数据处理方法、装置、存储介质及电子装置与流程
本技术涉及数据湖,具体而言,涉及一种数据处理方法、装置、存储介质及电子装置。
背景技术:
1、数据湖是一个存储各种各样原始数据的大型仓库,数据湖中的数据可供存取、处理、分析及传输。数据湖从企业的多个业务系统获取原始数据,简称为数据入湖,目前hadoop是最常用的部署数据湖的技术。
2、相关技术中,通过手动编写代码的方式,根据业务系统的数据模型对数据表逐一进行定制化代码开发,每次在数据湖中添加新的数据表都需要定制化开发。开发时间与需要开发的数据表数量、数据表的字段数量呈正相关,数据表数量越多,每张表的字段数量越多,那么每张表的开发工作量就越大,因此手动开发方式存在开发效率低,还无法保证代码质量,可能发生字段漏写、写错等技术问题;而且采用手动编写代码的方式不具备扩展性与可复用性,导致容易出错和测试成本较大。
3、针对相关技术中手动执行数据入湖操作效率低和容易出错的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术提供一种数据处理方法、装置、存储介质及电子装置,以解决相关技术中手动执行数据入湖操作效率低和容易出错的问题。
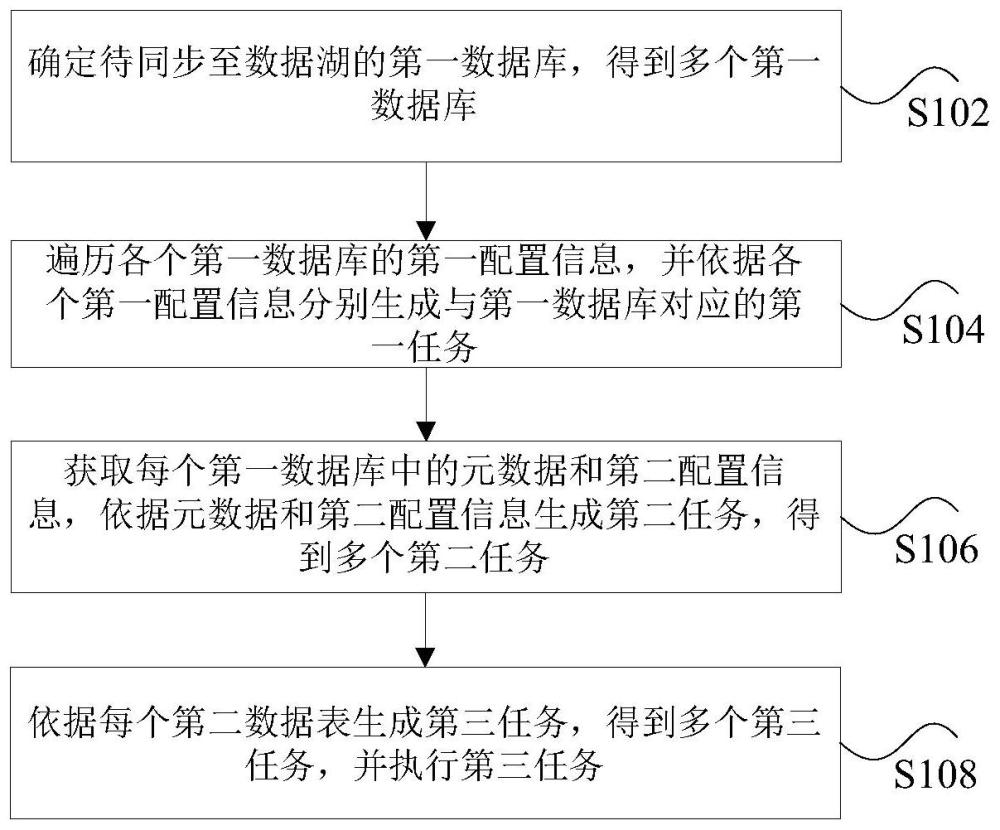
2、根据本技术的一个方面,提供了一种数据处理方法。该方法包括:确定待同步至数据湖的第一数据库,得到多个第一数据库,其中,第一数据库为各应用系统的数据库;遍历各个第一数据库的第一配置信息,并依据各个第一配置信息分别生成与第一数据库对应的第一任务,其中,第一任务用于指示建立第一数据库和数据湖中的第二数据库的关联关系;获取每个第一数据库中的元数据和第二配置信息,依据元数据和第二配置信息生成第二任务,得到多个第二任务,其中,第二任务用于指示在第二数据库中构建第二数据表,第二配置信息为第二数据表的配置信息;依据每个第二数据表生成第三任务,得到多个第三任务,并执行第三任务,其中,第三任务用于指示将第一数据表中的数据同步至数据湖,第一数据表为第一数据库中的数据表。
3、可选地,在遍历各个第一数据库的第一配置信息之后,该方法还包括:判断第一数据库是否设置有目标任务;在第一数据库设置有目标任务的情况下,检测目标任务是否完成,其中,按照预设时长轮询目标任务,并在查询到目标任务的目标参数为预设数值的情况下,确定目标任务完成;在目标任务完成的情况下,执行依据各个第一配置信息分别生成与第一数据库对应的第一任务的步骤。
4、可选地,依据各个第一配置信息分别生成与第一数据库对应的第一任务包括:在第一配置信息中获取第一数据库的第一数据库名称和第一数据库地址;在数据湖中确定第一数据库名称和第一数据库地址关联的第二数据库,得到目标第二数据库,并确定目标第二数据库的第二数据库名称和第二数据库地址;依据第一数据库名称、第一数据库地址、第二数据库名称和第二数据库地址建立第一数据库和目标第二数据库的关联关系。
5、可选地,在获取每个第一数据库中的元数据和第二配置信息之后,该方法还包括:判断元数据对应的数据是否为首次同步至数据湖的数据;在元数据对应的数据为首次同步至数据湖的数据的情况下,在数据湖中建立数据库,得到第一数据库关联的第二数据库。
6、可选地,执行第三任务包括:在第一数据库中确定待同步至数据湖的数据对应的第一数据表的类型;判断第一数据表的类型是否是第一类型,并在第一数据表的类型为第一类型时,通过增量同步的方式将第一数据库中的数据同步至数据湖,其中,第一类型的第一数据表为数据湖中的历史数据未发生变化的第一数据表;在第一数据表的类型不是第一类型的情况下,判断第一数据表的类型是否是第二类型,并在第一数据表的类型为第二类型时,通过全量同步的方式将第一数据库中的数据同步至数据湖,其中,第二类型的第一数据表为字典码值类的第一数据表;在第一数据表的类型不是第一类型且不是第二类型时,通过增量同步的方式将第一数据库中的数据同步至数据湖。
