一种基于元学习和支持向量描述的学业预警方法
1.本发明涉及人工智能领域,特别涉及一种基于元学习和支持向量描述的学业预警方法。
背景技术:
2.现今,高校大力推进学分制教学,在给学生更多的选择权和自主权的同时,这种教学制度对学生的学习能力和自我治理能力也提出了更高的要求。高校普遍缺乏系统的学习指导体系,有的学生的学习能力不足、自制力差导致学科挂科、绩点无法达到毕业要求而延迟毕业。并且近年来,各高校中因学业问题而延迟毕业的学生的人数持续增加,如何帮助学生提高其学习能力以完成学业迫在眉睫。
3.针对上述问题,一些高校开始探索学业预警制度,当学生的学分或绩点异常时及时对学生进行学业预警,以帮助学生顺利的完成学业。学业预警方法的类型较少,最常见的学业预警方法是利用信息技术手段对学生的历史学年的课程数据如绩点进行统计与分析,对学生可能存在的学业困难进行告知和警示,结合学校、家长、学生三方之间的沟通合作以帮助学生顺利完成学业。但这种参考单一数据类型的学业预警方法存在缺陷,其无法真正的反映学生在当前学年的学习情况,譬如有些学生在历史学年存在挂科情况但其在当前学年的学习态度端正,如果仅因为该类学生的历史绩点达到预警要求而对该类型的学生发出学业预警报告,则该学业预警报告可能存在极大地误差,这种学业预警方法的准确率低、单一性高,无法全面地评估学生在当前学年的学习情况。
技术实现要素:
4.本发明的目的是提供一种基于元学习和支持向量描述的学业预警方法,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
5.本发明解决其技术问题的解决方案是:提供一种基于元学习和支持向量描述的学业预警方法,所述方法包括以下步骤:
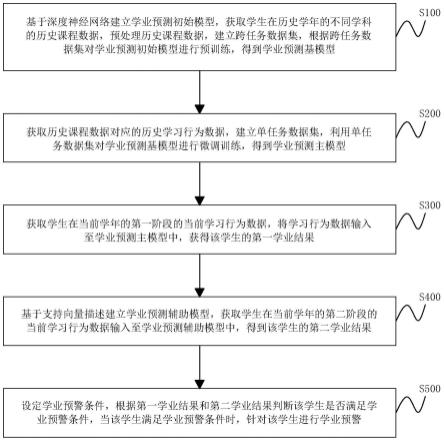
6.s100,基于深度神经网络建立学业预测初始模型,获取学生在历史学年的不同学科的历史课程数据,预处理历史课程数据,建立跨任务数据集,根据跨任务数据集对学业预测初始模型进行预训练,得到学业预测基模型;
7.s200,获取历史课程数据对应的历史学习行为数据,建立单任务数据集,利用单任务数据集对学业预测基模型进行微调训练,得到学业预测主模型;
8.s300、获取学生在当前学年的第一阶段的当前学习行为数据,将学习行为数据输入至学业预测主模型中,获得该学生的第一学业结果;
9.其中,所述第一学业结果包括第二时刻对应的未来课程数据,所述第二时刻在所述第一阶段之后;
10.s400,基于支持向量描述建立学业预测辅助模型,获取学生在当前学年的第二阶段的当前学习行为数据输入至学业预测辅助模型中,得到该学生的第二学业结果;
11.其中,所述第二学业结果为第二阶段对应的未来学业预警概率,所述第二阶段在所述第一阶段之后、第二时刻之前;
12.s500,设定学业预警条件,根据第一学业结果和第二学业结果判断该学生是否满足学业预警条件,当该学生满足学业预警条件时,针对该学生进行学业预警。
13.作为上述技术方案的进一步改进,步骤s100中根据跨任务数据集对学业预测初始模型进行预训练,得到学业预测基模型的步骤具体为:
14.s110,初始化学业预测初始模型的网络参数给定n个训练任务分类器,将网络参数赋予给这n个训练任务分类器的网络结构θn,即
15.s120,将跨任务数据集分为n组训练数据,每一组训练数据均有其对应的训练任务分类器,每一组训练数据均分为查询集和支持集;
16.s130,每一个训练任务分类器分别在其对应的支持集上训练,并根据每个训练任务分类器对应的查询集计算得出所有训练任务分类器的总损失函数,利用梯度下降法和总损失函数更新学业预测初始模型的网络参数;
17.s140,设定学业预测初始模型的网络参数的预期值区间,判断学业预测初始模型的网络参数是否位于预期值区间内,如果是,则转至步骤s141;
18.s141,输出学业预测基模型;
19.如果学业预测初始模型的网络参数位于预测值区间之外,则转至步骤s142;
20.s142,循环执行步骤s130至s140。
21.作为上述技术方案的进一步改进,步骤s130具体包括:
22.s131,通过随机采样从n个训练任务分类器中选择n个训练任务分类器,采样得出的n个训练任务分类器分别在其对应的支持集上进行训练,并通过梯度下降法更新一次各自的网络参数θn为θ
