数据处理方法、装置、存储介质、设备及产品与流程
1.本技术涉及计算机技术领域,尤其涉及一种数据处理方法、装置、存储介质、设备及产品。
背景技术:
2.像深度神经网络等复杂模型能够通过特征转换,将样本数据抽象到新的向量空间,增加对原始信息的提取能力,从而在大部分任务上呈现卓越的表现。但深度神经网络等复杂模型相当于是一个黑盒,人们无法理解这些黑盒模型为什么做出某些决策,因此对这类黑盒模型的特征转换过程进行可解释性分析是有必有的。
技术实现要素:
3.本技术实施例提供了一种数据处理方法、装置、存储介质、设备及产品,可以实现对特征转换过程进行可解释性分析。
4.一方面,本技术实施例提供了一种数据处理方法,所述方法包括:
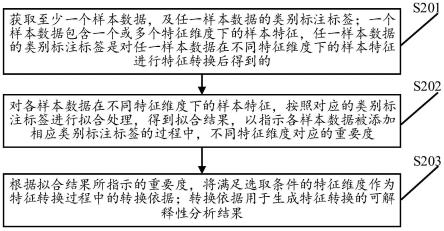
5.获取至少一个样本数据,及任一样本数据的类别标注标签;一个样本数据包含一个或多个特征维度下的样本特征,所述任一样本数据的类别标注标签是对所述任一样本数据在不同特征维度下的样本特征进行特征转换后得到的;
6.对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度;
7.根据所述拟合结果所指示的重要度,将满足选取条件的特征维度作为特征转换过程中的转换依据;所述转换依据用于生成特征转换的可解释性分析结果。
8.一方面,本技术实施例提供了一种数据处理装置,所述装置包括:
9.获取单元,用于获取至少一个样本数据,及任一样本数据的类别标注标签;一个样本数据包含一个或多个特征维度下的样本特征,所述任一样本数据的类别标注标签是对所述任一样本数据在不同特征维度下的样本特征进行特征转换后得到的;
10.处理单元,用于对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度;
11.所述处理单元,还用于根据所述拟合结果所指示的重要度,将满足选取条件的特征维度作为特征转换过程中的转换依据;所述转换依据用于生成特征转换的可解释性分析结果。
12.一方面,本技术实施例提供了一种计算机设备,该计算机设备包括处理器、通信接口和存储器,该处理器、通信接口和存储器相互连接,其中,该存储器存储有计算机程序,该处理器用于调用该计算机程序,执行上述任一可能实现方式的数据处理方法。
13.一方面,本技术实施例提供了一种计算机可读存储介质,该计算机可读存储介质
存储有计算机程序,该计算机程序被处理器执行时实现该任一可能实现方式的数据处理方法。
14.一方面,本技术实施例还提供了一种计算机程序产品,上述计算机程序产品包括计算机程序或计算机指令,上述计算机程序或计算机指令被处理器执行实现本技术实施例提供的数据处理方法的步骤。
15.一方面,本技术实施例还提供了一种计算机程序,上述计算机程序包括计算机指令,上述计算机指令存储在计算机可读存储介质中,计算机设备的处理器从上述计算机可读存储介质读取上述计算机指令,上述处理器执行上述计算机指令,使得上述计算机设备执行本技术实施例提供的数据处理方法。
16.在本技术实施例中,可以获取至少一个样本数据以及任一样本数据的类别标注标签,该任一样本数据的类别标注标签是对任一样本数据在不同特征维度下的样本特征进行特征转换后得到的,通过对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,可以得到拟合结果,该拟合结果可以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度,因此通过拟合结果所指示的重要度,可以将满足选取条件的特征维度作为特征转换过程中的转换依据,即满足选取条件的特征维度是特征转换过程中用于区分样本数据的重要因素,可以基于该转换依据生成特征转换的可解释性分析结果。通过本技术实施例,可以实现对特征转换过程进行可解释性分析。
附图说明
17.为了更清楚地说明本技术实施例技术方法,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1为本技术实施例提供的一种数据处理的示意图;
19.图2为本技术实施例提供的一种数据处理方法的流程示意图;
20.图3为本技术实施例提供的另一种数据处理方法的流程示意图;
21.图4为本技术实施例提供的一种目标网络模型的示意图;
22.图5为本技术实施例涉及的获取至少一个样本数据的示意图;
23.图6为本技术实施例提供的另一种数据处理方法的流程示意图;
24.图7为本技术实施例提供的一种目标网络模型的决策路径的示意图;
25.图8为本技术实施例提供的另一种目标网络模型的决策路径的示意图;
26.图9为本技术实施例提供的一种数据处理装置的结构示意图;
27.图10为本技术实施例提供的一种计算机设备的结构示意图。
具体实施方式
28.下面将结合本技术实施例中的附图,对本技术实施例中的技术方法进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
29.本技术实施例提出了一种数据处理方法,可以实现对特征转换过程进行可解释性
分析,能够应用于云技术、人工智能、区块链、车联网、智慧交通、智能家居等各种领域或场景。在一实施例中,该数据处理方法可以基于人工智能技术中的机器学习技术实现。人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大视频处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习、自动驾驶、智慧交通等几大方向。机器学习(machinelearning,ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。例如,本技术实施例中采用机器学习技术进行样本数据和对应类别标注标签的拟合处理,以根据得到的拟合结果确定特征转换过程中的转换依据。
30.本技术提出的数据处理方法的执行主体为计算机设备,该计算机设备可以包括终端以及服务器等中的一个或多个。即,本技术实施例提出的数据处理方法可以由终端执行,也可以由服务器执行,还可以由能够进行互相通信的终端和服务器共同执行。
31.其中,终端可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能语音交互设备、智能家电、车载终端,等等。服务器可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn(content delivery network,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器。
