一种基于混合采样的滑坡易发性评价建模样本挑选方法
1.本发明涉及滑坡易发性评价领域,尤其涉及一种基于混合采样的滑坡易发性评价建模样本挑选方法。
背景技术:
2.随着计算机性能的提升,数据处理和预测也进入了高速发展阶段,其中以地理信息科学(gis)为基础,结合机器学习模型的方法在滑坡易发性评价领域中被广泛应用,如支持向量机模型、梯度提升树模型、随机森林模型等。机器学习模型相较于传统的数理统计模型,其结果具有更强的量化能力。尽管目前有大量的研究证明机器学习和深度学习能够尽可能的适应不同采样策略下的样本,但不可否认的是建模学习得到高精度的前提仍然是大量的建模样本支持。
3.根据实际调研结果,不同区域中滑坡与非滑坡样本比例往往是不一致的,其中在大量区域中滑坡样本是远远小于非滑坡样本的,在数据二分类建模分析中,数据样本相差过大时,我们就可默认研究区存在样本不平衡问题,其中样本数量较多的一类被称为多数类,较少的一类被称为少数类。在滑坡易发性评价中,滑坡相比较非滑坡而言是更值得关注和统计的,但在数据不平衡下往往会导致在建立模型时,模型会过多关注多数类样本的特征,忽略少数类样本的信息,导致模型预测结果出现偏差和过拟合情况。
4.目前通用的采样方法来解决样本不平衡问题主要分为随机过采样和随机欠采样。随机过采样是指在少数类样本中随机选择一些样本,然后通过复制所选择的样本进而生成样本数据集,将他们添加到原样本数据中扩大原数据集从而得到新的少数类集合。对于随机过采样,由于需要对少数类样本进行复制来扩大数据集,造成模型训练复杂度加大。另一方面也容易造成模型的过拟合问题,因为随机过采样是简单的对初始样本进行复制采样,这就使得学习器学得的规则过于具体化,不利于学习器的泛化性能,造成过拟合问题。随机欠采样即从多数类样本s中随机选择一些样本组成样本集e。然后将样本集e从s中移除,进而得到新的数据集snew=s-e。随机欠采样方法通过改变多数类样本比例以达到修改样本分布的目的,从而使样本分布较为均衡,但是这也存在一些问题。对于随机欠采样,由于采样的样本集合要少于原来的样本集合,因此会造成一些信息缺失,即将多数类样本删除有可能会导致分类器丢失有关多数类的重要信息。
5.在目前进行滑坡易发性评价时,滑坡数据往往通过野外实际调研得到,是很准确的数据,而由于研究区面积辽阔、存在大量人难以达到地方,因此非滑坡数据往往存在一定不确定性,但研究者往往将高质量的滑坡数据和低质量的非滑坡数据同时进行建模,导致模型出现过多冗余、错误数据,使得模型精度较低。
6.滑坡是我国主要的地质灾害类型,对土地资源可持续利用和经济可持续发展造成了不可估量的破坏。特别是二十一世纪以来,大量人类工程活动,严重影响了地质环境稳定性,加上在地震、火山爆发、强降雨等因素的影响,使得滑坡发生频率与规模逐步增加,造成人员伤亡和经济损失也呈直线上升。据2020年自然资源部发布的全国地质灾害通报,全国
共发生地质灾害7840起,造成直接经济损失50.2亿元,人员伤亡197人。其中共发生滑坡共计4810起,占比超过总地质灾害的60%,较2019年4220起滑坡有不少增长,尤其是在四川、重庆等地,存在众多潜在的滑坡隐患,严重威胁群众生命安全和财产安全。准确开展滑坡易发性评价能够为政府对土地利用合理规划提供有力的技术支持。
技术实现要素:
7.本发明的目的在于克服传统随机过采样和欠采样的不足,将单分类支持向量机(one-class support vector machine,ocsvm)和合成少数类过采样技术(synthetic minority oversampling technique,smote)进行结合构成一种混合采样模型,用来解决滑坡易发性评价中样本不平衡问题,进而提高滑坡评价的预测精度。
8.一种基于混合采样的滑坡易发性评价建模样本挑选方法,包括:
9.s1:加载原始总指标数据集,在数据集中的所有数据与原点间构建超平面;
10.s2:将步骤s1中获取的原始数据输入至ocsvm模型中,进行数据的欠采样处理,得到滑坡数据和非滑坡数据;
11.s3:从相似的滑坡数据中和不相似非滑坡数据中选择部分作为训练数据,并输入至smote模型中,进行训练数据的过采样处理,得到新滑坡数据集;
12.s4:对于新滑坡中每一个样本x,以欧氏距离为标准计算它到新滑坡数据集中所有样本的距离,得到其k近邻;
13.s5:根据样本不平衡比例设置一个采样比例以确定采样倍率n,对于每一个样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn,对于每一个随机选出的近邻xn,结合原样本构建新的样本,即为挑选得到的样本。