n*
,n=1,2,3
…
;
23.s132,根据步骤s131中得到的网络参数θ
n*
,这n个训练任务分类器分别在其对应的查询集上进行测试,并计算得出每个训练任务分类器所对应的第一子损失函数ln(θ
n*
);
24.s133,根据所有第一子损失函数计算得到总损失函数;其中所述总损失函数满足以下公式:
[0025][0026]
其中,表示总损失函数;
[0027]
s134,根据总损失函数更新学业预测初始模型的网络参数所述更新学业预测初始模型的网络参数满足以下公式:
[0028][0029][0030]
其中,β表示学业预测初始模型的学习率,表示总损失函数关于学业预测初始模型的网络参数的导数。
[0031]
作为上述技术方案的进一步改进,步骤s200具体包括:
[0032]
s210,获取历史课程数据对应的历史学习行为数据,其格式与预处理时的历史课程数据的格式相同,历史学习行为数据构成单任务数据集;
[0033]
s220,通过随机采样将单任务数据集分为m组训练集和j组测试集,利用这m组训练集的数据对学业预测基模型执行一次梯度下降操作,将学业预测基模型的网络参数更新更新为
[0034]
s230,根据这j组测试集计算每一组训练集对应的第二子损失函数,并根据所有第二子损失函数计算整体损失函数;其中,整体损失函数满足以下公式:
[0035][0036]
其中,lm表示第m组训练集对应的第二子损失函数,表示整体损失函数;
[0037]
s240,设定学业预测基模型的整体损失函数的预期区间,判断所述整体损失函数是否在其预期区间内,如果整体损失函数位于其预期区间内,则转至步骤s241;如果整体损失函数在其预期区间外,则转至步骤s242;
[0038]
s241,输出学业预测主模型;
[0039]
s242,循环执行步骤s220至s240。
[0040]
作为上述技术方案的进一步改进,步骤s400中建立学业预测辅助模型的步骤为:
[0041]
s410,获取在历史学年的第二阶段存在学业预警的学生的样本行为数据,对样本行为数据进行pca分析和预处理,得到辅助样本集;
[0042]
其中,所述预处理包括:样本行为数据为多类,每一类属性均不同,通过归一化方法将所有类别的样本行为数据进行统一度量;
[0043]
s420,通过随机采样将辅助样本集分为训练样本集x={xi,i=1,2,3
…
,l}和测试样本集x
′
={xi′
,i=1,2,3
…
,n},基于支持向量描述分类器建立预测模型,将训练样本集作为预测模型的输入,通过映射函数f将训练样本集x={xi,i=1,2,3
…
,l}映射至高维特征空间;其中,映射函数f为高斯核函数,所述高斯核函数满足以下公式:
[0044][0045]
其中,y表示高斯核函数的中心,σ表示高斯核函数的宽度参数;
[0046]
s430,设定支持向量描述分类器的松弛变量εi和惩罚参数c,支持向量描述分类器在训练过程中逐渐构成能够描述辅助样本集的超球体;其中,所述超球体满足以下公式:
[0047][0048][0049]
其中,r表示超球体的半径,μ表示超球体的球心,c表示支持向量描述分类器的惩罚参数,εi表示松弛变量,xi表示辅助样本集中的第i个样本课程数据,s.t.表示受约束;
[0050]
所述超球体为以μ为中心包含训练样本集x={xi,i=1,2,3
…
}的数据域;
[0051]
s440,引入拉格朗日算子,构建拉格朗日函数,结合拉格朗日函数和kkt条件得到最优超球体及其对应的球心和半径;其中,最优超球体满足以下公式:
[0052][0053][0054]
其中,l表示最优超球体,αi、αj均为拉格朗日算子;
[0055]
最优超球体的球心满足以下公式:
[0056][0057]
根据最优超球体的球心计算得到最优超球体的半径,其半径满足以下公式:
[0058][0059]
其中,xk表示训练样本集中任一个数据;
[0060]
s450,根据测试样本集评估学业预测辅助模型的性能,得到学业预测辅助模型的模型准确率,设定模型准确率的预期值,判断模型准确率是否小于其预期值;
[0061]
若模型准确率小于预期值,则重新执行步骤s420至步骤s450;
[0062]
若模型准确率未小于预期值,则输出学业预测辅助模型。
[0063]