32.像深度神经网络等复杂模型存在大量的非线性网络层,大量非线性网络层的组合可以对原始数据在各种抽象层面上抽取表征,但其模型复杂度高、参数多,人们无法理解这种“端到端”的模式是如何做出决策的。而透明模型是一种结构简单、能够直观理解的模型,例如逻辑回归模型、决策树模型、朴素贝叶斯模型等,可以解释从数据输入到输出预测这个过程中间的所有环节。因此,如图1所示,在本技术提出的数据处理方法中,计算机设备可以在对样本数据进行特征转换得到样本表征之后,利用样本表征所反映出的样本数据的类别属性,为样本数据添加类别标注标签,再通过透明模型让样本数据拟合对应类别标注标签,得到拟合结果,该拟合结果实际上是透明模型的可解释分析结果,可以反映在将样本数据拟合成对应类别标注标签时,样本数据的不同特征维度对拟合对应类别标注标签的影响程度。因此本技术通过该拟合结果来指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度,通过该拟合结果所指示的重要度,可以知道在特征转换过程中,一个样本数据中的哪些特征维度是特征转换过程中的重要因素,从而得到特征转换过程中的转换依据,并基于转换依据生成特征转换的可解释性分析结果,以实现对特征转换过程进行可解释性分析。
33.请参阅图2,图2为本技术实施例提供的一种数据处理方法的流程示意图。该方法可以应用于上述图1中的计算机设备,该方法包括。
34.s201、获取至少一个样本数据,及任一样本数据的类别标注标签;一个样本数据包含一个或多个特征维度下的样本特征,任一样本数据的类别标注标签是对任一样本数据在
不同特征维度下的样本特征进行特征转换后得到的。
35.在本技术实施例中,一个样本数据可以用于描述一个对象,该对象是指客观存在的事物,例如一个人、一朵花、一只动物等。一个或多个特征维度是通过对该对象进行多维度划分得到的,例如人可以按照身高、体重进行划分,花可以按照颜色、大小、生长期进行划分,动物可以按照花纹、体温进行划分。特征维度下的样本特征是指该特征维度对应的值,例如一个人的身高是156厘米,一朵花的颜色是红色,一只动物的体温是恒温。需说明的是,该至少一个样本数据中的各个样本数据包含一个或多个相同的特征维度。
36.在一实施例中,计算机设备可以对任一样本数据在不同特征维度下的样本特征进行特征转换,得到任一样本数据对应的特征向量。接着,基于该任一样本数据对应的特征向量,将对应特征向量之间具有高度相似性的样本数据划分到一个数据集中,将对应特征向量差别较大的样本数据划分到不同数据集中。最终基于该任一样本数据所在的数据集确定任一样本数据的类别标注标签,其中,一个类别标注标签可以对应(指示)一个数据集。
37.对样本数据进行特征转换的过程,相当于是一个黑盒模型的处理过程,该黑盒模型会对样本数据中各个特征维度下的样本特征进行分析,判断该样本数据倾向于属于哪个类别属性,就会生成容易让样本数据被判别为该类别属性的特征向量。以一个常见的图像分类模型为例,若一个图像的真实标签为猫,则会生成容易让该图像被判别为猫的图像特征,同时该图像特征会与真实标签为其他类别的图像特征的差别较大,这样模型才能进行分类。因此,对应特征向量之间的相似度越高,说明样本数据被划分为同一类别属性的可能性就更大,对应特征向量差别越大,说明样本数据被划分到同一类别属性的可能性就更低。而上述通过特征向量对至少一个样本数据进行划分的过程,相当于是在确定,该特征转换过程倾向于将各个样本数据归属到哪一个类别属性(通过类别标注标签指示)。由于特征转换过程往往会涉及大量的非线性映射,因此,人们无法知道在特征转换时,是基于样本数据中的哪些特征维度进行的分析。
38.s202、对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度。
39.在本技术实施例中,会对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果。该拟合处理的过程相当于是输入任一样本数据在不同特征维度下的样本特征,使输出为该任一样本数据的类别标注标签的过程,因此该拟合处理过程与特征转换过程本质都是,通过分析样本数据中的各个特征维度下的样本特征,判别样本数据倾向于属于哪一个类别标注标签。而该拟合处理过程可以通过透明模型实现,由于透明模型可以解释从数据输入到输出预测这个过程中间的所有环节,因此,可以通过透明模型的可解释性结果,对特征转换过程进行可解释性分析。其中,该透明模型或者说该拟合处理过程是通过拟合结果进行可解释性分析的,该拟合结果可以反映任一样本数据在拟合对应类别标注标签时,该任一样本数据下的不同特征维度的影响程度,可以通过该影响程度反映各样本数据被添加相应类别标注标签的过程中,该特征维度对应的重要度。
40.具体可以通过该拟合处理确定一个拟合模型,将该任一样本数据在不同特征维度下的样本特征作为该拟合模型的输入,通过该拟合模型中的目标权重w
jm
对样本数据进行变
换处理,得到拟合模型的输出,该拟合模型的输出可以指示该任一样本数据的类别标注标签。例如将任一样本数据输入该拟合模型时,该拟合模型的输出是该任一样本数据被添加不同类别标注标签的预测概率,且最大预测概率的类别标注标签就是该任一样本数据的类别标注标签。此时,该目标权重w
jm
的绝对值的大小可以反映,通过该拟合模型确定任一样本数据被添加第m类别标注标签的预测概率时,该任一样本数据包含的第j个特征维度对该预测概率的影响程度。另外,目标权重w
jm
是正数,则表明第j个特征维度与该预测概率是正相关的,即在第j个特征维度下的样本特征越大,会使得该预测概率越大;目标权重w
jm
是负数,则表明第j个特征维度与该预测概率是负相关的,即在第j个特征维度下的样本特征越大,会使得该预测概率越小。其中,j和m为大于0的整数。
41.则通过上述目标权重w
jm
可知,若目标权重w
jm
是正数且越大,则一个样本数据中第j个特征维度下的样本特征越大,该一个样本数据越容易被添加第m类别标注标签。若目标权重w
jm
是负数且越小,则一个样本数据中第j个特征维度下的样本特征越大,该一个样本数据越不可能被添加第m类别标注标签。若目标权重w
jm
的绝对值越小,则一个样本数据中第j个特征维度下的样本特征,对于该一个样本数据被不被添加第m类别标注标签的影响不大。因此将该目标权重w
jm
作为拟合结果,就可以知道特征转换过程中,哪些特征维度对应的重要度比较高,且知道特征维度会如何影响样本数据的类别标注标签的判别。
42.s203、根据所述拟合结果所指示的重要度,将满足选取条件的特征维度作为特征转换过程中的转换依据;所述转换依据用于生成特征转换的可解释性分析结果。
43.通过特征转换可以将样本数据抽象到高维空间(例如向量空间),但难以对特征转换过程中学习到的信息进行解读,人们无法知道哪个或哪些特征维度在特征转换过程中起到了(重要)作用以及是如何起作用,即不知道特征转换过中的转换依据。
44.由于拟合处理也涉及通过样本数据中的不同特征维度下的样本数据,判别样本数据倾向于哪一个类别标注标签,因此基于样本数据的拟合,可实现对前述特征转换步骤的可解释性分析,也就是说,本技术通过拟合结果所指示的重要度,可以将满足选取条件的特征维度作为特征转换过程中的转换依据。其中,拟合结果所指示的重要度是通过目标权重w
jm
量化的。可理解的,当目标权重w
jm
是正数且越大时,一个样本数据中的第j个特征维度下的样本特征越大,越容易被添加第m类别标注标签。又因为每个类别标注标签对应一个数据集,所以在特征转换时,一个样本数据中第j个特征维度下的样本特征越大,该一个样本数据越容易与第m类别标注标签对应的数据集中的样本数据生成相近特征。
45.在一实现方式中,按照拟合结果所指示的重要度从大到小的顺序,依次选取出目标数量的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据,包括:假设一个样本数据包含有d个特征维度下的样本特征,则针对第m类别标注标签存在目标权重集合wm={w
