基于配电网关键要素数据的配电运行风险评估方法、系统与流程
1.本发明涉及供电技术领域,具体为一种基于配电网关键要素数据的配电运行风险评估方法和系统。
背景技术:
2.一般来说,城市地区配电网具有负荷密度大、用电量集中、供电要求高等特点,部分地区的设备运行年限长,配电网络较为薄弱,负荷转供能力面临着重大的挑战,尤其在夏季高温时段的城中村区域,大功率电器的使用导致用电负荷大幅攀升,部分配变容量无法满足客户用电增长需求,台区出现故障停电、电压不稳等问题。
3.据某些城市地区度夏期间的数据统计,当天气持续高温,连续3天达到35℃时,用电负荷大幅上涨,设备重过载、故障跳闸、客户投诉等问题突出,高峰负荷日低压报障工单和停电类客户投诉工单数量呈爆发式增长,台区运行风险加大。因此,配电网关键要素(包括馈线、配变、低压等)的运行风险评估预警,是配电网运营监控中的重要内容。目前,对于配电网关键要素问题综合治理,通常集中在事中监控和事后处理两个阶段,即通过对配变运行情况的实时监测发现已经重过载、低电压、三相不平衡与频繁跳闸的台区,运维人员接到告警后再采取相应的措施,这种处理方式以事后处理为主,相对被动,缺乏预判性,导致很多情况下无法避免电网和用户的损失。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种基于配电网关键要素数据的配电运行风险评估方法和系统,通过对配电网相关数据进行预处理,筛选出高价值的数据,对台区风险影响因素的关联度进行分析,构建具有动态自适应能力的预测模型,技术方案在整体上能够提前发现和预测台区配电网络中出现的潜在威胁,提高了低压台区的供电可靠率,解决了对配电网运行风险进行有效预判的问题。
5.本发明的第一发明目的是提供一种基于配电网关键要素数据的配电运行风险评估方法,包括以下步骤:
6.收集配电运行风险评估所需要用到的信息数据;
7.筛选信息数据:对所收集到的信息数据采用基于孤立划分机制的孤立森林机器学习算法辨识异常数据点,筛选出不含异常数据点的信息数据;
8.采用基于随机少数类过采样算法添加合成样本,对信息数据进行均衡处理;
9.对均衡处理后的数据进行分类,以确定不同类簇的台区样本;
10.对台区风险影响因素进行关联系分析,明确台区运行风险的关键风险影响因素;
11.根据关键风险影响因素和台区负荷预测结果,利用信息熵技术构建基于配电网关键要素的台区风险预测机器学习模型,基于所构建的台区风险预测机器学习模型判断该台区是否会发生运行风险。
12.在优选的实施例中,利用信息熵技术构建基于配电网关键要素的台区风险预测机
器学习模型时,采用虚拟预测技术计算不同机器学习预测模型针对不同预测尺度的相对误差熵值与变异程度系数。
13.本发明的第二发明目的是提供一种基于配电网关键要素数据的配电运行风险评估系统,包括:
14.信息数据收集模块,用于收集配电运行风险评估所需要用到的信息数据;
15.信息数据筛选模块,对所收集到的信息数据采用基于孤立划分机制的孤立森林机器学习算法辨识异常数据点,筛选出不含异常数据点的信息数据;
16.均衡处理模块,采用基于随机少数类过采样算法添加合成样本,对信息数据进行均衡处理;
17.数据分类模块,对均衡处理后的数据进行分类,以确定不同类簇的台区样本;
18.关联分析模块,对台区风险影响因素进行关联系分析,明确台区运行风险的关键风险影响因素;
19.模型构建模块,根据关键风险影响因素和台区负荷预测结果,利用信息熵技术构建基于配电网关键要素的台区风险预测机器学习模型,基于所构建的台区风险预测机器学习模型判断该台区是否会发生运行风险。
20.与现有技术相比,本发明提供了一种基于配电网关键要素数据的配电运行风险评估方法和系统,具备以下有益效果:
21.1、本发明基于配电网关键要素数据的配电运行风险评估方法和系统,通过采用机器学习方法对相关配电网数据进行数据预处理,筛选出高价值的数据,以确保后续数据分析以及评估结果的精准性和价值性,做出更好的预测、分析和决策。
22.2、本发明基于配电网关键要素数据的配电运行风险评估方法和系统,通过对台区风险影响因素关联度的深入分析,在明确关键风险影响因素后,利用台区负荷预测结果,结合天气预报,建立基于机器学习的台区风险预测模型,从而判断该台区是否会发生低电压重过载等运行风险,并给出相应风险等级。