7、可选地,在执行第三任务之前,该方法还包括:判断第一数据表的结构与数据湖中的第二数据表的结构是否相同;在第一数据表的结构与数据湖中的第二数据表的结构不相同的情况下,更新第二数据表的结构,以使得更新后的第二数据表的结构与第一数据表的结构匹配。
8、可选地,在依据第二数据表生成多个第三任务,并执行第三任务之后,该方法还包括:获取第二任务的并行数,得到第一并行数,并获取第三任务的并行数,得到第二并行数;判断各个第二数据库是否携带有目标标志,其中,目标标志用于指示第三任务执行结束;在各个第二数据库均携带有目标标志的情况下,确定起始节点和结束节点,根据第一数据库的数量确定多个第一分支,根据第二任务的第一并行数确定第二分支,根据第三任务的第二并行数确定第三分支,并根据第一数据库和第二任务的关系确定第一连接关系,根据第二任务和第三任务的关系确定第二连接关系;在起始节点和结束节点之间根据第一连接关系连接第一分支和第二分支,并根据第二连接关系连接第二分支和第三分支,得到有向无环图。
9、根据本技术的另一方面,提供了一种数据处理装置。该装置包括:确定单元,用于确定待同步至数据湖的第一数据库,得到多个第一数据库,其中,第一数据库为各应用系统的数据库;生成单元,用于遍历各个第一数据库的第一配置信息,并依据各个第一配置信息分别生成与第一数据库对应的第一任务,其中,第一任务用于指示建立第一数据库和数据湖中的第二数据库的关联关系;获取单元,用于获取每个第一数据库中的元数据和第二配置信息,依据元数据和第二配置信息生成第二任务,得到多个第二任务,其中,第二任务用于指示在第二数据库中构建第二数据表,第二配置信息为第二数据表的配置信息;执行单元,用于依据每个第二数据表生成第三任务,得到多个第三任务,并执行第三任务,其中,第三任务用于指示将第一数据表中的数据同步至数据湖,第一数据表为第一数据库中的数据表。
10、根据本发明实施例的另一方面,还提供了一种非易失性存储介质,非易失性存储介质包括存储的程序,其中,程序运行时控制非易失性存储介质所在的设备执行一种数据处理方法。
11、根据本发明实施例的另一方面,还提供了一种电子装置,包含处理器和存储器;存储器中存储有计算机可读指令,处理器用于运行计算机可读指令,其中,计算机可读指令运行时执行一种数据处理方法。
12、通过本技术,采用以下步骤:确定待同步至数据湖的第一数据库,得到多个第一数据库,其中,第一数据库为各应用系统的数据库;遍历各个第一数据库的第一配置信息,并依据各个第一配置信息分别生成与第一数据库对应的第一任务,其中,第一任务用于指示建立第一数据库和数据湖中的第二数据库的关联关系;获取每个第一数据库中的元数据和第二配置信息,依据元数据和第二配置信息生成第二任务,得到多个第二任务,其中,第二任务用于指示在第二数据库中构建第二数据表,第二配置信息为第二数据表的配置信息;依据每个第二数据表生成第三任务,得到多个第三任务,并执行第三任务,其中,第三任务用于指示将第一数据表中的数据同步至数据湖,第一数据表为第一数据库中的数据表,解决了相关技术中手动执行数据入湖操作效率低和容易出错的问题。通过在数据湖中依据应用系统的数据库和数据表的配置信息,进行自动建库、自动建表,执行数据同步的操作,进而达到了提高数据入湖效率,避免人为失误的效果。
- 还没有人留言评论。精彩留言会获得点赞!