基于作者学术背景的合著论文作者贡献度评价分析方法与流程
1.本发明属于机器学习应用技术领域,具体涉及一种基于作者学术背景的合著论文作者贡献度评价分析方法。
背景技术:
2.随着烟草科学研究活动的不断深入以及研究领域的不断扩大,烟草科学研究问题的复杂性、综合性和跨学科日益突出,越来越多的烟草科研工作者开始关注交叉学科的知识融合,科研合作已成为了烟草科学研究的主要趋势,并且合作的规模和覆盖范围也越来越大。科研合作是科研工作者技术交流、知识融合、资源共享的重要途径,科研工作者之间通过合著论文进行科研合作是一种非常常见的成果产出形式,通过论文合著不仅可以提高科学研究质量,加快学术产出速度,拓展学术影响力,还可以加快学术知识传播和成果推广。近年来,移动互联技术的快速发展使得烟草行业内不同研究领域的科研工作者以及烟草行业内和行业外的科研工作者之间的学术交流越来越方便快捷,科研合作不再受地域、机构、学科等条件的限制,科研人员之间的合作越来越频繁,合著论文数量也显著增加。烟草行业是一个跨越多个学科的领域,对烟草领域合著论文作者贡献度的评价分析不仅可以评估烟草科研工作者真正的学术能力,还可以挖掘学者之间的关联关系和合作态势,并且有利于对烟草科研人员进行客观的科研产出绩效评定以及烟草领域学者专家库的构建。
3.合著论文中作者贡献分配问题一直没有一个很好的能让所有学科领域学者都满意的解决方案,烟草领域也面临这样的问题,在科研合作日益密切的大科学时代,迫切需要对论文合著者进行合理的学术贡献评估和荣誉分配,维护良好科研道德秩序的维持,避免因虚假署名等学术不端行为造成的学术成果版权纠纷以及干扰职称考核评定等问题。目前合著论文作者贡献度计算方法总体上可以分为以下三种:
4.(1)直接计算方法。这种算法将论文的贡献全部分配给第一作者或通信作者,无论有多少其他合著者都不予分配权限,仅仅将第一作者和通讯作者视为论文的共同贡献享有者,该方法操作简单,但忽略了其他合著者的贡献。
5.(2)基于作者数量的学术贡献权重算法。这种算法默认所有论文作者的贡献相同,按照作者数量平均分配贡献值,不区分作者的先后顺序,这种算法无形中放大了大部分作者的贡献,对论文的真正贡献者是不公平的。
6.(3)基于作者署名顺序的学术贡献权重算法。这种算法假设所有合著论文的署名均以作者贡献大小的次序排列,依据署名顺序计算作者贡献的权重。它综合考虑了论文中作者数量和作者署名顺序对贡献权重的影响,但不能正确反映署名靠后的通信作者对论文做出的重要贡献。
7.综上所述,目前合著论文作者学术贡献度计算方法还存在多种不足之处,现有方法中更多是关注对作者数量和署名顺序,而这些因素并不能真正反映作者实际对合著论文的贡献度。
技术实现要素:
8.本发明的目的在于提供一种基于作者学术背景的合著论文作者贡献度评价分析方法,用以解决现有技术评价合著论文作者贡献度的方法无法准确评价论文合著者对合著论文实际贡献度的问题。
9.为解决上述技术问题,本发明所提供的技术方案以及技术方案对应的有益效果如下:
10.本发明的一种基于作者学术背景的合著论文作者贡献度评价分析方法,包括如下步骤:
11.1)获取待分析合著论文,识别出待分析合著论文的作者;
12.2)提取待分析合著论文的若干主题关键词,以确定待分析合著论文主题的研究领域;
13.3)对于待分析合著论文的某一作者,获取其已发表的论文,从中提取出该作者的若干学术关键词,以确定该作者的学术研究领域;
14.4)计算待分析合著论文的若干主题关键词和作者的若干学术关键词之间的语义相似度,以确定待分析合著论文主题的研究领域和作者的学术研究领域之间的关联性,并将确定的相似度值作为评价作者对待分析合著论文贡献的基于学术背景的贡献权重ωi;
15.5)依据所述某一作者在待分析合著论文中的署名顺序和所述某一作者的贡献权重,确定所述某一作者对待分析合著论文的贡献度;其中,贡献权重越大,贡献度越大。
