基于边缘特征增强的任意形状文本检测方法
1.本发明涉及图像处理技术领域,尤其涉及任意场景的一种基于边缘特征增强的任意形状文本检测方法。
背景技术:
2.传统场景文本检测方法主要使用了文本区域的形状、边缘等特征对文本区域进行检测,而相较于传统的检测方法,基于深度学习的检测方法能够提取到与文本对象更相关、更深层的特征,尤其是多尺度的复杂特征,由于场景文本检测的精度与文本区域的特征提取密切相关,基于深度学习的检测方法往往能够得到更高的文本检测精度。
3.自然场景中的文本对象通常具有不同的形状,在对文本对象的检测过程中,准确地检测任意形状文本是提高文本检测精度的关键。因此,在基于回归和基于分割的两种文本检测方法的基础上,很多研究工作对于任意形状文本对象检测的方法进行相应改进。在基于回归的检测方法方面,相关研究通常对于所回归的文本包围框进行改进,一个常见的方法是改进文本包围框的表示方式,另一种方法是根据文本区域特征对初步得到的文本框使用子网络进行调整;而在基于语义分割的检测方法方面,主要通过在进行分割时增加不同类别像素之间(各文本实例像元之间以及文本实例像元同背景像元之间)的区分度以提高文本区域检测的精度,其中一种改进方法通过在已分割的文本实例核心区域基础上逐步扩张区分度高的像元或区域以获得准确的文本实例,一些方法将像元特征嵌入到一个新的空间以增加实例像元的内聚性。
4.在基于深度学习的模型中,目标边缘信息的提取与像元特征的提取通常是密切相关的,对目标边缘信息的关注往往能够帮助模型提取出更易于检测边缘区域的像元特征。同时,文本区域的边缘检测结果与骨干网络获取的像元特征影响着文本检测精度。因此,在基于深度学习的文本检测方法中通过引入更多边缘信息的方式可以更好地从原始图像中提取同文本边界相关的像元特征,从而增加不同文本实例之间以及文本实例同背景之间的区分度,并进一步提高任意文本区域的检测精度。
5.本发明为进一步提高任意形状场景文本检测的精度,提出了基于边缘特征增强的任意形状文本检测方法。
技术实现要素:
6.本发明提供了一种基于边缘特征增强的任意形状文本检测方法,通过在特征提取过程中对边缘特征进行增强以提升场景文本检测的精度。
7.本发明的具体技术方案包含以下步骤:
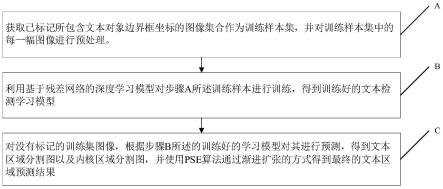
8.步骤a:获取所包含文本对象边界框标记的图像集合作为训练样本集,并对训练样本集中的每一幅图像进行预处理;
9.步骤b:利用基于残差网络的深度学习模型对步骤a所述训练样本进行训练,得到训练好的文本检测学习模型;
10.步骤c:对没有标记的训练集图像,根据步骤b所述的训练好的学习模型对其进行预测,得到文本区域分割图以及内核区域分割图,并使用pse算法通过渐进扩张的方式得到最终的文本区域预测结果。
11.步骤a所述的对训练样本集中的每一幅图像进行预处理,具体为:
12.步骤a1、使用多边形裁剪算法得到原文本区域标记的收缩文本框和扩张文本框;
13.步骤a2、根据原文本框标记得到完整文本区域标记分割图,根据收缩的边界框得到内核区域标记分割图,根据收缩文本框和扩张文本框得到文本边缘区域标记分割图;
14.步骤a3、将训练样本中的图像随机剪切成640
×
640像元固定大小的图像,之后在水平方向进行随机翻转并进行随机缩放和随机选择,并进行归一化处理;
15.步骤b所述基于残差网络(resnet)的深度学习模型具体为:
16.步骤b1、将所述步骤a中预处理过的样本图像作为resnet的输入,得到resnet特征图fr,并使用特征金字塔(fpn)进行初步的特征融合得到特征f
f1
;
17.步骤b2、浅层特征增强模块首先使用卷积处理特征f
f1
获取各像元在更大尺度上的深层特征fh,将深层特征fh从融合后的特征f
f1
中以相减的方式剥离得到尽可能保留更多浅层信息的特征f
