基于改进聚类算法优化随机森林的人口空间化方法及系统与流程
1.本发明涉及人口空间化技术领域,更具体地说,它涉及基于改进聚类算法优化随机森林的人口空间化方法及系统。
背景技术:
2.人口数据空间化是通过构建与人口空间分布相关的指标体系,利用数学模型将基于行政区划的人口数据分配到规则格网,从而反演人口数据的空间分布。对于生态环境保护、灾害评估与救援、商业决策及城市规划与管理等方面具有重要的指导意义。
3.多年来,众多学者对人口数据空间化展开了深入研究,经历了从简单的空间插值方法到结合机器学习方法进行建模、从单一数据支撑到多源数据融合的发展阶段。目前,很多学者利用机器学习方法开展人口数据空间化研究,如卷积神经网络、深度神经网络、随机森林模型等,其中随机森林模型应用最多且效果较佳,然而该模型在处理非平衡数据集时存在局限,非平衡数据表现为各个类别的样本数目相差巨大,多数类样本在数量上占据优势,现有的随机森林模型在构建过程中采用bootstrap随机采样,在一定概率的情况下,随机抽取的数据均来自于多数类,使得训练集数据的分布不具有代表性,从而影响随机森林模型的预测精度。
4.人口空间分布非均衡性是人口分布的重要特征,基于此特征下的人口数据构建模型就会出现与非平衡数据相同的问题,导致模型对人口密度差异大的区域预测准确率较低。
技术实现要素:
5.本发明的目的是提供基于改进聚类算法优化随机森林的人口空间化方法及系统,弥补上述随机森林模型进行人口数据空间化时的不足。
6.本发明的上述技术目的是通过以下技术方案得以实现的:包括
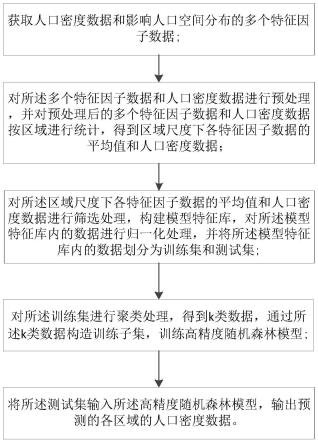
7.s1、获取人口密度数据和影响人口空间分布的多个特征因子数据;
8.s2、对所述多个特征因子数据和人口密度数据进行预处理,并对预处理后的多个特征因子数据和人口密度数据按区域进行统计,得到区域尺度下各特征因子数据的平均值和人口密度数据;
9.s3、对所述区域尺度下各特征因子数据的平均值和人口密度数据进行筛选处理,构建模型特征库,对所述模型特征库内的数据进行归一化处理,并将所述模型特征库内的数据划分为训练集和测试集;
10.s4、对所述训练集进行聚类处理,得到k类数据,通过所述k类数据构造训练子集,训练高精度随机森林模型;
11.s5、将所述测试集输入所述高精度随机森林模型,得到预测的各区域的人口密度数据。
12.采用上述技术方案,采集多个对人口空间分布有影响的特征因子数据,预处理后
按区域进行统计,得到各区域中各个特征因子数据的平均值和人口密度数据,分析各个特征因子数据与人口密度数据的相关性,筛选相关性高的特征因子数据构建模型特征库,在模型特征库内划分训练集和测试集;模型构建时,先对训练集进行聚类处理,降低训练集的非均衡性,再构建随机森林模型,可以提高模型对大差异人口密度区域预测的准确性,最后再通过测试集验证随机森林模型。
13.进一步的,所述对所述多个特征因子数据和人口密度数据进行预处理,包括:对所述多个特征因子数据和人口密度数据进行投影、拼接裁剪和重采样,所述重采样的像元大小为网格尺度,所述网格尺度为最小乡镇面积/街道面积的10%的平方根。
14.采用上述技术方案,将多个特征因子数据和人口密度数据细化到网格尺度,可确定各个网格内的多个特征因子数据和人口密度数据,便于按区域进行统计,得到区域尺度下各特征因子数据的平均值和人口密度数据。
15.进一步的,所述对所述区域尺度下各特征因子数据的平均值和人口密度数据进行筛选处理,构建模型特征库,包括:计算各特征因子数据与人口密度数据的pearson相关性系数以及显著性检验值;提取显著性检验值小于0.05的特征因子数据,构建模型特征库。
16.采用上述技术方案,筛选相关性较好的特征因子数据构建模型特征库,排除低相关性数据的干扰。
17.进一步的,所述计算各特征因子数据与人口密度数据的pearson相关性系数,通过如下公式进行:
[0018][0019]
其中,r为pearson相关性系数,n为区域的个数,xi为第i个区域的特征因子数据的特征值,yi为第i个区域的人口密度数据,为n个区域的特征因子数据的平均值,为n个区域的人口密度数据的平均值。
[0020]
进一步的,所述对所述训练集进行聚类处理,得到训练子集,通过以下步骤得到:
[0021]
s411、通过elbow method计算所述训练集的最佳聚类数k;
[0022]
s412、从训练集中随机选择一个点作为第一初始聚类中心,计算训练集中各点与所述第一初始聚类中心的距离以及各点被选为下一个聚类中心的概率,采用轮盘法选出概率最大的点作为下一个聚类中心,直至选出k个聚类中心;
[0023]
s413、计算各点到各聚类中心的欧氏距离,将其划分给最近聚类中心所代表的簇中;计算各簇中所有点的均值作为新的聚类中心;
[0024]
s414、迭代步骤s413直至聚类中心不再变化,输出k类数据。
[0025]
进一步的,所述各点被选为下一个聚类中心的概率,通过以下公式计算:
[0026][0027]
其中,x为训练集,x为训练集中的一点,p为该点被选为下一个聚类中心的概率,d
(x)
为各点与聚类中心的距离中的最短距离。
[0028]
采用上述技术方案,将训练集内的数据通过聚类算法分为k类,在k类数据中选取训练子集,可以有效的降低训练集内数据的非均衡性,避免非均衡数据对随机森林模型的
影响,提高随机森林模型的预测精度;且,聚类算法中,通过随机选择第一个聚类中心,计算各点到聚类中心的距离以及各点作为下一个聚类中心的概率,通轮盘法选择概率最大的点为下一个聚类中心,重复上述步骤直至确定k个聚类中心,可以避免聚类算法中,因初始聚类中心选取不当陷入局部最优解的问题。
[0029]
进一步的,通过所述k类数据构造训练子集,训练高精度随机森林模型,通过以下步骤得到:
[0030]
s421、通过bootstrap重抽样法从所述k类数据中随机抽取等量数据,构成包含n个样本数据和k个特征的训练子集;
[0031]
s422、按gini指标从所述k个特征中选择最佳分割属性特征作为分割节点,通过所述n 个样本数据构建决策树;
[0032]
s423、将步骤s422重复t次,构建t棵决策树,形成随机森林分类模型,所述t棵决策树的算术平均值为所述随机森林分类模型的输出;
[0033]
s424、采用网格搜索法确定所述随机森林分类模型的最优参数,所述最优参数包括:决策树的棵数、决策树的最大深度以及决策树的最大特征数,得到高精度随机森林模型。
[0034]
进一步的,还包括计算所述高精度随机森林模型的评价指标,所述评价指标包括平均绝对误差mae、平均绝对误差百分比mape、均方根误差rmse和决定系数r2。
[0035]
进一步的,步骤s5中,还包括,对所述各区域的人口密度数据进行格网化,得到网格预测结果,并采用误差校正方法和无房屋无人口原则修所述正格网预测结果,得到修正后的人口空间分布图。
[0036]
采用上述技术方案,通过将随即森林模型输出的个区域的人口密度数据进行网格化,以便反演人口数据的空间分布,且通过对网格预测结果进行修正确保在区域尺度上预测汇总人口数量与统计人口数量一致。
[0037]
本发明另一方面还提供基于改进聚类算法优化随机森林的人口空间化系统,通过以下技术方案实现:
[0038]
包括:采集模块,用于获取人口密度数据和影响人口空间分布的多个特征因子数据;预处理模块,用于对所述多个特征因子数据和人口密度数据进行预处理,并对预处理后的多个特征因子数据和人口密度数据按区域进行统计,得到区域尺度下各特征因子数据的平均值和人口密度数据;模型特征库模块,用于对所述区域尺度下各特征因子数据的平均值和人口密度数据进行筛选处理,构建模型特征库,对所述模型特征库内的数据进行归一化处理,并将所述模型特征库内的数据划分为训练集和测试集;模型构建模块,用于对所述训练集进行聚类处理,得到k类数据,通过所述k类数据构造训练子集,训练高精度随机森林模型;预测模块,用于将所述测试集输入所述高精度随机森林模型,得到预测的各区域的人口密度数据。