1m
,w
2m
,...,w
dm
},可以按照目标权重集合wm={w
1m
,w
2m
,...,w
dm
}中的各个目标权重从大到小的顺序,依次选取出目标数量(可以人为设定)的目标权重,将该目标数量的目标权重对应的特征维度作为特征转换过程中的转换依据,且在特征转换过程中,一个样本数据中该目标数量的目标权重对应的特征维度下的样本特征越大,该一个样本数据越容易与第m类别标注标签对应的数据集中的样本数据生成相近特征,即特征转换的可解释性分析结果。
46.在另一实现方式中,根据拟合结果所指示的重要度,选取出对应重要度大于重要
度阈值的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据,包括:假设一个样本数据包含有d个特征维度下的样本特征,则针对第m类别标注标签存在目标权重集合wm={w
1m
,w
2m
,...,w
dm
},可以获取目标权重集合中大于权重阈值(可以人为设定)的目标权重,将大于权重阈值的目标权重对应的特征维度作为特征转换过程中的转换依据,且在特征转换过程中,一个样本数据中该大于权重阈值的目标权重对应的特征维度下的样本特征越大,该一个样本数据越容易与第m类别标注标签对应的数据集中的样本数据生成相近特征,即特征转换的可解释性分析结果。
47.在本技术实施例中,可以在对样本数据进行特征转换得到样本表征(即特征向量)之后,利用样本表征所反映出的样本数据的类别属性,为样本数据添加类别标注标签,再通过让样本数据拟合对应类别标注标签,得到拟合结果,该拟合结果可以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度。则通过拟合结果所指示的重要度,就可以知道在特征转换过程中,哪些特征维度比较重要,且知道特征维度会如何影响样本数据的类别标注标签的判别,从而可以确定特征维度是如何影响样本数据的特征转换,得到特征转换过程的转换依据以及可解释性分析结果,可以实现对特征转换过程进行可解释性分析。
48.请参阅图3,图3为本技术实施例提供的另一种数据处理方法的流程示意图。该方法可以应用于上述图1中的计算机设备,该方法包括:
49.s301、获取至少一个样本数据,及任一样本数据的类别标注标签;一个样本数据包含一个或多个特征维度下的样本特征,任一样本数据的类别标注标签是对任一样本数据在不同特征维度下的样本特征进行特征转换后得到的。
50.在一实施例中,可以对每个样本数据在不同特征维度下的样本特征进行特征转换,得到每个样本数据对应的特征向量。每个样本数据对应的特征向量,是通过调用包含分类功能的目标网络模型的第i网络隐层进行特征转换得到的。其中,该目标网络模型可以包含n个网络隐层,n为大于等于1的正整数,i为大于0且小于等于n的正整数。
51.其中,目标网络模型可以是单纯的分类模型,例如样本数据可以涉及花的大小、颜色、高度等多个特征维度,目标网络模型可以利用样本数据预测是什么种类的花;也可以是推荐模型,样本数据可以涉及对象每个月购买商品的次数、购买商品的平均价格,向对象所推荐的商品的价格、向对象所推荐的商品的浏览量等多个特征维度,目标网络模型可以通过该样本数据预测向对象推荐商品时,对象购买的可能性。其中,对象每个月购买商品的次数、购买商品的平均价格是在获得用户许可或者同意之后才获取的。
52.如图4所示,该目标网络模型可以是一个包含n个网络隐层的深度神经网络,可以将每个样本数据在不同特征维度下的样本特征输入目标网络模型,该目标网络模型的第一个网络隐层会将输入的样本特征经过变换抽象到一个新的向量空间,以输出每个样本数据对应的特征向量h1,进而再将该特征向量h1输入到下一个网络隐层,以输出每个样本数据对应的特征向量h2,通过n个网络隐层叠加,可以得到每个样本数据对应的特征向量hn。在一实施方式中,调用包含分类功能的目标网络模型的第i网络隐层进行特征转换,得到每个样本数据对应的特征向量,包括:将每个样本数据在不同特征维度下的样本特征输入目标网络模型,目标网络模型中的前i层会逐层叠加,变换抽象得到特征向量h
i-1
,进一步将特征向量h
i-1
输入第i网络隐层,得到每个样本数据对应的特征向量hi。
53.需说明的是,第i网络隐层在将输入的特征向量h
i-1
变换为特征向量hi的过程即为特征转换过程,因此基于第i网络隐层对至少一个样本数据进行特征转换后得到的可解释性分析结果,被作为第i网络隐层的可解释性分析结果。后续步骤实际上也是在对第i网络隐层进行可解释性分析。
54.进一步地,基于每个样本数据对应的特征向量,对至少一个样本数据进行聚类运算,以将至少一个样本数据划分到不同的数据集中。聚类算法是一种无监督方法,即在训练过程中不需要使用样本数据的真实标签,而是通过样本数据本身的表征,将表征相近的样本数据归到同一个数据集中。一可行的实现方式中,可以采用聚类算法,对每个样本数据对应的特征向量进行聚类处理,该聚类算法可以是k-means算法(硬聚类算法)、dbscan((density-based spatial clustering of applications with noise,基于密度的聚类)算法等。以k-means算法为例,
①
选择m(大于0的整数)个初始聚类中心{v1,v2,...,vm};
②
计算各个样本数据对应的特征向量与m个初始聚类中心的距离,并归属到距离最近的类簇中;
③
针对各个类簇,计算当前类簇内的平均特征向量,并作为新的聚类中心;
④
重复
②‑③
,直至达到终止条件,例如该终止条件可以是预设的迭代次数上限值或各类簇中的特征向量不发生变化。
55.通过上述聚类处理,可以将每个样本数据对应的特征向量划分到不同的类簇中,进一步通过特征向量与样本数据之间的对应关系,可以对至少一个样本数据进行聚类运算,即属于同一类簇的特征向量,其对应的样本数据被划分到同一个数据集,从而将至少一个样本数据划分到不同数据集。可理解的,由于有m个聚类中心,因此划分了m个类簇,得到了m个数据集。
56.其中,一个数据集对应一个聚类标签。在一实现方式中,可以在对至少一个样本数据进行聚类运算后,确定得到的数据集总量,并基于数据集总量确定得到的每个数据集对应的集合编号。例如有三个数据集,三个数据集对应的集合编号分别为1、2、3。可以将一个数据集对应的集合编号作为一个数据集对应的聚类标签,再将任一样本数据所在数据集对应的聚类标签作为任一样本数据的类别标注标签。因此,任一样本数据的类别标注标签可以指示该任一样本数据所在的数据集,例如任一样本数据的类别标注标签为3,则表明该任一样本数据所在的数据集的集合编号和聚类标签为3。
57.在可行的实施例中,可以获取用于对目标网络模型中的第i-1网络隐层进行可解释分析采用的至少一个参考样本数据,以及在对第i-1网络隐层进行可解释分析过程中对至少一个参考样本数据进行聚类运算后的得到的至少两个参考样本集,将任一参考样本集中包含的参考样本数据分别作为上述获取得到的至少一个样本数据。如图5所示,在针对第i-1网络隐层进行可解释性分析时,划分得到了n(大于1的整数)个参考样本集,在对第i网络隐层进行可解释分析时,可以将其中的任一参考样本集作为对第i网络隐层进行可解释分析的至少一个样本数据,则在对第i网络隐层进行可解释分析的过程中,针对第i-1网络隐层对应的任一参考样本集又可以进一步划分得到第i网络隐层对应的多(n)个参考样本集。
