一种虚拟试衣去遮挡方法和系统
1.本发明涉及深度学习中的虚拟试衣领域,更具体地,涉及一种虚拟试衣去遮挡方法和系统。
背景技术:
2.随着网络购物的普及,越来越多的消费者选择在网上购置一年四季的衣物。对于网店上琳琅满目的衣物,我们只能通过模特的试衣效果来评判衣物是否合适自己。但由于我们每个人的身材,气质等方面的不同,当我们购买某些在心仪的衣物后,我们实际上身时,会发现并不称心如意,这不仅影响了我们的购物体验,接下来的退货,换货等操作,也给商家带来了额外的人工成本。因此,如果能在顾客购物时,提供他们自身的虚拟试衣效果供他们评价,则可以显著提供顾客的购物体验,同时降低商家的人工成本,这是一项十分具有实用意义和商业价值的技术。
3.近年来,随着虚拟试衣技术逐渐深入,2018年han等人提出了基于parser-based的虚拟试衣生成方案,后续的cp-vton,acgpn等延续这条路线逐步提升生成图像的视觉一致性,但由于这种方法受到人物语义分割效果的影响,容易导致衣物形变效果不佳,生成的人物躯干过于扭曲等问题。2021年,ge等人提出parser-free的虚拟试衣方案,提出基于自监督的虚拟试衣训练方式,该方法显著提升了生成图像的效果,但仍存在衣物形变后遮挡了人物躯干,或者模型的鲁棒性不够强,生成的图像仍存在试衣前衣物的伪影。
4.现有技术中提供了一种虚拟试衣方法、虚拟试衣眼镜及虚拟试衣系统,涉及显示技术领域,用于解决用户在试衣过程中,需要多次亲自更换衣物的问题。该虚拟试衣方法包括:对目标衣物的特征数据进行采集,并根据采集结果获取衣物图像;将获取的衣物图像与用户的体征图像进行融合,以得出用户穿戴目标衣物的试衣图像;显示上述试衣图像。用于虚拟试衣。该方案依然存在衣物遮挡和躯干伪影的问题。
技术实现要素:
5.本发明的首要目的是提供一种虚拟试衣去遮挡方法,解决了虚拟试衣图像中的衣物遮挡和躯干伪影问题。
6.本发明的进一步目的是一种虚拟试衣去遮挡系统。
7.为解决上述技术问题,本发明的技术方案如下:
8.一种虚拟试衣去遮挡方法,其特征在于,包括以下步骤:
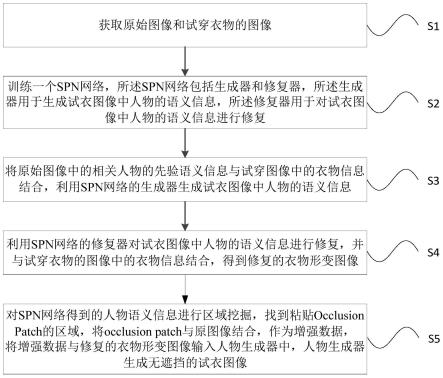
9.s1:获取原始图像和试穿衣物的图像;
10.s2:训练一个spn网络,所述spn网络包括生成器和修复器,所述生成器用于生成试衣图像中人物的语义信息,所述修复器用于对试衣图像中人物的语义信息进行修复;
11.s3:将原始图像中的相关人物的先验语义信息与试穿图像中的衣物信息结合,利用spn网络的生成器生成试衣图像中人物的语义信息;
12.s4:利用spn网络的修复器对试衣图像中人物的语义信息进行修复,并与试穿衣物
的图像中的衣物信息结合,得到修复的衣物形变图像;
13.s5:对spn网络得到的人物语义信息进行区域挖掘,找到粘贴occlusionpatch的区域,将occlusion patch与原图像结合,作为增强数据,将增强数据与修复的衣物形变图像输入人物生成器中,人物生成器生成无遮挡的试衣图像。
14.优选地,所述spn网络的生成器和修复器均为unet结构。
15.优选地,所述步骤s2中生成器的训练过程具体为:
16.将原始图像中相关人物中的先验衣物信息定义为mc,原始图像中人物躯干信息定义为mw,mw包括头、手臂和裤子的语义信息,试穿图像的衣物信息定义为由衣物tc形变得到,试穿图像的人物躯干信息定义为并将试穿图像的人物的骨架信息定义为m
p
,用相关人物的先验语义信息mw同结合起来得到
[0017][0018]
其中
⊙
表示逐像素点乘;
[0019]
把me作为mc和之间残差的布料:
[0020][0021]
得到潜在的,可能生成躯干部位的区域
[0022][0023]
得到了潜在生成躯干部位与相关人物躯干的先验语义信息mw后,在mw的监督下,由和m
p
生成剩余的躯干信息。
[0024]
优选地,所述修复器的训练过程具体为:
[0025]
从irregular mask dataset引入的掩模定义为md,模拟破坏躯干信息mw的情况如下式:
[0026][0027]
式中,表示被破坏的躯干信息,将其输入修复器,修复器在mw的监督下,进行修复。
[0028]
优选地,步骤s5中还对原始图像进行数据增强。
[0029]
优选地,所述对原始图像进行数据增强,具体为:
[0030]