作为上述技术方案的进一步改进,步骤s400中获取学生在当前学年的第二阶段的当前学习行为数据输入至学业预测辅助模型中,包括:
[0064]
将当前行为数据输入至学业预测辅助模型中,得到当前行为数据处于学业预测辅助模型的超球体状态下的支持向量;其中,所述支持向量满足以下公式:
[0065][0066]
其中,z表示当前行为数据;
[0067]
判断支持向量是否位于学业预测辅助模型的超球体内,计算学业预警概率,输出第二学业结果。
[0068]
作为上述技术方案的进一步改进,所述学业预警概率满足以下公式:
[0069][0070]
其中,p(z)表示学业预警概率,当f(z)-r2≥0时表示支持向量位于所述超球体之
外;当f(z)-r2《0时表示支持向量位于所述超球体内。
[0071]
作为上述技术方案的进一步改进,所述根据第一学业结果和第二学业结果判断该学生是否满足学业预警条件,当该学生满足学业预警条件时,针对该学生进行学业预警,包括:
[0072]
s510,所述学业预警条件包括课程数据合格区间、学业预警阈值概率以及补偿值,判断第一学业结果是否位于课程数据合格区间内,若否,则执行步骤s520;若是,则不输出学业预警报告;
[0073]
s520,判断第二学业结果是否低于学业预警阈值概率;如果是,则执行步骤s521;
[0074]
s521,根据第一学业结果和第二学业结果生成该学生的学业预警报告,所述学业预警报告包括该学生在当前学年的第一阶段和第二阶段的当前学习行为数据、未来课程数据、未来学业预警概率以及该学生的个人信息;
[0075]
如果第二学业结果未低于学业预警阈值概率,则转至步骤s522;
[0076]
s522,将第一学业结果和第二学业结果的绝对值进行乘积后输出补偿结果,所述补偿结果低于补偿值时生成该学生的学业预警报告。
[0077]
一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现所述一种基于元学习和支持向量描述的学业预警方法的步骤。
[0078]
一种基于元学习和深度学习的学业预警系统,所述系统包括:
[0079]
至少一个处理器;
[0080]
至少一个存储器,用于存储至少一个程序;
[0081]
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现所述一种基于元学习和支持向量描述的学业预警方法。
[0082]
本发明的有益效果是:提供一种基于元学习和支持向量描述的学业预警方法,包括:通过元学习建立学业预测主模型;基于支持向量描述建立学业预测辅助模型;获取学生在当前学年的第一阶段的当前学习行为数据并输入至学业预测主模型,得到第一学业结果;获取学生在当前学年的第二阶段的当前学习行为数据并输入至学业预测辅助模型,得到第二学业结果;设定学业预警条件,根据第一学业结果和第二学业结果判断学生是否符合学业预警条件,当学生符合学业预警条件时对学生采取相应的预警措施。本技术通过学业预测主模型和学业预测辅助模型判断学生是否存在学业预警的情况,在构建学业预测主模型时运用了元学习的方式以提高模型的准确率,而在构建学业预测辅助模型的时候运用了支持向量描述的方式以减少运算量,学业预测辅助模型对学业预测主模型进行误差补偿,提高了学业预警的准确率,减少了学业预警报告的片面性,能够更加准确的进行学业预警。
附图说明
[0083]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单说明。显然,所描述的附图只是本发明的一部分实施例,而不是全部实施例,本领域的技术人员在不付出创造性劳动的前提下,还可以根据这些附图获得其他设计方案和附图。
[0084]
图1是一种基于元学习和支持向量描述的学业预警方法的流程图;
[0085]
图2是一种基于元学习和支持向量描述的学业预警方法的根据跨任务数据集预训练学业预测初始模型的方法流程图;
[0086]
图3是一种基于元学习和支持向量描述的学业预警方法的更新学业预测初始模型的网络参数的方法流程图;
[0087]
图4是一种基于元学习和支持向量描述的学业预警方法的建立学业预测主模型的方法流程图;
[0088]
图5是一种基于元学习和支持向量描述的学业预警方法的建立学业预测辅助模型的方法流程图;