58.每个样本数据可以存在真实标签,该真实标签可以是基于目标网络模型的分类任务确定的。例如目标网络模型是要判别一个人是否购买商品时,真实标签可以包括购买、不购买;目标网络模型是要判别一个动物所属的类群时,真实标签可以包括两栖类、哺乳类、
爬行类。一实现方式中,上述m可以是真实标签的数量,例如真实标签包括购买、不购买,m为2;真实标签包括两栖类、哺乳类、爬行类,m为3。可以获取任一数据集中包含的每个样本数据的真实标签,并确定出对应同一真实标签的样本数量。接着基于对应同一真实标签的样本数量,及任一数据集中的样本数据总量,计算对应同一真实标签的样本占比,即对应同一真实标签的样本占比=对应同一真实标签的样本数量/任一数据集中的样本数据总量,从而得到不同真实标签分别对应的样本占比。进一步可以获取该任一数据集对应的最大样本占比的真实标签。若m个数据集各自对应的最大样本占比的真实标签不同,且其占比大于占比阈值(可以人为设定),则可以确定目标网络模型到第i网络隐层时已具有良好的特征转换能力,能够较优地完成分类任务,此时可以对目标网络模型进行剪枝处理,只保留目标网络模型的第i网络隐层和在第i网络隐层之前的网络隐层。例如,数据集1对应的最大样本占比的真实标签为两栖类且两栖类占比为98%,数据集2对应的最大样本占比的真实标签为哺乳类且哺乳类占比为98%,数据集3对应的最大样本占比的真实标签为爬行类且爬行类占比为98%,则认为目标网络模型到第i网络隐层已具有良好的特征转换能力。
59.s302、获取用于进行可解释性分析的目标算法。
60.该目标算法可以是具备自解释能力的透明模型,透明模型是一类结构简单、能够直观理解的模型。本技术以透明模型是逻辑回归模型为例进行说明。假设一个样本数据包括d(大于0的整数)个特征维度下的样本特征x=(x1,x2,...,xd),则逻辑回归模型的表达式如下述式(1)所示,是通过训练一组θ=(w,b)学习从样本数据x到预测概率f(x)的映射关系。
61.f(x)=σ(w
t
x+b)(1)
62.其中,w=(w1,w2,...,wd),w表示预测权重,b表示偏置项,w和b是可调的模型参数,可以通过初始化参数得到,t表示转置运算,也就是说w
t
是对w进行转置运算后得到的,x表示输入的样本数据;σ()表示sigmoid函数,可以限定f(x)的取值范围在[0,1]之间,f(x)表示一个样本数据x为正样本的预测概率,1-f(x)表示一个样本数据x为负样本的预测概率。其中,w中的wj的绝对值的大小可以反映第j个特征维度对预测概率f(x)的影响程度的大小。另外,wj是正数,则代表对应的特征维度与预测概率f(x)是正相关的,即一个样本数据中第j个特征维度下的样本特征越大,预测概率f(x)越大,反之则为负相关。
[0063]
上述式(1)为适用于二分类的逻辑回归模型的表达式,下述式(2)是基于多个二分类的逻辑回归模型,构成的多分类的逻辑回归模型的表达式。
[0064][0065]
其中,p(y=m|x,w)表示一个样本数据x被分类为第m类别的预测概率,wm=(w
1m
,w
2m
,...,w
dm
)是预测权重,wm中的w
jm
的绝对值的大小可以反映一个样本数据x被分类为第m类别的预测概率时,第j个特征维度对该预测概率p(y=m|x,w)的影响程度的大小。
[0066]
s303、采用目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度。
[0067]
在一实施例中,采用目标算法,对各样本数据在不同特征维度下的样本特征,按照
对应的类别标注标签进行拟合处理,得到拟合结果,包括:采用目标算法对每个样本数据在不同特征维度下的样本特征进行标签预测处理,得到每个样本数据的类别预测结果。具体的,可以将式(2)转换为下述式(3)所示。
[0068][0069]
将每个样本数据在不同特征维度下的样本特征作为式(3)所示的多分类的逻辑回归模型的输入x=(x1,x2,...,xd),以输出每个样本数据的类别预测结果:p(y=1|x,w)、p(y=2|x,w)、...、p(y=m|x,w)。该每个样本数据的类别预测结果可以指示该每个样本数据被分类为不同类别标注标签的预测概率。因为有m个数据集,一个数据集对应一个类别标注标签,所以存在m个类别标注标签。
[0070]
进一步地,可以利用该每个样本数据的类别预测结果和每个样本数据的类别标注标签,对目标算法的预测权重进行调整,即对式(3)中的预测权重w1、w2、...、wm进行调整。例如,可以获取适用于多分类的损失函数,例如交叉熵损失函数,交叉熵损失函数的表达式如下述式(4)所示。
[0071][0072]
其中,loss1表示第一损失值,s表示至少一个样本数据的样本数量,xj表示第j个样本数据,p(y=m|xj,w)表示第j个样本数据被添加为第m类别标注标签的预测概率,y
jm
表示符号函数,其取值为0或1,如果样本数据xj的类别标注标签是第m类别标注标签,则y
jm
为1,其余为0。
[0073]
再将每个样本数据的类别预测结果代入式(4)中的p(y=m|xj,w)以及基于每个样本数据的类别标注标签确定式(4)中的y
jm
,从而使得式(4)可以输出第一损失值,进一步可以通过该第一损失值以及随机梯度下降法调整式(3)中的预测权重w1、w2、...、wm,重复进行多次调整,当满足停止条件时,如达到指定数量的调整次数,或交叉熵损失函数收敛就满足停止条件。将调整后的预测权重作为拟合结果。该调整后的预测权重w1=(w
11
,w
21
,...,w
d1
)、w2=(w
12
,w
22
,...,w
d2
)、...、wm=(w
1m
,w
2m
,...,w
dm
)即上述s202和s203中的目标权重,包含有该目标权重的多分类的逻辑回归模型即为上述s202中的拟合模型。
[0074]
在另一实施例中,得到的类别标注标签的标签类型数量为至少一个,则采用目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,包括:从获取到的类别标注标签中,选取出目标标签类型的类别标注标签,并将选取出的目标标签类型的类别标注标签作为拟合目标。具体可以从至少一个标签类型中依次选取一个标签类型作为目标标签类型,以选取出目标标签类型的类别标注标签。
[0075]
进一步地,基于拟合目标,并采用目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果。假设以类别标注标签1作
为拟合目标,将一个样本数据在不同特征维度下的样本特征作为式(1)所示的二分类的逻辑回归模型的输入x=(x1,x2,...,xd),以输出一个样本数据x的预测概率f(x)。进一步地获取下述式(5)所示的适用于二分类的对数损失函数的表达式。
[0076][0077]
其中,loss2表示第二损失值,f(xj)表示第j个样本数据为正样本的预测概率,yj表示第j个样本数据的标签,若该第j个样本数据的类别标注标签是拟合目标,则yj为1,否则为0。例如,当类别标注标签1为拟合目标时,若该第j个样本数据的类别标注标签是类别标注标签1,则yj为1,否则为0。
[0078]