s5.1:利用灰度共生矩阵计算衣物图像的熵,并对所有衣物图像进行纹理分类,分为简单纹理和复杂纹理;
[0031]
s5.2:利用基于语义指导的occlusionmixup方法,对原始图像中的相关人物进行数据增强。
[0032]
优选地,所述步骤s5.1利用灰度共生矩阵计算衣物图像的熵,具体为:
[0033]
[0034]
式中,ent表示灰度共生矩阵的熵,g(i,j)表示不同像素灰度值出现频率的归一化数值,k表示灰度共生矩阵的行列数。
[0035]
优选地,所述步骤s5.1中对所有衣物图像进行纹理分类,分为简单纹理和复杂纹理,具体为:
[0036]
设置阈值,如果ent大于等于阈值,判断衣服纹理为复杂纹理,如果ent小于阈值,则判断衣服纹理为简单纹理。
[0037]
优选地,所述步骤s5.2中基于语义指导的occlusion mixup方法,具体为:
[0038]
将试衣人物定义为xa,然后从复杂-简单纹理集合中,以0.3的概率挑选简单纹理,以0.7的概率挑选为复杂纹理,并将纹理对应的人物定义为xb;利用所述spn网络的生成器生成人物语义先验信息,在densepose的辅助下,挖掘出粘贴occlusion的区域并提取出xb的衣物语义信息然后利用下式生成用于虚拟试衣的数据增强图像
[0039][0040][0041]
一种虚拟试衣去遮挡系统,包括:
[0042]
数据获取模块,所述数据获取模块用于获取原始图像和试穿衣物的图像;
[0043]
训练模块,所述训练模块用于训练一个spn网络,所述spn网络包括生成器和修复器,所述生成器用于生成试衣图像中人物的语义信息,所述修复器用于对试衣图像中人物的语义信息进行修复;
[0044]
语义生成模块,所述生成模块将原始图像中的相关人物的先验语义信息与试穿图像中的衣物信息结合,利用spn网络的生成器生成试衣图像中人物的语义信息;
[0045]
语义修复模块,利用spn网络的修复器对试衣图像中人物的语义信息进行修复,并与试穿衣物的图像中的衣物信息结合,得到修复的衣物形变图像;
[0046]
数据增强模块,所述数据增强模块对spn网络得到的人物语义信息进行区域挖掘,找到粘贴occlusionpatch的区域,将occlusion patch与原图像结合,作为增强数据,将增强数据与修复的衣物形变图像输入人物生成器中,人物生成器生成无遮挡的试衣图像。
[0047]
与现有技术相比,本发明技术方案的有益效果是:
[0048]
1、本发明相比于之前的虚拟试衣的训练方式,提出结合occlusion mixup的数据增强方法,增强了传统模型对躯干部分的生成能力;
[0049]
2、本发明相比于之前虚拟试衣方案没有考虑不合理的衣物形变问题,提出sharpened parsing network来修复不合理的形变部分,解决衣物遮挡的问题;
[0050]
3、本发明在viton数据测试集上取得了目前最好的frechet inception distance(fid)指标。该指标用于衡量生成图像的多样性,效果越好代表生成的图像越逼近真实图像。
附图说明
[0051]
图1为本发明的方法流程示意图
[0052]
图2为spn网络的生成器训练流程图。
[0053]
图3为spn网络的修复器训练流程图。
[0054]
图4为spn网络的修复器的修复效果图。
[0055]
图5为衣物纹理分类示意图。
[0056]
图6为cclusion mixup操作过程示意图。
[0057]
图7为模型训练过程对比示意图。
[0058]
图8为occlusion mixup与传统数据增强方式的对比示意图。
[0059]
图9为本发明的方法与其它baseline的对比示意图。
[0060]
图10为pf-afn加上occlusionmix的效果示意图。
[0061]
图11为spn网络的效果示意图。
[0062]
图12为本发明的系统模块示意图。
具体实施方式
[0063]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0064]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0065]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0066]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0067]
