基于数据增量的卷积神经网络前视声呐图像识别技术
1.本发明涉及前视声呐图像识别技术领域,具体是指基于数据增量的卷积神经网络前视声呐图像识别技术。
背景技术:
2.声呐是利用声波作为信息载体的探测设备,按工作方式可分为主动声呐、被动声呐。前视声呐也可称为扇扫声呐,属于主动声呐的一种,声呐图像不仅能够提供目标的大小、方位信息,还能够在大角度范围内同时进行探测,直观地展现水下环境,从而为分类和识别提供了更加稳定、可靠的依据。
3.早期的水下目标识别主要是依赖于回波信号进行识别,根据回波信号进行分类识别的方法主要有时域波形结构特征提取、信号谱估计、时间-频率分析特征提取等。二十世纪90年代以来,水下无人航行器得到快速发展,为了让机器实现高效快速地自动识别目标,科研人员通过结合先验知识,提取声呐图像目标的特征,再结合支持向量机(svm)、决策树、人工神经网络等统计机器学习方法进行识别。
4.本世纪初,由于深度学习方法的快速发展,新的训练方法突破了传统bp神经网络易陷入局部最优的缺点,使得深度学习方法得到了研究人员的关注。其中,基于卷积神经网络的深度学习方法被广泛应用至计算机视觉的各个领域中。卷积神经网络是一种深度人工神经网络,其使用原始的图像数据进行训练,从而避免了信息的丢失。此外,卷积神经网络能够自动提取庞杂的原始数据的特征,解决了传统法方法对于人工经验的依赖,于是将卷积神经网络引入到声呐图像的处理中并实现水下目标识别和检测成为一种研究趋势。本技术方案采用卷积神经网络对水下运动目标前视声呐图像进行识别分类。
5.现有前视声呐成像技术存在以下技术问题:
6.1、在探测水下运动目标时,由于回波信号受到混响、环境噪声和浮游生物的干扰以及声波的透射和衰减会造成声呐图像具有对比度差、分辨率低、阴影暗区像素少、目标边缘残缺等特点。此外,在波束形成时,除在较窄的主波束上形成极大值外,其旁瓣一般还在较宽的指向性范围内接收信号,形成旁瓣干扰;当目标运动时,由于声波入射角、目标表面反射、散射等因素影响,可能会造成同一目标具有截然不同的声图像。并且声呐图像的采集需要耗费大量的资源,很多声呐图像都涉及到了保密问题,因此目前在声呐这个领域公开的数据集十分有限,这就导致深度学习在声呐图像检测分类的应用受到了极大限制。
7.2、在使用传统机器学习方法对目标声呐图像检测时,通常分为定位和识别两个步骤,首先使用人工设计的特征提取器将感兴趣的目标区域从复杂的声呐图像中分离出来,然后对于分离出来的区域,提取相关特征来训练分类器从而做出识别决策并进行识别,这样复杂的检测过程不但消耗时间人力,而且非常依靠人工经验,一旦检测的目标发生变化,就需要重新设计特征和相关算法,可移植性差,不利于提高目标声呐图像检测和识别的效率,由于使用svm对目标识别是分成定位和分类两步解决的,这样的解决方式需要大量人工成本的同时也缺乏泛化能力,传统机器学习方法的固有缺陷限制了它在水下目标识别领域
的进一步发展。
8.3、bp神经网络存在收敛速度慢、所得的网络容错能力差、网络隐含层层数及隐含层单元数的选取尚无理论上的知道,而是根据经验确定,因此,网络往往有很大的冗余性,无形中增加了网络学习的时间;在对声呐图像进行识别训练时,bp神经网络作为传统训练多层网络的典型算法,网络稍微一深,训练结果就会很不理想,主要问题有梯度越来越稀疏:从顶层越往下,误差校正信号越小;容易收敛到局部最小值,深度结构非凸目标代价函数中普遍存在的局部最小会导致利用bp神经网络训练非常困难。
9.所以,基于数据增量的卷积神经网络前视声呐图像识别技术成为人们亟待解决的问题。
技术实现要素:
10.本发明要解决的技术问题是在探测水下运动目标时,由于回波信号受到混响、环境噪声和浮游生物的干扰以及声波的透射和衰减会造成声呐图像具有对比度差、分辨率低、阴影暗区像素少、目标边缘残缺等特点。
11.为解决上述技术问题,本发明提供的技术方案为:基于数据增量的卷积神经网络前视声呐图像识别技术,包括五种不同的水下运动目标,所述五种不同的水下运动目标分别为单柱目标、双柱目标、三柱目标、四柱目标和t型目标,所述卷积神经网络前视声呐图像识别技术如下所示:
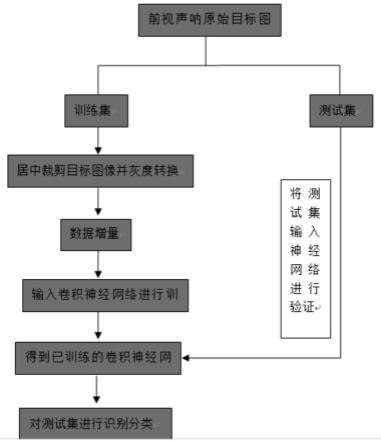
12.步骤1、从前视声呐原始目标图像中抽取训练集和测试集:通过对实验采集到的五类水下运动目标的前视声纳图像视频进行帧截取获得五类目标图像,抽取部分图像为训练集,再从声呐图像视频中挑选与训练集不重复的图像作为后续神经网络的测试集;
