一种基于人工智能算法的高精度充填管路故障预警方法与流程
1.本发明涉及矿山充填技术领域,具体涉及一种基于人工智能算法的高精度充填管路故障预警方法。
背景技术:
2.充填采矿法是保证深部开采安全最有效的方法之一,也是矿山尾砂充分利用的最好途径,随着矿山开采深度的增加,充填料浆输送管路逐渐延长、空间布置结构更加复杂,充填料浆输送管路故障点增多,故障频发。目前主要依靠人工巡视管路的方式保障充填管路的安全性,虽然已有相关的充填管路故障自动化监测方法,但是目前的监测方法达不到提前预警的效果,只能在管路发生“堵管”或者“泄露”后进行判断提醒,由于管理人员难以了解充填管路压力变化情况,不能及时做出控制决策,从而无法有效避免充填管路故障的发生。
技术实现要素:
3.本发明提出了一种基于人工智能算法的高精度充填管路故障预警方法,其目的是:通过建立压力预测模型判断充填管路工作状态,实现对管路异常及故障状态进行提前预警。
4.本发明技术方案如下:
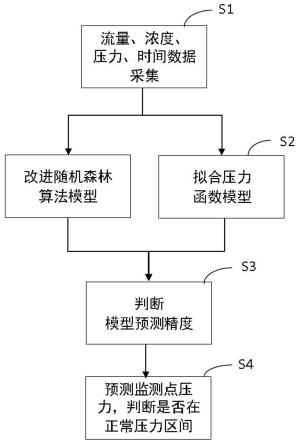
5.一种基于人工智能算法的高精度充填管路故障预警方法,包括如下步骤:
6.s1:采集地表充填站浓度、流量数据,获取井下管路关键监测点压力、时间数据;
7.s2:建立改进随机森林算法模型和拟合压力函数模型;
8.s3:判断改进随机森林算法模型和拟合压力函数模型的预测精度,若预测精度达标则执行步骤s4,否则返回步骤s1;
9.s4:构建压力预测模型,预测关键监测点压力并进行管路故障预警。
10.进一步地,步骤s2所述建立改进随机森林算法模型的方法包括:
11.s21:对步骤s1获取的浓度、流量、监测点压力、时间数据进行归一化处理,得到原始数据集;
12.s22:通过改进的smote算法和混合采样相结合的方式对原始数据集进行预处理,得到平衡数据集;
13.s23:通过relieff算法对平衡数据集进行特征加权和维度约简,筛选出有效的维度较低的子集训练决策树,采用加权投票方法得到优化数据集;
14.s24:将优化数据集划分为训练集和测试集,建立改进随机森林算法模型,使用平方误差作为模型预测精度标准,利用对比散度训练算法确定模型参数,利用训练集归一化得到的均值mean_train和方差std_train对测试集归一化,使用测试集检验模型预测精度,若模型预测压力值与实际测量压力值之间误差达到预测精度要求,则判定当前模型作为所述改进随机森林算法模型。
15.进一步地,所述步骤s22具体包括:
16.s22-1:使用聚类算法对少数类进行聚类操作,确定少数类中各簇的分布状态,然后计算簇心,在簇心与簇内样本连线上根据下式插值增加样本数据:
17.x
new
=ci+rand(0,1)*(x-ci)i=1,2...n
18.其中,x
new
为新插样本,ci为簇心,x为以ci为簇心聚类中的原始样本;
19.s22-2:依次计算多数类样本与少数类样本的采样数量:
20.p
mix
=q-l
21.pm=p
mix
·
t
22.pn=p
mix
·
(1-t)
23.其中,q为多数类样本数,l为少数类样本数,p
mix
为混合采样数量,pm为欠采样数量,pn为过采样数量,t为混合比例系数;
24.s22-3:对多数类样本采取欠采样、少数类样本采取过采样的方式进行处理,分别得到全新数据集,合并所述全新数据集,得到平衡数据集d
new
。
25.进一步地,所述步骤s23具体包括:
26.s23-1:将平衡数据集d
new
中各样本的特征权值设为0;
27.s23-2:从平衡数据集样本中随机选取样本r,在样本r的同类样本集中选择样本r的k个同类最近邻样本,分别在每个样本r的不同类样本集中选择k个不同类最近邻样本,计算得出样本中每个类对应的特征权值;