16.上述技术方案的有益效果为:本发明将作者的研究领域、作者学术关键词等学术背景对合著论文参与程度的影响考虑在内,并结合作者在论文中的署名顺序来综合评价作者对合著论文的贡献程度。具体的,采用如下方式计算作者的研究领域、作者学术关键词等学术背景对合著论文参与程度的影响:首先提取合著论文的主题关键词,然后利用作者的已发表论文来提取作者的学术关键词,最后计算两者之间的语义相似度来确定合著论文主题的研究领域和作者的学术研究领域之间的关联性。相对于现有技术方法,该方法提高了论文合著者实际学术贡献度计算和分配的全面性和精准度,弥补了现有技术对论文合著者实际学术贡献评估不准确的不足之处;而且,该方法还可以用来评估烟草科研工作者真正的学术能力,进而为各领域科研人员公正客观的科研绩效评定以及各领域学者专家库的构建服务。
17.进一步地,步骤5)中,所述某一作者对待分析合著论文的贡献度采用如下公式计算得到:
18.λi=ki*ωi19.式中,λi表示按署名顺序确定的第i位作者的贡献度;ki表示依据第i位作者在待分析合著论文中的署名顺序确定的署名顺序权重。
20.上述技术方案的有益效果为:将署名顺序权重和贡献权重的乘积作为作者的贡献度,能体现出署名顺序权重越大则作者的贡献度越大,以及贡献权重越大则作者的贡献度越大这个原则,计算简单。
21.进一步地,作者的署名顺序越靠前,作者的署名顺序权重越大。
22.进一步地,若作者为第一作者和通讯作者外的作者,则第i位作者的署名顺序权重ki为:
[0023][0024]
式中,n表示待分析合著论文的所有作者的总个数,i≥2;
[0025]
若作者为第一作者,则第一作者的署名顺序权重k1为:
[0026][0027]
式中,α表示第一作者的附加权重,0<α<1;
[0028]
若作者为通讯作者,则通讯作者的署名顺序权重ki为:
[0029][0030]
式中,β表示第一作者的附加权重,0<β<1。
[0031]
上述技术方案的有益效果为:考虑到第一作者和通讯作者是合著论文的核心作者,且一般情况下在论文合著过程中会承担更多的工作,对论文合著的贡献更大,因此相对于其他作者,对第一作者和通讯作者均附加了一个权重,以提高作者评估的准确性。
[0032]
进一步地,步骤4)中,所述计算待分析合著论文的若干主题关键词和作者的若干学术关键词之间的语义相似度所采用的手段为:以待分析合著论文的若干主题关键词为基础,构建合著论文主题关键词词向量;以作者的若干学术关键词为基础,构建作者学术关键词词向量;利用余弦相似度法计算合著论文主题关键词词向量和作者学术关键词词向量之间的语义相似度,得到的相似度计算结果为待分析合著论文的若干主题关键词和作者的若干学术关键词之间的语义相似度。
[0033]
上述技术方案的有益效果为:利用语义相似度计算方式来评估待分析合著论文主题的研究领域和作者的学术研究领域之间的关联性,该方法简单且有效。
[0034]
进一步地,步骤3)中,所述提取出该作者的若干学术关键词所采用的手段为:对作者已发表的论文进行分词处理;根据分词处理结果,对主题关键词进行提取,生成主题关键词矩阵;根据分词处理结果,对论文关键词进行提取,得到论文关键词词向量;计算同一主题下的主题关键词和所有论文关键词之间的语义相似度,得到各个主题下的主题关键词和论文关键词之间的相似度排序结果,选择相似度较高的若干个主题关键词和论文关键词作为该作者的学术关键词。
[0035]
进一步地,采用lda主题模型对主题关键词进行提取,采用word2vec词向量模型对论文关键词进行提取。
[0036]
进一步地,步骤2)中,提取待分析合著论文的若干主题关键词的手段为:对待分析合著论文进行分词处理,并统计分词后词语的属性信息;将分词后词语的属性信息输入至词语分类模型中,以得到分类结果;利用分类结果确定每个词语的权重,并作为textrank算法的初始权重,采用textrank算法进行处理以筛选出待分析合著论文的若干主题关键词。
[0037]
进一步地,所述词语分类模型为支持向量机模型。
[0038]
进一步地,所述属性信息包括语意、词频、词性、长度、出现的文档数和文档中位置中的至少一种信息。
[0039]
上述技术方案的有益效果为:选择了各种不同类型的属性信息来对词语进行聚类和分类,使得分类效果更准确,从而保证了作者的学术关键词筛选的准确性。
附图说明
[0040]
图1是本发明的基于作者学术背景的合著论文作者贡献度评价分析方法的整体流程图;
[0041]
图2是本发明的基于作者学术背景的合著论文作者贡献度评价分析方法的步骤三流程图;
