一种基于多任务多视角学习的多目标软件缺陷预测方法
1.本发明提供一种基于多任务多视角学习的多目标软件缺陷预测方法,属于软件缺陷预测领域。
背景技术:
2.准确而有效的软件缺陷预测对于软件可靠性保证和维护十分重要。然而,软件功能的丰富和软件结构的日益复杂对软件缺陷预测方法提出了更高的要求。因此,软件缺陷预测多年来一直是软件工程研究中的活跃领域。软件缺陷预测工作的核心就是,主要包含以下三项预测目标:
3.(1)预测代码的缺陷倾向性:预测目标软件的待测代码中是否包含缺陷;
4.(2)预测代码的缺陷位置:预测软件代码中的缺陷位置;
5.(3)预测代码的缺陷类型:预测软件代码中的缺陷类型。
6.然而,常见的缺陷预测方法大多数仅能够完成上述目标中的其中一种,即为单目标缺陷预测方法。它们仅能够提供某一个方面的缺陷预测信息,因此对开发人员进行缺陷挖掘的帮助相对有限。同时,针对不同的缺陷预测目标采用不同的缺陷预测方法又会大大增加缺陷预测工作的操作复杂度与时间消耗,从而导致可用性较差。因此,研发一个多目标的软件缺陷方法能够同时准确地完成多项缺陷预测目标,能够大大提升缺陷预测的效率,是十分有意义的。同时,多任务多视角学习是一种新颖的机器学习方法,它能够充分利用来自不同视角的信息从而有效的学习多个相关任务。它在计算机视觉与自然语言处理领域的优秀表现证明了,采取多任务多视角神经网络模型能够有效地提升模型的表现。并且,静态分析方法是一种通过直接扫描目标代码来提取缺陷警告的方法,能够提供充分的多个视角的缺陷信息,例如缺陷的位置信息、缺陷的类型信息等。因此本发明选择通过多任务多视角学习与静态分析方法构建一个多目标软件缺陷预测方法。
7.本发明提供了一种基于多任务多视角学习的多目标软件缺陷预测方法,能够基于目标软件已知缺陷情况的历史代码对未知缺陷情况的待测代码中的缺陷进行预测。它基于集成静态分析方法从源代码中提取了缺陷的空间分布和语义特征,深度挖掘了多视角的缺陷信息。之后,所构建的多任务多视角神经网络模型具有强大的学习能力,可以充分考虑各个任务与各个视角的特征间的关联关系,从而同时预测出待测代码的缺陷的倾向性、位置和类型。它充分考虑了多个软件缺陷预测任务之间和特征之间的相关性,并分享各个任务中学习的经验,从而有效地提高软件缺陷预测的效率与准确率,并且显着地减少了静态分析工具的误报和漏报情况。本发明能够从多个角度对软件开发者提供更加全面而准确的缺陷预测信息,从而高效的完成缺陷挖掘并有效地提升软件的质量与可靠性。
技术实现要素:
8.(一)目的
9.本发明一种基于多任务多视角学习的多目标软件缺陷预测方法,能够基于目标软
件已知缺陷情况的历史代码对未知缺陷情况的待测代码中的缺陷进行预测,属于软件缺陷预测领域。本发明方法可以解决传统软件缺陷预测方法仅能完成一项缺陷预测目标而对不同的缺陷预测目标采用不同预测方法时,使用复杂度与资源消耗较大的难题,并且能够有效地改善静态分析工具的误报与漏报情况。本发明能够基于集成静态分析方法提取包含代码度量特征、缺陷空间结构特征与缺陷典型语义特征的多视角特征信息。通过本发明所构建的多任务多视角神经网络模型,能够基于所提取的多视角特征信息同时完成目标代码的缺陷倾向性、位置与类型预测,准确而高效地提供多个方面的缺陷预测信息,大幅度改善静态分析的漏报与误报情况,帮助开发者完成有效的缺陷挖掘。
10.(二)技术方案
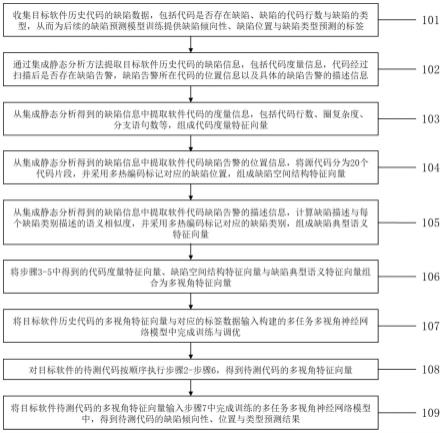
11.本发明一种基于多任务多视角学习的多目标软件缺陷预测方法,能够基于已知缺陷情况的目标软件的历史代码,对未知缺陷情况的待测代码中的缺陷进行预测,其具体实施步骤如下:如图1所示;
12.步骤1:收集目标软件历史代码的缺陷数据,包括代码是否存在缺陷、缺陷的代码行数与缺陷的类型,从而为后续的缺陷预测模型训练提供缺陷倾向性、缺陷位置与缺陷类型预测的标签;
