一种基于新词识别的化工领域分词方法
1.本发明属于数据处理技术领域,尤其涉及一种基于新词识别的化工领域分词方法。
背景技术:
2.分词是中文自然语言处理中最基础的任务。到目前为止,已有的分词研究成果仍不能完全满足应用的需要。在一些专业关键领域问题上仍然值得继续探讨,如分词的规范性、切分歧义、未登录词识别、分词与理解的先后等。
3.目前,普遍的新词识别方法为基于规则的方法和基于统计的方法。基于规则的方法以现有的词典作为基础结合一定的人工规则进行分词,对于新词的识别能力很低;基于统计的方法通常需要一个很大规模的语料库,在语料库不充足的情况下,对于新词识别的准确率会很低。目前主流的方法时采用统计和规则相结合的方法,发挥两个方法各种的优势从而提高新词的识别效果。现有的分词任务在通用领域已经取得了良好的效果,然而,由于化工领域词汇的特殊性,还不能完全满足针对化工领域分词的需要。
技术实现要素:
4.发明目的:本发明的目的在于提供一种基于新词发现的化工领域分词方法。该化工领域分词方法分为两个模块,分别是新词发现模块和分词模块。所述新词发现模块为通过结合内部凝固度、聚集性规则以及新词识别模型来构建新词集合;所述分词模块为通过所述的新词集合对一次分词结果进行细化分词,得到最后的分词结果。
5.技术方案:本发明的一种基于新词发现的化工领域分词方法,采用以下步骤实现对化工领域语料的分词:
6.s1、对获取的中文化工文本进行预处理操作获得切分词语集;
7.s2、针对各切分词语,获取切分词语的内部凝固度,根据所述内部凝固度和预设的凝固度阈值,从所述多个切分词语集中获取预设数目的切分词语,采用符合聚集性规则构建候选新词集;
8.s3、在所述候选新词集中随机选取l条数据作为训练集的初始规模,每次按照一定的增量增加训练集的规模,将候选新词语的统计量特征作为自变量进行训练新词识别模型,当模型的准确率浮动范围基本不变时停止训练;
9.s4、将所述候选新词集中除去训练集以外的候选新词语输入模型,进行进一步的成词判断,返回新词集合;
10.s5、将nlpir分词结果作为一次分词结果,利用s4得到的新词集合对所述分词结果进行细化分词,得到分词结果。
11.进一步地,上述步骤s1中,对文本数据进行预处理操作包括以下步骤:当遇到空格、英文字母、数字、停用词以及标点符号时将文本分割,形成切分词语集。
12.进一步地,上述步骤s2中,构建新词识别样本包括以下步骤:
13.s21、将s1中得到的语料从左至右扩展候选词语,计算候选词语与右邻接字的增强信息值,若超过阈值便继续向右扩展,否则从上一位置切分,下一字串的截取位置从此位置作为起始点,继续向右扩展,形成候选未登录词集,本发明用词语本身出现概率与该词语所有二分方法中两个组成部分独立出现的概率乘积比值的最小值来表示某一词语的增强信息值,采用以下公式计算增强信息值;
[0014][0015]
其中c表示候选词语,len(c)表示词c的长度,c[0:i],c[i:len(c)表示该候选词所有二分方法中两个组成部分。
[0016]
s22、根据所述增强信息值和预设的阈值,从所述多个切分词语集中获取预设数目的切分词语作为候选未登录词集;
[0017]
s23、对s22得到的候选未登录词集通过word2vec模型得到词向量;
[0018]
s24、基于聚集性规则,在s23中得到的候选未登录词集中挖掘由2到3个子词组成的新候选未登录词,采用余弦相似度对组合成新候选录词的相邻子词相似度进行比较,过滤掉相似度低的新候选未登录词,得到候选新词集。
[0019]
进一步地,上述步骤s3中,训练新词识别模型包括以下步骤:
[0020]
s31、从s2中得到的候选新词集中随机选取k条数据作为训练集、p条数据作为检验集;
[0021]