在一实施例中,可以将每个样本数据的预测概率代入式(5)中的f(xj)以及基于每个样本数据的类别标注标签是否是拟合目标确定式(5)中的yj,从而使得式(5)可以输出第二损失值,进一步可以通过该第二损失值以及随机梯度下降法调整式(1)中的预测权重w=(w1,w2,...,wd),重复进行多次调整,当满足停止条件时,如达到指定数量的调整次数,或对数损失函数收敛就满足停止条件。将调整后的预测权重w=(w1,w2,...,wd)作为拟合结果,且基于拟合目标拟合处理得到的拟合结果,是与拟合目标关联的拟合结果。即调整后的预测权重w=(w1,w2,...,wd)是与拟合目标:类别标注标签1关联的拟合结果。接着可以又将类别标注标签2作为拟合目标,采用同样的方式得到与类别标注标签2关联的拟合结果。可理解的,假设存在m个类别标注标签,每个类别标注标签都存在关联的拟合结果,则第m个类别标注标签关联的拟合结果w=(w1,w2,...,wd),即相当于上述式(4)中的wm,即上述s202和s203中的目标权重。同时会得到多个二分类的逻辑回归模型,该多个二分类的逻辑回归模型即为上述s202中的拟合模型。
[0079]
s304、根据拟合结果所指示的重要度,将满足选取条件的特征维度作为特征转换过程中的转换依据;转换依据用于生成特征转换的可解释性分析结果。
[0080]
在一实现方式中,按照拟合结果所指示的重要度从大到小的顺序,依次选取出目标数量的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据,包括:假设一个样本数据包含有d个特征维度下的样本特征,则针对第m类别标注标签存在目标权重集合wm={w
1m
,w
2m
,...,w
dm
},可以按照目标权重集合wm={w
1m
,w
2m
,...,w
dm
}中的各个目标权重从大到小的顺序,依次选取出目标数量(可以人为设定)的目标权重,将该目标数量的目标权重对应的特征维度作为特征转换过程中的转换依据,且在特征转换过程中,一个样本数据中该目标数量的目标权重对应的特征维度下的样本特征越大,该一个样本数据越容易与第m类别标注标签对应的数据集中的样本数据生成相近特征,即特征转换的可解释性分析结果。
[0081]
在另一实现方式中,根据拟合结果所指示的重要度,选取出对应重要度大于重要度阈值的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据,包括:假设一个样本数据包含有d个特征维度下的样本特征,则针对第m类别标注标签存在目标权重集合wm={w
1m
,w
2m
,...,w
dm
},可以获取目标权重集合中大于权重阈值(可以人为设定)的目标权重,将大于权重阈值的目标权重对应的特征维度作为特征转换过程中的转换依据,且在特征转换过程中,一个样本数据中该大于权重阈值的目标权重对应的特征维度下的样本特征
越大,该一个样本数据越容易与第m类别标注标签对应的数据集中的样本数据生成相近特征,即特征转换的可解释性分析结果。
[0082]
上述特征转换的可解释性分析结果是第i网络隐层的可解释性分析结果。在可行的实施例中,还可以分析目标网络模型中第i网络隐层的决策逻辑(一种可解释性分析)。具体的,获取任一数据集中包含的每个样本数据的真实标签,并确定出对应同一真实标签的样本数量。基于对应同一真实标签的样本数量,及任一数据集中的样本数据总量,计算对应同一真实标签的样本占比,即对应同一真实标签的样本占比=对应同一真实标签的样本数量/任一数据集中的样本数据总量,从而得到不同真实标签分别对应的样本占比。再根据不同真实标签分别对应的样本占比,确定出该任一数据集对应最大样本占比的真实标签。假设一个样本数据中参考特征维度下的样本特征越大,该一个样本数据越容易与该任一数据集中的样本数据生成相近特征,则可以推出该一个样本数据中参考特征维度下的样本特征越大,第i网络隐层针对该一个样本数据的真实标签越倾向于预测为该任一数据集对应最大样本占比的真实标签,则第i网络隐层在特征转换时会使该一个样本数据特征转换后的特征向量与最大样本占比的真实标签下的样本数据对应的特征向量之间的相似度小于阈值。因此,最大样本占比的真实标签用于指示:特征转换生成的特征向量,与最大样本占比的真实标签下的样本数据对应的特征向量之间的相似度小于阈值。
[0083]
综上所示,本技术实施例提供的数据处理方法的流程如图6所示,包括:
①
获取目标网络模型,该目标网络模型可以包括多个网络隐层。
②
将至少一个样本数据输入目标网络模型,得到第l个网络隐层输出的样本表征集合x={x1,x2,
…
,xn},其中xj代表第j个样本数据的样本表征(即对应的特征向量)。
③
使用聚类算法,例如k-means算法,对样本表征集合进行聚类处理,从而将样本表征划分成两个类簇,根据样本表征所属的类簇,将至少一个样本数据划分为数据集x0和数据集x1(可以划分更多的数据集,此处以两个数据集作为示例)。
④
基于样本数据所在的数据集对应的聚类标签,确定样本数据的类别标注标签。
⑤
采用目标算法,拟合样本数据和样本数据的类别标注标签,得到拟合结果,通过拟合结果得到第l个网络隐层的重要特征维度,该重要特征维度是满足选取条件的特征维度。
⑤
基于第l个网络隐层的重要特征维度,确定第l个网络隐层在特征转换时的转换依据,并基于转换依据确定第l个网络隐层的可解释性分析结果。
⑥
将数据集x0中的各个样本数据作为对第l+1个网络隐层进行可解释性分析时的至少一个样本数据;以及将数据集x1中的各个样本数据作为对第l+1个网络隐层进行可解释性分析时的至少一个样本数据,从而得到对数据集x0和数据集x1的细分逻辑。通过这种方式,可以得到目标网络模型中每个网络隐层的可解释性分析结果。
[0084]
在本实施例中,可以在利用目标网络模型的网络隐层对样本数据进行特征转换得到样本表征之后,通过样本表征所反映出的样本数据的类别属性,对样本表征进行聚类处理,从而将样本数据划分到不同的数据集,再基于样本数据所在的数据集确定样本数据的类别标注标签,进一步通过逻辑回归模型,让样本数据拟合对应类别标注标签,可以得到目标权重,通过该目标权重可以知道各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度(影响程度),从而可以确定网络隐层在特征转换过程中,哪些特征维度比较重要,且知道特征维度会如何影响样本数据的类别标注标签的判别,从而可以确定特征维度是如何影响样本数据的特征转换,得到特征转换过程的转换依据以及可解释性分
析结果,可以实现对特征转换过程进行可解释性分析。
[0085]
在一实施例中,当目标网络模型中所有网络隐层都得到可解释性分析结果之后,可以基于各个网络隐层的可解释性分析结果,确定目标网络模型的决策路径。
[0086]
以下述图7作为示例进行说明,其中,census-income数据集包括从人口普查局数据库中抽样得到的样本数据,每个样本数据包含一个人的年电子资源获得量是否大于5万美元的真实标签,特征维度包括性别等基础属性,以及工作类型、受教育年限等信息。每个样本数据是在获得相应用户许可或者同意之后才获取的。另外,该目标网络模型包括第一网络隐层和第二网络隐层。
[0087]