13.步骤2:通过集成静态分析方法提取目标软件历史代码的缺陷信息,包括代码度量信息,代码经过扫描后是否存在缺陷告警,缺陷告警所在代码的位置信息以及具体的缺陷告警的描述信息;
14.步骤3:从集成静态分析得到的缺陷信息中提取软件代码的度量信息,包括代码行数、圈复杂度、分支语句数等,组成代码度量特征向量;
15.步骤4:从集成静态分析得到的缺陷信息中提取软件代码缺陷告警的位置信息,将源代码分为20个代码片段,并采用多热编码标记对应的缺陷位置,组成缺陷空间结构特征向量;
16.步骤5:从集成静态分析得到的缺陷信息中提取软件代码缺陷告警的描述信息,计算缺陷描述与每个缺陷类别描述的语义相似度,并采用多热编码标记对应的缺陷类别,组成缺陷典型语义特征向量;
17.步骤6:将步骤3-5中得到的代码度量特征向量、缺陷空间结构特征向量与缺陷典型语义特征向量组合为多视角特征向量;
18.步骤7:将目标软件历史代码的多视角特征向量与对应的标签数据输入构建的多任务多视角神经网络模型中完成训练与调优;
19.步骤8:对目标软件的待测代码按顺序执行步骤2-步骤6,得到待测代码的多视角特征向量;
20.步骤9:将目标软件待测代码的多视角特征向量输入步骤7中完成训练的多任务多视角神经网络模型中,得到待测代码的缺陷倾向性、位置与类型预测结果。
21.通过以上步骤,可以基于目标软件已知缺陷情况的历史代码对未知缺陷情况的待测代码中缺陷的有无,缺陷位置与缺陷类型同时进行预测,从而解决传统软件缺陷预测方法仅能完成一项缺陷预测目标而对不同的缺陷预测目标采用不同预测方法时使用复杂度与资源消耗较大的难题,并且能够有效地改善静态分析工具的误报与漏报情况。本发明能够基于集成静态分析与多任务多视角模型同时完成目标代码的缺陷倾向性、位置与类型预
测,准确而高效地提供多个方面的缺陷预测信息,帮助开发者完成有效的缺陷挖掘。本发明的原理示意图如图2所示。本发明基于使用多个静态分析方法s1至sn对带分析软件的源代码f至fn得到的静态分析结果,之后对静态分析结果进行集成,提取其中的代码度量信息,代码经过扫描后是否存在缺陷告警,缺陷告警所在代码的位置信息以及具体的缺陷告警的描述信息。之后从集成静态分析结果中,提取出多视角特征,包含代码度量特征、缺陷空间结构特征与缺陷典型语义特征,并生成多视角特征向量。将多视角特征向量输入训练调优后的多任务多视角神经网络模型中,即可同时完成代码的缺陷倾向性预测、缺陷位置预测与缺陷类型预测,并得到相应的多目标缺陷预测结果。此时,本发明可完成准确而高效的多目标软件缺陷预测,并且有效地改善静态分析工具的漏报与误报情况。
22.其中,步骤1中所述的“收集目标软件历史代码的缺陷数据,包括代码是否存在缺陷、缺陷的代码行数与缺陷的类型,从而为后续的缺陷预测模型训练提供缺陷倾向性、缺陷位置与缺陷类型预测的标签”。其具体做法如下:从软件缺陷库或缺陷数据集中收集目标软件历史代码的缺陷信息,目标软件代码可以由常见的c/c++语言或java语言编写。编写自动化提取工具将缺陷与否、缺陷的位置与缺陷的具体描述进行提取。之后通过热编码生成对应的缺陷倾向性、缺陷位置与缺陷类型预测的标签,并使用csv文件进行统一储存。
23.其中,步骤2中所述的“通过集成静态分析方法提取目标软件历史代码的缺陷信息,包括代码度量信息,代码是否存在缺陷,缺陷所在代码位置以及具体的缺陷描述信息”。其具体做法如下:通过调用对应语言的多个静态分析工具对目标软件历史代码的缺陷进行扫描分析,将多个静态分析工具生成的不同静态分析结果进行提取与集成。其中,代码度量结果通过代码度量软件进行提取,而缺陷分析结果通过开源的静态分析工具进行提取,包括缺陷位置信息与具体描述信息。提取后的缺陷信息通过csv文件进行统一储存。
