基于BiLSTM-CRF的社会治理领域事件要素命名实体识别的方法与流程
基于bilstm-crf的社会治理领域事件要素命名实体识别的方法
技术领域
1.本发明涉及社会治理技术领域,具体涉及一种基于 bilstm-crf的社会治理领域事件要素命名实体识别的方法。
背景技术:
2.近年来,随着互联网+政务服务的推进,平安、信访件、12345、非警务警情、96345、人民调解等政务数据已成为地方政府了解民情、听取民声、体察民意、汇聚民智的一个重要桥梁。基于自然语言处理技术建立起的智慧政务系统已成为社会治理创新发展的迫切需求与新趋势。命名实体作为nlp的一项重要基础任务,广泛地应用于自动问答、智能检索、热点主题发现等领域,随着开源社区理念的倡导,出现许多开源的实体识别工具和实体识别训练语料,但是依然存在很多缺陷,主要体现在以下几个方面:
3.一、通用领域实体识别工具pyunit-ner仅能识别人民、地址和组织机构三类实体,而且模型训练代码未公开,无法进行新语料添加和重训练;
4.二、公开的细粒度命名实体识别语料cluener涉及的领域为体育、金融、游戏等领域,将其迁移到社会治理云领域难以达到理想的效果;
5.三、政务文本领域的中文机构名中罕见词多、结构复杂,不同领域机构的命名规则差异大,且地址表达式呈现随意性、多样性和歧义性,导致编码规则容易出现错误。
6.由此可见,现有的实体识别方案对于社会治理领域丰富且差异化的底层特征难以进行准确的标记和实体识别,且识别行为容易受限,影响使用效果。
技术实现要素:
7.本发明的目的是针对上述问题,提供一种设计合理、使用效果好的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法。
8.为达到上述目的,本发明采用了下列技术方案:基于 bilstm-crf的社会治理领域事件要素命名实体识别的方法,本方法包括以下步骤:
9.s1、对民众投诉和咨询类数据进行收集并制作与标注实体相关的词典;
10.s2、将标注词典作为多关键词匹配算法wumanber的查询项,对数据进行语料自动标注;
11.s3、将文本数据中的字、词、词性和知识kg特征转化为词嵌入形式的向量,拼接组合成bilstm模型的输入变量;
12.s4、利用bilstm模型提取词语的内在特征后输入到crf层, crf层则计算待标注序列中所有位置的标注得分以及相邻位置标注之间的转移得分,并输出文字形式的序列标注结果。
13.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,在步骤s1中,民众的投诉和咨询类数据通过政务服务网抓取。
14.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,在步骤s2中,语料自动标注的内容包括地理位置及中文人名,其中,职能部门名称从政务公开网站获取,地理位置包括细分为行政区域地名、街巷名、小区、门址以及标志物。
15.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,步骤s3具体包括以下步骤:
16.s21、运行实体识别工具github上的chinese-names-corpus,从标注词典中解析出组织机构名,并借分词和词性标注成企业或个体户名称中的feature和function词典;
17.s22、按照标签类别进行分类并建立映射关系,作为标注的词汇知识库kg;
18.s23、对于待标注的每条数据,通过算法wumanber搜索所有匹配到的关键词及其在文本中的位置信息,并在相应的位置打上对应的tag标签,其余位置则标o标签。
19.5.根据权利要求4基于bilstm-crf的社会治理领域事件要素命名实体识别的方法,字、词、词性以及知识kg四类特征在向量化的过程中序列长度保持一致,且采集jieba分词工具进行分词,在四类特征向量化的过程中,词和词性特征能够进行合并处理。
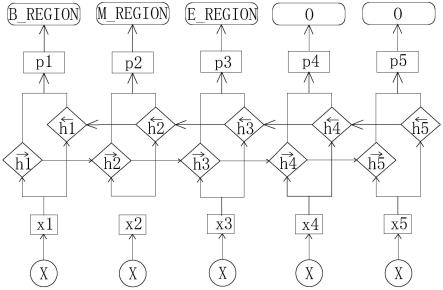
20.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,在步骤s4中,对输出的序列标注结果采用下列方式的实体抽取:
21.s41、合并序列结果中所有以b、m、e开头且具有相同后缀的实体标签,生成新的词序列并抽取部分目标实体;
22.s42、根据地址编码规则和组织机构模式库,采用多关键词匹配算法wumanber进一步对中文地址和组织机构实体提取。
23.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,步骤s41具体包括以下步骤:
24.s411、利用预训练互随机初始化的embedding矩阵将句子中的每个字由one-hot向量映射为低维稠密的charembedding序列(c1,c2,c3,c4,c5),词和词性特征经词嵌入技术转化为wordandpostagembedding序列(t1,t2,t3,t4,t5),知识库kg特征则转化为kgembedding序列(k1,k2,k3,k4,k5);
25.s412、将上述序列对象在embedding维度上进行拼接并生成组合特征(x1,x2,x3,x4,x5),该组合特征在输入下一层之前,设置dropout以缓解过拟合。
