一种改进的联邦加权聚合方法及系统
1.本发明涉及har人类活动识别技术领域,尤其涉及一种改进的联邦加权聚合方法及系统。
背景技术:
2.随着智能传感器设备的快速发展,越来越多的传感器设备被用在人类活动识别(har)中,har人类活动识别技术通过采集人体运动产生的各种物理信息来识别姿态动作,包括身体姿态、手指运动、面部运动等,用于医疗康复、日常行为检测、安全驾驶等方面。传统的har识别都是集中式的,需要用户把数据上传服务器,这样会导致用户体征数据的泄露。联邦学习(federated learning)是一种分布式机器学习方法,它实现了模型向数据移动,客户端数据不出本地,降低隐私数据泄露的风险,联邦学习的快速发展为人们的生活提供了很大便捷。
3.现有联邦学习方法简单介绍如下:
4.1、fedavg:首先随机选择m个客户端采样,对这m个客户端的梯度更新进行平均以形成全局更新,同时用当前的全局模型替换未采样的客户端。但是该方法虽然对fedsgd在相同效果情况下,通讯成本大大降低,但是最终的模型是有偏倚的,不同于预期的每个客户端确定性聚合后的模型。仅仅使用简单的加权平均,不足以表达复杂的模型。
5.2、fedfast:该方法基于用户端的embedding进行聚类,把用户端模型分为不同的cluster,每次在cluster内部抽取部分用户,减少通信成本,但是模型的准确率提升有限,也没有考虑用户端数据质量的问题,这样会带来联邦聚合数据漂移的问题。
6.现有联邦学习存在如下缺点:
7.1、缺少对客户端模型效果的度量
8.现有方法仅仅考虑了客户端数据量的大小,在server端聚合时每个模型的权重都是一致的,但实际不同用户端模型的准确率是不同,这样导致在server进行模型融合时会带来偏移,导致模型的准确率下降。每个模型由于本地数据的多样性,训练的模型准确率也有偏差,而在服务器端进行模型聚合时不考虑模型的准确率,往往导致聚合偏差,需要更多轮次的迭代才可以收敛。
9.2、对选择加入聚合的客户端缺少有效的抽样算法
10.现有联邦学习算法对加入聚合的客户端都是随机抽样,但是随机抽样会导致聚合的客户端有很多相似的情况,更多相同的客户端聚合会导致本轮模型偏离最终的收敛结果。
技术实现要素:
11.本发明针对联邦学习在人类活动识别应用时存在的缺少对客户端模型效果的度量、对选择加入聚合的客户端缺少有效的抽样算法,导致人类活动识别模型聚合时间长、模型的准确率低的问题,提出一种改进的联邦加权聚合方法及系统,引入了对加入聚合客户
端的抽样机制,提升人类活动识别模型聚合速度,引入server端模型准确率评估机制,提高人类活动识别模型聚合的准确率。
12.为了实现上述目的,本发明采用以下技术方案:
13.本发明一方面提出一种改进的联邦加权聚合方法,包括:
14.客户端发送训练后的人类活动识别模型到服务器端,服务器端对客户端上传的人类活动识别模型进行minhash聚类;
15.服务器端基于聚类后的客户端上传的人类活动识别模型进行等量抽样;结合服务器端的人类活动无标签数据,利用选举机制获取抽样的每个客户端上传的人类活动识别模型的准确率,并对模型准确率进行评估,从而获取参与服务器端全局模型聚合的客户端上传的人类活动识别模型,进而得到服务器端模型聚合时的准确率;
16.把得到的参与全局模型聚合的客户端上传的人类活动识别模型和服务器端模型聚合时的准确率一起加权到服务器端全局模型的模型聚合更新中,得到联邦加权聚合后的人类活动识别模型,并基于得出的人类活动识别模型进行人类活动识别。
17.进一步地,在客户端发送人类活动识别模型到服务器端之前,还包括:
18.服务器端选择初始化的人类活动识别模型,并下发模型给各个客户端;
19.客户端接收初始化的人类活动识别模型,结合本地存储的人类活动数据和模型参数训练本地模型更新,得到训练后的人类活动识别模型。
20.进一步地,按照如下方式对模型准确率进行评估:
21.按照下式对每个模型的准确率进行评估,以判断模型的准确率是否符合条件,能否参与到服务器端模型的聚合中:
[0022][0023]
其中f(x)为代表模型准确率的复合函数,用于对模型的准确率进行激活;r为准确率阈值;α为超参数,用于保证函数的连续性以及可导性;