在将census-income数据集中的各个样本数据输入第一网络隐层进行特征转换后,可以得到各个样本数据对应的特征向量,利用各个样本数据对应的特征向量,对各个样本数据进行聚类运算,可以将各个样本数据划分到不同的数据集,具体可以通过k-means算法实现。此处划分了两个数据集,其中,数据集1中正样本(年电子资源获得量大于5万美元)的占比为23.53%,数据集2中正样本的占比为100%。同时图7中的71所指示的部分为第一网络隐层进行特征转换的转换依据,即第一网络隐层的重要特征维度,其中一个样本数据中的数据集1指示的特征维度下的样本特征越大,该样本数据越容易被划分到数据集1,一个样本数据中的数据集2指示的特征维度下的样本特征越大,该样本数据越容易被划分到数据集2。可见,若一个人未婚、资本损失越大、工资类型为私人、学历为高中毕业、性别为女性时,第一网络隐层倾向于这个人电子资源获得量不超过5万美金;一个样本数据中的资本收益越高、受教育年限越长、已婚、性别为男性、学历是学士、学历是硕士时,第一网络隐层倾向于这个人的电子资源获得量超过5万美金。
[0088]
进一步地,由于数据集2中全是正样本,因此可以只对数据集1进行分析,即数据集1中的各个样本数据作为第二网络隐层进行可解释性分析的至少一个样本数据。同样通过划分数据集和拟合逻辑回归模型,得到数据集3和数据集4,以及第二网络隐层进行特征转换的转换依据(图7中72所指示的部分),数据集3中正样本的占比为0.7%,数据集4中正样本的占比为36.4%。若一个人从未结婚过、是清洁工、从事农业、最高学历是11年级时,目标网络模型倾向于这个人电子资源获得量超过5万美金的可能性更低;一个人每周工作时长越长、性别为男性、是专业技术人员时,目标网络模型倾向于这个人电子资源获得量超过5万美金的可能性会相对更高。
[0089]
通过上述示例可以看出,通过每个网络隐层的转换依据,就可以知道各个网络隐层是如何逐层预测一个人电子资源获得量是否会超过五万美元,因此可以得到目标网络模型的决策路径,可以解决深度神经网络等复杂模型不具有透明度的问题,提高目标网络模型的可解释性。
[0090]
另外,以下述图8作为示例继续进行补充说明,图8使用的目标网络模型用于判别用户是否购买候选物品(例如基金),其中,用户购买候选物品时,为正样本,用户不购买候选物品时,为负样本。目标网络模型使用的每个样本数据是在获得相应用户许可或者同意之后才获取的。其中,一个样本数据中的簇0指示的特征维度下的样本特征越大,该样本数据越容易被划分到簇0,一个样本数据中的簇1指示的特征维度下的样本特征越大,该样本数据越容易被划分到簇1。
[0091]
具体以图8中的路径1进行说明。在目标网络模型的第一网络隐层中,重要的正向
因素是用户近14天访问我的资产页面的天数、近92天的主站访问次数、昨日申购金额等,这些反映了用户的活跃程度,一般来说活跃程度越高的用户越可能申购,而基金公司在管基金的平均夏普率、该基金近一年来收益率等则反映了候选物品的质量,质量越高用户可能越感兴趣。此外,用户一天内对该基金的搜索点击次数直接反映了用户对该基金的偏好,也是越高越好;如果一个用户在这些正向指标上的值较低,反而是基金公司在管基金的最大回撤高,基金经理的管理基金的下行波动率高,同时用户的保险型基金页面访问次数高,则代表当前基金的表现可能不佳,高于用户的风险承受能力,因此用户的申购概率可能相对更低。(但不代表经过这一层后到簇0的用户全都是不申购用户,需要更细粒度的划分)。
[0092]
经过第一个网络隐层,簇0的正样本比例为0.4448,明显低于簇1的0.8849,说明模型已经区分了一些高转化样本;经过第二个网络隐层后,该簇0中的用户进一步可以划分为两个用户群:其中,如果30天内给该用户曝光该基金的次数较多(用户有一定认知),该基金上行波动率较高,基金的卡玛比率、昨日申购金额较高,则基金表现较好,用户仍然有较高概率购买,被分到该路径第二层的簇1中,正样本比例为0.6354;反之,如果这些指标较低,且该基金近一年最大回撤高,费率高、收益率排名值大(收益率越低收益率排名值越大),则用户的申购概率较低,进入该路径的簇0,正样本比例仅有0.1013。
[0093]
经过第二个网络隐层中,当前的簇0正样本比例已经很低了,但目标网络模型仍然需要进行进一步区分,如果近7天内给该用户曝光该基金的次数较多(近期印象),基金经理在管基金的平均展示收益率较高(基金经理水平),用户近7天内搜索点击该基金次数(用户兴趣),基金持有期3个月盈利概率较高,则用户仍然还是有一定概率购买;反之,如果该基金费率高,用户近一天赎回笔数高(有可能行情下行,用户想要退场),用户近12个月网贷还款月数多(用户缺少补入资金),则用户购买该候选基金的概率就会极低,到达路径1终点,正样本比例仅有0.006。
[0094]
其他路径也可照此分析,这里仅再针对路径6和路径8进行案例分析。
[0095]
针对路径6,在第一网络隐层中正向特征值较高的用户进入了第一层的簇1(第一个节点区分逻辑同路径2),如果该基金的昨日点击uv较高、昨日申购金额较高,昨日曝光人数/转化人数较多,则该基金的表现较好,同时,如果用户历史申购金额较多,申购该基金的用户平均申购金额也较多,说明高申购用户可能倾向于购买该基金,匹配度较高的用户会进入第二层的簇1,正样本比例达到了0.9461,反之,如果这些特征值较低,但是基金近15日滑动收益率排名大(收益率低),用户近31天申购指数的笔数较多,则进入簇0,正样本比例0.7693。
[0096]
当前节点的正样本比例仍然较高,说明用户仍然具有较高的申购意愿,模型更多需要区分用户的资产偏好:用户近30天微证券访问次数多,历史腾安基金保有量高,股票证券类rfm模型偏好得分较高等因素,说明用户倾向于进阶理财,而如果当前待排序的基金是进阶理财,用户近6个月内持有该基金的天数多,近期有搜索点击行为,则用户购买的概率大大提升,进入路径6的终点,正样本比例达到了0.8833。
[0097]
针对路径8,在第一层中正向特征值较高的用户进入了第一层的簇1(第一个节点区分逻辑同路径2,6),第二层正向特征值较高的进入了第二层的簇1,区分逻辑同路径6(该基金表现较好,用户申购金额较多),第三层中,如果用户的电子资源量+累计收益较高(说明保有量较高),且申购该基金的用户的平均电子资源量+保有量1万以上天数较长,则用户
的申购概率较大,同时,如果该基金近一年收益率较高、用户的安稳债基持仓产品数量多,并且该基金也属于稳健理财,则用户购买概率较高(用户资产偏好和该资产匹配)。
[0098]
可见,本技术对于金融场景中使用的目标网络模型具有较强的可解释能力,可以实现从输入到输出的决策路径的输出。另外,通过目标网络模型的决策路径,可以知道目标网络模型主要是在使用哪些特征维度进行分类预测,以及可以判别目标网络模型是否抓住了有意义的特征,因此可以对目标网络模型的特征选择算法进行改进。例如通过图8可以知道目标网络模型的各个网络隐层主要关注的特征维度,而其它特征维度可能是该目标网络模型不太关注的,因此目标网络模型在做分类预测时,可以只使用目标网络模型的决策路径上所包括的特征维度。
[0099]
可以理解的是,在本技术的具体实施方式中,涉及到样本数据等相关数据,当本技术以上实施例运用到具体产品或技术中时,需要获得用户许可或者同意,且相关数据的收集、使用和处理需要遵守相关国家和地区的相关法律法规和标准。
[0100]