[0042]
图3是本发明的基于作者学术背景的合著论文作者贡献度评价分析方法的步骤四流程图。
具体实施方式
[0043]
本发明将合著论文作者的学术背景考虑在内,来分析合著论文作者对合著论文的实际贡献程度。下面结合附图和实施例,对本发明的一种基于作者学术背景的合著论文作者贡献度评价分析方法进行详细说明。
[0044]
方法实施例:
[0045]
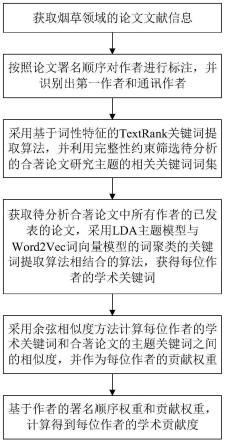
本实施例以合著论文为烟草领域的合著论文为例来具体介绍本发明的基于作者学术背景的合著论文作者贡献度评价分析方法,其整体流程如图1所示,过程如下:
[0046]
步骤一,获取烟草领域的论文文献信息,并解析论文题目、作者名称、作者署名顺序、单位名称、论文关键词、学科分类号等基本信息。假设所要分析论文中按署顺序排列的作者分别为a、b、c、d、e。
[0047]
步骤二,按照论文作者署名顺序对作者进行标注,并识别出第一作者和通讯作者,分别为a和e。
[0048]
步骤三,针对待分析的合著论文,采用基于词性特征的textrank关键词提取算法,并利用完整性约束筛选该待分析的合著论文研究主题的相关关键词词集(即合著论文的主题关键词),以确定该合著论文主题的研究领域。如图2所示,具体实现方法如下:
[0049]
1)从文献数据库中下载所需的合著论文数据,对原始论文数据进行预处理,并进行词性标注,结合领域词典,进行文本分词和去停用词处理,以得到分词处理结果。
[0050]
2)统计分词后各个词语的属性信息,主要包括词语的语意、词频、词性、长度、出现的文档数和位置。
[0051]
3)将各个词语的属性信息输入至支持向量机模型中,得到分类结果,处于一个分类的词语的权重所赋予的权重一致,并将赋予的权重作为textrank初始权值,采用textrank算法进行处理以得到所有词语的排名。
[0052]
4)将候选词排名由大到小的顺序排序,基于给定阈值并利用完整性约束筛待分析的合著论文研究的若干主题关键词,形成的主题关键词集合为ω={农作物,病虫害,图像识别,深度学习,水稻,智慧农业,目标检测,andorid,数据筛选,特征选择}。
[0053]
步骤四,获取待分析合著论文的所有作者的已发表的论文,采用lda主题模型与
word2vec词向量模型的词聚类的关键词提取算法相结合的算法,从文本摘要、引文、以及全文中获取作者的主题关键词和论文关键词,进而获得每位作者的学术关键词,以确定每位作者的学术研究领域。针对合著论文作者a、b、c、d、e,如图3所示,具体实现方法如下:
[0054]
1)从文献数据库中下载所需的论文数据(即该作者所有的已发表论文,在有部分论文无法获取的情况下仅获取部分已发表论文也可),对原始数据进行预处理,并进行词性标注,结合领域词典,进行文本分词和去停用词处理。
[0055]
2)利用lda主题模型对于数据集的主题进行初步提取,生成主题-词(m
×
n)矩阵。这里每一个主题对应有若干个主题关键词。
[0056]
3)根据步骤1)中获取的分词结果,采用word2vec词向量模型进行训练学习,生成词向量模型,从而获取得到该作者的论文关键词词向量。word2vec词向量模型是一种简化的神经网络,利用one-hot对句子进行编码,用指定长度的向量表示每一个在句子中出现的词,将所使用的关键词转化为语义级别的单词特征向量形式,然后再计算关键词之间的语义相似度。本实施例中,word2vec嵌入模型的训练参数分别为:最相似词维度topnsize=40,上下文窗口大小参数window=5,高频词汇的随机降采样的配置阈值为1e-3,为获取关键词向量采用cbow算法模型并采用softmax方法进行优化。
[0057]
4)根据步骤3)生成的词向量模型,用余弦相似度方法计算步骤2)中某一个主题下词语与词语之间的相似度,作为两点之间的权重。设置阈值过滤掉权重较低的词关系,通过构建关键词关系网络,利用pagerank方法进行迭代,最后输出pr值最高的topn1个词作为该主题下的关键词。对于其他主题,同样采用该方式筛选出pr值最高的topn2个词作为该主题下的关键词。将每个主题下筛选出的关键词合并。topn1和topn2可相等,也可不等。
