一种基于用户信任度挖掘的协同过滤推荐方法与流程
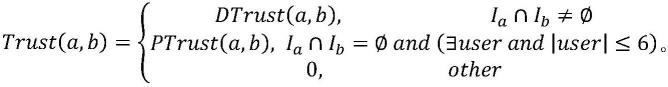
1.本发明涉及推荐算法技术领域,具体提供一种基于用户信任度挖掘的协同过滤推荐方法。
背景技术:
2.协同过滤算法是推荐系统领域应用最广泛的技术,基于用户的协同过滤是协同过滤算法的一种,其基本实现流程是首先计算出用户之间的相似度,然后找出与目标用户相似度最高的k个用户,之后根据选定的标准化评分算法预测目标用户对所有物品的评分,最后选取评分最高的指定数量的物品推荐给目标用户。
3.协同过滤算法中用户相似度的计算一般会使用修正的余弦相似度。余弦相似度就是求用户评分向量夹角的余弦值,余弦值越大,用户相似度越高。修正的余弦相似度相比余弦相似度,在计算过程中把向量的每一项的值都减去用户评分平均值,用以平衡用户评分尺度对计算结果的影响。
4.用户信任关系作为用户间的一种联系,可以反映某位用户对其它用户的影响力,在推荐算法中引入用户信任关系能够有效改善推荐系统的性能。
技术实现要素:
5.在实际生活中,每位用户都有自己的评分习惯。有的用户喜欢给所有物品都打低分,有的用户习惯于只给自己喜欢的物品评分,还有的用户则从来不给物品评分。除此之外,有些商家为了赢得竞争,会故意给自己的商品注入大量高分或给对手的商品注入大量低分,以此来吸引用户。以上这些问题都会严重降低用户之间的信任可靠度。
6.本发明通过引入用户信任度这一属性来改进传统的协同过滤推荐算法,得到一种性能更强的新型推荐算法。
7.鉴于以上问题和技术,本发明提供了如下技术方案:
8.一种基于用户信任度挖掘的协同过滤推荐方法,所述方法的实现过程包括:
9.1)根据用户的历史记录生成用户-物品评分矩阵,该矩阵中的每一项为二元组《score,time》的形式,其中score为用户对物品的评分,time为用户给物品评分的时间;
10.2)根据用户-物品评分矩阵以及用户信任度,计算出每个用户对之间的信任度,并生成用户信任度矩阵t,矩阵t的大小为m
×
m,m为系统用户数;
11.3)生成矩阵t后利用矩阵分解将t分解为两个矩阵,这两个矩阵的乘积为填补了空缺项的用户信任度矩阵t-,其中空缺项是指矩阵t中用户信任度为0的矩阵项;
12.4)生成矩阵t的同时需要对用户-物品评分矩阵进行聚类,使用聚类算法生成若干个用户簇;
13.5)针对需要推荐的用户,寻找该用户所在的用户簇,计算该用户与所在用户簇中其它所有用户的相似度,选择相似度最高的k个用户作为该用户的近邻;
14.6)预测目标用户对其未接触过的物品的评分,选取预测评分最高的若干个物品推
荐给用户。
15.更进一步的,所述用户信任度,包括:用户的评分可信度、直接信任度或间接信任度。
16.更进一步的,所述用户的评分可信度的确定包括:用户评分偏差和用户评分活跃度,其中:
17.所述用户评分偏差为用户对商品的评分值与该商品的评分均值的差值,该差值越接近,那么该用户的评分值越值得被信任;
18.所述用户评分偏差的计算公式如下:
[0019][0020]
其中re(a)表示用户a的评分偏差,ia为用户a的评分物品集,r
a,i
为用户a对物品i的评分,为物品i的平均评分,max(ri)为物品i的最高评分;
[0021]
所述用户评分活跃度根据用户的评分数量来衡量,用户评分数越多,用户的评分积极度就越高,用户的评分值也越可信。所述用户评分活跃度的计算公式如下:
[0022][0023]
其中ra(a)为用户a的评分活跃度;
[0024]
综合考量用户评分偏差和用户评分活跃度,则用户评分可信度计算如下:
[0025]
rtrust(a)=re(a)*ra(a)
[0026]
其中rtrust(a)为用户a的评分可信度。
[0027]
更进一步的,所述直接信任度仅通过用户的评分数据来计算用户之间的信任度,计算过程包括:
[0028]
1)用户之间的信任关系与用户对物品的兴趣有关,用户的兴趣相似度计算公式如下:
[0029][0030]
用户u与用户v之间的兴趣相似度int(u,v)等于用户u与v的共同评分物品集的大小与u、v评分物品集并集大小的比值;
[0031]
2)用户评分值的大小也影响着用户之间的信任度,为了衡量用户评分值的影响,定义评分误差值的计算方法,用户a与用户b之间的评分误差ε(a,b)的计算公式如下:
[0032][0033]
根据用户之间的评分误差定义用户交互响应因子:若两用户对某物品的评分差值大于两用户之间的评分误差,则认为用户在该物品上交互失败,为负响应,反之则为正响应;最后统计用户之间的正负响应个数;