[0039]
与现有技术相比,本发明具有以下有益效果:
[0040]
1.本发明提供了一种基于改进聚类算法优化随机森林模型的人口空间化方法,通过改进聚类算法对训练集的数据进行聚类,在聚类后的各类数据中随机抽取等量的数据融合作为训练子集,通过训练子集构建随机森林模型,使得数据均衡且具有代表性,可以有效的降低不均衡数据对随机森林模型预测精度的影响,提高随机森林模型对大差异人口密度
区域预测的准确性。
[0041]
2.本发明提供改进聚类算法对训练集数据进行聚类,通过随机选择第一初始聚类中心,计算各点到第一聚类中心的距离以及各点作为下一个聚类中心的概率,选择概率最大的点为下一个聚类中心,直至确定k个聚类中心,可以避免聚类算法中因初始聚类中心选取不当而陷入局部最优解的问题。
附图说明
[0042]
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本技术的一部分,并不构成对本发明实施例的限定。在附图中:
[0043]
图1为本发明一实施例提供的改进前的人口空间化方法的流程图;
[0044]
图2为本发明一实施例提供的改进后的人口空间化方法的流程图;
[0045]
图3为本发明一实施例提供的聚类处理流程图;
[0046]
图4为本发明一实施例提供的最佳聚类数k的确定图;
[0047]
图5为本发明一实施例提供的改进前的随机森林模型的预测值与实际值的数据图;
[0048]
图6为本发明一实施例提供的改进后的随机森林模型的预测值与实际值的数据图;
[0049]
图7为本发明一实施例提供的基于改进后的随机森林算法人口空间分布格网图。
具体实施方式
[0050]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0051]
需要说明的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
[0052]
实施例:基于改进聚类算法优化随机森林的人口空间化方法,
[0053]
为了便于描述,我们将本发明提供的基于改进聚类算法优化随机森林的人口空间化方法称为改进后的人口空间化方法,将直接采用随机森林的人口空间化方法称为改进前的人口空间化方法;以某市人口普查的乡镇级数据为例,对改进前、后的人口空间化方法进行详细阐述。
[0054]
s1、获取人口密度数据和影响人口空间分布的多个特征因子数据;
[0055]
本实施例中,具体优选地,获取:某市的dem数据(digital elevation model,数字高程模型)、夜间灯光数据、poi数据(point of interest,兴趣点)、地理国情普查数据以及各乡镇级的行政区划数据以及人口普查统计数据。
[0056]
s2、对所述多个特征因子数据和人口密度数据进行预处理,并对预处理后的多个特征因子数据和人口密度数据按区域进行统计,得到区域尺度下各特征因子数据的平均值和人口密度数据;
[0057]
其中,预处理包括:利用arcgis对获取的多个特征因子数据和人口密度数据进行投影、拼接裁剪和重采样处理,重采样的像元大小为网格尺度,通过下式计算:
[0058][0059]
其中,s
min
为最小的乡镇面积/街道面积,单位为m2,grid为格网大小,单位m。
[0060]
本实施例中,某市的网格尺度经计算为430m,基于以上预处理,将多个特征因子数据和人口密度数据细化为430
×
430的网格,得到网格尺度下多个特征因子数据和人口密度数据,便于统计,其后,可以设定区域,统计区域尺度下各特征因子数据的平均值和人口密度数据,即各个区域内的各特征因子数据的平均值和人口密度数据,本实施例选择以乡镇为区域进行统计,包括耕地密度、林地密度、平均dem值、平均dn值(digital number,遥感影像像元亮度值)等28个特征因子数据和人口密度数据。