[0058]
5)合并后组成关键词网络,对其进行过滤,将一些干扰或者无用词筛掉,以最终得到该作者的若干学术关键词。
[0059]
本实施例中,按照上述方法得到的各作者的学术关键词集合为:
[0060]
a={大数据,神经网络,深度学习,人工智能,传感器,图像识别,智慧农业,农作物,病虫害,特征选择};
[0061]
b={企业管理,管理创新,管理模式,人力成本,员工,规章制度,考核机制,绩效管理,组织结构,资源配置};
[0062]
c={智慧农业,大数据,农作物,水稻,烟草青枯病,图像识别,农药,病虫害,农业机械化,化学防治};
[0063]
d={多孔材料,纳米纤维,阻抗匹配,石墨烯,吸波材料,衰减特性,结构设计,多重反射,有机高分子材料,固化反应};
[0064]
e={大数据,物联网,数据采集,数据关联性分析,机器学习,数据集,系统集成,数据治理,数字孪生,智能制造}。
[0065]
该步骤中,主题关键词和论文关键词有可能会有重复的情况,且最终筛选出的若干学术关键词可能为主题关键词,也可能为论文关键词。
[0066]
步骤五,分别以步骤四筛选出的作者的学术关键词和步骤三筛选出的合著论文的主题关键词为基础,构建论文关键词词向量和合著论文的主题关键词词向量,构建研究领域相似度评价分析模型,利用余弦相似度法计算合著论文主题关键词词向量和作者学术关键词词向量之间的语义相似度,得到的相似度计算结果cos(p,q),具体见式(1),进而可得
出作者的学术研究领域和合著论文主题的研究领域之间的关联性。cos(p,q)的值越大,表明作者的学术研究领域与合著论文主题的研究领域相似度越高,说明该作者对合著论文的学术参与度越高,即该作者对合著论文的学术贡献度越大。
[0067][0068]
式中,p=[p1,p2,
…
,pn]表示合著论文主题关键词词向量,q=[q1,q2,
…
,qn]表示作者学术关键词词向量。
[0069]
根据本实施例中各作者的学术关键词集合,采用公式(1)得到n位作者的贡献权重分别为:ωa=0.732,ωb=0.126,ωc=0.622,ωd=0.186,ωe=0.536。
[0070]
步骤六,基于合著论文中作者的署名顺序,以及步骤五中计算得到的作者的学术研究领域和合著论文主题的研究领域之间的关联性,作为评价作者对待分析合著论文贡献的基于学术背景的贡献权重ωi,通过结合论文作者学术关联信息对论文合著者实际学术贡献度进行计算和评估。具体的:
[0071]
1)针对一篇共有n位作者的合著论文,基于作者署名顺序的学术贡献权重算法可得到道第i位作者的署名顺序权重ki,ki为归一化处理后的数值,具体包括如下三种情况:
[0072]
①
若作者为第一作者和通讯作者外的作者,则第i位作者的署名顺序权重ki为:
[0073][0074]
式中,ki表示依据第i位作者在待分析合著论文中的署名顺序确定的署名顺序权重,i≥2。例如,当作者位于整个署名顺序的第2位时,i=2,当作者位于整个署名顺序的第5位时,i=5。
[0075]
②
若作者为第一作者,则第1位作者的署名顺序权重k1为:
[0076][0077]
式中,α表示第一作者的附加权重,0<α<1。从上式可以看出,单独给第一作者附加了一个权重α,这么做是考虑到第一作者对该合著论文的贡献更大一些。
[0078]
③
若作者为通讯作者,通讯作者在整个署名顺序中的位置不定,可能是第2位,也可能是最后1位,则通讯作者的署名顺序权重ki为:
[0079][0080]
式中,β表示第一作者的附加权重,0<β<1。同样的,给通讯作者一个附加权重β同样是考虑到第一作者对该合著论文的贡献更大一些。
[0081]
附加的权重α和β根据算法模型在测试数据集的计算,结合作者在待分析合著论文