26.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,步骤s42具体包括以下步骤:
27.s421、采用双向lstm层自动提取句子特征,将一个句子的组合特征序列作为双向lstm各个时间步的输入,再将正向lstm输出的隐状态序列与反向lstm的在各个位置输出的隐状态进行按位置拼接得到完整的隐状态序列(h1,h2,h3,h4,h5);
28.s422、设置dropout后再接入一个线性层,将隐状态向量映射到k维,k是标注集的标签数,从而得到自动提取的句子特征,记作(p1,p2,p3,p4,p5)。
29.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,crf层进行句子的序列标注,crf层的参数是一个(k+2)
×
(k+2)的矩阵a,其中,a
ij
表示的是从第
i个标签到第j个标签的转移得分,进而在为一个位置进行标注的时候可以利用此前已经标注过的标签,经过crf层运算后输出标签列表 (b-regiob,m-regiob,e-regiob,o,o)。
30.在上述的基于bilstm-crf的社会治理领域事件要素命名实体识别的方法中,对上述步骤识别的结果序列进行社会治理领域实体抽取,合并所有以b、m、e开头且具有相同tag后缀的标签的词块,s标记单独成词、o标签对应的词块合并一起作为不属于任何实体类别的无关短语,根据城市地理信息公共平台地名/地址编码规则的地址表达式规则生成地址模式串并作为算法 wumanber的查询关键词,在生成的词序列结果中找出匹配到的模式串,并在标注序列t
tag
={tag1,tag2,...,tagm}中的位置,同时根据位置角标抽取t
word
={word1,word
2
,...,wordm}中对应位置的词块作为地址实体内容并保存。
31.与现有的技术相比,本发明的优点在于:针对社会治理领域文本的特点,设计了一套专门针对政务文本名的实体识别数据及标注标签,并将bilstm模型及crf算法相结合的实体识别算法应用到社会治理领域事件要素命名实体识别中,该模型具有强大的上下文记忆能力,可以解决未登录词和歧义问题,提高了实体识别的准确率,精准定位事件发生地址、事件涉及的组织机构、人员、事项等,为有关部门决策带来优化便捷,同时为知识图谱等技术拓展奠定基础,使用效果好,提高社会事件的处理效率。
附图说明
32.图1是本发明中的bilstm模型构建图;
33.图2是本发明中的语料自动标注流程图。
具体实施方式
34.下面结合附图和具体实施方式对本发明做进一步详细的说明。
35.如图1-2所示,基于bilstm-crf的社会治理领域事件要素命名实体识别的方法,本方法包括以下步骤:
36.s1、运行实体识别工具pyunit-ner对民众投诉和咨询类数据进行收集并制作与标注实体相关的词典;
37.例如:某事件,通过了解分析,主要包含某某地址、某某机构、某某人名,归纳总结主要涉及地点、机构、人名三类特征,围绕这三类特征,对地点词、机构名称以及人物名称进行划分归类,为机器学习整理出基础词。
38.s2、将标注词典作为多关键词匹配算法wumanber的查询项,对数据进行语料自动标注;
39.s3、将文本数据中的字、词、词性和知识kg特征转化为词嵌入形式的向量,拼接组合成bilstm模型的输入变量;
40.s4、利用bilstm模型提取词语的内在特征后输入到crf层, crf层则计算待标注序列中所有位置的标注得分以及相邻位置标注之间的转移得分,并输出文字形式的序列标注结果。
41.采用bilstm模型及crf层算法进行命名实体序列标注, bilstm模型整合了双向长短时记忆模型和条件随机场模型,能更好地捕捉上下文信息,其中,bilstm模型首先将文本中的字、词转化为向量形式,作为输入变量,利用bilstm模型提取词语的内在特征,向量化
的词语输入类crf层,crf层则充分考虑了待标注序列中所有位置的标注得分以及相邻位置标注之间的转移得分,从而提高标注预测效果。
42.其中,bilstm模型拥有强大的上下文记忆能力,不依赖词典和特征,可以解决未登录词和歧义问题,crf层算法可以通过转移概率矩阵控制序列标注输出,crfcrf层算法标注采用b、m、e、 o为基础标记,根据需要也可以加上单字标记s,其中b代表一个实体的开始,m代表一个实体的中间部分,e代表实体尾字,o代表非实体标记。
43.在步骤s1中,民众的投诉和咨询类数据通过政务服务网抓取。抓取后标注标签tag,另外单字成词的标记符号为s-tag,两字或以上成词需要将标签扩展为b-tag,m-tag和e-tag,tag取值为表1定义的标注类别:
[0044][0045]
表1
[0046]
在步骤s2中,语料自动标注的内容包括地理位置及中文人名,其中,职能部门名称从政务公开网站获取,地理位置包括细分为行政区域地名、街巷名、小区、门址以及标志物。
[0047]
其中,语料自动标注过程为:
[0048]
s21、将整理后的词语集合p={p_1,p_2,
…
,p_r},其中p_i 是由多个中文字符构成的词串,全都作为wumanber算法的查询关键词,并构造wumanber的两张hash表shift和hash;
[0049]
s22、对文本集合t={t_1,t_2,