[0061]
s3、对所述区域尺度下各特征因子数据的平均值和人口密度数据进行筛选处理,构建模型特征库,对所述模型特征库内的数据进行归一化处理,并将所述模型特征库内的数据划分为训练集和测试集;
[0062]
筛选处理包括:计算各特征因子数据与人口密度数据的pearson相关性系数以及显著性检验值;筛选出显著性检验值小于0.05之间的特征因子数据;
[0063]
计算各特征因子数据与人口密度数据的pearson相关性系数,通过如下公式进行:
[0064][0065]
其中,r为pearson相关性系数,n为区域的个数,xi为第i个区域的特征因子数据,yi为第i个区域的人口密度数据,为n个区域的特征因子数据的平均值,为n个区域的人口密度数据的平均值。
[0066]
本实施例中,利用spss相关性分析对特征因子数据进行初筛,初筛后绘制相关系数表格,选择相关系数通过显著性检验的特征因子数据构建模型特征库,其中平均坡度和平均起伏度为dem的衍生数据,dem与平均坡度、dem与平均起伏度、平均坡度与平均起伏度相关性系数分别为0.882、0.862、0.998,三个因子之间的相关性极强,本实施例选择其中与人口密度相关性最高的平均起伏度参与模型特征库构建,如表1所示,表中的特征名称,即为本实施例的特征因子,对模型特征库内的特征因子数据进行归一化处理,然后将特征库数据集划分为训练集和测试集,具体的可以是:75%的训练集和25%的测试集,上述的显著性检验,即显著性检验值小于0.05。
[0067]
表1模型特征库
[0068][0069][0070]
注:**.表示在0.01层上双尾显著,*.表示在0.05层上双尾显著
[0071]
对于改进前的人口空间化方法而言,如图1所示,基于上述模型特征库内的训练集直接 bootstarp采样获取训练子集,训练随机森林算法模型,使用网格搜索法调整随机森林中决策树的棵数n_estimators、决策树的深度max_depth和最大特征数max_features三个主要参数,调至表2中的最优值,再将测试集数据作为验证数据检验模型精度,得到该模型预测结果,该模型的预测值与实际值的数据图如图5所示,图中三角形符号为预测值,圆形符号为真实值。
[0072]
表2rf算法参数最优值
[0073][0074]
对于改进后的人口空间化方法而言,如图2所示,还包括以下步骤:
[0075]
s4、对所述训练集进行聚类处理,得到k类数据,通过所述k类数据构造训练子集,训练高精度随机森林模型;
[0076]
其中,聚类处理的具体步骤如图3所示,包括:
[0077]
s411、通过elbow method计算训练集的最佳聚类数k;
[0078]
具体的,由下述公式先计算误差平方和sse,画出k值与sse值的关系图,选择图中到达临界点对应的k值
[0079][0080]
其中,ci是第i个簇,p是ci中的样本点,mi是ci的质心。
[0081]
s412、从训练集中随机选择一个点作为聚类中心,计算训练集中各点与聚类中心的距离,记最短距离为d
(x)
,并计算各点被选为下一个聚类中心的概率,采用轮盘法选出概率最大的点作为下一个聚类中心,直至选出k个聚类中心;
[0082]
具体地,各点被选为下一个聚类中心的概率,通过以下公式计算:
[0083][0084]
其中,x为训练集,x为训练集中的一点,p为该点被选为下一个聚类中心的概率,d
(x)
为各点与聚类中心的距离中的最短距离。
[0085]
s413、计算各点到各聚类中心的欧氏距离,将其划分给最近聚类中心所代表的簇中;计算各簇中所有点的均值作为新的聚类中心;
[0086]
s414、迭代步骤s413直至聚类中心不再变化,得到k类数据。
