一种提升时间序列预测效果的方法和系统
1.本发明属于人工智能时间序列预测领域,具体涉及一种提升时间序列预测效果的方法和系统。
背景技术:
2.随着人工智能和时间序列预测方法的发展,时间序列信息在各个领域得到了广泛应用,利用历史数据预测未来数据的变化趋势从而指导决策,对工业界具有重要意义。对于随机高波动的时序数据(如风速、太阳辐射、电力负荷、金融数据等),现有基于信号分解的深度学习的预测效果不尽人意,其主要原因是此类方法存在一定的主观经验性,子序列缺乏明确的物理意义,高频子序列预测困难,且对新数据的输入较为敏感。
3.为提高建模效率和模型预测准确度,本发明创新性地提出了一种“积分-建模-差分”的预测方法,既降低了多个子序列带来的模型复杂度,又具有明确的物理意义,同时提高时间序列预测的准确度。
技术实现要素:
4.本发明为了解决背景技术中存在的技术问题,目的在于提供了一种提升时间序列预测效果的方法和系统,用于时间序列预测过程中实现更快速地建模和更准确的预测。
5.为了解决技术问题,本发明的技术方案是:
6.一种提升时间序列预测效果的方法,包括一个积分预处理子步骤、一个预测模型和一个差分回溯目标变量子步骤。这里所述时间序列数据是按照时间顺序排列的数据点序列,每个数据均为实数值。
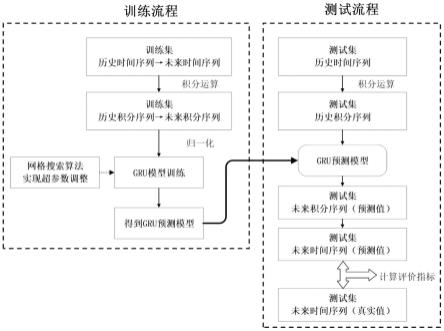
7.该预测方法实现预测的基本流程为:将一定长度的历史时间序列进行积分累加,或者进行一定代数处理后进行积分累加,称为历史积分序列;以一组固定长度的历史积分序列作为预测模型输入,经过预测模型计算后输出接下来一个或多个时间点的序列,称为未来积分序列预测值;对未来积分序列进行差分计算,得到未来时间序列预测值。
8.预测模型的目标为:使未来时间序列预测值与未来时间序列真实值的差距尽可能地小。为此,时间序列预测模型需要先根据已有的时间序列数据也就是过去数据训练得到时间序列预测模型的参数,该时间序列预测模型可用于预测未来时间序列。
9.由于本发明的预测模型需要在训练之后才可以使用,所以本发明的具体操作步骤分为:预测模型训练步骤和预测模型测试步骤。其中,训练步骤为学习时间序列预测模型中所有参数;测试步骤为使用时间序列预测模型来输出未来数据。具体步骤如下:
10.步骤1:收集一定长度的时间序列数据,划分训练集和测试集(注:接下来步骤2至步骤4中用到的任意时间序列都来自训练集);
11.步骤2:对历史时间序列进行积分处理,得到历史积分序列,对历史积分序列进行归一化;
12.步骤3:初始化预测模型,将训练集的历史积分序列输入模型进行训练;
13.步骤4:通过网格搜索算法重复训练预测模型,选择预测模型的最优超参数;
14.步骤5:将测试集历史积分序列做归一化处理后,输入训练好的模型,得到测试集的未来积分序列预测值;
15.步骤6:对测试集的未来积分序列预测值进行反归一化和差分运算,得到未来时间序列预测值;
16.步骤7:评估测试集上的预测准确率。
17.步骤1中划分训练集和测试集:将整个数据集以时间顺序按照70%/30%的比例划分训练集和测试集,即前70%为训练集,后30%为训练集。设训练集共包含n条时间序列数据,对于任意一条时间序列数据(y1,y2,
…
,y
t
),选定参数l(l《t),序列的前l条数据构成的子序列为历史时间序列,第l+1到l+a条数据构成的子序列为未来时间序列,记为(y
l+1
,y
l+2
,
…
,y
l+a
).