[0024]
得出评估后的每个模型的准确率。
[0025]
本发明另一方面提出一种改进的联邦加权聚合系统,包括:
[0026]
聚类模块,用于客户端发送训练后的人类活动识别模型到服务器端,服务器端对客户端上传的人类活动识别模型进行minhash聚类;
[0027]
模型准确率评估模块,用于服务器端基于聚类后的客户端上传的人类活动识别模型进行等量抽样;结合服务器端的人类活动无标签数据,利用选举机制获取抽样的每个客户端上传的人类活动识别模型的准确率,并对模型准确率进行评估,从而获取参与服务器端全局模型聚合的客户端上传的人类活动识别模型,进而得到服务器端模型聚合时的准确率;
[0028]
联邦加权聚合模块,用于把得到的参与全局模型聚合的客户端上传的人类活动识别模型和服务器端模型聚合时的准确率一起加权到服务器端全局模型的模型聚合更新中,得到联邦加权聚合后的人类活动识别模型,并基于得出的人类活动识别模型进行人类活动识别。
[0029]
进一步地,还包括:
[0030]
模型下发模块,用于服务器端选择初始化的人类活动识别模型,并下发模型给各
个客户端;
[0031]
模型训练模块,用于客户端接收初始化的人类活动识别模型,结合本地存储的人类活动数据和模型参数训练本地模型更新,得到训练后的人类活动识别模型。
[0032]
进一步地,按照如下方式对模型准确率进行融合:
[0033]
按照下式对每个模型的准确率进行评估,以判断模型的准确率是否符合条件,能否参与到服务器端模型的聚合中:
[0034][0035]
其中f(x)为代表模型准确率的复合函数,用于对模型的准确率进行激活;r为准确率阈值;α为超参数,用于保证函数的连续性以及可导性;
[0036]
得出评估后的每个模型的准确率。
[0037]
与现有技术相比,本发明具有的有益效果:
[0038]
1、引入了对加入聚合客户端的抽样机制,提升人类活动识别模型聚合速度。
[0039]
传统fedavg的方式是每轮次聚合时候随机进行抽样,这样存在一个非常重要的问题,就是抽样数据分布不均匀,在迭代过程中可导致模型更大震荡,收敛速度大大降低。因为随机抽样再聚合时候会出现更多相似的客户端,这样相似的客户端导致本轮训练数据和整体并不完全相符,因此选择更加合适的客户端参与人类活动识别联邦模型聚合可以提高服务器端模型聚合效率。所以本发明提出一种先聚类再选择客户端模型的有效方法,该方案首先根据客户端上传的人类活动识别模型进行聚类。最终达到相似客户端模型在一个类cluster效果,然后在每个类内进行等量的抽样,这样就保证客户端数据的多样行,在模型训练时候减少了模型震荡,提升了训练效率。
[0040]
2、引入server端模型准确率评估机制,提高人类活动识别模型聚合的准确率。
[0041]
引入了客户端数据质量权重后,模型的漂移会有所减少,为了进一步解决该问题。引入server端,首先客户端上传人类活动识别模型到sever端后,server端会收集一些没有标签的数据,各个客户端的人类活动识别模型会对这些没有标签的数据进行预测,最后根据所有客户端人类活动识别模型预测的结果进行投票选举,从而获得每一个模型的准确率,进一步减少模型漂移。
附图说明
[0042]
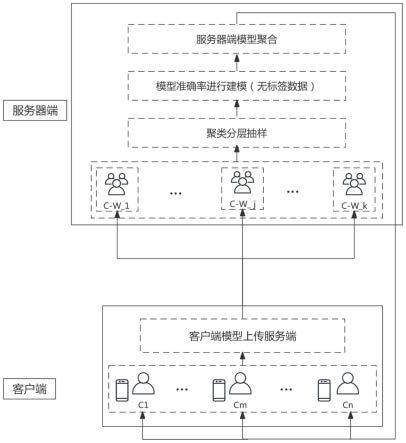
图1为本发明实施例一种改进的联邦加权聚合方法的流程示意图;
[0043]
图2为本发明实施例客户端建模流程图;
[0044]
图3为本发明实施例服务器端建模流程图;
[0045]
图4为本发明实施例客户端数据建模示意图;
[0046]
图5为本发明实施例服务器端模型准确率评估流程图;
[0047]
图6为本发明实施例一种改进的联邦加权聚合系统架构图。
具体实施方式
[0048]
下面结合附图和具体的实施例对本发明做进一步的解释说明:
[0049]
如图1所示,一种改进的联邦加权聚合方法,包括:
[0050]
客户端发送训练后的人类活动识别模型到服务器端,服务器端对客户端上传的人类活动识别模型进行minhash聚类;
[0051]