28.s23-3:将步骤s23-2重复m次,得到每个类的m个特征权值,计算每个类的特征权值平均值作为每个类的权重值w,将各个类按权重值w降序排列,按照权重值大小将特征均匀分至高、中、低3个区域中,进行聚类约简,通过获取的3个特征区域筛选出维度较低的子集训练决策树;
29.s23-4:随机抽样平衡数据集d
new
得到样本子集,未被抽取的数据集记为ot数据集,通过ot数据集得到每棵决策树对ot数据的正确分类的比率,计算各棵决策树的权重值,计算公式如下:
[0030][0031]
其中fj为分类比率;
[0032]
选出权重最高的决策树作为最终分类结果,生成优化数据集。
[0033]
进一步地,步骤s2所述建立拟合压力函数模型的方法为:采用数据拟合方式建立监测点压力、浓度、流量函数关系:p=f(q,cv),拟合多种结构的函数关系,对比多种函数关系的标准误差和拟合优度,按照标准误差小、拟合优度大的原则选定拟合压力函数;选定拟合压力函数后,对于不同的监测点分别进行数据拟合。
[0034]
进一步地,步骤s3所述判断改进随机森林算法模型和拟合压力函数模型的预测精度的方法为:对改进随机森林算法模型的压力预测值和拟合压力函数模型的压力预测值进行均方误差计算,如果计算值在设定范围内,则判定预测精度达标。
[0035]
进一步地,步骤s4所述压力预测模型为:所述改进随机森林算法模型的压力预测值和拟合压力函数模型的压力预测值分别占一定的权重,得到最终的监测点压力预测值。
[0036]
进一步地,所述步骤s1还包括对采集数据进行预处理,以地表料浆到达压力监测
点的时间差为基准进行数据融合处理,剔除系统异常及停车数据。
[0037]
进一步地,步骤s1所述获取井下管路关键监测点压力、时间数据的方法为:确定垂直段管路下口料浆势能产生的压力值,减去环管试验得到的料浆沿程压力损失值,求得管路任一点的料浆压力值;将压力最大值和压力最小值对应位置作为井下充填管路关键点位置,在所述关键点位置安装压力变送器测量压力数据,使用无纸记录仪记录压力、时间数据。
[0038]
相对于现有技术,本发明具有以下有益效果:
[0039]
(1)本方法充分利用矿山充填的浓度、流量、压力数据建立充填管路关键监测点处的改进随机森林算法压力预测模型和拟合压力函数关系模型,利用两个压力计算模型综合预测料浆到达压力监测点时的压力值并进行故障预警,压力预测准确率高,实施性强,本方法可直接应用于现有自动化充填系统中,无需新增复杂管路状态监测设备;
[0040]
(2)本方法采用改进的smote算法和混合采样法改进随机森林算法模型参数,对原始高维不平衡数据集进行预处理,提高了数据集的均衡度,通过relieff算法和加权投票原则进一步提高了改进随机森林算法模型的分类性能,保证了改进随机森林算法模型的拟合优度,提高了压力预测的准确率;
[0041]
(3)本方法采用数据拟合方式建立多种结构的函数关系,筛选出标准误差小、拟合优度大的函数关系作为拟合压力函数,对不同的监测点分别进行数据拟合,进一步提高了压力预测的准确率。
附图说明
[0042]
图1为本发明的流程图;
[0043]
图2为改进随机森林算法压力预测模型的误差图;
[0044]
图3为拟合压力函数模型示意图。
具体实施方式
[0045]
下面结合附图详细说明本发明的技术方案:
[0046]
如图1,一种基于人工智能算法的高精度充填管路故障预警方法,包括如下步骤:
[0047]
s1:采集地表充填站浓度、流量数据,获取井下管路关键监测点压力、时间数据。
[0048]
优选地,充填站进行充填作业时,针对不同充填上位机软件采用不同的数据采集软件读取充填自动化服务器浓度、流量数据、充填时间数据,如:充填自动化系统上位机采用wincc软件,可采用西门子wincc ole db provider软件进行数据提取。
[0049]
