基于多源域适应字典学习和稀疏表示的脑电情感识别方法
1.本发明涉及eeg脑电技术领域,尤其涉及基于多源域适应字典学习和稀疏表示的脑电情感识别方法。
背景技术:
2.现有的基于eeg的情感识别需要在训练阶段花费大量的带标签数据,一种比较简单而直接的方法是重复利用之前采集的eeg数据训练一个通用分类器,而不考虑个体间的差异。但是,传统的机器学习算法建立在训练数据和测试数据独立同分布的假设之上;而这个假设对情感bci往往难以成立,这是因为eeg信号具有非线性和非平稳性的固有特性,针对相同情绪状态从不同人群中提取的特征集,如脑电通道的谱带功率,并没有表现出很强的相关性;因此,脑电通道谱带功率及其导数的训练和测试数据往往具有不同的分布,也就是说,当同一分类器应用于其他受试者的脑电数据或从各种其他数据集中提取的数据时,性能会显著降低。
3.另外,现有方法中只考虑单个源领域,将所有相关的辅助脑电图数据视为一个源领域,没有涉及多源域学习问题。
技术实现要素:
4.针对现有算法的不足,本发明将多个源域和目标域的eeg样本投影到一个共享的投影子空间中,在共享子空间中学习一个域不变字典,域不变字典的学习准则是最小化类内稀疏重建误差和最大化类间稀疏重建误差,学习到的稀疏特征具有很强的识别能力,并满足类内分散度小和类间分离大的特性;本发明为每个源域分配一个领域适应权重,且在模型学习中自适应学习到每个源领域权重最佳值,能有效避免负迁移的发生;多源域领域适应字典学习和稀疏表示(mda-dlsr)目标函数的求解采取参数交替优化的方法,保证所有的参数同时达到最优解。
5.本发明所采用的技术方案是:一种基于多源域适应字典学习和稀疏表示的脑电情感识别方法包括以下步骤:
6.首先,构建字典学习和稀疏表示的训练样本,使用lc-svd算法得到字典和稀疏表示矩阵的初始值;
7.dlsr是为无监督学习提出,其优化问题是在词典空间中最小化原始信号与重构信号之间的重构误差,设训练集x=[x1,x2,...,xn]∈rm×n,其中,m和n分别表示数据的维数和样本数,通过优化经验函数dlsr使用字典d∈rm×k的有限原子对数据进行分解,a=[a1,...,an]∈rk×n是稀疏系数,l()表示损失函数,k是字典原子数;在dlsr中,原始信号和重构信号之间的重构误差均方是最常见的损失函数,通常由l1范数将稀疏性引入目标函数,因此,这一思想表示成:
[0008]
[0009]
为了避免d的值任意大,从而避免ai的值任意小,需要对字典原子或稀疏系数进行额外的约束,以限制其l2范数的值。式(1)中添加该约束后表示为:
[0010][0011]
其中,t0表示字典原子中非零个数阈值,显然,原始dlsr是无监督学习,其在优化问题中没有考虑类别的标签信息;因此,在监督学习中,需要将标签类别信息加入到目标式中,由此,产生了一系列有监督dlsr方法,标签一致性lc-svd算法使用线性分类器来构建模型:
[0012][0013]
其中,w∈rc×k是分类参数,t0表示字典原子的阈值,α是正则化参数,d表示字典,a表示稀疏表示矩阵。
[0014]
然后,使用投影矩阵将源域投影到低维子空间,计算源域上的类内稀疏重建误差和类间稀疏重建误差;
[0015]
然后,使用投影矩阵将目标域投影到低维子空间,计算目标域上的类内稀疏重建误差和类间稀疏重建误差;
[0016]
然后,根据最小化类内稀疏重建误差和最大化类间稀疏重建误差的构建判别项,并计算字典学习和稀疏表示的目标函数,采用参数迭代优化方法对目标函数求解;
[0017]
最后,通过未标注的测试样本,根据得到的最优投影矩阵和字典,计算测试样本类别。
[0018]
进一步的,具体步骤包括:
[0019]
步骤一、构建字典学习和稀疏表示的训练样本,从deap数据集采集eeg信号,构成源域样本集,设sc个源域样本集si={1,2,...,sc}和一个目标域且每个领域的数据都不重叠,均带有类别标签,sc个源域和目标域的特征空间一致,但它们的边缘概率分布和条件概率分布可以不同,第si个源域x
