0176]
一些实施例对于犯罪侦察和查找恐怖分子或造反分子是有用的。系统从调查者那里获取一组解译,将它们与从解译中得出的概念相匹配,并返回它们被表达的位置的列表。一些实施例获取相关解译值的集合(例如,与特定人员的连接)、从数据库中筛选包含该信息的表述、以及返回位置列表。
[0177]
一些这样的实施例维护人实体图,该人实体图具有针对每个可识别的说话的人的节点,以及到发言人在表述中曾提到过的每个其他人的指向边线。边线还包括关于人们之间可辨别关系的信息,以及提及的频率和新近度。人节点随着时间的推移积累属性值对,因为可以从采集的表述中确定这些属性值对。类似的人图实施例对于广告商是有用的。
[0178]
广告用例和示例
[0179]
使用挖掘的数据可适用于选择要投资资源的位置。向某一位置投资资源的示例是选择广告牌的位置。某些实施例接受来自广告买家的广告,并计算其在任意给定位置和时间的相关性。一些实施例在选择要呈现的广告时还考虑消费者的情况。广告买家在出价时至少指定关注的地区和概念。在一些实施例中,广告买家可以表达地区范围和概念的功能。概念功能的一个示例是表述是否包括中国食物的概念。概念功能的另一示例是是否表达天气概念,它是否包含与热、冷相关或与这两者都不相关的概念。
[0180]
各种实施例允许广告买家通过一个或多个邮政编码、地理政治学定义、兴趣点、纬度/经度范围或者通过自定义的位置边界(例如,广告牌的视野内的位置)来指定地区。其他指定筛选方式的方法是可行的,包括指定时期内的阶段、情感范围、用户属性等。
[0181]
如果消费者在广告的出价地区内做出表述,则广告将进入竞价,并在表述的解译上运行广告出价功能。一些实施例基于固定的出价金额来选择广告。一些实施例将距离加权函数考虑在内,该距离加权函数与表述的位置到针对出价指定的中心位置的距离成比例地对广告的出价金额产生影响。在一些实施例中,广告的出价金额考虑了表述的解译和针对出价指定的概念之间的概念距离函数。广告提供商使用专有公式,其中任何一种都适用
于实现本发明的实施例。一些实施例使用最高出价金额从广告数据库中选择要显示的广告。
[0182]
各种实施例将所选择的广告呈现在广告牌上、将它们显示在诸如电话或汽车之类的移动设备上、或者将其作为音频片段在移动或固定设备上进行播放。可使用任意广告传送方式。
[0183]
一些实施例允许广告买家将出价金额指定为以下各项中的一项或多项的函数:来自表述的信息、环境信息、以及响应于对信息或动作的请求而提供的信息。环境信息的一些示例是人口统计属性、情感、时期内的阶段、以及一个或多个具体的人id。
[0184]
一些实施例向广告买家呈现对表述解译的地理洞悉。图9-图15示出了使用这种实施例的简单场景。图9示出了具有玛丽亚
·
埃琳娜(maria elena)墨西哥餐厅801、瓦尔(vahl)餐厅和酒吧802、两个公共汽车站803和804、美国邮政局805和加德纳家庭保健诊所806的小镇的地图。这个系统采集对移动电话上的虚拟助手应用讲出的查询。在一天当中,在玛丽亚
·
埃琳娜801处,有人问:“我们应该在午饭后带孩子去哪里?”;在公交车站804处,有人问:“下一班车什么时候到?”在瓦尔802处,有人问:“鸡尾酒玛格丽塔里含什么?”在邮局805处有人问:“我的包裹什么时候到?”在保健诊所806处,有人问:“我可以在哪里抓药?”[0185]
图10显示了在给定一天中并且地理上位于该小镇中累积的显著概念。在玛丽亚
·
埃琳娜801内及其周围,孩子们、食物、午餐、墨西哥卷饼和花费被突出表达。在靠近公共汽车站803的街区的阴凉侧,公共汽车、冷、以及等待等概念词在早晨被表达;在靠近公共汽车站803的街区的向阳侧,通勤时间、公共汽车和太阳被表达。在瓦尔餐厅802,表达了食物、晚餐、鸡尾酒和体育运动领域的概念词被表达。整个晚上,关于不同体育运动的表述被表达出来。由于每一项特定体育运动都与体育运动概念有很强的关系,所以体育运动一般具有比任何单个体育运动都要高的权重。例如,有一天举行一场非常受欢迎的篮球比赛,该篮球概念的权重通常会超过体育运动概念。在一天中,在邮局805处,慢、垃圾邮件和包裹被表述。在保健诊所806处,孩子、疾病、医生、药和费用被表述。驾驶概念在向镇外延伸的金色大街807上被表述。具体地,各种与驾驶有关的概念全天被表述,因此,更广泛的驾驶概念通过显著性强度在地图上标识出。这种效果就如同体育运动示例一样,取决于在思想地图系统中按分类学表示的概念的层级。
[0186]
在对图10的地理解译图进行分析之后,啤酒广告商决定对玛丽亚
·
埃琳娜餐厅801和瓦尔酒吧802之间的广告牌上的广告进行出价,如图15所示。系统分析在广告牌投放后的一个月内的表述。后续分析显示,啤酒在公共汽车站803被表达、在玛丽亚
·
埃琳娜餐厅801处被强烈地表达、在瓦尔酒吧802处被非常强烈地表达、甚至是在金色大街807上由司机表达。对表述进行采集和解译不仅允许广告商衡量特定广告的成功性,还允许他们衡量衡量广告牌影响人们的思想的能力。广告牌的影响力取决于它的位置、方位和周围的环境。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1