实施例1
[0068]
本实施例提供一种虚拟试衣去遮挡方法,如图1所示,包括以下步骤:
[0069]
s1:获取原始图像和试穿衣物的图像;
[0070]
s2:训练一个spn网络,所述spn网络包括生成器和修复器,所述生成器用于生成试衣图像中人物的语义信息,所述修复器用于对试衣图像中人物的语义信息进行修复;
[0071]
s3:将原始图像中的相关人物的先验语义信息与试穿图像中的衣物信息结合,利用spn网络的生成器生成试衣图像中人物的语义信息;
[0072]
s4:利用spn网络的修复器对试衣图像中人物的语义信息进行修复,并与试穿衣物的图像中的衣物信息结合,得到修复的衣物形变图像;
[0073]
s5:对spn网络得到的人物语义信息进行区域挖掘,找到粘贴occlusionpatch的区域,将occlusion patch与原图像结合,作为增强数据,将增强数据与修复的衣物形变图像输入人物生成器中,人物生成器生成无遮挡的试衣图像。
[0074]
实施例2
[0075]
本实施例在实施例1的基础上,继续公开以下内容:
[0076]
所述spn网络的生成器和修复器均为unet结构。
[0077]
在实际应用中,我们需要网络从原始图像结合试穿的衣物来生成试衣图像的语义信息,但由于缺少试衣图像的真实数据作为监督,我们提出用自监督的方式,利用原始图像自身的信息,来解决数据限制的问题,如图2所示,所述步骤s2中生成器的训练过程具体为:
[0078]
将原始图像中相关人物中的先验衣物信息定义为mc,原始图像中人物躯干信息定义为mw,mw包括头、手臂和裤子的语义信息,试穿图像的衣物信息定义为由衣物tc形变得到,试穿图像的人物躯干信息定义为并将试穿图像的人物的骨架信息定义为m
p
,因
为缺乏所以用相关人物的先验语义信息mw同结合起来得到
[0079][0080]
其中
⊙
表示逐像素点乘;
[0081]
把me作为mc和之间残差的布料:
[0082][0083]
得到潜在的,可能生成躯干部位的区域
[0084][0085]
得到了潜在生成躯干部位与相关人物躯干的先验语义信息mw后,在mw的监督下,由和m
p
生成剩余的躯干信息。
[0086]
spn网络的生成器已经生成了人类的躯干信息,但该信息在试衣图像中会受到不合理的衣物形变干扰,使得生成的躯干语义信息不连贯,为了解决这个问题,引入irregular mask dataset来模拟衣物遮挡躯干语义信息的情况,并使用restorer对被破坏的躯干语义信息进行修复,如图3所示,所述修复器的训练过程具体为:
[0087]
从irregular mask dataset引入的掩模定义为md,模拟破坏躯干信息mw的情况如下式:
[0088][0089]
式中,表示被破坏的躯干信息,将其输入修复器,修复器在mw的监督下,进行修复。
[0090]
修复效果如图4所示,在修复器的修复下,试衣人物的躯干语义信息不会被不合理的衣物形变干扰,能够保持连续。将该修复后的语义信息与不合理的衣物形变进行点乘处理,修复不合理的衣物形变图像。
[0091]
步骤s5中还对原始图像进行数据增强,传统的数据增强方案诸如cutmix,mixup和supermix等采用random patch的方式对图像进行数据增强,但在虚拟试衣人物中,由于random patch的模式破坏了人物的相关先验信息,不利于模型训练出合理的生成模型,因此我们针对虚拟试衣任务设计了一种基于语义指导的,用于提升模型感应不合理衣物区间能力的数据增强方案。
[0092]
所述对原始图像进行数据增强,具体为:
[0093]
s5.1:利用灰度共生矩阵计算衣物图像的熵,并对所有衣物图像进行纹理分类,分为简单纹理和复杂纹理,如图5所示;通过大量实验,发现pf-afn生成模型保留部分试衣前衣物的情况大多出现在试衣前衣物较复杂的时候,因此,需要先将衣物图像进行纹理分类;
[0094]
s5.2:利用基于语义指导的occlusionmixup方法,对原始图像中的相关人物进行数据增强。
[0095]
所述步骤s5.1利用灰度共生矩阵计算衣物图像的熵,具体为:
[0096][0097]