服务器端基于聚类后的客户端上传的人类活动识别模型进行等量抽样;结合服务器端的人类活动无标签数据,利用选举机制获取抽样的每个客户端上传的人类活动识别模型的准确率,并对模型准确率进行评估,从而获取参与服务器端全局模型聚合的客户端上传的人类活动识别模型,进而得到服务器端模型聚合时的准确率;
[0052]
把得到的参与全局模型聚合的客户端上传的人类活动识别模型和服务器端模型聚合时的准确率一起加权到服务器端全局模型的模型聚合更新中,得到联邦加权聚合后的人类活动识别模型,并基于得出的人类活动识别模型进行人类活动识别。
[0053]
进一步地,人类活动识别是一个分类问题,因此本发明使用的人类活动识别模型包括dnn、贝叶斯分类、决策树、随机森林、gbdt、xgboost等分类模型。
[0054]
进一步地,在客户端发送人类活动识别模型到服务器端之前,还包括:
[0055]
服务器端选择初始化的人类活动识别模型,并下发模型给各个客户端;
[0056]
客户端接收初始化的人类活动识别模型,结合本地存储的人类活动数据和模型参数训练本地模型更新,得到训练后的人类活动识别模型。
[0057]
进一步地,按照如下方式对模型准确率进行评估:
[0058]
按照下式对每个模型的准确率进行评估,以判断模型的准确率是否符合条件,能否参与到服务器端模型的聚合中:
[0059][0060]
其中f(x)为代表模型准确率的复合函数,用于对模型的准确率进行激活;r为准确率阈值;α为超参数,用于保证函数的连续性以及可导性;
[0061]
得出评估后的每个模型的准确率。
[0062]
具体地,本发明整个流程可以分为2部分,分别是客户端和服务器端,首先在服务器端采用分层聚类的方式,先把相似客户端模型进行聚类,然后在同一个cluster类内进行等量的抽样,避免了在全量数据随机抽样带来的模型训练震荡的问题。然后在服务器端对客户端的模型准确率进行建模,通过服务器端无标签数据对模型的准确率进行建模,进一步减少模型漂移。
[0063]
首先,在服务器端利用客户端上传模型进行聚类,由于这里的客户端很多,采用kmeans、高斯、lda等方案耗时都比较高,kmeans时间复杂度为0(k*n*d*t),k为聚类数量,n为数据量,d数位维度,t是迭代次数。所以本实施例采用minhash的分桶的高效方法,首先对每个模型的embedding进行hash,这里需要选择hash函数的个数,经过每个hash函数后特征都会产出一个二进制的0、1编码。通过多个hash函数的映射最终产出一串二进制编码的字符串,由于在高维空间相似的特征在经过hash后在还有很大的概率相似,因此通过多个hash函数后,如果产出的二进制字符串相似,则之前特征就基本相似,以上是理论依据。通过多个hash函数后对比kmeans算法时间复杂度就大大降低,从之前的0(k*n*d*t)降低到o(n*k*d)(其中n是数据量、k是哈希函数个数、d是数据的维度)。每个客户端模型的特征经过hash之后的二进制字符串可以直接进行分组,同一个组内的客户端模型就是同一个cluster,每个cluster抽样相同客户端模型数目。
[0064]
其次,服务器端对客户端上传的模型质量进行建模。通过在客户端和服务端的建模提升模型整体准确率。客户端上传本地更新模型到sever后,server端会收集一些没有标签的数据,抽样得出的各个客户端的模型会对这个没有标签的数据进行预测,最后根据所有客户端模型预测的结果进行投票选举,并进行评估,从而获得每一个模型的准确率,进一步减少模型的漂移。
[0065]
最后,经过多轮迭代达到模型收敛,经过实验发现该方案可以减少随机抽样带来的模型震荡问题,同时无标签数据也提升了模型准确率。
[0066]
具体地,客户端建模流程图如图2所示,包括:
[0067]
c01 server端选择初始化模型model1,并下发模型给各个客户端;
[0068]
c02客户端接收model1;
[0069]
c03客户端结合本地数据训练本地模型更新;
[0070]
c04客户端把模型上传服务器端;
[0071]
c05服务器端接收客户端模型。
[0072]