24.其中,步骤3中所述的“从集成静态分析得到的缺陷信息中提取软件代码的度量信息,包括代码行数、圈复杂度、分支语句数等,组成代码度量特征向量”。其具体做法如下:从步骤2中提取的缺陷信息中筛选出11个代码度量指标,包括代码行数、除去空行后的代码行数、语句数、分支语句百分比、注释百分比、方法数、最复杂方法所在行数、最深嵌套块所在行数、最大嵌套深度、平均嵌套深度与圈复杂度。将上述指标合成为一个一维向量,即为代码度量特征向量。它是后续步骤训练预测模型时所需的输入特征的一部分。如果用f1至f
11
分别表示这11个代码度量指标,则代码度量特征向量可以表示为:
25.feature1=[f1,f2,f3,...,f
11
]。
[0026]
其中,步骤4中所述的“从集成静态分析得到的缺陷信息中提取软件代码缺陷告警的位置信息,将源代码分为20个代码片段,并采用多热编码标记对应的缺陷位置,组成缺陷空间结构特征向量”。其具体做法如下:从步骤2中提取的缺陷信息中筛选出缺陷所在的代码行数,将代码平均分为20个片段后,通过热编码方式针对缺陷告警行数所在的片段进行标记,生成位置标记向量。并且在标记时,针对每个工具的结果根据告警的严重程度将告警分为error与warning两类。将每个工具告警的缺陷位置标记向量进行组合,则可以得到缺陷空间结构特征向量。它也是后续步骤训练预测模型时所需的输入特征的一部分。如果用和分别表示20段代码中的error告警数量与warning告警数量,则缺陷空间结构特征向量可以表示为:
[0027]
其中代表向量间拼接。
[0028]
其中,步骤5中所述的“从集成静态分析得到的缺陷信息中提取软件代码缺陷告警的描述信息,计算缺陷描述与每个缺陷类别描述的语义相似度,并采用多热编码标记对应的缺陷类别,组成缺陷典型语义特征向量”。其具体做法如下:从步骤2中提取的缺陷信息中筛选出缺陷告警的具体描述,计算缺陷告警的描述与缺陷类型描述的语义相似度,从而通过热编码方式针对缺陷的类型进行标记。其中,我们采用基于common weakness enumeration的缺陷分类方法seven pernicious kingdoms,它将缺陷分为以下几个类别:如表1所示;
[0029]
表1
[0030][0031]
之后在标记时,分别计算缺陷描述与缺陷类别名称的相似度,和缺陷描述与缺陷类别内容的相似度,全面地考察该缺陷描述的典型类型,并组成缺陷典型语义特征向量。它是后续步骤训练预测模型时所需的输入特征的最后一部分。如果用和分别表示缺陷告警的描述与8个缺陷类型名称和缺陷类型描述的相似度,则缺陷典型语义特征向量可以表示为:
[0032]
其中代表向量间拼接。
[0033]
其中,步骤6中所述的“将步骤3-5中得到的代码度量特征向量、缺陷空间结构特征向量与缺陷典型语义特征向量组合为多视角特征向量”。其具体做法如下:在步骤2-步骤5之后,已经得到了目标软件历史代码的度量特征向量、缺陷空间结构特征向量与缺陷典型语义特征向量。则将上述三个向量进行顺序拼接,得到多视角特征向量,即:
[0034][0035]
其中,步骤7中所述的“将目标软件历史代码的多视角特征向量与对应的标签数据输入构建的多任务多视角神经网络模型中进行训练调优”。其具体做法如下:将目标软件历史代码的多视角特征向量作为构建的多任务多视角神经网络模型的输入特征,以对应的标签数据作为标准输出,配置好训练参数后开展多任务多视角神经网络模型的训练并自动化地完成模型调优。其中,所构建的神经网络模型结构,如下图3所示。它主要包含三个特征编码器与三个任务解码器。