信息抽取模板的生成方法和装置与流程
本发明涉及自然语言处理,尤其涉及一种信息抽取模板的生成方法和装置。
背景技术:
1、信息抽取(information extraction)目前可以应用于各类信息的处理,如药学领域文本信息(如药品说明书、药品单据等)。信息抽取指的是从自然语言文本中抽取出特定的事件或事实信息,来帮助将海量内容自动分类、提取和重构,这些信息通常包括实体(entity)、关系(relation)和事件(event),目前信息抽取技术主要有两个方向:基于模板匹配的方法和基于深度学习的方法。
2、对于前一方法,其信息抽取准确率高,但是由于自然语言的灵活性,需要人工编写和维护大量的规则模板,使得人工工作量较大,如果规则模板数量不足,则无法保证召回率。对于后一方法,深度学习模型的可解释性稍差,难以针对具体结果进行调优,只能在统计层面改进,并且,目前深度学习模型在一些经典自然语言理解任务上(例如实体抽取、关系抽取)的准确率还达不到实用要求。
技术实现思路
1、有鉴于此,本发明实施例提供一种信息抽取模板的生成方法和装置,能够根据已有的初始模板自动生成多个新模板来执行信息抽取,从而在保证信息抽取准确率且不增加人工工作量的情况下提高信息抽取召回率。
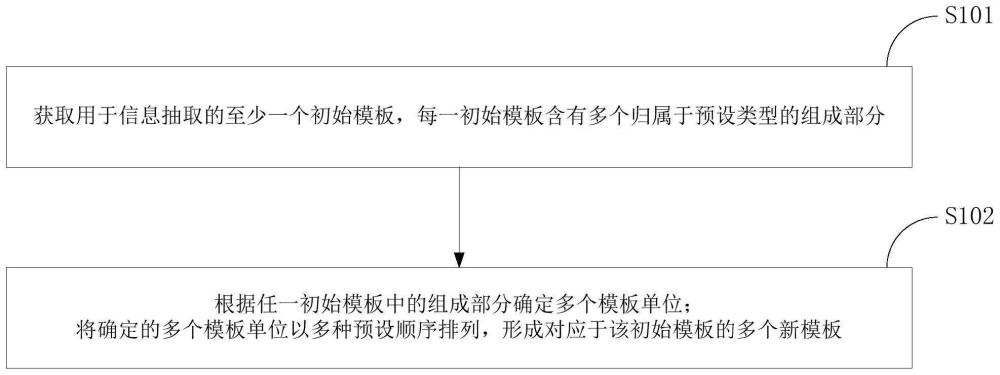
2、为实现上述目的,根据本发明的一个方面,提供了一种信息抽取模板的生成方法。
3、本发明实施例的信息抽取模板的生成方法包括:获取用于信息抽取的至少一个初始模板;其中,每一初始模板含有多个归属于预设类型的组成部分,所述组成部分为匹配符号和固定词中的至少一项,所述预设类型包括实体类型和关系类型中的至少一项;根据任一初始模板中的组成部分确定多个模板单位;将确定的多个模板单位以多种预设顺序排列,形成对应于该初始模板的多个新模板。
4、可选地,所述根据任一初始模板中的组成部分确定多个模板单位,包括:将该初始模板中的每一匹配符号确定为一个模板单位;对于该初始模板中归属于任一预设类型的一个固定词:将该固定词确定为一个模板单位,或者,生成归属于该预设类型的匹配符号并将该匹配符号确定为一个模板单位。
5、可选地,所述预设顺序为:所述多个模板单位之间的任一随机顺序,或者,符合预设排序规则的、所述多个模板单位之间的一种随机顺序。
6、可选地,所述将确定的多个模板单位以多种预设顺序排列,形成对应于该初始模板的多个新模板,包括:将所述多个模板单位以一种预设顺序排列;在相邻的模板单位之间插入至少一个间隔字符号,形成一个新模板;其中,所述间隔字符号用于匹配待抽取文本中不归属于所述预设类型的字。
7、可选地,所述方法进一步包括:在所述形成对应于该初始模板的多个新模板之后,对于任一新模板:获取该新模板和该初始模板在预设的同一语料库的匹配文本,计算该新模板的每一匹配文本与该初始模板的每一匹配文本的相似度;在所述相似度的平均值符合预设的相似条件时,将该新模板确定为目标模板。
8、可选地,所述方法进一步包括:在所述形成对应于该初始模板的多个新模板之后,对于任一新模板:获取该新模板和该初始模板在预设的同一语料库的匹配文本;在该新模板的匹配文本数量与该初始模板的匹配文本数量之商大于预设的第一阈值时,计算该新模板的每一匹配文本与该初始模板的每一匹配文本的相似度;在所述相似度的平均值符合预设的相似条件时,将该新模板确定为目标模板。
9、可选地,所述间隔字符号具有字数限制范围;所述相似条件包括:所述相似度的平均值大于预设的第二阈值;所述信息抽取包括实体抽取和关系抽取。
10、为实现上述目的,根据本发明的另一方面,提供了一种信息抽取模板的生成装置。
11、本发明实施例的信息抽取模板的生成装置可以包括:初始模板获取单元,用于:获取用于信息抽取的至少一个初始模板;其中,每一初始模板含有多个归属于预设类型的组成部分,所述组成部分为匹配符号和固定词中的至少一项,所述预设类型包括实体类型和关系类型中的至少一项;新模板生成单元,用于根据任一初始模板中的组成部分确定多个模板单位;将确定的多个模板单位以多种预设顺序排列,形成对应于该初始模板的多个新模板。