14.进一步地,步骤s1中,数据集中的每一个数据都包含多个指标因子构成的自变量x以及对应的因变量y,自变量x包括高程、坡向和坡度,因变量y为是否发生滑坡。
15.进一步地,步骤s2中具体包括以下步骤:
16.s21:在分类正确的基础上,最大化超平面与原点的距离;
17.s22:通过对耦合问题进行处理及加入松弛变量ξ,将最大化超平面与原点的距离的问题转化为求解优化的目标函数;
18.s23:通过导出对偶问题和使用核技巧,采用支持向量对上述优化的目标函数进行求解,得到决策函数;
19.s24:通过决策函数,得出对偶问题,对非滑坡数据中与滑坡数据相似的样本进行剔除,得到更为纯粹的滑坡和非滑坡数据。
20.进一步地,最大化超平面与原点的距离的公式为:
[0021][0022]
subject to(w
·
xi)≥ρ
[0023]
其中,w为斜率,xi为第i个自变量,ρ为常数项,f为正有理数集合,r为实数集。
[0024]
进一步地,优化的目标函数为:
[0025][0026]
subject to(w
·
φ(xi))≥ρ-ξi,ξi≥0
[0027]
其中,w为斜率,xi为第i个自变量,ρ为常数项,f为正有理数集合,r为实数集,ξi为第i个松弛变量。
[0028]
进一步地,所述决策函数为:
[0029][0030]
其中,αi为lagrange乘数,w(xi,x)为核函数,ρ为常数项。
[0031]
进一步地,构建新的样本的公式为:
[0032]
x
nev
=x+rand(0,1)
×
(xn-x)
[0033]
其中,x表示原始样本,x
nev
表示新的样本。
[0034]
本发明提供的技术方案带来的有益效果是:
[0035]
(1)本发明的混合采样算法相比传统欠采样算法,能够充分保留代表性数据,不会丢失重要信息,筛选出的数据有完整特征,并且使得样本更加纯粹化。
[0036]
(2)本发明的混合采样算法相比传统过采样算法,,并不是简单的通过复制数据来增加样本点数量,而是对现有数据特征进行学习之后生成新样本,是充分考虑到现有数据的差异性,且不易产生数据冗余问题。
附图说明
[0037]
下面将结合附图及实施例对本发明作进一步说明,附图中:
[0038]
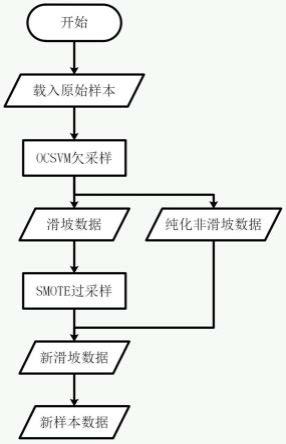
图1是本发明实施例中一种基于混合采样的滑坡易发性评价建模样本挑选方法的流程图。
[0039]
图2是本发明实施例中使用ocsvm-smote抽样和未使用ocsvm-smote抽样的lr易发性评价精度曲线图。
[0040]
图3是本发明实施例中使用ocsvm-smote抽样和未使用ocsvm-smote抽样的rf易发性评价精度曲线图。
[0041]
图4是本发明实施例中使用ocsvm-smote抽样和未使用ocsvm-smote抽样的gbdt易发性评价精度曲线图。
具体实施方式
[0042]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
[0043]
本发明的实施例提供了一种基于混合采样的滑坡易发性评价建模样本挑选方法。
[0044]
请参考图1,图1是本发明实施例中一种基于混合采样的滑坡易发性评价建模样本挑选方法的流程图,具体包括:
[0045]
一种基于混合采样的滑坡易发性评价建模样本挑选方法,首先进行单分类支持向量机模型运算(步骤1-步骤10),在进行合成少数类过采样技术运算(步骤11-步骤12),具体为:
[0046]
步骤1:加载原始总指标数据集,包含滑坡数据和非滑坡数据集,每一个数据皆是包含多个指标因子(高程、坡向、坡度等)构成的自变量x=(x1,x2,
…
,x
10
)以及对应的因变
量y(是否发生滑坡)。数据与原点间构建超平面,现在假设该超平面为:
[0047]w·
φ(x)-ρ=0
[0048]
其中,w为斜率,xi为第i个自变量,ρ为常数项,f为正有理数集合,r为实数集。
[0049]
步骤2:在分类正确的基础上最大化超平面与原点的距离:
[0050][0051]
(w
·
φ(xi))≥ρ
[0052]
其中,xi为第i个自变量。
[0053]
步骤3:同时根据超平面的定义,实际上ρ的正负和w向量中的元素正负同时调整就不会影响超平面,那么假如ρ》0,那么最大化超平面与原点的距离问题可以重写为:
[0054][0055]
步骤4:对步骤2求解的最大化超平面与原点的距离的问题进行处理,将其拆解为:
[0056][0057][0058]