…
,t_n}中的每条数据,通过 wumanber的两张hash表搜索出所有匹配到的关键词及其在文本中的位置信息,在相应的位置标注合适的tag标签。
[0050]
步骤s3具体包括以下步骤:
[0051]
s31、运行实体识别工具github上的chinese-names-corpus,从标注词典中解析出组织机构名,并借分词和词性标注成企业或个体户名称中的feature和function词典;
[0052]
s42、按照标签类别进行分类并建立映射关系,作为标注的词汇知识库kg;其中,知识库kg特征类型定义如表2所示:根据 kg特征词典查找匹配词在文本中的位置,并在相应位置上赋值其类别标签。
[0053][0054][0055]
表2
[0056]
s33、对于待标注的每条数据,通过算法wumanber搜索所有匹配到的关键词及其在文本中的位置信息,并在相应的位置打上对应的tag标签,其余位置则标o标签。
[0057]
详细地,字、词、词性以及知识kg四类特征在向量化的过程中序列长度保持一致,且采集jieba分词工具进行分词,在四类特征向量化的过程中,词和词性特征能够进行合并处理。
[0058]
在步骤s4中,对输出的序列标注结果采用下列方式的实体抽取:
[0059]
s41、合并序列结果中所有以b、m、e开头且具有相同后缀的实体标签,生成新的词序列并抽取部分目标实体;
[0060]
s42、根据地址编码规则和组织机构模式库,采用多关键词匹配算法wumanber进一步对中文地址和组织机构实体提取。
[0061]
实体抽取分为三步:
[0062]
第一步:对bilstm-crf算法输出的字序列进行合并,即合并所有以b、m、e开头且具有相同tag后缀的标签及其对应的词块词块,并生成新的词序列;
[0063]
第二步:对于复杂地址实体,从标签序列中学习出地址的模式串,采用多关键词匹配算法wumanber进行复杂地址表达式提取;
[0064]
第三步:将算法包装成为对外接口使用,通过输入事件内容,输出地点、人物、机构信息。
[0065]
步骤s41具体包括以下步骤:
[0066]
s411、利用预训练互随机初始化的embedding矩阵将句子中的每个字由one-hot向量映射为低维稠密的charembedding序列(c1,c2,c3,c4,c5),词和词性特征经词嵌入技术转化为wordandpostagembedding序列(t1,t2,t3,t4,t5),知识库kg特征则转化为kgembedding序列(k1,k2,k3,k4,k5);
[0067]
s412、将上述序列对象在embedding维度上进行拼接并生成组合特征(x1,x2,x3,x4,x5),该组合特征在输入下一层之前,设置dropout以缓解过拟合。
[0068]
步骤s42具体包括以下步骤:
[0069]
s421、采用双向lstm层自动提取句子特征,将一个句子的组合特征序列作为双向lstm各个时间步的输入,再将正向lstm输出的隐状态序列与反向lstm的在各个位置输出的隐状态进行按位置拼接得到完整的隐状态序列(h1,h2,h3,h4,h5);
[0070]
s422、设置dropout后再接入一个线性层,将隐状态向量映射到k维,k是标注集的标签数,从而得到自动提取的句子特征,记作(p1,p2,p3,p4,p5)。
[0071]
优选地,crf层进行句子的序列标注,crf层的参数是一个(k+2)
×
(k+2)的矩阵a,其中,a
ij
表示的是从第i个标签到第j个标签的转移得分,进而在为一个位置进行标注的时候可以利用此前已经标注过的标签,经过crf层运算后输出标签列表(b-regiob,m-regiob,e-regiob,o,o)。
[0072]
具体地,对上述步骤识别的结果序列进行社会治理领域实体抽取,合并所有以b、m、e开头且具有相同tag后缀的标签的词块,s标记单独成词、o标签对应的词块合并一起作为不属于任何实体类别的无关短语,根据城市地理信息公共平台地名/地址编码规则的地址表达式规则生成地址模式串并作为算法wumanber的查询关键词,在生成的词序列结果中找出匹配到的模式串,并在标注序列t
tag
={tag1,tag2,...,tagm}中的位置,同时根据位置角标抽取t
word
={word1,word2,...,wordm}中对应位置的词块作为地址实体内容并保存。
[0073]
综上所述,本实施例的原理在于:首先运行实体识别工具pyunit-ner对人名、地址、组织机构名进行采集,并按照表1定位标签进行短语分类并建立短语和其标签的映射关
系,然后采用用多模式匹配算法wumanber进行语料自动标注,其次,合并所有以 b、m、e开头且具有相同tag后缀的标签及其对应的词块词块,所有o标签对应的词块也合并在一起,作为不属于任何实体类别的无关短语,最后生成地址模式串将所有模式串作为查询关键词,采用多关键词匹配算法wumanber找出模式串在标注序列 t
tag
={tag1,tag2,...,tagm}中的位置,并根据位置角标抽取t
word
={word1,word2,...,wordm}对应位置的词块作为地址实体内容并保存。
[0074]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1