s32、选取l条数据作为训练集的初始规模,按照增量δ增加训练集的规模,当训练的模型在验证集上的准确率浮动范围基本不变时,模型停止训练;
[0022]
s33、按照模型平衡时的规模在候选新词集中随机抽出数据作为训练集,训练新词识别的神经网络模型;
[0023]
s34、将所述候选新词集中除去训练集以外的候选新词语分别输入模型,进行进一步的成词判断,得到新词集合。
[0024]
进一步地,上述步骤s5中,利用s4得到的新词集合对所述分词结果进行细化分词,包括以下步骤:
[0025]
s51、利用nlpir分词算法得到一次分词结果,采用从右向左的顺序对所述分词结果的字符串,与s3得到的新词集合匹配,匹配成功将该字符串切分为词;
[0026]
s52、通过上述匹配使得第一次分词结果中的词被重新切分,组成新词,判断是否将当前匹配到新词集合的字符串进行调整,得到最终的分词结果。
[0027]
有益效果:与现有技术相比,本发明具有如下显著优点:
[0028]
(1)本发明提供了一种基于新词识别的化工领域分词方法,通过结合内部凝固度、聚集性规则识别出可能的新词词语,引入新词识别模型来进一步判断出该新词词语是否实际上为正确的新词,进而构建新词集合,使得新词识别的准确率得到显著的提升;
[0029]
(2)本发明在分词模块引入细化分词,通过得到的新词集合对一次分词结果进行调整,进而对中文化工文本实现准确的分词,从而提高了分词结果的准确性。
附图说明
[0030]
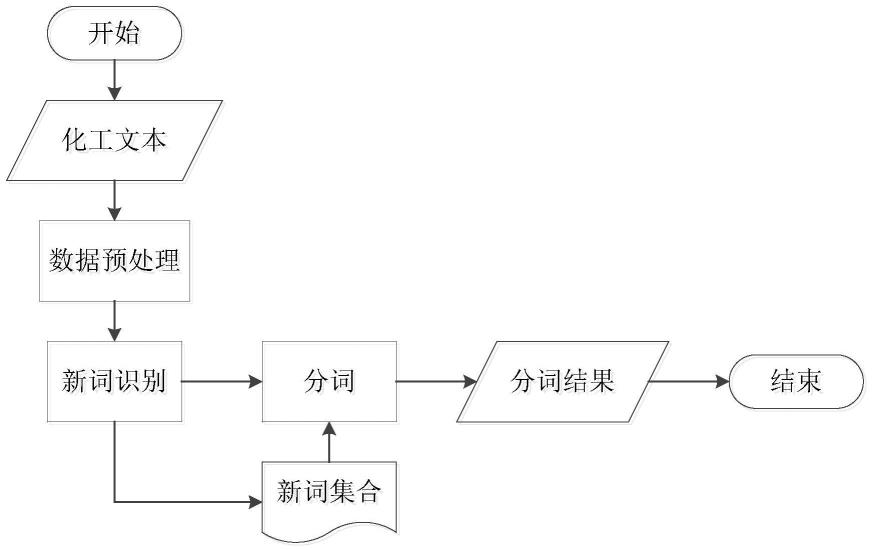
图1为本发明的流程图;
[0031]
图2为本发明新词识别的流程图;
[0032]
图3为本发明分词的流程图。
具体实施方式
[0033]
下面结合附图对本发明的技术方案作进一步说明。
[0034]
如图1所示,本发明的一种基于新词识别的化工领域分词方法,包括以下步骤:
[0035]
s1、对获取的中文化工文本进行预处理操作获得切分词语集;
[0036]
对文本数据进行预处理操作包括以下步骤:当遇到空格、英文字母、数字、停用词以及标点符号时将文本分割,形成汉字组成的语句片段集合。
[0037]
s2、针对各切分词语,获取切分词语的内部凝固度,根据所述内部凝固度和预设的凝固度阈值,从所述多个切分词语集中获取预设数目的切分词语,采用符合聚集性规则构建候选新词集;
[0038]
如图2所示,针对上述得到的语句片段集合,通过结合内部凝固度、聚集性规则以及新词识别模型来构建新词集合。具体步骤如下所示:
[0039]
在上述步骤s2中,通过从左到右扩展的方式,按照设定的最大词长以及计算得到的候选的增强信息值等生成候选未登录词集。99%以上的词语长度都在5字及以内,在化工领域文本上发现5字以上的词也较为常见,为了尽可能识别更多新词,在本发明中设定最大词长为7。具体步骤如下所示:
[0040]
将s1中得到的语料从左至右扩展候选词语,计算候选词语与右邻接字的增强信息值,若超过阈值便继续向右扩展,否则从上一位置切分,下一字串的截取位置从此位置作为起始点,继续向右扩展,形成候选未登录词集,本发明用词语本身出现概率与该词语所有二分方法中两个组成部分独立出现的概率乘积比值的最小值来表示某一词语的增强信息值,采用以下公式计算增强信息值:
[0041][0042]
其中c表示候选词语,len(c)表示词c的长度,c[0:i],c[i:len(c)表示该候选词所有二分方法中两个组成部分。
[0043]
从左到右扩展候选词语可能会将出现的新词不恰当地分割成若干子词,这些子词单独看包含一部分含义,但当几个相邻自此组合在一起时可能是出现的新词,候选词由4个或以上子词组成时,子词之间的语义联系不大,所以本发明基于聚集性规则,挖掘2到3个子词组成的候选未登录词,具体步骤如下所示:
[0044]
对得到的候选未登录词集通过word2vec模型得到词向量。
[0045]
基于聚集性规则,在得到的候选未登录词集中挖掘由2到3个子词组成的新候选未登录词,采用余弦相似度对组合成新候选录词的相邻子词相似度进行比较,过滤掉相似度低的新候选未登录词,得到候选新词集。
[0046]
s3、在所述候选新词集中随机选取l条数据作为训练集的初始规模,每次按照一定
的增量增加训练集的规模,将候选新词语的统计量特征作为自变量进行训练新词识别模型,当模型的准确率浮动范围基本不变时停止训练;
[0047]
s4、将所述候选新词集中除去训练集以外的候选新词语输入模型,进行进一步的成词判断,返回新词集合;
[0048]
本发明实施例中,新词识别模型优选bp网络模型,bp网络模型具有复杂的模式分类能力,融入bp神经网络模型可以过滤候选新词集中的垃圾串,提高新词发现的准确率,为得到满足条件的最小训练集,本发明采用逐渐扩大训练样本量的方法来训练模型,训练模型具体步骤如下:
[0049]
从得到的候选新词集中随机选取k条数据的词语,将每个词语中的频率、概率、增强信息值等作为词语的特征来构建训练集、随机选取p条数据作为检验集。
[0050]
将候选新词集的词语作为候选词语,将词频、增强信息值等特征作为自变量进行建模,选取100条数据作为训练集的初始规模,按照增量100增加训练集的规模,当训练的模型在验证集上的准确率浮动范围浮动不超过1%时,模型停止训练。
[0051]
利用得到的模型对候选新词集除去训练集外的词语进行是否构成新词进行分类判断,将模型中判别为正的词语加入新词集合,得到新词集合。
[0052]
其中,bp网络输入层节点个数为s,隐含层个数为y,输出层节点为c。输出层单元到隐含层单元有s*y条连线,连接权值为w
lo
;隐含层单元到输出层的单元有y*c条连线,连接权值w
op
;
[0053]
输入向量为x=(x1,...,xs);
[0054]
隐含层输入变量为ol=(ol1,...,oly),隐含层输出变量为op=(op1,...,opy);
[0055]
输出层输入变量为sl=(sl1,...,slc),输出层输出变量为sp=(sp1,...,spc);
[0056]
作为本发明优选的实施例,输入层节点个数为8,隐含层节点个数为5,输出层节点为2,分别对应判断是否成为新词的两种结果。
[0057]
s5、将nlpir分词结果作为一次分词结果,利用s4得到的新词集合对所述分词结果进行细化分词,得到分词结果。
[0058]
如图3所示,本发明将nlpir分词结果作为一次分词结果,利用上述得到的新词集合对所述分词结果进行细化分词,得到最终的分词结果,具体步骤如下所示:
[0059]
利用nlpir分词算法得到一次分词结果,采用从右向左的顺序对所述分词结果的字符串,与s3得到的新词集合匹配,匹配成功将该字符串切分为词。例如:“乙烯利对干旱胁迫下草地早熟禾抗氧化酶基因表达的影响。”用nlpir分词,得到:“乙烯/利对/干旱/胁迫/下/草地/早熟/禾/抗氧化/酶/基因/表达/的/影响”,所述新词集合中包含“乙烯利”、“抗氧化酶”、“草地早熟禾”。进行从右向左匹配,调整后的分词结果为:“乙烯利对/干旱/胁迫/下/草地早熟禾/抗氧化酶/基因/表达/的/影响”。
[0060]
通过上述匹配使得第一次分词结果中的词被重新切分,组成新词,判断是否将当前匹配到新词集合的字符串进行调整,得到最终的分词结果,具体步骤如下:
[0061]
如果匹配后词的数目变多或匹配后单字词的数目变多,则不对此次匹配做调整,反之将匹配后的结果作为最终的分词结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1