l
。随后,将特征f
l
同fpn最高分辨率的特征f
p2
进行拼接和卷积以增强浅层特征得到特征f
le
。最后将特征f
le
与特征fh逐像元相加作为后续文本检测的图像特征fe;
18.步骤b3、将特征fe通过不同的卷积处理以构建面向文本实例与其边缘的特征,得到文本区域特征f
t
和文本边缘区域特征fb。为了突出最具有代表性的特征并抑制无关特征,分别对特征f
t
和fb使用注意力机制模块处理以对不同特征赋予不同的权重,其中权重的获取是通过se(squeeze and extract)通道注意模块完成。经过注意力机制处理的特性f
t
和fb再通过拼接和两次卷积后进行融合以得到同时包含两者信息的混合特征fm;
19.步骤b4、在完整文本实例检测分支中,首先根据特征f
t
使用先卷积后激活的方法得到文本实例区域分割结果。随后采用自适应二值化方法过滤初始分割结果中被错误分割的像元。其中首先使用特征fm得到逐项元调整阈值t,然后再使用二值化方法将初始分割结果和阈值t进行融合从而得到最终的文本实例区域分割结果,具体公式为:其中b为文本分割图,t为文本阈值;
20.步骤b5、在文本实例边缘检测分支中,首先根据特征fb使用先卷积后激活的方法获得初始边缘区域分割结果。随后在初始分割结果基础上融合了混合特征信息以及部分文本实例区域初始分割结果信息。对于混合特征信息也采用了先卷积后激活的方法得到每个像元归属于边缘区域的概率信息。对于文本实例区域初始分割结果则采用rpcnet中的方法,从计算空间梯度的方式从文本实例区域初始分割结果中得到边缘信息,具体公式为:其中σ是激活函数,pool
3*3
为内核大小为3的自适应平均池化操作,m为text map。最后将三个信息进行拼接、卷积和激活后得到最终的文本边缘预测结果;
21.步骤b6、为解决训练过程中存在着正负样本不均衡问题,首先使用ohem方法根据正负样本比例将分割结果和实际标签进行掩膜处理,得到掩膜后的结果为s和g,再使dice损失函数计算损失,具体公式为:其中s
x,y
和g
x,y
分为分割
结果和实际标签掩膜后的像素值。
22.步骤c所述的渐进扩展算法:
23.步骤c1、对最小尺度的内核分割图s1求连通区域得到不同文本实例的核心区域;
24.步骤c2、在s1各核心区域的基础上合并邻域内的文本像素得到s
′2,其中,合并方式为在核心区域的边缘像素中,根据其在s2中的分类结果,将属于文本像素的四邻域像素扩展合并到s1相应的各核心区域中。最后,使用同样的扩展合并操作依次得到s
′3....s
′n,并将s
′n作为最终的文本预测结果。
附图说明
25.图1为本发明的一种基于边缘特征增强的任意形状文本检测方法的实施例的流程;
26.图2为本发明的一种基于边缘特征增强的任意形状文本检测方法的完整模型的示意图;
27.图3为本发明的一种基于边缘特征增强的任意形状文本检测方法的浅层特征增强模块的示意图;
28.图4为本发明的一种基于边缘特征增强的任意形状文本检测方法的分支特征融合模块的示意图;
29.图5为本发明的一种基于边缘特征增强的任意形状文本检测方法的完整文本区域检测分支以及文本边缘区域检测分支的示意图;
具体实施方式
30.如图1所示,本实施例所述一种基于边缘特征增强的任意形状文本检测方法,所述方法包括以下3个步骤:
31.步骤a:获取所包含文本对象边界框标记的图像集合作为训练样本集,并对训练样本集中的每一幅图像进行预处理;
32.步骤b:利用基于残差网络的深度学习模型对步骤a所述训练样本进行训练,得到训练好的文本检测学习模型;
33.步骤c:对没有标记的训练集图像,根据步骤b所述的训练好的学习模型对其进行预测,得到文本区域分割图以及内核区域分割图,并使用pse算法通过渐进扩张的方式得到最终的文本区域预测结果。