18.步骤2中所述积分处理定义为,某一时间戳的积分量yi等于自第一个时间序列数据y1到该时间戳对应的时间序列y
t
数据对应的所有时间序列数据的累加,即由此可得到积分时间序列(y1,y2,
…
,yn).积分处理可将波动序列转化为平滑的单调递增序列。归一化方法采用线性归一化,即由此可将积分序列数值范围控制在[0,1],便于后续计算。
[0019]
步骤3中所述预测模型可以采用任意的现有时间序列预测模型,如支持向量回归(svr),bp神经网络(bpnn),长短期记忆神经网络(lstm)和门控循环单元神经网络(gru)等。在本发明中,综合预测的准确度和参数计算量,最终选用gru作为预测模型。该模型包含一层gru层和一层全连接层。gru层的计算单元是以relu为激活函数的多层全连接神经网络,在每个时间节点t,该循环神经网络的输入层维度为输出为该输出表示基于第t个时间点对第t+1时间点的预测。全连接层以relu为激活函数,其输入为gru层的输出,其输出为长度为a的一维向量,即未来积分序列预测值。
[0020]
步骤4中网格搜索算法即穷举搜索,在所有候选的超参数组合中,通过循环遍历,表现最好的参数作为最终的结果。
[0021]
步骤6中反归一化即归一化的逆运算,即yi=y
′i(y
max-y
min
)+y
min
。由所述步骤2中对积分序列的定义可知,某时间戳对应的时间序列的值等于当前时间戳和前一时间戳的积分时间序列值的一阶差分,即y
t
=y
t-y
t-1
。由此可得未来时间序列预测值。
[0022]
步骤7中使用平均绝对误差(mae)和均方根误差(rmse)来评估时间序列预测准确率,mae和rmse越小,则表示预测准确率越高。对于未来时间序列实际值yi及其对应的预测值mae和rmse可分别表示为
[0023]
[0024][0025]
本发明还提供一种提升时间序列预测效果的系统,包括:
[0026]
scada系统,用于采集和传输数据;
[0027]
一个或多个处理器;
[0028]
存储器,用于存储算法程序以及scada系统的传输数据;
[0029]
所述scada系统采集现场数据并传输至存储器中存储,当所述算法程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行上述一种提升时间序列预测效果的方法。
[0030]
与现有技术相比,本发明的优点在于:
[0031]
(1)本发明采用变上限积分平滑时间序列的高频波动,使得机器学习模型能够更容易学习到平滑曲线的特征;
[0032]
(2)本发明避免将时间序列分解后分别建模,大大减少子模型数量,降低模型复杂度,提升了计算效率;
[0033]
(3)本发明的积分时间序列仍有明确的物理含义,相较于分解模型的子序列,具有更强的可解释性。
附图说明
[0034]
图1为本发明的算法流程图;
[0035]
图2为本发明时间预测系统与emd和persistence方法的预测结果比较图。
[0036]
图3为本发明时间预测系统与emd方法的模型训练时间比较图。
具体实施方式
[0037]
结合实施例说明本发明的具体技术方案。
[0038]
本实施采用gefcom2014风电数据集,通过本发明提出的方法提升时间序列预测系统在未来时间点上的预测准确度。本实施例具体步骤如图1所示,包括:
[0039]
步骤1:收集一定长度的时间序列数据,划分训练集和测试集;
[0040]
步骤2:对历史时间序列进行积分处理,得到历史积分序列,对历史积分序列进行归一化;
[0041]
步骤3:初始化预测模型,将训练集的历史积分序列输入模型进行训练;
[0042]
步骤4:通过网格搜索算法重复训练预测模型,选择预测模型的最优超参数;
[0043]
步骤5:将测试集历史积分序列做归一化处理后,输入训练好的模型,得到测试集的未来积分序列预测值;
[0044]
步骤6:对测试集的未来积分序列预测值进行反归一化和差分运算,得到未来时间序列预测值;
[0045]
步骤7:评估测试集上的预测准确率。
[0046]
所述步骤1划分训练集和测试集:由于数据集包含2012-2013两年的风功率数据,将2012年数据作为训练集,2013年数据作为测试集。训练集共包含8770条时间序列数据,对
于任意一条时间序列数据(y1,y2,
…
,y
t
),选定参数l(l《t),序列的前l条数据构成的子序列为历史时间序列,第l+1到l+a条数据构成的子序列为未来时间序列,记为(y
l+1
,y
l+2
,
…
,y
l+a
).
[0047]
所述步骤2所述积分处理定义为,某一时间戳的积分量yi等于自第一个时间序列数据y1到该时间戳对应的时间序列y
t
数据对应的所有时间序列数据的累加,即由此可得到积分时间序列(y1,y2,
…
,yn).积分处理可将波动序列转化为平滑的单调递增序列。归一化方法采用线性归一化,即由此可将积分序列数值范围控制在[0,1],便于后续计算。
[0048]
所述步骤3所述预测模型采用门控循环单元神经网络(gru),该模型包含一层gru层和一层全连接层。gru层的计算单元是以relu为激活函数的多层全连接神经网络,在每个时间节点t,该循环神经网络的输入层维度为输出为该输出表示基于第t个时间点对第t+1时间点的预测。全连接层以relu为激活函数,其输入为gru层的输出,其输出为长度为a的一维向量,即未来积分序列预测值。
[0049]
所述步骤4网格搜索算法即穷举搜索,在所有候选的超参数组合中,通过循环遍历,表现最好的参数作为最终的结果。
[0050]
所述步骤6反归一化即归一化的逆运算,即yi=y
′i(y
max-y
min
)+y
min
。由所述步骤2中对积分序列的定义可知,某时间戳对应的时间序列的值等于当前时间戳和前一时间戳的积分时间序列值的一阶差分,即y
t
=y
t-y
t-1
。由此可得未来时间序列预测值。
[0051]
所述步骤7本发明中使用平均绝对误差(mae)和均方根误差(rmse)来评估时间序列预测准确率,mae和rmse越小,则表示预测准确率越高。以提前2步预测为例,对于未来时间序列实际值yi及其对应的预测值mae和rmse可分别表示为
[0052][0053][0054]
该算例中,mae=0.06,rmse=0.11。
[0055]
图2为本发明时间预测系统与emd和persistence方法的预测结果比较图。
[0056]
图3为本发明时间预测系统与emd方法的模型训练时间比较图。
[0057]
一种提升时间序列预测效果的系统,包括:
[0058]
scada系统,用于采集和传输数据;
[0059]
一个或多个处理器;
[0060]
存储器,用于存储算法程序以及scada系统的传输数据;
[0061]
所述scada系统采集现场数据并传输至存储器中存储,当所述算法程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行如上述所述一种提升时间序列预
测效果的方法。
[0062]
上面对本发明优选实施方式作了详细说明,但是本发明不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。不脱离本发明的构思和范围可以做出许多其他改变和改型。应当理解,本发明不限于特定的实施方式,本发明的范围由所附权利要求限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1