23.3、本发明基于配电网关键要素数据的配电运行风险评估方法和系统,通过利用信息熵理论,研究具有动态自适应能力的集合机器学习预测新模型。由于基于信息熵的预测框架能够根据不同机器预测模型在一定时间尺度上的表现,动态辨识出权重系数,大大提高了自适应预测能力;通过构建智能故障诊断和配电网关键要素风险分类等级与评估模型,利用混合机器学习方法解决配电网关键要素风险预测机器学习模型的鲁棒性和动态自适应问题,提升了模型应用中的泛化能力。
24.4、本发明具备及时通报预警、助力专业部门提升客户用电服务水平、为迎峰度夏、节假日保供电和日常的主动服务和主动检修等提供支撑等优点,能够提前发现和预测台区配电网络中出现的潜在威胁,从而可以具有针对性地对台区范围内设备进行检修和调整,提升电力设备的正常工作,提高低压台区的供电可靠率,解决了对配电网运行风险进行有效预判的问题。
附图说明
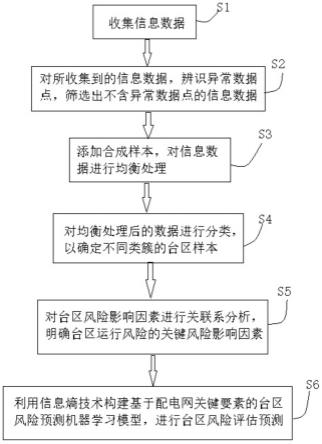
25.图1是本发明实施例中配电运行风险评估方法的流程图;
26.图2是本发明实施例中配电运行风险评估系统的结构框图。
具体实施方式
27.下面将结合本发明的实施例和附图,对本发明的技术方案进行清楚、完整的描述;显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
28.实施例1
29.本实施例提供一种基于配电网关键要素数据的配电运行风险评估方法,如图1所示,包括以下步骤:
30.s1、收集信息数据:从配电网各业务系统中,获取配电网内部数据和外部数据,对内部数据和外部数据进行预处理,形成配电运行风险评估所需要用到的信息数据。
31.在本实施例中,可以通过电压系统、巡视app、营配(供电可靠性)、营配(快速复电)、资产一体化系统、电能量平台、计量自动化系统、营销一体化系统、营销运行监控系统、ems(能量管理系统)、电网运行管理系统、配用电系统、快速复电系统等业务系统,收集、获取配电网的内部数据以及气象、人口、地域、经济、时间节气等外部数据,并对内部数据和外部数据进行数据提取、清洗、整合、存储等预处理,形成配电运行风险评估所需要用到的信息数据,为分析模型的构建提供数据基础。
32.s2、筛选信息数据:对所收集到的信息数据采用一种基于孤立划分机制的孤立森林机器学习算法辨识异常数据点,筛选出不含异常数据点的信息数据。
33.对于信息数据的数据集x={x1,...,xn},x∈r
p
为数据集内的数据点,即数据集x中含有n个数据点;孤立森林采用集成机器学习策略构建t棵名为itree的二叉树,每棵二叉树在数据集x中抽取子样本并随机选取特征变量及值域范围内的划分阈值对子样本空间进行递归划分,直至达到叶节点只包含一个数据点无法继续分割时,itre二叉树构建完成。
34.在itree二叉树中,观测数据点x的分割叶节点至根节点之间树的路径长度h(x),路径长度h(x)值越小表示该数据点x越容易被孤立,数据点x的异常程度就越高,反之说明数据点正常。异常的数据点在三次递归划分后被孤立,在对应itree二叉树中,异常的数据点分割叶节点的路径长度小于其它观测对象(即其它观测数据点),将会被itree二叉树更早定位和孤立。
35.本实施例通过数据点的异常分值来衡量数据点的异常程度,并将任一数据点x的异常分值s(x,n)定义为:
[0036][0037]
式(1)中,e(h(x))为数据点x在t棵itree二叉树中路径长度h(x)的平均值;c(n)为子样本抽样数量为n时所有数据点在二叉树中路径长度的平均值。由此计算的异常分值越接近1,说明观测点很早就被孤立,异常程度高;异常分值接近0,则表示数据点不容易被孤立,安全性较高。
[0038]
s3、添加合成样本,对信息数据进行均衡处理。
[0039]
针对配电网台区风险预测与动态预警中容易出现的样本不平衡问题,本实施例采用一种基于随机少数类过采样smote-nc的算法,用于样本不均衡时添加合成样本,从而使数据集趋于均衡。具体实施如下:
[0040]
设少数类样本集x={x1,x2,...,xn},其中xi=(x
i1
,x
i2
,...,x
im
,...,x
in
)
t
为第i个(i=1,2,...,n)少数类样本实例,x
i1
,x
i2
,...,x
im
为少数类样本实例xi的m个连续数值型特征取值,x
i(m+1)
,x
i(m+2)
,...,x
in
为少数类样本实例xi的n-m个名义型特征属性。随机少数类过采样算法smote-nc合成新样本的步骤如下:
[0041]
1)计算中位数。计算少数类样本实例中所有连续数值型特征的标准差的中位数,记为med:
[0042][0043]
med=median(σ1,σ2,...,σm)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0044]
式(2)中,μk为少数类样本x中所有少数类样本实例第k个连续数值型特征的平均值。
[0045]
2)计算最近邻。在原始欧式距离计算方法的基础上,考虑名义特征差异的影响,添加式(3)中标准差的中位数med作为距离计算的惩罚项,定义任意少数类样本实例xi和xj之间的距离d
ij
:
[0046][0047]
式(4)中,n通过少数类样本实例xi和xj名义型特征差异个数d计算得到。值得注意的是,经one-hot编码转换的名义型特征差异个数会增加一倍,这种情况n应取值为d/2。
[0048]
根据式(4)计算少数类样本实例xi的k个近邻样本,记为少数类样本实例xi的近邻样本集k默认为5。
[0049]
3)计算合成样本的连续数值型特征部分。设合成样本为x
new
、合成样本x
new
的连续数值型特征部分为x
′
new
,则合成样本的连续数值型特征部分采用smote算法的随机线性插值方法进行合成:
[0050][0051]
式(5)中,xi=(x
i1
,x
i2
,
…
,x
im
)
t
,rand(0,1)表示区间(0,1)的一个随机数,为近邻样本集中的随机一点。
[0052]
4)计算合成样本的名义型特征部分。选取少数类样本实例xi的近邻样本集中各名义型特征的众数值,作为合成样本x
new
的名义型特征部分x
″
new
,然后将两部分特征合成值x
′
new
和x
″
new
进行合并得到合成样本x
new
。
[0053]
s4、对均衡处理后的数据进行分类,以确定不同类簇的台区样本,从而对台区风险预测的机器学习模型进行训练学习,以降低台区风险预测的机器学习模型难度。
[0054]
本实施例中,数据分类可以采用以下两种对策方案来实现:
[0055]
(1)borderhne-smote方法:有效克服传统smote算法存在的边缘化和盲目性等问题,从而解决生成样本重叠发问题,使新增加的“人造”样本(即所添加的合成样本)更有效。该算法仅使用边界上的少数类样本来合成新样本,从而改善样本的类别分布,采样过程是将少数类样本分为3类,分别为safe、danger和noise。最后,仅对表为danger的少数类样本过采样。
[0056]
(2)生成式对抗网络gan方法:
[0057]
生成式对抗网络gan(generative adversarial networks)属于一种深度学习模型,是近年来复杂分布上无监督学习的最具前景的方法之一,可有效解决小数据集的数据量不足的问题。
[0058]
gan应用需要有良好的训练方法,否则可能由于传统神经网络模型的自由性而导致输出不理想,为此,本实施例采用深度神经网络建立生成模型g和判别模型d,通过它们之间的互相博弈学习产生预期的“人造”样本输出。在本实施例中,gan是由一个生成器和一个判别器构成。生成器捕捉真实数据样本的潜在分布,并由潜在分布生成新的数据样本;判别器是一个二分类器,判别输入是真实数据还是生成的样本。
[0059]
s5、对台区风险影响因素进行关联系分析,明确台区运行风险的关键风险影响因素。
[0060]
本实施例将台区运行的大量历史相关监测数据与电网内外部各类数据进行融合,通过数据挖掘方法深入分析各类台区风险影响因素之间的关联关系与影响程度,采用高效快速的灰色关联度分析方法对台区风险与其影响因素间的关系进行分析。
[0061]
灰色关联度分析方法可以高效的寻求系统中各子系统(或各类影响因素)之间的数值关系。因此,灰色关联度分析对于一个系统发展变化态势提供了量化的度量,适合动态过程的分析。灰色关联度分析的过程,具体如下:
[0062]
(1)确定反映系统行为特征的参考数列和影响系统行为的比较数列。其中,反映系统行为特征的数据序列,称为参考数列;影响系统行为的因素组成的数据序列,称为比较数列。
[0063]
(2)对参考数列和比较数列进行无量纲化处理。由于系统中各因素的物理意义不同,导致数据的量纲也不一定相同,不便于比较,或在比较时难以得到正确的结论;因此在进行灰色关联度分析时,一般都要进行无量纲化的数据处理。