[0034]
用户a和b之间的响应因子计算如下:
[0035]
[0036]
其中t为正响应因子数,f为负响应因子数;若a、b在它们公共物品评分集中的某一物品上为正响应,则t=t+1,否则f=f+1,遍历整个公共物品评分集,得到最终的t和f;
[0037]
由于正负响应因子数呈现出非线性变化,用户信任度会呈现非线性变化,正响应因子数越多用户之间的信任程度越大,所以可以利用t与f的比值来作为用户信任度的影响因子。但t/f的取值范围无法确定,故本发明借鉴机器学习中逻辑回归的思路,使用sigmoid函数将t/f的取值范围约束在(0,1)之间,其中sigmoid函数如下:
[0038][0039]
3)用户a对用户b的直接信任度计算公式如下:
[0040][0041]
更进一步的,所述间接信任度的计算过程如下:
[0042]
当用户a与用户c没有共同评分过的物品集时,a、c之间不存在直接信任度,那么此时可以采用信任传递的方式获取两位用户的间接信任度;
[0043]
假设用户a、c之间至少存在一个中间用户集群user={ub,uc,
…
,uv},user中相邻的用户之间均存在直接信任关系;
[0044]
这样一来,a与用户ub存在直接信任关系,ub和uc存在直接信任关系,uc与其右边邻居存在直接信任关系,依此类推,uv与c存在直接信任关系。那么,a与c之间的间接信任度ptrust(a,c)可以如公式如下:
[0045][0046]
根据小世界理论,两个陌生人最多通过6个人就可以互相认识,因此,当|user|大于6时,两用户的间接信任度设置为0。再者,若用户a与c之间存在多个中间用户群,则选取传递人数最少的用户群进行计算。
[0047]
综合用户直接信任度和间接信任度,用户间的最终信任度计算公式如下:
[0048][0049]
更进一步的,所述矩阵分解操作过程包括:
[0050]
矩阵分解能够将矩阵rm×n分解为pk×m和qk×n两个矩阵,使得p
t
与q的乘积和r近似,其中k为隐特征个数;
[0051]
根据用户信任度计算公式得到每对用户之间的信任度值,建立用户信任度矩阵tm×m,其中m为用户数;
[0052]
对矩阵tm×m进行矩阵分解,得到矩阵gk×m和hk×m,令则为没有空余项(空余项是指用户之间信任度为0的情况)的用户信任度矩阵,所有空余项都被填充完毕。
[0053]
因为用户之间的信任关系具有传递性,所以用户信任值为0的情况很少,矩阵tm×m会很稠密。在数据稀疏度不高的情况下,矩阵分解的效果会非常好,通过矩阵分解补全的用户信任值可靠度很高。
[0054]
更进一步的,所述用户相似度计算过程如下:
[0055]
传统的用户相似度计算方法如皮尔逊系数、余弦相似度等只关注于用户之间的评
分大小,没有考虑用户兴趣漂移以及用户之间信任关系的问题,故本发明引入时间权重因子、用户信任度来对传统的修正余弦相似度进行改良。
[0056]
time
first
为用户第一次对物品进行评分的时间,timei为用户对物品i进行评分的时间,time
all
为用户使用系统的总时长,用户u对物品i的时间权重因子的计算公式如下:
[0057][0058]
其中,时间权重因子的取值范围为(0,1],用户评分间隔时间越长得到的权值越小;
[0059]
用户的相似度计算公式如下:
[0060][0061]
其中,iu表示用户u评分过的物品集,表示用户u在iu上的平均评分,r
u,i
表示用户u对物品i的评分;
[0062]
t为经过矩阵分解填充后的用户信任度矩阵,t
u,v
表示用户u对用户v的信任度,引入用户信任度后最终的用户相似度计算公式如下:
[0063][0064]
当用户u、v之间没有共同的物品评分集时,sim(u,v)为0,此时将用户u对v的信任度当作u、v之间的相似度。
[0065]
更进一步的,所述方法通过逆热门物品频率对热门物品的推荐做惩罚;
[0066]
衡量推荐算法好坏的重要因素之一就是挖掘长尾物品的能力,所谓长尾物品就是相对不热门的不处于用户消费头部的物品。当给用户做推荐时,要充分发掘用户潜在的兴趣,不能只推荐热门物品,故需要对热门物品的推荐做惩罚。
[0067]
计算公式如下:
[0068][0069]
其中,ipif(i)为物品i的逆热门物品频率,user为推荐系统中所有用户集合,t用于计数,当物品i出现在用户u评分过的物品集iu中时,t为1,否则t为0。
[0070]