[0087]
在本实施例中,k值与sse值的关系图,如图4所示,表明最佳k值为5,利用上述的聚类算法将训练集的数据分为5类。
[0088]
通过k类数据构造训练子集,训练高精度随机森林模型,包括以下步骤:
[0089]
s421、通过bootstrap重抽样法从k类数据中随机抽取等量数据,构成包含n个样本数据和k个特征的训练子集;
[0090]
s422、按gini指标从所述k个特征中选择最佳分割属性特征作为分割节点,通过所述n 个样本数据构建决策树;
[0091]
s423、将步骤s422重复t次,构建t棵决策树,形成随机森林分类模型,所述t棵决策树的算术平均值为所述随机森林分类模型的输出;
[0092]
s424、采用网格搜索法确定所述随机森林分类模型的最优参数,所述最优参数包括:决策树的棵数、决策树的最大深度以及决策树的最大特征数,得到高精度随机森林模型。
[0093]
在本实施例中,基于训练子集的数据按上述步骤构建随机森林模型,通过步骤s424将参数调整至表3的最优值,得到高精度随机森林模型。
[0094]
表3k-means++rf算法参数最优值
[0095][0096]
s5、将测试集输入高精度随机森林模型,输出预测的各区域的人口密度数据。
[0097]
在本实施例中,将测试集的数据作为验证数据带入高精度随机森林模型,的到预
测结果,该模型的预测值与实际值的数据图,如图6所示,图中三角形符号为预测值,圆形符号为真实值,与图5的数据相比,可以明显的看出,高精度随机森林模型的预测值对大差异人口密度区域的预测值更接近真实值,预测结果更为准确。
[0098]
进一步的,可以计算高精度随机森林模型以及未改进随机森林模型的评价指标进行对比,具体的,评价指标包括平均绝对误差mae、平均绝对误差百分比mape、均方根误差rmse 和决定系数r2,可通过下述公式计算。
[0099][0100][0101][0102][0103]
其中,n为区域的个数,y
true
(i)代表第i个区域的实际人口数量,y
pre
(i)代表第i个区域的预测人口数量,代表n个区域的实际人口数量的平均值。
[0104]
在本实施例中,高精度随机森林模型以及未改进随机森林模型的评价指标,如表4所示,由表4可知高精度随机森林算法有效的将预测精度提升了3.4%左右,验证了高精度随机森林算法的可行性。
[0105]
表4评价指标结果
[0106][0107]
进一步的,在步骤s5中,还包括,对各区域的人口密度数据进行格网化,得到网格预测结果,并采用误差校正方法和无房屋无人口原则修所述正格网预测结果,得到修正后的人口空间分布图。
[0108]
在本实施例中,以430
×
430的网格进行网格化,得到基于改进后的随机森林算法人口空间分布格网图,如图7所示。
[0109]
本实施例另一方面还提供基于改进聚类算法优化随机森林的人口空间化系统,包括:
[0110]
采集模块,用于获取人口密度数据和影响人口空间分布的多个特征因子数据;
[0111]
预处理模块,用于对所述多个特征因子数据和人口密度数据进行预处理,并对预处理后的多个特征因子数据和人口密度数据按区域进行统计,得到区域尺度下各特征因子
数据的平均值和人口密度数据;
[0112]
模型特征库模块,用于对所述区域尺度下各特征因子数据的平均值和人口密度数据进行筛选处理,构建模型特征库,对所述模型特征库内的数据进行归一化处理,并将所述模型特征库内的数据划分为训练集和测试集;
[0113]
模型构建模块,用于对所述训练集进行聚类处理,得到k类数据,通过所述k类数据构造训练子集,训练高精度随机森林模型;
[0114]
预测模块,用于将所述测试集输入所述高精度随机森林模型,输出预测的各区域的人口密度数据。
[0115]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1