[0089]
图6是一种基于元学习和支持向量描述的学业预警方法的判断是否存在学业预警情况的方法流程图。
具体实施方式
[0090]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0091]
需要说明的是,虽然在系统示意图中进行了功能模块划分,在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于系统中的模块划分,或流程图中的顺序执行所示出或描述的步骤。说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
[0092]
请参考图1至图6,本技术提供一种基于元学习和支持向量描述的学业预警方法,该方法包括以下步骤:
[0093]
s100,基于深度神经网络建立学业预测初始模型,获取学生在历史学年的不同学科的历史课程数据,预处理历史课程数据,建立跨任务数据集,根据跨任务数据集对学业预测初始模型进行预训练,得到学业预测基模型;
[0094]
其中,所述预处理历史课程数据的步骤包括:
[0095]
查找历史课程数据中的缺失值,丢弃缺失值;
[0096]
标准化历史课程数据,并将历史课程数据的数据格式转换为符合深度神经网络的输入格式;
[0097]
s200,获取历史课程数据对应的历史学习行为数据,建立单任务数据集,利用单任务数据集对学业预测基模型进行微调训练,得到学业预测主模型;
[0098]
s300、获取学生在当前学年的第一阶段的当前学习行为数据,将学习行为数据输入至学业预测主模型中,获得该学生的第一学业结果;
[0099]
其中,所述第一学业结果包括第二时刻对应的未来课程数据,所述第二时刻在所述第一阶段之后;
[0100]
s400,基于支持向量描述建立学业预测辅助模型,获取学生在当前学年的第二阶段的当前学习行为数据输入至学业预测辅助模型中,得到该学生的第二学业结果;
[0101]
其中,所述第二学业结果为第二阶段对应的未来学业预警概率,所述第二阶段在所述第一阶段之后、第二时刻之前;
[0102]
s500,设定学业预警条件,根据第一学业结果和第二学业结果判断该学生是否满足学业预警条件,当该学生满足学业预警条件时,针对该学生进行学业预警。
[0103]
在步骤s100和s200中,本技术所采集的有关学生的课程数据量小,由于课程数据较少,若根据这些课程数据使网络模型直接进行机器学习,则输出的模型的预测准确率会较低,这样非常不利于对学生的未来课程数据进行预测。因此,本技术采用元学习(meta-learning)的概念更新学业预测初始模型的网络参数,元学习又称为“学会学习”,元学习使网络模型获取一种学会学习调参的能力,使网络模型可以在获取已有知识的基础上快速学习新的任务。元学习适用于训练样本少、存在另一个新的训练任务的情况,还适用于找寻某个网络模型的初始化参数。
[0104]
在机器学习中,当训练一个神经网络时,具体的步骤为:预处理数据集、选择网络模型、设置超参数、初始化参数、选择优化器、定义损失函数、梯度下降更新参数,其中涉及的参数称为网络参数,网络参数需要人为设置和定义;而元学习则是先通过其他的任务训练出一个较好的网络参数,再对特定特务进行训练。
[0105]
进一步的,步骤s100中基于深度神经网络建立学业预测初始模型,以历史课程数据作为模型的输入,以将预测的未来课程数据作为模型的输出,所述课程数据为绩点。请参考图2,根据跨任务数据集对学业预测初始模型进行预训练,得到学业预测基模型的步骤具体为:
[0106]
s110,初始化学业预测初始模型的网络参数给定n个训练任务分类器,将网络参数赋予给这n个训练任务分类器的网络结构θn,即
[0107]
s120,将跨任务数据集分为n组训练数据,每一组训练数据均有其对应的训练任务分类器,每一组训练数据均分为查询集和支持集;
[0108]
s130,每一个训练任务分类器分别在其对应的支持集上训练,并根据每个训练任务分类器对应的查询集计算得出所有训练任务分类器的总损失函数,利用梯度下降法和总损失函数更新学业预测初始模型的网络参数;
[0109]
s140,设定学业预测初始模型的网络参数的预期值区间,判断学业预测初始模型的网络参数是否位于预期值区间内,如果是,则转至步骤s141;