其中每个特征编码器都由一个卷积神经网络层(convolutional neural networks layer)、一个门控循环单元网络层(gated recurrent units layer)与两个全连接网络层组成,用cgru来表示,且每个编码器对应来自一个视角的输入特征;而每个解码器均由一个门控循环单元网络层与两个全连接网络层组成,用gru来表示,且每个解码器对应一种预测任务。同时,在编码器完成对于输入的多视角特征向量的编码后,通过向量拼接层进行组合,并输入到空间注意力层中进行训练,获取不同特征的空间重要性并完成多视角特征融合,使得解码器根据不同特征的空间重要性进行有效的解码。最终,三个解码器在训练后能够分别完成缺陷倾向性预测、缺陷位置预测与缺陷类型预测任务。即基于目标软件历史代码调优后的模型,可以用来完成后续针对目标软件待测代码的缺陷预测。
[0036]
其中,步骤8所述的“对目标软件的待测代码按顺序执行步骤2-步骤6,得到待测代码的多视角特征向量”。其具体做法如下:对目标软件的待测代码进行预测时,需要重复步骤2至步骤6,分别得到目标软件待测代码的代码度量特征向量、缺陷空间结构特征向量与缺陷典型语义特征向量,并组合为多视角特征向量。
[0037]
其中,步骤9所述的“将目标软件待测代码的多视角特征向量输入步骤7中完成训练的多任务多视角神经网络模型中,得到待测代码的缺陷倾向性、位置与类型预测结果”。其具体做法如下:将步骤8中的目标软件待测代码的多视角特征数据输入至步骤7中训练完成的多任务多视角神经网络模型,则可以获得待测代码的缺陷倾向性、位置与类型预测结果。与原始的静态分析结果相比,模型优化后的结果使漏报误报情况得到了极大的改善,能够准确而高效地实现缺陷的倾向性、位置与类型预测目标。
[0038]
(三)优点及功效
[0039]
本发明一种基于多任务多视角学习的多目标软件缺陷预测方法,属于软件缺陷预测领域。本发明方法可以解决传统软件缺陷预测方法仅能完成一项缺陷预测目标而对不同的缺陷预测目标采用不同预测方法时使用复杂度与资源消耗较大的难题,并且能够有效地改善静态分析工具的误报与漏报情况。本发明能够基于集成静态分析方法提取包含代码度量特征、缺陷空间结构特征与缺陷典型语义特征的多视角特征信息。通过本发明所构建的多任务多视角神经网络模型,能够基于所提取的多视角特征信息同时完成目标代码的缺陷倾向性、位置与类型预测,准确而高效地提供多个方面的缺陷预测信息,大幅度改善静态分
析的漏报与误报情况,帮助开发者完成有效的缺陷挖掘。
附图说明
[0040]
图1是本发明实施例提供的方法流程图。
[0041]
图2是本发明实施例提供的一种基于多任务多视角学习的多目标软件缺陷预测方法的原理示意图。
[0042]
图3是神经网络模型结构。
[0043]
图4a是训练过程中三项预测任务的损失函数值变化曲线;其中,实线为训练集结果,而虚线为验证集结果。
[0044]
图4b是训练过程中三项预测任务的预测准确率变化曲线;其中,实线为训练集结果,而虚线为验证集结果。
具体实施方式
[0045]
为了更具体地说明本发明实施例中的具体实施方式,下面将以一个开源项目juliettestsuite 1.3中的代码数据集为例,详细介绍本发明的具体实施方式。它包含用c与c++语言编写的64000多个测试用例与对应的缺陷信息,能够适用并验证本发明中的方法。
[0046]
(1):收集目标数据集的缺陷数据,包括代码是否存在缺陷、缺陷的代码行数与缺陷的类型,作为相应缺陷预测任务的标签。之后将目标数据集分为历史代码与待测代码,其中历史代码占80%而待测代码占20%。在后续的缺陷预测过程中,本发明中的缺陷预测模型能够在基于目标数据集历史代码的训练调优后,对目标数据集待测代码的缺陷倾向性、缺陷位置与缺陷类型进行预测;
[0047]