所述获取井下管路关键监测点压力、时间数据的方法为:首先根据能量守恒原理通过初步计算得出充填管路压力分布,具体地,确定垂直段管路下口料浆势能产生的压力值,减去环管试验得到的料浆沿程压力损失值,可求得管路任一点的料浆压力值,将压力最大值和压力最小值对应位置作为井下充填管路关键点位置,然后在所述关键点位置安装压力变送器测量压力数据,使用无纸记录仪记录压力、时间数据。
[0050]
进一步地,对采集数据进行预处理,以地表料浆到达压力监测点的时间差为基准进行数据融合处理,剔除系统异常及停车数据。
[0051]
s2:建立改进随机森林算法模型和拟合压力函数模型。
[0052]
优选地,所述建立改进随机森林算法模型的方法包括如下步骤:
[0053]
s21:对步骤s1获取的浓度、流量、监测点压力、时间数据进行归一化处理,得到原始数据集。归一化公式如下:
[0054][0055]
其中,x为特征值,x
mean
为特征值对应的均值,s为特征值对应的方差。
[0056]
s22:通过改进的smote算法和混合采样相结合的方式对原始数据集进行预处理,得到平衡数据集,保证模型拟合优度在0.97以上。
[0057]
具体包括如下步骤:
[0058]
s22-1:使用聚类算法对少数类进行聚类操作,确定少数类中各簇的分布状态,然后计算簇心,在簇心与簇内样本连线上根据下式插值增加样本数据:
[0059]
x
new
=ci+rand(0,1)*(x-ci)i=1,2...n
[0060]
其中,x
new
为新插样本,ci为簇心,x为以ci为簇心聚类中的原始样本。
[0061]
s22-2:依次计算多数类样本与少数类样本的采样数量:
[0062]
p
mix
=q-l
[0063]
pm=p
mix
·
t
[0064]
pn=p
mix
·
(1-t)
[0065]
其中,q为多数类样本数,l为少数类样本数,p
mix
为混合采样数量,pm为欠采样数量,pn为过采样数量,t为混合比例系数。
[0066]
s22-3:对多数类样本采取欠采样、少数类样本采取过采样的方式进行处理,分别得到全新数据集,合并所述全新数据集,得到平衡数据集d
new
。
[0067]
s23:通过relieff算法对平衡数据集进行特征加权和维度约简,筛选出有效的维度较低的子集训练决策树,采用加权投票方法得到优化数据集。
[0068]
具体包括如下步骤:
[0069]
s23-1:将平衡数据集d
new
中各样本的特征权值设为0;
[0070]
s23-2:从平衡数据集样本中随机选取样本r,在样本r的同类样本集中选择样本r的k个同类最近邻样本,分别在每个样本r的不同类样本集中选择k个不同类最近邻样本,计算得出样本中每个类对应的特征权值;
[0071]
s23-3:将步骤s23-2重复m次,得到每个类的m个特征权值,计算每个类的特征权值平均值作为每个类的权重值w,将各个类按权重值w降序排列,按照权重值大小将特征均匀分到高、中、低3个区域中,进行聚类约简,通过获取的3个特征区域筛选出维度较低的子集训练决策树;
[0072]
s23-4:随机抽样平衡数据集d
new
得到样本子集,未被抽取的数据集记为ot数据集,每个样本未被抽到的概率约为0.368。通过ot数据集得到每棵决策树对ot数据的正确分类的比率,计算各棵决策树的权重值,计算公式如下:
[0073][0074]
其中fj为分类比率,k表示正整数;
[0075]
选出权重最高的决策树作为最终分类结果,生成优化数据集。
[0076]
s24:将得到的优化数据集划分为训练集和测试集(训练集占优化数据集的70%,测试集占优化数据集的30%)两部分,建立改进随机森林算法模型,使用平方误差作为模型预测精度标准,利用对比散度训练算法确定模型参数,利用训练集归一化得到的均值mean_train和方差std_train对测试集归一化,测试集归一化公式如下:
[0077][0078]
其中,x_test为测试集数据。
[0079]
使用测试集检验模型预测精度,如图2,若模型预测压力值与实际测量压力值之间误差达到预测精度要求(0.97),则判定当前模型作为所述改进随机森林算法模型。
[0080]
所述建立拟合压力函数模型的方法为:采用数据拟合方式建立监测点压力、浓度、流量函数关系:p=f(q,cv),拟合多种结构的函数关系,如下:
[0081][0082]
p2=a+bx1+clnx2[0083]
p3=a+bx1+cx2[0084]
p4=a+blnx1+clnx2[0085]
如表1所示,对比多种函数关系的标准误差和拟合优度,按照标准误差小、拟合优度大的原则选定拟合压力函数,保证标准误差在0.006以内。函数p1标准误最小为0.0051且拟合优度最大,选定p1作为拟合压力函数,如表2及图3所示。
[0086]
表1四种拟合函数评价指标
[0087]
rankmodelstderrorresidual sumresidual avg.rssr^2ra^21p10.005144.56302e-147.60503e-160.0014790.942850.939782p20.00524-2.9865e-14-4.9775e-160.0015510.940070.937963p30.00522-1.3223e-13-2.20379e-150.0015530.940020.937924p40.00522-4.6685e-13-7.78081e-150.0015550.939940.93783
[0088]
表2函数p1置信区间
[0089][0090]
选定拟合压力函数后,对于不同的关键监测点分别进行数据拟合:
[0091]
[0092]
其中,pt
a1
为管路压力最小值对应监测点处压力预测值,a=108.53,b=-3.094,c=2.188,d=7.822,x1为充填站内浓度数据,x2为搅拌桶出口流量数据。
[0093][0094]
其中,pt
b1
为管路压力最大值对应监测点处压力预测值,a'=109.41,b'=-2.04,c'=2.142,d'=8.236,x1为充填站内浓度数据,x2为搅拌桶出口流量数据。
[0095]
s3:判断改进随机森林算法模型和拟合压力函数模型的预测精度,若预测精度达标则执行步骤s4,否则返回步骤s1,重新采集数据建立模型。
[0096]
优选地,所述判断改进随机森林算法模型和拟合压力函数模型的预测精度的方法为:以改进随机森林算法模型的压力预测值为基础,对改进随机森林算法模型的压力预测值和拟合压力函数模型的压力预测值进行均方误差计算,如果计算值在设定范围内(如5%),则判定预测精度达标。计算公式如下:
[0097][0098]
其中,fa(p)为改进随机森林算法模型的压力预测值,f
a1
(p)为拟合压力函数模型的压力预测值。
[0099]
s4:构建压力预测模型,预测关键监测点压力并进行管路故障预警。
[0100]
优选地,所述压力预测模型为:所述改进随机森林算法模型的压力预测值和拟合压力函数模型的压力预测值分别占一定的权重,作为料浆到达压力监测点时的压力预测值,即得到最终的监测点压力预测值。例如,将两个模型的压力预测值的均值作为最终的压力预测值,若最终的压力预测值不在设定正常压力范围之内则进行故障预警,提前为后续充填管路压力控制调节预警。
[0101]
本方法以智能算法综合数据拟合为基础,通过大量工业数据形成高精度充填管路故障预警方法,能动态决策判断管路压力状态,实现了充填料浆输送过程中提前预测管路压力状态,提前为后续料浆输送控制提供参考。
[0102]
显然,本发明的上述实施例仅仅是为了清楚说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1