更进一步的,所述方法对目标用户u做推荐时先找到用户u所在的用户簇,然后根据用户相似度计算公式计算出用户u与u所属用户簇中所有用户的相似度,选取与u相似度最高的k个用户,记为通过逆热门物品频率的用户评分预测公式来预测用户对物品的评分,所述公式用户评分预测公式如下:
[0071][0072]
其中,pre(u,i)为用户u对物品i的预测评分;
[0073]
最后选取预测评分最高的若干个物品推荐给用户u。
[0074]
与现有技术相比,本发明一种基于用户信任度挖掘的协同过滤推荐方法具有以下突出的有益效果:
[0075]
1、引入用户信任度计算方法,通过矩阵分解来挖掘空缺的用户信任度,给推荐系统中用户信任度的获取提供了新的方式。聚类算法的引入缩小了用户近邻的寻找范围,提高了算法的性能。
[0076]
2、利用用户信任度、时间权重因子改良原有的相似度计算方法,使得用户相似度的计算结果更加精确,也进一步改善了用户兴趣漂移的问题。
[0077]
3、引入逆热门物品频率来对推荐结果做惩罚,进一步提升了推荐系统挖掘处于长尾部分物品的能力,能更好的发掘出用户的潜在兴趣。
附图说明
[0078]
图1是本发明方法实现流程图。
具体实施方式
[0079]
下面将结合附图和实施例,对本发明作进一步详细说明。
[0080]
如图1所示,一种基于用户信任度挖掘的协同过滤推荐方法,所述方法的实现过程包括:
[0081]
1、根据用户的历史记录生成用户-物品评分矩阵,该矩阵中的每一项为二元组《score,time》的形式,其中score为用户对物品的评分,time为用户给物品评分的时间;
[0082]
所述用户信任度,包括:用户的评分可信度、直接信任度或间接信任度,具体包括:
[0083]
(1)所述用户的评分可信度的确定包括:用户评分偏差;
[0084]
所述用户评分偏差为用户对商品的评分值与该商品的评分均值的差值,该差值越接近,那么该用户的评分值越值得被信任;
[0085]
所述用户评分偏差的计算公式如下:
[0086][0087]
其中re(a)表示用户a的评分偏差,ia为用户a的评分物品集,r
a,i
为用户a对物品i的评分,为物品i的平均评分,max(ri)为物品i的最高评分。
[0088]
(2)所述用户的评分可信度的确定还包括用户评分活跃度;
[0089]
所述用户评分活跃度根据用户的评分数量来衡量,用户评分数越多,用户的评分积极度就越高,用户的评分值也越可信。所述用户评分活跃度的计算公式如下:
[0090][0091]
其中ra(a)为用户a的评分活跃度;
[0092]
综合考量用户评分偏差和用户评分活跃度,则用户评分可信度计算如下:
[0093]
rtrust(a)=re(a)*ra(a)
[0094]
其中rtrust(a)为用户a的评分可信度。
[0095]
(3)所述直接信任度仅通过用户的评分数据来计算用户之间的信任度,计算过程
包括:
[0096]
1)用户之间的信任关系与用户对物品的兴趣有关,用户的兴趣相似度计算公式如下:
[0097][0098]
用户u与用户v之间的兴趣相似度int(u,v)等于用户u与v的共同评分物品集的大小与u、v评分物品集并集大小的比值;
[0099]
2)用户评分值的大小也影响着用户之间的信任度,为了衡量用户评分值的影响,定义评分误差值的计算方法,用户a与用户b之间的评分误差ε(a,b)的计算公式如下:
[0100][0101]
根据用户之间的评分误差定义用户交互响应因子:若两用户对某物品的评分差值大于两用户之间的评分误差,则认为用户在该物品上交互失败,为负响应,反之则为正响应;最后统计用户之间的正负响应个数;
[0102]
用户a和b之间的响应因子计算如下:
[0103][0104]
其中t为正响应因子数,f为负响应因子数;若a、b在它们公共物品评分集中的某一物品上为正响应,则t=t+1,否则f=f+1,遍历整个公共物品评分集,得到最终的t和f;
[0105]
由于正负响应因子数呈现出非线性变化,用户信任度会呈现非线性变化,正响应因子数越多用户之间的信任程度越大,所以可以利用t与f的比值来作为用户信任度的影响因子。但t/f的取值范围无法确定,故本发明借鉴机器学习中逻辑回归的思路,使用sigmoid函数将t/f的取值范围约束在(0,1)之间,其中sigmoid函数如下:
[0106][0107]
3)用户a对用户b的直接信任度计算公式如下:
[0108][0109]
(4)所述间接信任度的计算过程如下:
[0110]
当用户a与用户c没有共同评分过的物品集时,a、c之间不存在直接信任度,那么此时可以采用信任传递的方式获取两位用户的间接信任度;
[0111]