(2):通过集成静态分析方法提取目标软件历史代码的缺陷信息,包括代码度量信息,代码经过扫描后是否存在缺陷告警,缺陷告警所在代码的位置信息以及具体的缺陷告警的描述信息,保存为csv文件。其中,我们选择了三个常见的针对c/c++语言的开源静态分析工具,分别为cppcheck,flawfinder和tscancode;
[0048]
(3):从集成静态分析得到的缺陷信息中提取软件代码的11种度量信息,包括代码行数、除去空行后的代码行数、语句数、分支语句百分比、注释百分比、方法数、最复杂方法所在行数、最深嵌套块所在行数、最大嵌套深度、平均嵌套深度与圈复杂度,即feature1;
[0049]
(4):从集成静态分析得到的缺陷信息中提取软件代码缺陷告警的位置信息,将源代码分为20个代码片段,并采用多热编码标记对应的缺陷位置,组成缺陷空间结构特征向量,即feature2;
[0050]
(5):从集成静态分析得到的缺陷信息中提取软件代码缺陷告警的描述信息,计算缺陷描述与每个缺陷类别描述的语义相似度,并采用多热编码标记对应的缺陷类别,组成缺陷典型语义特征向量,即feature3;
[0051]
(6):将步骤3-5中得到的代码度量特征向量、缺陷空间结构特征向量与缺陷典型语义特征向量组合为多视角特征向量,即feature。部分文件得到的多视角特征向量的前11列,如表2所示:
[0052]
表2
[0053]
namelinestrue_linesstatementspercent brpercent linfunctionsline numbline numbmaximumbaverage blocaverage ccwe134_uncontrolled_format_stri148995710.5235325051.562.2cwe127_buffer_underread__mallo1541016910.131.85573141.72.4cwe190_integer_overflow__int_m1891327521.324.37483631.453.29cwe124_buffer_underwrite__new_157102606.729.35593331.571.8cwe134_uncontrolled_format_stri895430025.86353820.91cwe23_relative_path_traversal__w196144751216.84668641.613.5cwe190_integer_overflow__int64_1781237611.824.210593231.181.9cwe124_buffer_underwrite__new_5532185.6400354531.441.5cwe122_heap_based_buffer_over1731228411.927.78375131.252.25cwe190_integer_overflow__int64_1056144029.55302210.71cwe195_signed_to_unsigned_con834229037.34242610.661cwe121_stack_based_buffer_over1167448030.24284631.231cwe122_heap_based_buffer_over1025636028.44303210.691cwe23_relative_path_traversal__c123743910.3264375651.262.25
[0054]
(7):将目标软件历史代码的多视角特征向量feature与第一步得到的对应的标签数据输入构建如前文所述的多任务多视角神经网络模型中完成训练与调优,我们训练了100个循环,并且在训练集中选取了10%的样本作为验证集,验证训练过程是否出现欠拟合或过拟合情况,可以得到以下的训练过程记录;