式中,ent表示灰度共生矩阵的熵,g(i,j)表示不同像素灰度值出现频率的归一化数值,k表示灰度共生矩阵的行列数。
[0098]
所述步骤s5.1中对所有衣物图像进行纹理分类,分为简单纹理和复杂纹理,具体为:
[0099]
设置阈值,如果ent大于等于阈值,判断衣服纹理为复杂纹理,如果ent小于阈值,则判断衣服纹理为简单纹理,本实施例中,阈值取值为2.5。
[0100]
所述步骤s5.2中基于语义指导的occlusion mixup方法,如图6所示,具体为:
[0101]
将试衣人物定义为xa,然后从复杂-简单纹理集合中,以0.3的概率挑选简单纹理,以0.7的概率挑选为复杂纹理,并将纹理对应的人物定义为xb;利用所述spn网络的生成器生成人物语义先验信息,在densepose的辅助下,挖掘出粘贴occlusion的区域并提取出xb的衣物语义信息然后利用下式生成用于虚拟试衣的数据增强图像
[0102][0103][0104]
在具体的实施例中,详细叙述本发明中网络训练过程和整个方法实现流程,并带入viton据集以及网络参数以方便理解;
[0105]
网络模型信息及数据集参数如下:
[0106]
本发明以unet作为sharpenedparsingnetwork中generator和restorer的生成其,使用pf-afn中用到的appearancemodule对衣物进行形变,并使用res-unet生成人物图像。在virtualtryondataset(viton)上训练,该数据集包含16253张人物图像与对应的衣物图像,其中训练集包括14221张,测试集包括2032张,使用self-correction-human-parsing的方法得到人物先验语义信息,使用openpose获得人物先验姿态信息。
[0107]
训练步骤:
[0108]
1、先训练appearancemodule,为后续sharpenedparsingnetwork的训练过程提供形变衣物。
[0109]
2、用self-correction-human-parsing得到的人物先验语义信息来辅助训练sharpenedparsingnetwork,得到generator和resotorer。
[0110]
3、将sharpenedparsingnetwork的结果用来指导occlusion mixup,用于建模各种各样的遮挡情况,让生成器学会去克服这些遮挡的情况。
[0111]
测试步骤:
[0112]
用appearancemodule生成形变衣物;
[0113]
用sharpenedparsingnetwork产生的结果用来修复不合理的形变结果,得到处理后的形变衣物,克服由形变衣物导致的遮挡情况;
[0114]
用在occlusionmixup正则下的生成器生成试衣图像,克服由试衣前衣物造成的遮挡或伪影情况。
[0115]
具体的效果如图7至图11。
[0116]
实施例3
[0117]
本实施例提供一种虚拟试衣去遮挡系统,如图12,包括:
[0118]
数据获取模块,所述数据获取模块用于获取原始图像和试穿衣物的图像;
[0119]
训练模块,所述训练模块用于训练一个spn网络,所述spn网络包括生成器和修复器,所述生成器用于生成试衣图像中人物的语义信息,所述修复器用于对试衣图像中人物的语义信息进行修复;
[0120]
语义生成模块,所述生成模块将原始图像中的相关人物的先验语义信息与试穿图像中的衣物信息结合,利用spn网络的生成器生成试衣图像中人物的语义信息;
[0121]
语义修复模块,利用spn网络的修复器对试衣图像中人物的语义信息进行修复,并与试穿衣物的图像中的衣物信息结合,得到修复的衣物形变图像;
[0122]
数据增强模块,所述数据增强模块对spn网络得到的人物语义信息进行区域挖掘,找到粘贴occlusionpatch的区域,将occlusion patch与原图像结合,作为增强数据,将增强数据与修复的衣物形变图像输入人物生成器中,人物生成器生成无遮挡的试衣图像。
[0123]
相同或相似的标号对应相同或相似的部件;
[0124]
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
[0125]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1