[0110]
s141,输出学业预测基模型;
[0111]
如果学业预测初始模型的网络参数位于预测值区间之外,则转至步骤s142;
[0112]
s142,循环执行步骤s130至s140。
[0113]
在元学习中分为两个阶段,一个阶段是训练任务训练,另一个阶段是测试任务训练。而本技术中步骤s100中所述根据跨任务数据集对学业预测初始模型进行预训练属于元学习的第一阶段,即训练任务训练,其目的是找寻学业预测初始模型的最优网络参数,并将该最优网络参数赋予至学业预测初始模型,使其网络性能提高。
[0114]
在训练任务中,首先初始化学业预测初始模型的初始参数给定n个训练任务分类器,每个训练任务的数据集分为查询集和支持集,通过这n个训练任务分类器的支持集训练学业预测初始模型的网络参数,分别训练每个训练任务分类器的参数;通过这n个训练任务分类器的查询集去测试对应的训练任务分类器的性能,并计算出所有训练任务分类器
的总损失函数最后利用梯度下降法计算以更新学业预测初始模型的网络参数。
[0115]
请参考图3,步骤s130具体为:
[0116]
s131,通过随机采样从n个训练任务分类器中选择n个训练任务分类器,采样得出的n个训练任务分类器分别在其对应的支持集上进行训练,并通过梯度下降法更新一次各自的网络参数θn为θ
n*
,n=1,2,3
…
;
[0117]
s132,根据步骤s131中得到的网络参数θ
n*
,这n个训练任务分类器分别在其对应的查询集上进行测试,并计算得出每个训练任务分类器所对应的第一子损失函数ln(θ
n*
);
[0118]
s133,根据所有第一子损失函数计算得到总损失函数;其中所述总损失函数满足以下公式:
[0119][0120]
其中,表示总损失函数;
[0121]
s134,根据总损失函数更新学业预测初始模型的网络参数所述更新学业预测初始模型的网络参数满足以下公式:
[0122][0123][0124]
其中,β表示学业预测初始模型的学习率,表示总损失函数关于学业预测初始模型的网络参数的导数。
[0125]
本技术通过步骤s200实现元学习第二阶段,即测试任务训练,测试任务训练可视作正常的机器学习的过程。请参考图4,所述步骤s200具体为:
[0126]
s210,获取历史课程数据对应的历史学习行为数据,其格式与预处理时的历史课程数据的格式相同,历史学习行为数据构成单任务数据集;
[0127]
s220,通过随机采样将单任务数据集分为m组训练集和j组测试集,利用这m组训练集的数据对学业预测基模型执行一次梯度下降操作,将学业预测基模型的网络参数更新更新为
[0128]
s230,根据这j组测试集计算每一组训练集对应的第二子损失函数,并根据所有第二子损失函数计算整体损失函数;其中,整体损失函数满足以下公式:
[0129][0130]
其中,lm表示第m组训练集对应的第二子损失函数,表示整体损失函数;
[0131]
s240,设定学业预测基模型的整体损失函数的预期区间,判断所述整体损失函数是否在其预期区间内,如果整体损失函数位于其预期区间内,则转至步骤s241;如果整体损失函数在其预期区间外,则转至步骤s242;
[0132]
s241,输出学业预测主模型;
[0133]
s242,循环执行步骤s220至s240。
[0134]
步骤s200的目的是对学业预测基模型进行微调训练。首先获取历史课程数据对应的历史学习行为数据并构成单任务数据集,其格式必须与历史课程数据的格式保持一致;再者通过随机采样将单任务数据集分为训练集和测试集,学业预测基模型在训练集上进行训练并进行一次梯度下降,更新学业预测基模型的网络参数;根据测试集计算训练集的整体损失函数,以获得学业预测主模型。
[0135]
需要注意的是,步骤s100与步骤s200分别为元学习的训练任务训练和测试任务训练,第一阶段根据跨任务数据集得到网络模型的最优初始化参数,而第二阶段则是利用从第一阶段中获得的最优初始化参数,根据单任务训练集得到最终的学业预测主模型。
[0136]
步骤s300为获取学生在当前学年的第一阶段的当前学习行为数据,将学习行为数据输入至学业预测主模型中,获得该学生的第一学业结果。其中,第一学业结果包括第二时刻对应的未来课程数据,即根据学业预测主模型,可通过当前学习行为数据预测获得预测的未来课程数据。