[0064]
(3)求参考数列与比较数列的灰色关联系数ξ(xi)。关联程度实质上是曲线间几何形状的差别程度;因此曲线间差值大小,可作为关联程度的衡量尺度。
[0065]
在本实施例中,设一个参考数列x0有若干个比较数列x1,x2,
…
,xn,各比较数列与参考数列在各个时刻(即曲线中的各点)的关联系数ξ(xi)可由下列公式算出:
[0066]
其中ρ为分辨系数,一般在0-1之间,通常取0.5。
[0067]
如果是第二级最小差,则记为δmin;如果是两级最大差,记为δmax。
[0068]
为各比较数列xi曲线上的每一个点与参考数列x0曲线上的每一个点的绝对差值,记为δ
0i
(k)。
[0069]
所以关联系数也可简化如下列公式:
[0070][0071]
(4)求关联度
[0072]
因为关联系数是比较数列与参考数列在各个时刻(即曲线中的各点)的关联程度值,所以它的数不止一个,而信息过于分散不便于进行整体性比较。因此有必要将各个时刻(即曲线中的各点)的关联系数集中为一个值,即求其平均值,作为比较数列与参考数列间关联程度的数量表示,关联度的公式如下:
[0073][0074]
关联度的值越接近1,说明相关性越好。
[0075]
(5)关联度排序
[0076]
因素间的关联程度,主要是用关联度的大小次序描述,而不仅是关联度的大小。将m个子序列对同一母序列的关联度按大小顺序排列起来,便组成了关联序,记为{x},它反映了对于母序列来说各子序列的“优劣”关系。若r
0i
>r
0j
,则称{xi}对于同一母序列{x0}优于{xi},记为{xi}>{xj};r
0i
表示第i个子序列对母数列特征值。
[0077]
s6、构建预测模型进行预测评估:通过对台区风险影响因素关联度的深入分析,在明确关键风险影响因素后,再根据台区负荷预测结果,利用信息熵技术构建基于配电网关键要素的台区风险预测机器学习模型,从而基于所构建的台区风险预测机器学习模型判断该台区是否会发生低电压重过载等运行风险,并给出相应风险等级。
[0078]
在本步骤中,采用虚拟预测技术计算不同机器学习预测模型针对不同预测尺度的相对误差熵值与变异程度系数,从而解决台区风险预测集合机器学习预测权重系数难以确定和动态自适应能力差的问题。主要实施步骤如下:
[0079]
步骤s61:计算第j个机器学习预测模型在第t时刻的相对误差比重p
jt
:
[0080][0081]
式中,e
jt
为预测相对误差,其中,y
t
表示t时刻的实际值,y
jt
表示t时刻第j种机器学习预测方法的预测值;
k为机器学习预测模型的数目;
[0082]
步骤s62:计算第j个机器学习预测模型的预测相对误差的熵值hj:
[0083][0084]
步骤s63:计算第j个机器学习预测模型的预测相对误差的变异程度系数dj:
[0085]dj
=1-hjꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0086]
步骤s64:计算第j个机器学习预测模型的权重系数wj:
[0087][0088]
式中,k为机器学习预测模型数,
[0089]
实施例2
[0090]
本实施例与实施例1基于相同的发明构思,提供的是一种基于配电网关键要素数据的配电运行风险评估系统,如图2所示,包括:
[0091]
信息数据收集模块,用于收集配电运行风险评估所需要用到的信息数据;
[0092]
信息数据筛选模块,对所收集到的信息数据采用基于孤立划分机制的孤立森林机器学习算法辨识异常数据点,筛选出不含异常数据点的信息数据;
[0093]
均衡处理模块,采用基于随机少数类过采样算法添加合成样本,对信息数据进行均衡处理;
[0094]
数据分类模块,对均衡处理后的数据进行分类,以确定不同类簇的台区样本;
[0095]
关联分析模块,对台区风险影响因素进行关联系分析,明确台区运行风险的关键风险影响因素;
[0096]
模型构建模块,根据关键风险影响因素和台区负荷预测结果,利用信息熵技术构建基于配电网关键要素的台区风险预测机器学习模型,基于所构建的台区风险预测机器学习模型判断该台区是否会发生运行风险。
[0097]
本实施例的各模块分别用于实现实施例1的步骤s1-s6,具体实现过程可参照实施例1所描述的技术内容,在此不赘述。
[0098]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1