中的署名顺序一次次迭代获得,即在迭代过程中不断调整α和β的取值以得到较为合适的值。这么处理是考虑到有时通讯作者是在整个署名顺序的最末位,仅依据署名顺序得到的署名顺序权重会较小,低于第三作者、第四作者等排名较靠后的作者的署名顺序权重,但这并不合理,所以会附加一个权重以使通讯作者最终的署名顺序权重较高一些,但该值又必须保证附加该权重后的ki不能大于1,所以需合理设置改值。最终得到的α和β的取值可能相同,也可能不同,一般为α>β,根据算法迭代计算一般取α=0.535,β=0.465。当然,如果某一个作者既是通讯作者又是第一作者,则可对该作者附加的权重可以选择α和β中的较大值,或者附加一个比α大的值,均根据实际情况赋值即可。但该种处理方式的主题思想在于考虑到第一作者和通讯作者对合著论文的贡献更大,对其附加一个权重,例如设置为α=0.615,β=0.385。
[0082]
本实施例中,设置α=0.535,β=0.465,并代入到公式(3)和(4)中,可以得到作者署名顺序权重分别为:ka=0.973,kb=0.219,kc=0.146,kd=0.110,ke=0.553。
[0083]
2)将计算的待分析合著论文的若干主题关键词和作者的若干学术关键词之间的语义相似度,作为评价作者对待分析合著论文贡献的基于学术背景的贡献权重ωi,ωi同样为归一化处理后的数值,n位作者的贡献权重为w={ωa,ωb,ωc,ωd,ωe}。
[0084]
3)基于作者的署名顺序权重和贡献权重,计算得到第i位作者的学术贡献度:
[0085]
λi=ki*ωi[0086]
结合上述数据,本实施例得到的各合著论文作者的学术贡献度分别为:λa=0.712,λb=0.028,λc=0.091,λd=0.020,λe=0.296。
[0087]
4)依据λi对每位作者对该合著论文的贡献情况进行评价。
[0088]
综上,本发明方法综合考虑作者研究领域、作者学术关键词等学术背景对合著论文参与程度的影响,弥补了现有技术对论文合著者实际学术贡献评估不准确的不足之处。通过对参与作者学术背景的提取和分析,结合合著论文作者数量和署名顺序以学术关联信息综合赋权的方式对论文合著者实际学术贡献度进行计算和评估,提高了烟草领域论文合著者实际学术贡献度计算和分配的全面性和精准度,而且,还可以用来评估烟草科研工作者真正的学术能力,进而为烟草科研人员公正客观的科研绩效评定以及烟草领域学者专家库的构建服务。
[0089]
本实施例针对是合著论文是烟草领域的论文/文献,相应的,论文合著者的已发表论文大多也还是烟草领域的论文/文献。当然,论文合著者的所有已发表论文/文献不一定全部都是烟草领域的论文/文献,因某些技术存在技术交叉的情况,可能该论文合著者已发表论文/文献会有一些其他领域的论文/文献,均按照本实施例所介绍的方法处理即可。当然,合著论文也可为其他领域的论文/文献。
[0090]
为了评价论文合著者学术贡献度需要用到两个参数,分别为利用论文合著者的署名顺序所确定的署名顺序权重ki和利用待分析合著论文主题的研究领域和论文合著者的学术研究领域之间的关联性所在确定的贡献权重ωi。这两个参数与论文合著者对待分析合著论文的贡献度λi的关系为:ki越大,ωi越大,λi越大,ωi越大。为了展现该关系,本实施例中将ki和ωi的乘积作为论文合著者对待分析合著论文的贡献度λi,即λi=ki*ωi。作为其他实施方式,可直接将ki和ωi的和作为论文合著者对待分析合著论文的贡献度λi,或者ki和ωi的加权求和结果作为论文合著者对待分析合著论文的贡献度λi,均是可以的,两个参
数权重的分配可根据实际情况考虑,例如可设置ωi>ki。当然还可以设置其他方式,但是需体现的是ki越大,ωi越大,λi越大,ωi越大。
[0091]
而且,本实施例中考虑到第一作者和通讯作者在合著论文过程中承担了更多的工作,相应的给第一作者和通讯作者附加了一个权重。作为其他实施方式,可不给第一作者和通讯作者附加权重,所有作者均按照式(1)计算署名顺序权重ki即可。
[0092]
本实施例中使用了较多的机器学习模型,包括步骤三中的支持向量机模型,步骤四中的lda主题模型与word2vec词向量模型等,这些均是需要训练的,由于具体的训练过程和方式为现有技术,因而本实施例中没有详细展开介绍。当然,为了达到相应的目的,并不局限于使用这些模型,可使用现有技术中的其他可达到相应目的的模型。例如支持向量机模型的作用在于聚类,为了达到聚类的目的,可使用现有技术中的其他聚类模型来达到该目的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1