[0137]
本实施例中步骤s400为基于支持向量描述(support vector data description,svdd)建立学业预测辅助模型,并通过学业预测辅助模型得到该学生的第二学业结果,其中第二学业结果为第二时刻对应的未来学业预警概率。
[0138]
其中,请参考图5,所述建立学业预测辅助模型的步骤为:
[0139]
s410,获取在历史学年的第二阶段存在学业预警的学生的样本行为数据,对样本行为数据进行pca分析和预处理,得到辅助样本集;
[0140]
其中,所述预处理包括:样本行为数据为多类,每一类属性均不同,通过归一化方法将所有类别的样本行为数据进行统一度量;
[0141]
s421,通过随机采样将辅助样本集分为训练样本集x={xi,i=1,2,3
…
,l}和测试样本集x
′
={x
′i,i=1,2,3
…
,n},基于支持向量描述分类器建立预测模型,将训练样本集作为预测模型的输入,通过映射函数f将训练样本集x={xi,i=1,2,3
…
,l}映射至高维特征空间;其中,映射函数f为高斯核函数,所述高斯核函数满足以下公式:
[0142][0143]
其中,y表示高斯核函数的中心,σ表示高斯核函数的宽度参数;
[0144]
s430,设定支持向量描述分类器的松弛变量εi和惩罚参数c,支持向量描述分类器在训练过程中逐渐构成能够描述辅助样本集的超球体;其中,所述超球体满足以下公式:
[0145][0146][0147]
其中,r表示超球体的半径,μ表示超球体的球心,c表示支持向量描述分类器的惩罚参数,εi表示松弛变量,xi表示辅助样本集中的第i个样本课程数据,s.t.表示受约束;
[0148]
所述超球体为以μ为中心包含训练样本集x={xi,i=1,2,3
…
}的数据域;
[0149]
s440,引入拉格朗日算子,构建拉格朗日函数,结合拉格朗日函数和kkt条件得到最优超球体及其对应的球心和半径;其中,最优超球体满足以下公式:
[0150][0151][0152]
其中,l表示最优超球体,αi、αj均为拉格朗日算子;
[0153]
最优超球体的球心满足以下公式:
[0154][0155]
根据最优超球体的球心计算得到最优超球体的半径,其半径满足以下公式:
[0156][0157]
其中,xk表示训练样本集中任一个数据;
[0158]
s450,根据测试样本集评估学业预测辅助模型的性能,得到学业预测辅助模型的模型准确率,设定模型准确率的预期值,判断模型准确率是否小于其预期值;
[0159]
若模型准确率小于预期值,则重新执行步骤s420至步骤s450。
[0160]
若模型准确率未小于预期值,则输出学业预测辅助模型。
[0161]
在本技术领域,支持向量描述是一种单分类器,其常用于数据的离群或野值点的检测;其基本思想是找出一个超球体来描述给定目标数据集,该超球体以最小的半径包含目标数据集中的所有数据,位于超球体上的数据点称为支持向量。在支持向量描述分类器训练过程中,最重要的问题是如何获得超球体的最小半径。
[0162]
本实施例中,首先利用高斯核函数将训练样本集映射至高维特征空间,作为优选的,映射函数可以是其他的核函数;随后,在高维特征空间中构建一个超球体来包含一个高概率区域,即以超球体的球心为中心包含训练样本集的数据域;通过拉格朗日函数和kkt条件获得最优超球体。
[0163]
其中,本发明在步骤s430中设定了支持向量描述分类器的松弛变量和惩罚参数,所述松弛变量用于允许训练样本集中部分异常点位于超球体外,而所述惩罚参数则用于设定对异常点的惩罚程度,惩罚参数为训练样本集映射至高维特征空间的支持向量数与训练样本集的数据总数的比值,其满足以下公式:
[0164][0165]
其中,svs为支持向量数,l为训练样本集的数据总数。
[0166]
本实施例中,所述获取学生在当前学年的第二阶段的当前学习行为数据输入至学业预测辅助模型中,得到该学生的第二学业结果,包括:
[0167]
将当前学习行为数据输入至学业预测辅助模型中,得到当前行为数据处于学业预测辅助模型的超球体状态下的支持向量;其中,所述支持向量满足以下公式:
[0168][0169]
其中,z表示当前行为数据;
[0170]
判断支持向量是否位于学业预测辅助模型的超球体内,计算学业预警概率,输出第二学业结果;其中,所述学业预警概率满足以下公式:
[0171][0172]
其中,p(z)表示学业预警概率,当f(z)-r2≥0时表示支持向量位于所述超球体之外;当f(z)-r2《0时表示支持向量位于所述超球体内。
[0173]
具体地,当前学习行为数据输入至学业预测辅助模型中,得到当前行为数据处于超球体状态下的支持向量,若支持向量落在超球体内,则p(z)为负数;若支持向量落在超球体外,则p(z)为正数。
[0174]
请参考图6,本实施例步骤s500为根据第一学业结果和第二学业结果判断该学生是否满足学业预警条件,当该学生满足学业预警条件时,针对该学生进行学业预警,其具体为:
[0175]
s510,所述学业预警条件包括课程数据合格区间、学业预警阈值概率以及补偿值,判断第一学业结果是否位于课程数据合格区间内,若否,则执行步骤s520;若是,则不输出学业预警报告;
[0176]
s520,判断第二学业结果是否低于学业预警阈值概率;如果是,则执行步骤s521;
[0177]
s521,根据第一学业结果和第二学业结果生成该学生的学业预警报告,所述学业预警报告包括该学生在当前学年的第一阶段和第二阶段的当前学习行为数据、未来课程数据、未来学业预警概率以及该学生的个人信息;
[0178]
如果第二学业结果未低于学业预警阈值概率,则转至步骤s522;
[0179]
s522,将第一学业结果和第二学业结果的绝对值进行乘积后输出补偿结果,所述补偿结果低于补偿值时生成该学生的学业预警报告。
[0180]
本发明从两个维度来衡量学生是否符合学业预警条件,第一维度是通过学业预测主模型得到的未来课程数据(即第一学业结果),第二维度是通过学业预测辅助模型得到的未来学业预警概率(即第二学业结果),第二维度用于弥补第一维度存在的误差,减少了学业预警结果的片面性。
[0181]
在步骤s500中,首先设定学业预警条件为课程数据合格区间、学业预警阈值概率和补偿值,所述课程数据合格区间可根据学校对于绩点的相关规定而定,其用于判断未来课程数据是否为合格值;所述学业预警阈值概率用于判断未来学业预警概率低于正常值,所述补偿值用于补偿判断结果。
[0182]
在设定学业预警条件之后,根据第一学业结果和第二学业结果对学生是否存在学业预警进行判断,其中当第一学业结果超出课程数据合格区间并且第二学业结果低于学业预警阈值概率时,才会视作该学生存在学业预警,并且输出其学业预警报告。
[0183]
在另一实施方式中,若第一学业结果超出课程数据合格区间但第二学业结果未低于学业预警阈值概率,则需要进行下一步处理:将第一学业结果和第二学业结果的绝对值进行成绩后输出补偿结果,并根据补偿值判断该学生是否符合学业预警。
[0184]
在这个实施例中,第二学业结果的数值类型为百分比,若当前学习行为数据位于超球体内,则第二学业结果为负数,因此在进行乘积运算时需要取第二学业结果的绝对值。将第二学业结果的绝对值与第一学业结果进行乘积的目的是通过第二学业结果对第一学业结果存在的误差进行补偿。
[0185]
上述技术方案的有益效果是:通过两个维度对学生是否存在学业预警问题进行分析,第二维度对第一维度起到了补偿误差的作用,进而提高了学业预警的准确率,减少了学业预警报告的片面性。
[0186]
本技术还公开了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现所述一种基于元学习和支持向量描述的学业预警方法的步骤。
[0187]
本技术还公开了一种基于元学习和深度学习的学业预警系统,其特征在于,所述系统包括:
[0188]
至少一个处理器;
[0189]
至少一个存储器,用于存储至少一个程序;
[0190]
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现所述一种基于元学习和支持向量描述的学业预警方法。
[0191]
以上对本发明的较佳实施方式进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可作出种种的等同变型或替换,这些等同的变型或替换均包含在本技术权利要求所限定的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1