上述详细阐述了本技术实施例的方法,为了便于更好地实施本技术实施例的上述方法,相应地,下面提供了本技术实施例的装置。请参见图9,图9是本技术实施例提供的一种数据处理装置的结构示意图,该数据处理装置90可以包括:
[0101]
获取单元901,用于获取至少一个样本数据,及任一样本数据的类别标注标签;一个样本数据包含一个或多个特征维度下的样本特征,所述任一样本数据的类别标注标签是对所述任一样本数据在不同特征维度下的样本特征进行特征转换后得到的;
[0102]
处理单元902,用于对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度;
[0103]
所述处理单元902,还用于根据所述拟合结果所指示的重要度,将满足选取条件的特征维度作为特征转换过程中的转换依据;所述转换依据用于生成特征转换的可解释性分析结果。
[0104]
在一实施例中,所述获取单元901具体用于:获取用于进行可解释性分析的目标算法;
[0105]
所述处理单元902具体用于:采用所述目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果。
[0106]
在一实施例中,所述处理单元902具体用于:对每个样本数据在不同特征维度下的样本特征进行特征转换,得到每个样本数据对应的特征向量;基于每个样本数据对应的特征向量,对所述至少一个样本数据进行聚类运算,以将所述至少一个样本数据划分到不同的数据集中,且一个数据集对应一个聚类标签;将任一样本数据所在数据集对应的聚类标签,作为所述任一样本数据的类别标注标签。
[0107]
在一实施例中,所述至少一个样本数据中每个样本数据对应的特征向量,是通过调用包含分类功能的目标网络模型的第i网络隐层进行特征转换得到的,所述目标网络模型包含n个网络隐层;其中,n为大于等于1的正整数,i为大于0且小于等于n的正整数;基于所述第i网络隐层对所述至少一个样本数据进行特征转换后得到的可解释性分析结果,被作为所述第i网络隐层的可解释性分析结果。
[0108]
在一实施例中,所述获取单元901具体用于:获取用于对所述目标网络模型中的第
i-1网络隐层进行可解释分析采用的至少一个参考样本数据,以及在对所述第i-1网络隐层进行可解释分析过程中对所述至少一个参考样本数据进行聚类运算后的得到的至少两个参考样本集;
[0109]
所述处理单元902具体用于:将任一参考样本集中包含的参考样本数据分别作为获取得到的至少一个样本数据。
[0110]
在一实施例中,所述获取单元901具体用于:获取将所述至少一个样本数据进行聚类运算后,得到的数据集总量,并基于所述数据集总量确定得到的每个数据集对应的集合编号;
[0111]
所述处理单元902具体用于:将一个数据集对应的集合编号作为所述一个数据集对应的聚类标签。
[0112]
在一实施例中,所述获取单元901具体用于:获取任一数据集中包含的每个样本数据的真实标签,并确定出对应同一真实标签的样本数量;
[0113]
所述处理单元902具体用于:基于对应同一真实标签的样本数量,及所述任一数据集中的样本数据总量,计算对应所述同一真实标签的样本占比,得到不同真实标签分别对应的样本占比;根据不同真实标签分别对应的样本占比,确定出对应最大样本占比的真实标签;所述最大样本占比的真实标签用于指示:特征转换生成的特征向量,与所述最大样本占比的真实标签下的样本数据对应的特征向量之间的相似度小于阈值。
[0114]
在一实施例中,所述处理单元902具体用于:采用所述目标算法对每个样本数据在不同特征维度下的样本特征进行标签预测处理,得到所述每个样本数据的类别预测结果;基于每个样本数据的类别预测结果及对应的类别标注标签,对所述目标算法的预测权重进行调整;将调整后的预测权重作为拟合结果。
[0115]
在一实施例中,所述获取单元901具体用于:从获取到的类别标注标签中,选取出目标标签类型的类别标注标签,并将选取出的目标标签类型的类别标注标签作为拟合目标;
[0116]
所述处理单元902具体用于:基于所述拟合目标,并采用所述目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,其中,基于所述拟合目标拟合处理得到的拟合结果,是与所述拟合目标关联的拟合结果。
[0117]
在一实施例中,得到的类别标注标签的标签类型数量为至少一个,所述处理单元902具体用于:从至少一个标签类型中依次选取一个标签类型作为目标标签类型,以选取出所述目标标签类型的类别标注标签。
[0118]
在一实施例中,所述处理单元902具体用于:按照拟合结果所指示的重要度从大到小的顺序,依次选取出目标数量的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据;或者,根据拟合结果所指示的重要度,选取出对应重要度大于重要度阈值的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据。
[0119]
可以理解的是,本技术实施例所描述的数据处理装置的各功能单元的功能可根据上述方法实施例中的方法具体实现,其具体实现过程可以参照上述方法实施例的相关描述,此处不再赘述。
[0120]
在本技术实施例中,可以获取至少一个样本数据以及任一样本数据的类别标注标
签,该任一样本数据的类别标注标签是对任一样本数据在不同特征维度下的样本特征进行特征转换后得到的,通过对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,可以得到拟合结果,该拟合结果可以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度,因此通过拟合结果所指示的重要度,可以将满足选取条件的特征维度作为特征转换过程中的转换依据,该转换依据可以用于生成特征转换的可解释性分析结果。通过本技术实施例,可以实现对特征转换过程进行可解释性分析。
[0121]
如图10所示,图10是本技术实施例提供的一种计算机设备的结构示意图,该计算机设备100内部结构如图10所示,包括:一个或多个处理器1001、存储器1002、通信接口1003。上述处理器1001、存储器1002和通信接口1003可通过总线1004或其他方式连接,本技术实施例以通过总线1004连接为例。
[0122]
其中,处理器1001(或称cpu(central processing unit,中央处理器))是计算机设备100的计算核心以及控制核心,其可以解析计算机设备100内的各类指令以及处理计算机设备100的各类数据,例如:cpu可以用于解析用户向计算机设备100所发送的开关机指令,并控制计算机设备100进行开关机操作;再如:cpu可以在计算机设备100内部结构之间传输各类交互数据,等等。通信接口1003可选的可以包括标准的有线接口、无线接口(如wi-fi、移动通信接口等),受处理器1001的控制用于收发数据。存储器1002(memory)是计算机设备100中的记忆设备,用于存放计算机程序和数据。可以理解的是,此处的存储器1002既可以包括计算机设备100的内置存储器,当然也可以包括计算机设备100所支持的扩展存储器。存储器1002提供存储空间,该存储空间存储了计算机设备100的操作系统,可包括但不限于:windows系统、linux系统、android系统、ios系统,等等,本技术对此并不作限定。处理器1001通过运行存储器1002中存储的计算机程序,执行如下操作:
[0123]
获取至少一个样本数据,及任一样本数据的类别标注标签;一个样本数据包含一个或多个特征维度下的样本特征,所述任一样本数据的类别标注标签是对所述任一样本数据在不同特征维度下的样本特征进行特征转换后得到的;
[0124]
对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度;
[0125]
根据所述拟合结果所指示的重要度,将满足选取条件的特征维度作为特征转换过程中的转换依据;所述转换依据用于生成特征转换的可解释性分析结果。
[0126]
在一实施例中,所述处理器1001具体用于:获取用于进行可解释性分析的目标算法;采用所述目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果。
[0127]
在一实施例中,所述处理器1001具体用于:对每个样本数据在不同特征维度下的样本特征进行特征转换,得到每个样本数据对应的特征向量;基于每个样本数据对应的特征向量,对所述至少一个样本数据进行聚类运算,以将所述至少一个样本数据划分到不同的数据集中,且一个数据集对应一个聚类标签;将任一样本数据所在数据集对应的聚类标签,作为所述任一样本数据的类别标注标签。
[0128]
在一实施例中,所述至少一个样本数据中每个样本数据对应的特征向量,是通过
调用包含分类功能的目标网络模型的第i网络隐层进行特征转换得到的,所述目标网络模型包含n个网络隐层;其中,n为大于等于1的正整数,i为大于0且小于等于n的正整数;基于所述第i网络隐层对所述至少一个样本数据进行特征转换后得到的可解释性分析结果,被作为所述第i网络隐层的可解释性分析结果。
[0129]
在一实施例中,所述处理器1001具体用于:获取用于对所述目标网络模型中的第i-1网络隐层进行可解释分析采用的至少一个参考样本数据,以及在对所述第i-1网络隐层进行可解释分析过程中对所述至少一个参考样本数据进行聚类运算后的得到的至少两个参考样本集;将任一参考样本集中包含的参考样本数据分别作为获取得到的至少一个样本数据。
[0130]
在一实施例中,所述处理器1001具体用于:获取将所述至少一个样本数据进行聚类运算后,得到的数据集总量,并基于所述数据集总量确定得到的每个数据集对应的集合编号;将一个数据集对应的集合编号作为所述一个数据集对应的聚类标签。
[0131]
在一实施例中,所述处理器1001具体用于:获取任一数据集中包含的每个样本数据的真实标签,并确定出对应同一真实标签的样本数量;基于对应同一真实标签的样本数量,及所述任一数据集中的样本数据总量,计算对应所述同一真实标签的样本占比,得到不同真实标签分别对应的样本占比;根据不同真实标签分别对应的样本占比,确定出对应最大样本占比的真实标签;所述最大样本占比的真实标签用于指示:特征转换生成的特征向量,与所述最大样本占比的真实标签下的样本数据对应的特征向量之间的相似度小于阈值。
[0132]
在一实施例中,所述处理器1001具体用于:采用所述目标算法对每个样本数据在不同特征维度下的样本特征进行标签预测处理,得到所述每个样本数据的类别预测结果;基于每个样本数据的类别预测结果及对应的类别标注标签,对所述目标算法的预测权重进行调整;将调整后的预测权重作为拟合结果。
[0133]
在一实施例中,所述处理器1001具体用于:从获取到的类别标注标签中,选取出目标标签类型的类别标注标签,并将选取出的目标标签类型的类别标注标签作为拟合目标;基于所述拟合目标,并采用所述目标算法,对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,得到拟合结果,其中,基于所述拟合目标拟合处理得到的拟合结果,是与所述拟合目标关联的拟合结果。
[0134]
在一实施例中,得到的类别标注标签的标签类型数量为至少一个;所述处理器1001具体用于:从至少一个标签类型中依次选取一个标签类型作为目标标签类型,以选取出所述目标标签类型的类别标注标签。
[0135]
在一实施例中,所述处理器1001具体用于:按照拟合结果所指示的重要度从大到小的顺序,依次选取出目标数量的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据;或者,根据拟合结果所指示的重要度,选取出对应重要度大于重要度阈值的特征维度,并将选取出的特征维度作为特征转换过程中的转换依据。
[0136]
具体实现中,本技术实施例中所描述的处理器1001、存储器1002及通信接口1003可执行本技术实施例提供的一种数据处理方法中所描述的实现方式,也可执行本技术实施例提供的一种数据处理装置中所描述的实现方式,在此不再赘述。
[0137]
在本技术实施例中,可以获取至少一个样本数据以及任一样本数据的类别标注标
签,该任一样本数据的类别标注标签是对任一样本数据在不同特征维度下的样本特征进行特征转换后得到的,通过对各样本数据在不同特征维度下的样本特征,按照对应的类别标注标签进行拟合处理,可以得到拟合结果,该拟合结果可以指示各样本数据被添加相应类别标注标签的过程中,不同特征维度对应的重要度,因此通过拟合结果所指示的重要度,可以将满足选取条件的特征维度作为特征转换过程中的转换依据,该转换依据可以用于生成特征转换的可解释性分析结果。通过本技术实施例,可以实现对特征转换过程进行可解释性分析。
[0138]
本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,当其在计算机设备上运行时,使得计算机设备执行上述任一可能实现方式的数据处理方法。其具体实现方式可参考前文描述,此处不再赘述。
[0139]
本技术实施例还提供了一种计算机程序产品,所述计算机程序产品包括计算机程序或计算机指令,所述计算机程序或计算机指令被处理器执行时实现本技术实施例提供的数据处理方法的步骤。其具体实现方式可参考前文描述,此处不再赘述。
[0140]
本技术实施例还提供了一种计算机程序,所述计算机程序包括计算机指令,所述计算机指令存储在计算机可读存储介质中,计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,处理器执行所述计算机指令,使得所述计算机设备执行本技术实施例提供的数据处理方法。其具体实现方式可参考前文描述,此处不再赘述。
[0141]
需要说明的是,对于前述的各个方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某一些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本技术所必须的。
[0142]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read-only memory,rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
[0143]
以上所揭露的仅为本技术部分实施例而已,当然不能以此来限定本技术之权利范围,因此依本技术权利要求所作的等同变化,仍属本技术所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1