13.步骤2、居中裁剪目标图像并灰度旋转:对原始声呐图像进行居中裁剪并进行灰度转换,滤除掉声呐图像中除了目标以外的其他杂乱信息得到裁剪后的目标灰度图像;
14.步骤3、数据增量:在经过上述对图像的操作步骤之后,基于卷积神经网络对扭曲图像的处理具有识别不变的优良特性,再对目标图像进行间隔10度的顺时针旋转,一共经过360度,每旋转一次角度,就对目标图像进行左右镜像对称、平移、高斯加噪并中值滤波、维纳滤波、桶形变换和针垫变换,得到原始目标的增量图像,每类目标由原始的48张图片增量到15552张,五类目标总计增量到77760张图像;
15.步骤4、输入卷积神经网络进行训练:在将声呐图像数据经过增量处理以后,将其存入到一个新的样本训练集,然后将增量样本集经过一个16层卷积神经网络进行训练,并使用训练集中的35%的卷积神经网络模型进行识别验证;
16.步骤5、得到已训练的卷积神经网络:得到训练集经过网络的识别,利用训练集中所划分的测试集对神经网络识别的正确率为99.89%;
17.步骤6、对测试集进行识别分类:对未经训练的测试集的总体识别进行分类,经过计算,对未经训练测试集的识别正确率为99.6129%,再从未经训练的测试集中随机抽取6张图片经网络识别后得到分类结果。
18.进一步的,所述一个16层卷积神经网络的每层结构如下所示:输入层
‑‑
卷积层(3,8)
‑‑
批处理层
‑‑
激活函数
‑‑
池化层(2,2)
‑‑
卷积层(3,16)
‑‑
批处理层—激活函数—池化层(2,2)
‑‑
卷积层(3,32)
‑‑
批处理层—激活函数—池化层(2,2)
‑‑
全连接层—归一化层—分
类层。
19.进一步的,步骤1所述的前视声呐原始目标图像数据是通过在水声实验站对五种不同的水下运动目标利用多波束前视声呐进行实验获取得到声呐图像,该实验将待测目标悬挂在转台下方,目标旋转360度,并且将图像声呐吊放在目标同一深度,在目标旋转过程中,记录目标全方位的声呐图像。
20.本发明与现有技术相比的优点在于:本发明不需要繁琐的特征工程,可以极大的减少人工成本并且泛化能力更强,训练速度更快;本发明用到的深层卷积神经网络的结构层次比bp神经网络复杂,其中包含大量的隐藏层。但是,网络结构内部相邻的卷积核或者下采样核采用局部感受野全链接,网络采取神经元权值共享的规则,使得卷积神经网络训练参数的数量远比传统神经网络少,在训练和前向测试的复杂度大幅度降低,同时也减少了神经网络训练参数过拟合的几率;本发明通过实验采集得到五种水下运动目标的前视声呐图像集,再扩大预训练数据集,训练一个尽可能覆盖到声呐图像特征的预训练网络来对目标进行识别并且提升网络的鲁棒性;本发明操作简便,设计合理,值得大力推广。
附图说明
21.图1是本发明基于数据增量的卷积神经网络前视声呐图像识别技术的流程图。
22.图2是卷积神经网络结构流程图。
23.图3是单柱目标的前视声呐原始图像。
24.图4是双柱目标的前视声呐原始图像。
25.图5是三柱目标的前视声呐原始图像。
26.图6是四柱目标的前视声呐原始图像。
27.图7是t型目标的前视声呐原始图像。
28.图8是四柱目标灰度图像增量处理过程中顺时针旋转10度的图像。
29.图9是四柱目标灰度图像增量处理过程中高斯加噪并中值滤波的图像。
30.图10是四柱目标灰度图像增量处理过程中左右镜像的图像。
31.图11是四柱目标灰度图像增量处理过程中平移处理的图像。
32.图12是四柱目标灰度图像增量处理过程中桶形变换的图像。
33.图13是四柱目标灰度图像增量处理过程中针垫变换的图像。
34.图14是卷积神经网络训练过程。
35.图15是训练集样本经过卷积神经网络验证混肴矩阵。
36.图16是未经训练的测试集对卷积神经网络进行识别验证结果。
37.图17是随机抽取测试集对神经网络进行验证。
具体实施方式
38.下面结合附图对本发明基于数据增量的卷积神经网络前视声呐图像识别技术做进一步的详细说明。
39.结合附图1-17,对本发明进行详细介绍。
40.基于数据增量的卷积神经网络前视声呐图像识别技术,包括五种不同的水下运动目标,所述五种不同的水下运动目标分别为单柱目标、双柱目标、三柱目标、四柱目标和t型
目标,所述卷积神经网络前视声呐图像识别技术如下所示:
41.步骤1、从前视声呐原始目标图像中抽取训练集和测试集:通过对实验采集到的五类水下运动目标的前视声纳图像视频进行帧截取获得五类目标图像,抽取部分图像为训练集,再从声呐图像视频中挑选与训练集不重复的图像作为后续神经网络的测试集;