步骤5:在求解问题时,由于w向量中元素的整体正负不会影响‖w‖2的取值,因此只需要保证ρ的最终取值为正值,也就满足了步骤3中的假设。同时为了方便梯度求解,将‖w‖2添加一个1/2,那么最终的优化目标可以写为:
[0059][0060]
(w
·
φ(xi))≥ρ
[0061]
其中,w为斜率,xi为第i个自变量,ρ为常数项,f为正有理数集合,r为实数集,ξi为第i个松弛变量。
[0062]
步骤6:一般情况下,对于一个斜率一定的直线,当其偏移量的绝对值越大时,其离零点越来越远,以w*x-b=0为例,当w确定时,|b|越大,直线离原点越远。因此在函数中加入松弛变量ξ后,其优化的目标函数可以写为:
[0063][0064]
(w
·
φ(xi))≥ρ-ξi,ξi≥0
[0065]
其中v∈(0,1)用于调节松弛程度,根据该目标函数进行优化求解得到w和ρ后,对多部分样本来说,其决策函数f(x)=sgn((w*φ(x))-ρ)输出为正。
[0066]
步骤7:为了求解对偶问题使用核技巧,这里使用lagrange乘数αi,βi,可以写出拉格朗日方程:
[0067][0068]
步骤8:那么根据对参数w,ξ,ρ求偏导,可以写出部分karush-kuhn-tucker(kkt)条件:
[0069]
[0070][0071]
步骤9:通过导出对偶问题和使用核技巧,便可以实现通过支持向量{xi:i∈[l],αi>0}求得决策函数:
[0072][0073]
其中,αi为lagrange乘数,w(xi,x)为核函数,ρ为常数项。
[0074]
步骤10:得出对偶问题,便可以实现将非滑坡数据中与滑坡数据相似的样本进行剔除,实现滑坡和非滑坡样本的纯粹化,也进行了一次样本的欠拟合处理。
[0075]
步骤11:对于滑坡中每一个样本x,以欧氏距离为标准计算它到原始总样本集中所有样本的距离,得到其k近邻。
[0076]
步骤12:根据样本不平衡比例设置一个采样比例以确定采样倍率n,对于每一个少数类滑坡数据样本,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。对于每一个随机选出的近邻xn,分别与原始总样本按照如下的公式构建新的样本。
[0077]
x
nev
=x+rand(0,1)
×
(xn-x)
[0078]
其中,x表示原始样本,x
nev
表示新的样本。
[0079]
使用以上方法可以很好的优化样本选择问题,并且使得筛选后的模型可以有效的运用到不同模型中进行训练,并提高滑坡易发性评价精度。
[0080]
本实施例中,将原始数据输入到单分类支持向量机模型中判断非滑坡数据与滑坡数据的相似性,将相似的非滑坡数据标记为1,不相似非滑坡数据标记为-1。在此训练过程中,设置ocsvm的核函数为rbf,训练误差为0.1。从相似的滑坡数据中选择70%作为训练数据,不相似非滑坡数据中选取相同数量的样本作为训练数据,剩余滑坡和非滑坡数据作为验证数据xtest,ytest,实现无效数据、冗余数据的剔除,达到欠采样的目的,但保留了样本中的有效信息。将训练数据输入到合成少数类过采样技术模型中,进行样本数据的过采样处理,得到新训练数据xsmo,ysmo,利用混合采样后的数据xsmo,ysmo输入到机器学习模型中进行自变量和因变量对应的建模运算,利用xtest,ytest进行模型精度验证。
[0081]
以下给出具体实例:
[0082]
以重庆市万州区走马镇和龙驹镇为例,利用arcgis提取出研究区指标因子(坡度、高程、斜坡结构、土地利用、地层、距道路距离、坡向、斜坡形态、地形湿度指数、植被归一化指数),并获取对应的滑坡数据组成样本数据集合,共计样本数量200601个,其中包含629个滑坡数据集和199972个非滑坡数据集。。
[0083]
将数据首先进行ocsvm欠采样,分离与滑坡特征相似的非滑坡,然后将滑坡数据进行smote过采样,最后随机选择出70%滑坡和相同数量的非滑坡进行建模,剩余数据进行验证。
[0084]
为证明混合采样模型的优越性和模型适应性,采用三种模型进行建模并通过受试者工作特征曲线(receiver operating characteristic curve,roc)来验证模型预测精度,预测精度分别如图2-4所示。
[0085]
可以看到:我们所提出的ocsvm-smote混合采样方法在3种模型中上都取得了不错
的优化效果,意味着通过混合采样可以有效提高模型预测精度,并具有较好的适应性。
[0086]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1