si
和目标域x
t
中的样本分别表示为和样本的个数分别是n
si
和n
t
,全部源域样本的个数为ns,
[0020]
步骤二、使用投影矩阵p
si
∈rm×d,将第si个源域x
si
投影到低维子空间,基于字典学习和稀疏表示理论计算类内稀疏重建误差:
[0021][0022]
其中,表示x
si
中第c类的第j个样本,是的稀疏表示,d表示字典,是源域x
si
上的类内散度,函数返回的稀疏表示系数的k维映射向量;
[0023]
通过下式计算得到
[0024][0025]
其中,函数返回的稀疏表示系数的k维映射向量,的稀疏表示中第c类系数保留原值的,其它值均为零,tr(
·
)表示矩阵的秩操作。
[0026]
投影空间中第si个源域x
si
上,基于字典学习和稀疏表示理论计算类间稀疏重建误差:
[0027][0028]
其中,是源域x
si
上的类间散度,函数返回的稀疏表示系数的k维映射向量;
[0029]
通过下式计算得到
[0030][0031]
其中,函数返回的稀疏表示系数的k维映射向量,与不同的是,其对应的的稀疏表示中第c类系数为零的,其它值保留。
[0032]
步骤三、使用投影矩阵p
t
∈rm×d,将目标域x
t
投影到低维子空间,目标域x
t
上的类内稀疏重建误差和类间稀疏重建误差计算式如下:
[0033][0034]
其中,是目标域x
t
上的类内散度,通过下式计算得到
[0035][0036]
其中,是目标域x
t
上的类间散度,
[0037]
在共享子空间中通过公共字典来学习多源域和目标域eeg数据的共有判别知识,一方面,多源域eeg信号的稀疏表示和分类器在子空间中是独立的;另一方面,域不变字典用于在各个域之间建立潜在的联系,将判别信息从多源域传递到目标域;
[0038]
步骤四、根据最小化类内稀疏重建误差和最大化类间稀疏重建误差构建判别项保证了模型的判别能力,为了有效利用多个源领数据的判别知识,同时避免负迁移,mda-dlsr赋予每个源域自适应权重,基于以上思想,mda-dlsr的目标函数表示为:
[0039][0040]
其中,向量λ=[λ1,λ2,
…
,λ
sc
]是权重向量,元素λ
si
表示第si个源领域在目标函数中的重要程度,r(r》1)是平衡指数;在传统的权重求解问题中,λ的值需人工设置,常通过网络搜索法获得最优,但mda-dlsr中λ的值作为一个模型参数自适应得到最优值;
[0041]
为简化目标函数的计算,将式(10)中两项的分子式和分母式进行合并,同时,定义矩阵式(10)可以重写为:
[0042][0043]
进一步的,公式(11)是一个非凸问题,涉及三个参数{p,d,λ},采用参数迭代优化方法进行求解,
[0044]
进一步的,参数迭代优化方法进行求解,具体包括:
[0045]
1、固定参数{d,λ},求解p,为了避免过度拟合,将一个正则化项加入到式(11)的分母中,根据跟踪比优化(trace ratio optimization,tro)策略,对于投影矩阵p,必有一个最大值q
*
,使得:
[0046][0047]
其中,μ为一个正数;
[0048]
因此得到:
[0049]
tr(p
t
ap)-q
*
tr(p
t
(b+μi)p
t
)≤0
ꢀꢀꢀ
(13)
[0050]
经过整理,式(13)进一步写成以下形式:
[0051]
tr(p
t
(a-q
*
(b+μi)p)≤0
ꢀꢀꢀ
(14)
[0052]
为求解式(14),定义以下关于q的函数f(q):
[0053][0054]
f(q)具有两个性质:(1)f(q)是一个递减函数;(2)f(q)=0当且仅当q=q
*
,也就是说,q的最优值总是存在的,通过迭代交替更新p和q能得到相应的最优解;因此,对(15)进行q的一阶求导,可得f'(q)=-tr(p(q)