42.步骤2、居中裁剪目标图像并灰度旋转:对原始声呐图像进行居中裁剪并进行灰度转换,滤除掉声呐图像中除了目标以外的其他杂乱信息得到裁剪后的目标灰度图像;
43.步骤3、数据增量:在经过上述对图像的操作步骤之后,基于卷积神经网络对扭曲图像的处理具有识别不变的优良特性,再对目标图像进行间隔10度的顺时针旋转,一共经过360度,每旋转一次角度,就对目标图像进行左右镜像对称、平移、高斯加噪并中值滤波、维纳滤波、桶形变换和针垫变换,得到原始目标的增量图像,每类目标由原始的48张图片增量到15552张,五类目标总计增量到77760张图像;
44.步骤4、输入卷积神经网络进行训练:在将声呐图像数据经过增量处理以后,将其存入到一个新的样本训练集,然后将增量样本集经过一个16层卷积神经网络进行训练,并使用训练集中的35%的卷积神经网络模型进行识别验证;
45.步骤5、得到已训练的卷积神经网络:得到训练集经过网络的识别,利用训练集中所划分的测试集对神经网络识别的正确率为99.89%;
46.步骤6、对测试集进行识别分类:对未经训练的测试集的总体识别进行分类,经过计算,对未经训练测试集的识别正确率为99.6129%,再从未经训练的测试集中随机抽取6张图片经网络识别后得到分类结果。
47.所述一个16层卷积神经网络的每层结构如下所示:输入层
‑‑
卷积层(3,8)
‑‑
批处理层
‑‑
激活函数
‑‑
池化层(2,2)
‑‑
卷积层(3,16)
‑‑
批处理层—激活函数—池化层(2,2)
‑‑
卷积层(3,32)
‑‑
批处理层—激活函数—池化层(2,2)
‑‑
全连接层—归一化层—分类层。
48.步骤1所述的前视声呐原始目标图像数据是通过在水声实验站对五种不同的水下运动目标利用多波束前视声呐进行实验获取得到声呐图像,该实验将待测目标悬挂在转台下方,目标旋转360度,并且将图像声呐吊放在目标同一深度,在目标旋转过程中,记录目标全方位的声呐图像。
49.本发明基于数据增量的卷积神经网络前视声呐图像识别技术的具体实施过程如下:步骤1、从前视声呐原始目标图像中抽取训练集和测试集:通过对实验采集到的五类水下运动目标的前视声纳图像视频进行帧截取获得五类目标图像,抽取部分图像为训练集,再从声呐图像视频中挑选与训练集不重复的图像作为后续神经网络的测试集;
50.步骤2、居中裁剪目标图像并灰度旋转:对原始声呐图像进行居中裁剪并进行灰度转换,滤除掉声呐图像中除了目标以外的其他杂乱信息得到裁剪后的目标灰度图像;
51.步骤3、数据增量:在经过上述对图像的操作步骤之后,基于卷积神经网络对扭曲图像的处理具有识别不变的优良特性,再对目标图像进行间隔10度的顺时针旋转,一共经过360度,每旋转一次角度,就对目标图像进行左右镜像对称、平移、高斯加噪并中值滤波、维纳滤波、桶形变换和针垫变换,得到原始目标的增量图像,每类目标由原始的48张图片增量到15552张,五类目标总计增量到77760张图像;
52.步骤4、输入卷积神经网络进行训练:在将声呐图像数据经过增量处理以后,将其存入到一个新的样本训练集,然后将增量样本集经过一个16层卷积神经网络进行训练,并
使用训练集中的35%的卷积神经网络模型进行识别验证;
53.步骤5、得到已训练的卷积神经网络:得到训练集经过网络的识别,利用训练集中所划分的测试集对神经网络识别的正确率为99.89%;
54.步骤6、对测试集进行识别分类:对未经训练的测试集的总体识别进行分类,经过计算,对未经训练测试集的识别正确率为99.6129%,再从未经训练的测试集中随机抽取6张图片经网络识别后得到分类结果。
55.本发明不需要繁琐的特征工程,可以极大的减少人工成本并且泛化能力更强,训练速度更快;本发明用到的深层卷积神经网络的结构层次比bp神经网络复杂,其中包含大量的隐藏层,相邻的卷积核或者下采样核采用局部感受野全链接,网络采取神经元权值共享的规则,使得卷积神经网络训练参数的数量远比传统神经网络少,在训练和前向测试的复杂度大幅度降低,同时也减少了神经网络训练参数过拟合的几率;本发明通过实验采集得到五种水下运动目标的前视声呐图像集,再扩大预训练数据集,训练一个尽可能覆盖到声呐图像特征的预训练网络来对目标进行识别并且提升网络的鲁棒性;本发明操作简便,设计合理,值得大力推广。
56.以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1