[0055]
由图4a和图4b可以得到,训练过程中训练精度不断提升且损失函数值不断下降并趋于稳定,同时在验证集中并未展示出过拟合或欠拟合的状况,依然能够保持较高的精度,因此训练与调优过程是成功的,可以进行接下来的针对待测代码的缺陷预测。
[0056]
(8):对目标软件的待测代码按顺序执行步骤2-步骤6,得到待测代码的多视角特征向量;
[0057]
(9):将目标软件待测代码的多视角特征向量输入步骤7中完成训练的多任务多视角神经网络模型中,得到待测代码的缺陷倾向性、位置与类型预测结果,具体内容如下:
[0058]
1)缺陷倾向性预测结果,如表3所示;
[0059]
表3
[0060][0061][0062]
其中,acc表示准确度accuracy,rec表示召回率recall,pre表示精准率precision,f表示f1-measure评价指标。它们均为越高越好,且rec与pre均可以反应各个预测方法的误报与漏报情况。而下标中avg表示所有代码文件计算出的平均值。因此我们可以看出,本发明中的方法在完成缺陷倾向性预测时,与三种静态分析工具相比在准确度、召回率、精准率等评价指标方面均有较大的提升,同时有效地减少静态分析工具的漏报误报现象,能够完成有效的缺陷倾向性预测。
[0063]
2)缺陷位置预测结果,如表4所示;
[0064]
表4
[0065]
metriccppchecktscancodeflawfinderproposedsub
acc
0.96820.96800.95350.9928
sub
pre
0.48670.26440.10810.9018sub
rec
0.01140.00410.06530.8723
[0066]
其中,sub表示模型输出的结果,而下标中的acc代表准确度accuracy,rec表示召回率recall,pre表示精准率precision。它们均为越高越好,且rec与pre均可以反应各个预测方法的误报与漏报情况。因此我们可以看出,本发明中的方法在完成缺陷位置预测时,与三种静态分析工具相比在准确度、召回率、精准率等评价指标方面均有较大的提升,同时有效地减少静态分析工具的漏报误报现象,能够完成有效的缺陷位置预测。
[0067]
3)缺陷类型预测结果,如表5所示;
[0068]
表5
[0069]
metriccppchecktscancodeflawfinderproposedsub
acc
0.86590.86030.84370.9879sub
pre
0.40460.21770.27980.9545sub
rec
0.00510.01920.10190.9485
[0070]
其中,sub表示模型输出的结果,而下标中的acc代表准确度accuracy,rec表示召回率recall,pre表示精准率precision。它们均为越高越好,且rec与pre均可以反应各个预测方法的误报与漏报情况。因此我们可以看出,本发明中的方法在完成缺陷类型预测时,与三种静态分析工具相比在准确度、召回率、精准率等评价指标方面同样均有较大的提升,同时有效地减少静态分析工具的漏报误报现象,能够完成有效的缺陷类型预测。
[0071]
4)结果总结:
[0072]
基于上述结果,我们可以验证本发明中的方法能够同时准确而有效地预测出待测代码中的缺陷倾向性、缺陷位置与缺陷类型,从而有效地提高软件缺陷预测的效率与准确率。并且与三种静态分析工具相比,本发明中的方法显着地减少了误报和漏报情况。因此,本发明能够从多个角度对软件开发者提供更加全面而准确的缺陷预测信息,从而高效的完成缺陷挖掘并有效地提升软件的质量与可靠性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1