具体地,服务器端建模流程图如图3所示,包括:
[0073]
s01客户端上传各个模型到服务器端;
[0074]
s02服务器端接收客户端模型;
[0075]
s03服务器端对上传的客户端模型进行聚类(采用minhash方法)并进行类内抽样;
[0076]
s04为减少抽样带来的准确率偏差,引入模型准确率机制;
[0077]
s05在模型聚合前对参与训练的各个客户端的模型采用投票机制计算其准确率;
[0078]
s06服务器端收集无标签数据,每个模型经过无标签数据得到预测结果;
[0079]
s07利用投票机制得出每个模型的准确率;
[0080]
s08引入f(x)函数对每个模型的准确率进行评估;
[0081]
s09根据f(x)评估出适合参与服务器端全局模型聚合的客户端;
[0082]
s10 server聚合时建模(投票机制)每个客户端模型的准确率。
[0083]
进一步地,客户端数据建模如图4所示:
[0084]
首先server端选择初始化模型model1,并下发模型给各个客户端;客户端接收model1,客户端利用本地数据和从服务器得到的模型model1进行本地训练获得model2,然后把模型model2上传到服务器端,服务器利用不同客户端的模型model2进行聚合。
[0085]
进一步地,服务器端模型准确率评估机制如图5所示:
[0086]
首先我们利用客户端上传的模型在服务器端引入模型准确率机制,在模型聚合前对参与训练的各个客户端的模型采用投票机制进行准确率评估。这里为了获得模型的准确率,采用无标签的数据,让每个模型经过无标签的数据得到预测结果,以此类推,经过这样的验证我们可以得到每个模型的准确率。得到每个模型的准确率之后需要对每个模型的准确率进行评估,判断模型的准确率是否符合条件,能否参与到server端模型的聚合中。这里我们引入代表模型准确率的复合函数f(x)对模型的准确率进行评估,根据评估结果来决定是否参与服务器端模型的聚合操作。
[0087][0088]
其中f(x)为代表模型准确率的复合函数,复合函数f(x)的作用是对模型的准确率
进行激活,目的是保证高于r的准确率不变,对低于r的准确率进行打压降权,保障高准确率的客户端在最后加权融合时候更占优势。其中r是一个超参数,代表对准确率的一个阈值,大于r的准确率不变,小于r的准确率利用公式f(x)=α(e
x-r-1+r)进行打压。α是一个超参数,目的是为了保证函数的连续性以及可导性。
[0089]
进一步地,最后把客户端的数据建模的结果和服务器端模型的准确率一起加权到服务器端全局模型的模型聚合更新中。
[0090]
进一步地,服务器端聚合抽样包括:
[0091]
客户端通过本地数据训练的模型上传到服务器,获取模型特征后进行特征工程的处理,最后每个客户端都形成一个multi-hot的embedding特征,然后针对特征进行聚类,但是这里由于需要较高的时效性,不再进行kmeans、高斯等聚类。而是本方案采用创新的minhash技术,采用多个hash函数对特征进行hash,每个hash函数对每个特征都可以产生一个hash值,为了提升hash后相似的特征还相似,需要提高hash函数的个数来保持相似性。因此这部分可以根据时效性和准确率进行hash函数的选择。更多的hash函数可以保持相似的特征,hash后还继续相似。然后获取根据对特征hash后的结果进行分组聚类,同时每个类cluster抽取等量的客户端,这样每次抽取的客户端更加分散,保持了数据的多样性,提升了收敛速度。
[0092]
假设:总计有n个客户端,每次抽样n客户端,m是聚类个数。
[0093]
每个cluster抽样:cn=n/m+1,忽略每个cluster内客户端的数据,每个cluster内抽样相同样本,这样避免cluster内按照客户端数量随机采样导致和全局采样一致的状态。
[0094]
具体地,服务器按照如下公式将接收到的各个客户端的本地更新参数进行加权平均聚合以产生新的全局模型参数w
t
:
[0095][0096]
其中,n表示全部客户端样本量之和,nk表示第k个客户端的样本量,表示第k个客户端的本地更新参数的权重,代表第k个客户端的本地更新参数,t表示迭代次数,f(x)为代表模型准确率的复合函数。