t
(b+μi)p(q)),令f'(q)=0,得到q的极值,考虑目标函数关于矩阵p的约束p
t
p=i,p的最优值可通过下式求解:
[0055][0056]
显然,式(16)是一个特征值分解问题:
[0057]
(a-qb-qμi)p=γp
ꢀꢀꢀ
(17)其最优解是求解式(11)得到的关于p的前d个最大特征值。
[0058]
2、固定参数{p,λ},求解d,目标函数关于每个类别的子字典表示为:
[0059][0060]
根据公式(5)和(7),以及矩阵a和b的定义,矩阵ac和bc分别对应矩阵a和b在第c类样本上的运算结果;
[0061]
子字典dc采用梯度上升法进行求解,dc=dc+αj'(dc),其中,α是学习率,j'(dc)则可由下式计算得到:
[0062][0063]
3、固定参数{p,d},求解λ,在式(10)上引入拉格朗日乘子β并忽略常数项,得到下式:
[0064][0065]
λ的极值的必要条件为同时考虑得到:
[0066][0067]
由式(21)得到:
[0068][0069]
将上式化简,并代入式(10),得λ
si
的解析解:
[0070][0071]
步骤五、对于一个未标注的测试样本z,根据得到的最优投影矩阵p
t
和字典d,使用下式计算其在第j类上的类别:
[0072][0073]
其中,是第j类子字典dj的伪逆;
[0074]
最后,使用投票法来得到样本z的类标签,即其中,δj表示第j类的票数。
[0075]
本发明的有益效果:
[0076]
1、通过多个源领域和目标领域寻找一个投影子空间,在子空间中通过共有字典建立多个源域和目标领域之间的桥梁,为充分利用源领域数据的识别能力,共有字典的学习准则是最小化类内稀疏重建误差和最大化类间稀疏重建误差;同时,通过源领域自适应地权重学习可以有效避免负迁移的发生;
[0077]
2、在真实脑电情感识别数据集deap上,对比本发明方法与现有技术的四种方法,结果表明本发明方法在deap数据集上的arousal和valence识别精度最高。
附图说明
[0078]
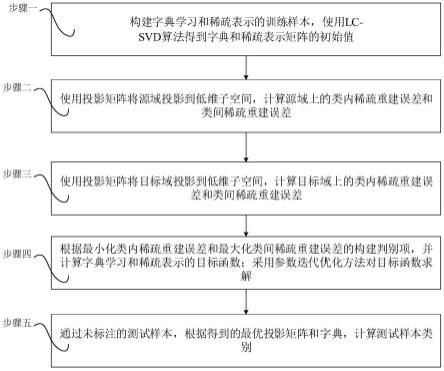
图1是本发明的基于多源域适应字典学习和稀疏表示的脑电情感识别方法流程图;
[0079]
图2是本发明的方法与现有方法在32名个体上的arousal识别精度比较;
[0080]
图3是本发明方法与现有方法在32名个体上的valence识别精度比较;
[0081]
图4是本发明的参数m和d在deap数据集上的arousal识别精度;
[0082]
图5是本发明的参数m和d在deap数据集上的valence识别精度。
具体实施方式
[0083]
下面结合附图和实施例对本发明作进一步说明,此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0084]
使用deap数据集验证本发明方法有效性,deap数据集来自英国伦敦玛丽皇后大学等4所大学,记录了32名志愿者在观看40段音乐视频时的eeg信号和视频信号,对每位志愿者进行了40次数据采集,每次采集过程中播放一段特定的63秒视频,这些视频由参与者根据唤醒(arousal)和效价(valence)等指标进行评分,评分范围为1-9;实验中采用的类别标签设定为:将评分划分成2个带有阈值5的二元分类问题:高/低arousal和高/低valence(低:≤5,高:》5);eeg信号按照国际10/20系统放置32个电极采集得到;数据预处理时将eeg数据下采样至128hz,去除信号的伪影并删除3秒基线数据,并应用4.0-45.0hz的频率实施带通滤波;在eeg信号的众多特征提取方法中,微分熵(differential entropy,de)被认为能反映eeg特征的连续随机变量的复杂性;对于固定长度的eeg片段,de特征可以等价于特定频带内的对数能量谱;实验使用256采样点的短时傅里叶变换和1s的非重叠窗口来提取eeg信号的五个频带(δ:1-3hz,θ:4-7hz,α:8-13hz,β:14-30hz,γ:31-50hz);然后计算每个频带的de特征,由于每个频带信号有62个通道,一个样本可提取310维的de特征。