假设用户a、c之间至少存在一个中间用户集群user={ub,uc,
…
,uv},user中相邻的用户之间均存在直接信任关系;
[0112]
这样一来,a与用户ub存在直接信任关系,ub和uc存在直接信任关系,uc与其右边邻居存在直接信任关系,依此类推,uv与c存在直接信任关系。那么,a与c之间的间接信任度ptrust(a,c)可以如公式如下:
[0113][0114]
2、根据用户-物品评分矩阵以及用户信任度,综合用户直接信任度和间接信任度
[0115]
用户间的最终信任度计算公式如下:
[0116][0117]
计算出每个用户对之间的信任度,并生成用户信任度矩阵t,矩阵t的大小为m
×
m,m为系统用户数;
[0118]
3、生成矩阵t后利用矩阵分解将t分解为两个矩阵,这两个矩阵的乘积为填补了空缺项的用户信任度矩阵t-,其中空缺项是指矩阵t中用户信任度为0的矩阵项;
[0119]
所述矩阵分解操作过程包括:
[0120]
矩阵分解能够将矩阵rm×n分解为pk×m和qk×n两个矩阵,使得p
t
与q的乘积和r近似,其中k为隐特征个数;
[0121]
根据用户信任度计算公式得到每对用户之间的信任度值,建立用户信任度矩阵tm×m,其中m为用户数;
[0122]
对矩阵tm×m进行矩阵分解,得到矩阵gk×m和hk×m,令则为没有空余项(空余项是指用户之间信任度为0的情况)的用户信任度矩阵,所有空余项都被填充完毕。
[0123]
因为用户之间的信任关系具有传递性,所以用户信任值为0的情况很少,矩阵tm×m会很稠密。在数据稀疏度不高的情况下,矩阵分解的效果会非常好,通过矩阵分解补全的用户信任值可靠度很高。
[0124]
4、生成矩阵t的同时需要对用户-物品评分矩阵进行聚类,使用聚类算法生成若干个用户簇;
[0125]
所述方法通过逆热门物品频率对热门物品的推荐做惩罚;
[0126]
衡量推荐算法好坏的重要因素之一就是挖掘长尾物品的能力,所谓长尾物品就是相对不热门的不处于用户消费头部的物品。当给用户做推荐时,要充分发掘用户潜在的兴趣,不能只推荐热门物品,故需要对热门物品的推荐做惩罚。
[0127]
计算公式如下:
[0128][0129]
其中,ipif(i)为物品i的逆热门物品频率,user为推荐系统中所有用户集合,t用于计数,当物品i出现在用户u评分过的物品集iu中时,t为1,否则t为0。
[0130]
5、针对需要推荐的用户,寻找该用户所在的用户簇,计算该用户与所在用户簇中其它所有用户的相似度,选择相似度最高的k个用户作为该用户的近邻;
[0131]
所述用户相似度计算过程如下:
[0132]
传统的用户相似度计算方法如皮尔逊系数、余弦相似度等只关注于用户之间的评分大小,没有考虑用户兴趣漂移以及用户之间信任关系的问题,故本发明引入时间权重因子、用户信任度来对传统的修正余弦相似度进行改良。
[0133]
time
first
为用户第一次对物品进行评分的时间,timei为用户对物品i进行评分的时间,time
all
为用户使用系统的总时长,用户u对物品i的时间权重因子的计算公式如下:
[0134]
[0135]
其中,时间权重因子的取值范围为(0,1],用户评分间隔时间越长得到的权值越小;
[0136]
用户的相似度计算公式如下:
[0137][0138]
其中,iu表示用户u评分过的物品集,表示用户u在iu上的平均评分,r
u,i
表示用户u对物品i的评分;
[0139]
t为经过矩阵分解填充后的用户信任度矩阵,t
u,v
表示用户u对用户v的信任度,引入用户信任度后最终的用户相似度计算公式如下:
[0140][0141]
当用户u、v之间没有共同的物品评分集时,sim(u,v)为0,此时将用户u对v的信任度当作u、v之间的相似度。
[0142]
6、预测目标用户对其未接触过的物品的评分,选取预测评分最高的若干个物品推荐给用户。
[0143]
所述方法对目标用户u做推荐时先找到用户u所在的用户簇,然后根据用户相似度计算公式计算出用户u与u所属用户簇中所有用户的相似度,选取与u相似度最高的k个用户,记为通过逆热门物品频率的用户评分预测公式来预测用户对物品的评分,所述公式用户评分预测公式如下:
[0144][0145]
其中,pre(u,i)为用户u对物品i的预测评分;
[0146]
最后选取预测评分最高的若干个物品推荐给用户u。
[0147]
以上所述的实施例,只是本发明较优选的具体实施方式,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1