[0097]
在上述实施例的基础上,如图6所示,本发明还提出一种改进的联邦加权聚合系统,包括:
[0098]
聚类模块,用于客户端发送训练后的人类活动识别模型到服务器端,服务器端对客户端上传的人类活动识别模型进行minhash聚类;
[0099]
模型准确率评估模块,用于服务器端基于聚类后的客户端上传的人类活动识别模型进行等量抽样;结合服务器端的人类活动无标签数据,利用选举机制获取抽样的每个客户端上传的人类活动识别模型的准确率,并对模型准确率进行评估,从而获取参与服务器端全局模型聚合的客户端上传的人类活动识别模型,进而得到服务器端模型聚合时的准确率;
[0100]
联邦加权聚合模块,用于把得到的参与全局模型聚合的客户端上传的人类活动识别模型和服务器端模型聚合时的准确率一起加权到服务器端全局模型的模型聚合更新中,得到联邦加权聚合后的人类活动识别模型,并基于得出的人类活动识别模型进行人类活动识别。
[0101]
进一步地,还包括:
[0102]
模型下发模块,用于服务器端选择初始化的人类活动识别模型,并下发模型给各个客户端;
[0103]
模型训练模块,用于客户端接收初始化的人类活动识别模型,结合本地存储的人类活动数据和模型参数训练本地模型更新,得到训练后的人类活动识别模型。
[0104]
进一步地,按照如下方式对模型准确率进行融合:
[0105]
按照下式对每个模型的准确率进行评估,以判断模型的准确率是否符合条件,能否参与到服务器端模型的聚合中:
[0106][0107]
其中f(x)为代表模型准确率的复合函数,用于对模型的准确率进行激活;r为准确率阈值;α为超参数,用于保证函数的连续性以及可导性;
[0108]
得出评估后的每个模型的准确率。
[0109]
综上,本发明引入了对加入聚合客户端的抽样机制,提升人类活动识别模型聚合速度:
[0110]
传统fedavg的方式是每轮次聚合时候随机进行抽样,这样存在一个非常重要的问题,就是抽样数据分布不均匀,在迭代过程中可导致模型更大震荡,收敛速度大大降低。因为随机抽样再聚合时候会出现更多相似的客户端,这样相似的客户端导致本轮训练数据和整体并不完全相符,因此选择更加合适的客户端参与人类活动识别联邦模型聚合可以提高服务器端模型聚合效率。所以本发明提出一种先聚类再选择客户端模型的有效方法,该方案首先根据客户端上传的人类活动识别模型进行聚类。最终达到相似客户端模型在一个类cluster效果,然后在每个类内进行等量的抽样,这样就保证客户端数据的多样行,在模型训练时候减少了模型震荡,提升了训练效率。
[0111]
本发明引入server端模型准确率评估机制,提高人类活动识别模型聚合的准确率:
[0112]
引入了客户端数据质量权重后,模型的漂移会有所减少,为了进一步解决该问题。引入server端,首先客户端上传人类活动识别模型到sever端后,server端会收集一些没有标签的数据,各个客户端的人类活动识别模型会对这些没有标签的数据进行预测,最后根据所有客户端人类活动识别模型预测的结果进行投票选举,从而获得每一个模型的准确率,进一步减少模型漂移。
[0113]
本发明在服务器端使用无标签数据测试每个客户端模型的准确率,同时在聚合前引入模型准确率机制,通过不同客户端模型的准确率建模。使得在最终聚合阶段获得更准确的模型。
[0114]
本发明避免了随机抽样带来的模型收敛慢和数据随机化的问题,采用先聚类后在每个cluster内抽样等量的客户端模型,加快了模型收敛的速度。同时在聚类时候为了提升效率,避免了使用kmeans、高斯等时间复杂度较大的算法,而是创新的采用了minhash的方法,对每个客户端进行minhash产生标签矩阵,然后对标签矩阵中的每行特征进行分组,就完成了聚类工作,最后在每个类内抽取等量的客户端。
[0115]
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人
员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1