34.如图2、图3、图4、图5所示,所述步骤a所述的对训练样本集中的每一幅图像进行预处理,具体为:
35.步骤a1、使用多边形裁剪算法得到原文本区域标记的收缩文本框和扩张文本框;
36.步骤a2、根据原标记文本框得到完整文本区域标记分割图,根据收缩的边界框得到内核区域标记分割图,根据收缩文本框和扩张文本框得到文本边缘区域标记分割图;
37.步骤a3、将训练样本中的图像随机剪切成640
×
640像元固定大小的图像,之后在水平方向进行随机翻转并进行随机缩放和随机选择,并进行归一化处理。
38.所述步骤b所述基于残差网络(resnet)的深度学习模型具体为:
39.步骤b1、将所述步骤a中预处理过的样本图像作为resnet的输入,得到resnet特征
图fr,并使用特征金字塔(fpn)进行初步的特征融合得到特征f
f1
;
40.步骤b2、浅层特征增强模块首先使用卷积处理特征fo获取各像元在更大尺度上的深层特征fh,将深层特征fh从融合后的特征f
f1
中以相减的方式剥离得到尽可能保留更多浅层信息的特征f
l
;随后,将特征f
l
同fpn最高分辨率的特征f
p2
进行拼接和卷积以增强浅层特征得到特征f
le
;最后将特征f
le
与特征fh逐像元相加作为后续文本检测的图像特征fe;
41.步骤b3、将特征fe通过不同的卷积处理以构建面向文本实例与其边缘的特征,得到文本区域特征f
t
和文本边缘区域特征fb;为了突出最具有代表性的特征并抑制无关特征,分别对特征f
t
和fb使用注意力机制模块处理以对不同特征赋予不同的权重,其中权重的获取是通过se(squeeze and extract)通道注意模块完成。经过注意力机制处理的特性f
t
和fb再通过拼接和两次卷积后进行融合以得到同时包含两者信息的混合特征fm;
42.步骤b4、在完整文本实例检测分支中,首先根据特征f
t
使用先卷积后激活的方法得到文本实例区域分割结果;随后采用自适应二值化方法过滤初始分割结果中被错误分割的像元;其中首先使用特征fm得到逐项元调整阈值t,然后再使用二值化方法将初始分割结果和阈值t进行融合从而得到最终的文本实例区域分割结果,具体公式为:其中b为文本分割图,t为文本阈值;
43.步骤b5、在文本实例边缘检测分支中,首先根据特征fb使用先卷积后激活的方法获得初始边缘区域分割结果;随后在初始分割结果基础上融合了混合特征信息以及部分文本实例区域初始分割结果信息;对于混合特征信息也采用了先卷积后激活的方法得到每个像元归属于边缘区域的概率信息;对于文本实例区域初始分割结果则采用rpcnet中的方法,从计算空间梯度的方式从文本实例区域初始分割结果中得到边缘信息,具体公式为:其中σ是激活函数,pool
3*3
为内核大小为3的自适应平均池化操作,m为text map。最后将三个信息进行拼接、卷积和激活后得到最终的文本边缘预测结果;
44.步骤b6、为解决训练过程中存在着正负样本不均衡问题,首先使用ohem方法根据正负样本比例将分割结果和实际标签进行掩膜处理,得到掩膜后的结果为s和g,再使dice损失函数计算损失,具体公式为:其中s
x,y
和g
x,y
分为分割结果和实际标签掩膜后的像素值。
45.所述步骤c所述的渐进扩展算法具体为:
46.步骤c1、对最小尺度的内核分割图s1求连通区域得到不同文本实例的核心区域;
47.步骤c2、在s1各核心区域的基础上合并邻域内的文本像素得到s
′2,其中,合并方式为在核心区域的边缘像素中,根据其在s2中的分类结果,将属于文本像素的四邻域像素扩展合并到s1相应的各核心区域中;最后,使用同样的扩展合并操作依次得到s
′3....s
′n,并将s
′n作为最终的文本预测结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1