[0085]
如图1所示,一种基于多源域适应字典学习和稀疏表示的脑电情感识别方法包括以下步骤:
[0086]
首先,构建字典学习和稀疏表示的训练样本,使用lc-svd算法得到字典和稀疏表示矩阵的初始值;
[0087]
然后,使用投影矩阵将源域投影到低维子空间,计算源域上的类内稀疏重建误差和类间稀疏重建误差;
[0088]
然后,使用投影矩阵将目标域投影到低维子空间,计算目标域上的类内稀疏重建误差和类间稀疏重建误差;
[0089]
然后,根据最小化类内稀疏重建误差和最大化类间稀疏重建误差的构建判别项,
并计算字典学习和稀疏表示的目标函数;采用参数迭代优化方法对目标函数求解;
[0090]
最后,通过一个未标注的测试样本,根据得到的最优投影矩阵和字典,计算测试样本类别。
[0091]
进一步的,具体步骤包括:
[0092]
步骤一、构建字典学习和稀疏表示的训练样本:
[0093]
步骤二、使用投影矩阵p
si
∈rm×d,将第si个源域x
si
投影到低维子空间,基于字典学习和稀疏表示理论计算类内稀疏重建误差:
[0094]
步骤三、使用投影矩阵p
t
∈rm×d,将目标域x
t
投影到低维子空间,目标域x
t
上的类内稀疏重建误差和类间稀疏重建误差
[0095]
步骤四、根据最小化类内稀疏重建误差和最大化类间稀疏重建误差的构建判别项保证了模型的判别能力,mda-dlsr赋予每个源域自适应权重,构建mda-dlsr的目标函数;
[0096]
步骤五、对于一个未标注的测试样本z,根据得到的最优投影矩阵p
t
和字典d,使用下式计算其在第j类上的类别。
[0097]
mda-dlsr方法的训练步骤表示如下:
[0098][0099]
为验证所提方法的性能,实验与两类方法进行了比较:一类是基线方法:高斯核支持向量机(support vector machine,svm)和标签一致lc-ksvd方法;另一类是领域适应方
法:自适应子空间特征匹配(adaptive subspace feature matching,asfm)方法,最大独立域自适应(maximum independence domain adaptation,mida)方法,稳健主成分分析(robust principal component analysis,rpca);具体的参数设置如下:
[0100]
高斯核的核参在网格{10-3,10-2,...,103}中搜索,正则化参数在网格{2-6,2-5,...,26}中搜索;lc-ksvd的字典原子数设置为训练样本个数的1/3;mida的投影空间维度在网格{20,30,...,100}中搜索;asfm的阈值参数设置为0.45;rpca的平衡参数设置为样本数和特征数最大值的平方根;本发明方法的子空间维度是通过搜索网格{20,30,...,100}来确定的;每个类的原子数在{10,15,20,25,30,35}中选择,实验中源领域和目标领域的设置策略采取留一法,即数据集中的每个个体均可作为目标领域,其它的个体均作为源域。因此,deap数据集上进行了32轮实验,其中31名个体作为多个源域,因为训练集样本较多,实验中在每名个体样本中随机选择1/2数量的eeg数据进行训练,目标域中随机选择20个样本作为训练集,剩余的目标域样本作为测试集;这一实验过程进行了10次,记录了每个方法的分类精度。所有算法均在matlab 2019a中实现。
[0101]
对比实验:
[0102]