12、可选地,所述预设顺序为:所述多个模板单位之间的任一随机顺序,或者,符合预设排序规则的、所述多个模板单位之间的一种随机顺序;所述新模板生成单元进一步用于:将该初始模板中的每一匹配符号确定为一个模板单位;对于该初始模板中归属于任一预设类型的一个固定词:将该固定词确定为一个模板单位,或者,生成归属于该预设类型的匹配符号并将该匹配符号确定为一个模板单位;将所述多个模板单位以一种预设顺序排列;在相邻的模板单位之间插入至少一个间隔字符号,形成一个新模板;其中,所述间隔字符号用于匹配待抽取文本中不归属于所述预设类型的字;所述装置进一步包括:目标模板生成单元,用于:获取该新模板和该初始模板在预设的同一语料库的匹配文本,计算该新模板的每一匹配文本与该初始模板的每一匹配文本的相似度;在所述相似度的平均值符合预设的相似条件时,将该新模板确定为目标模板;或者,获取该新模板和该初始模板在预设的同一语料库的匹配文本;在该新模板的匹配文本数量与该初始模板的匹配文本数量之商大于预设的第一阈值时,计算该新模板的每一匹配文本与该初始模板的每一匹配文本的相似度;在所述相似度的平均值符合预设的相似条件时,将该新模板确定为目标模板。
13、为实现上述目的,根据本发明的又一方面,提供了一种电子设备。
14、本发明的一种电子设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明所提供的信息抽取模板的生成方法。
15、为实现上述目的,根据本发明的再一方面,提供了一种计算机可读存储介质。
16、本发明的一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现本发明所提供的信息抽取模板的生成方法。
17、根据本发明的技术方案,上述发明中的实施例具有如下优点或有益效果:
18、首先获取已有且可用的信息抽取初始模板,此后将其拆分为多个归属于预设类型的组成部分进而形成多个模板单位,最后将这些模板单位按照任意随机顺序或者预设排序规则下的随机顺序重新排列,并可以插入一个或多个间隔字符号,即可得到多个新模板,最后通过判别新模板与初始模板在同一语料库中匹配文本的相似度即可筛选出新模板中可用的目标模板,由此以自动化程序的方式实现大量可用模板的快速生成,能够同时保证信息抽取任务的准确率、召回率以及模板编写维护过程的低人工工作量。
19、上述的非惯用的可选方式所具有的进一步效果将在下文中结合具体实施方式加以说明。
技术特征:
1.一种信息抽取模板的生成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述根据任一初始模板中的组成部分确定多个模板单位,包括:
3.根据权利要求1所述的方法,其特征在于,所述预设顺序为:所述多个模板单位之间的任一随机顺序,或者,符合预设排序规则的、所述多个模板单位之间的一种随机顺序。
4.根据权利要求1所述的方法,其特征在于,所述将确定的多个模板单位以多种预设顺序排列,形成对应于该初始模板的多个新模板,包括:
5.根据权利要求4所述的方法,其特征在于,所述方法进一步包括:在所述形成对应于该初始模板的多个新模板之后,对于任一新模板:
6.根据权利要求4所述的方法,其特征在于,所述方法进一步包括:在所述形成对应于该初始模板的多个新模板之后,对于任一新模板:
7.根据权利要求5或6所述的方法,其特征在于,所述间隔字符号具有字数限制范围;
8.一种信息抽取模板的生成装置,其特征在于,包括:
9.根据权利要求8所述的装置,其特征在于,所述预设顺序为:所述多个模板单位之间的任一随机顺序,或者,符合预设排序规则的、所述多个模板单位之间的一种随机顺序;
10.一种电子设备,其特征在于,包括:
11.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现如权利要求1-7中任一所述的方法。
技术总结
本发明公开了一种信息抽取模板的生成方法和装置,涉及自然语言处理技术领域。该方法的一具体实施方式包括:获取用于信息抽取的至少一个初始模板;其中,每一初始模板含有多个归属于预设类型的组成部分,所述组成部分为匹配符号和固定词中的至少一项,所述预设类型包括实体类型和关系类型中的至少一项;根据任一初始模板中的组成部分确定多个模板单位;将确定的多个模板单位以多种预设顺序排列,形成对应于该初始模板的多个新模板。该实施方式能够根据已有的初始模板自动生成多个新模板来执行信息抽取,从而在保证信息抽取准确率且不增加人工工作量的情况下提高信息抽取召回率。
技术研发人员:杨帅,张亚,吴元清,周谦
受保护的技术使用者:北京京东拓先科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!