实验比较了mda-dlsr方法在deap数据集上的arousal和valence的识别精度;各方法在32名个体上的平均识别精度如表1所示。为了充分显示各方法在每名个体上的具体结果,图2-3显示了各方法在32名个体上的arousal和valence的识别精度;从实验结果可以看到:
[0103]
1)首先,基线分类方法svm和lc-ksvd在deap数据集上的跨个体eeg情感识别任务中无法获得令人满意的arousal和valence识别精度;因为本质上它们并不是为了解决领域适应问题,svm和lc-ksvd在模型将所有的源域数据和目标域训练数据混合在一起,此时,由于不同领域数据分布上的差别使得源领域对于目标域上数据识别的辅助效果是有限的。
[0104]
2)其次,在对比的领域适应方法中,本发明方法比使用其它对比的方法表现更好,主要原因是从多个源领域习得的共享字典可以使用更多的判别知识来辅佐目标域上分类器的建立,而且每个源领域可以自适应地学习到对应的权重,可以有效防止负迁移的发生,保证迁移学习的效果,此外,mda-dlsr方法的参数迭代学习策略保证了所有参数同时达到最优解。
[0105]
3)从表1结果可以看出,mda-dlsr方法不仅arousal和valence的识别精度是最优的,其对应的标准差也是较小的,说明方法具有较好的稳定性。而所有方法中,非领域适应方法svm和lc-ksvd的标准差较大,说明这2个方法在处理跨个体eeg情感识别任务易发生过拟合的现象。
[0106]
4)从图2-3结果可以看出,32名个体的arousal和valence识别精度有较大的区别,有些个体的识别精度达到80%以上,有些个体的识别精度略高于50%,这也许是因为在eeg信号采样中受到外界和自身干扰,获得的eeg数据质量较低。
[0107]
表1 deap数据集的arousal和valence的识别精度(标准差)比较
[0108][0109]
参数分析
[0110]
本发明方法中需要寻优的参数有平衡指数γ、子空间的维数m和字典原子个数d;其中,平衡指数γ的寻优范围是{1,1.5,...,3},子空间的维数m的寻优范围是{10,20,...,100}和字典原子个数d的寻优范围是{30,40,...,120};表2列出了参数γ在deap数据集上的arousal和valence识别精度;图4-5分别显示了参数m和d在deap数据集上的arousal和valence识别精度,从实验结果可以看出:
[0111]
(1)平衡指数γ的作用是调节各源域在目标函数的权重,因为各源域的权重是介于[0,1]之间的实数,γ的值越小,各源域的权重比就越大;相反,γ的值越小,各源域的权重比就越接近;根据表2中的结果,平衡指数γ对应的arousal和valence识别精度的变化是温和的,实验中可设置γ=2。
[0112]
表2参数γ在deap数据集上的arousal和valence识别精度
[0113][0114]
(2)投影空间的维数m和字典原子个数d对mda-dlsr方法的性能起到决定性作用,不同m和d值对应不同的arousal和valence识别精度;从图4-5可以看出,mda-dlsr方法在m和d较小时就可以得到较高的arousal和valence,当m大于50且d大于80时,mda-dlsr方法的性能可以达到稳定;根据图4-5的结果,实验可以设置m和d值分别设置为60和80。
[0115]
本发明方法为多个源领域和目标领域寻找一个投影子空间,在子空间中通过共有字典建立多个源域和目标领域之间的桥梁,为充分利用源领域数据的识别能力,共有字典的学习准则是最小化类内稀疏重建误差和最大化类间稀疏重建误差。同时,通过源领域自适应地权重学习可以有效避免负迁移的发生,在真实脑电情感识别数据集deap上的实验证明了本发明方法的有效性。
[0116]
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1