基于CatBoost和Radam-LSTM的光伏发电功率预测方法
基于catboost和radam-lstm的光伏发电功率预测方法
技术领域
1.本发明属于光伏发电功率预测领域,具体涉及一种基于catboost和radam-lstm的光伏发电功率预测方法。
背景技术:
2.与传统电力系统相比,以新能源为主体的电力系统的源、荷两端具有较强的不确定性,不仅需要源端的发电部门能够实时跟踪荷端的负荷变化,还需要荷端的用户可以积极响应电力系统的运行情况。电力系统的调度难度上升,系统安全经济运行也受到极大挑战。合理高效地预测光伏发电功率,一方面有利于提高光伏电站的运维水平,增加市场竞争力;另一方面可以有效降低上述不确定性带来的影响,有利于制定合理的调度计划,供调度人员合理设计规划调度资源以满足负荷需求响应。
3.光伏发电功率受到多种因素的影响,除电站本身数据外,还和气象因素以及调度计划息息相关,如天气预报数据、实时气象数据、运行状态、检修计划等。统计电流、风速、功率、湿度、气温、全球水平辐照度以及降雨等数据特征后,对分析各个数据特征之间的相互依赖关系,确定出每个特征与目标特征之间的相关性强弱,进一步地筛选出关键特征用于模型的训练,有利于提高模型的训练速度以及光伏发电功率预测的准确性。
4.选择合理的预测模型不仅能够提高预测性能,还能够大大降低预测成本节省计算机资源。catboost模型能够高效合理地处理类别型特征,处理梯度偏差以及预测偏移问题,同时提高算法的准确性和泛化能力,长短期记忆网络(long short-term memory,lstm)是一种特定形式的循环神经网络(recurrent neural network,rnn),lstm能更好地处理时间序列的问题,对极具时间序列特性的光伏发电功率预测十分友好,同时lstm解决了rnn长期依赖问题,并且缓解了rnn在训练时反向传播带来的“梯度消失”问题,是一种性能极佳的神经网络模型。
技术实现要素:
5.本发明的技术问题是为充分挖掘时间序列中隐含的新特征、增强时间序列特征在光伏发电功率预测技术中的表达能力以及提升光伏发电功率预测的性能。
6.本发明的目的是针对上述问题,提供一种基于catboost和radam-lstm的光伏发电功率预测方法,采用stacking框架和瀑布融合法,将catboost和radam-lstm分别作为前级、后级模型进行集成、融合,得到功率预测模型,提高功率预测模型的稳定性、准确性和泛化能力,避免预测模型过拟合。
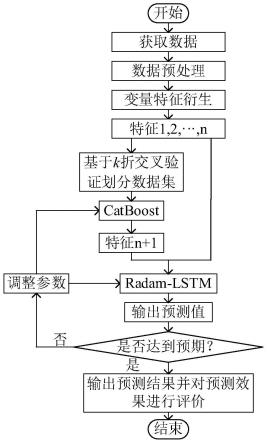
7.本发明的技术方案是基于catboost和radam-lstm的光伏发电功率预测方法,包括以下步骤:
8.步骤1:获取用于光伏发电功率预测的特征数据,对特征数据进行预处理;
9.步骤2:利用改进灰色关联度分析方法计算各个气象特征以及电气特征与目标特征之间的灰色关联度大小,剔除关联度小的特征;
10.步骤3:利用变量特征衍生方法从已有特征数据时间序列中衍生出新的特征,对特征数据时间序列进行扩展,以增加特征数据时间序列在光伏发电功率预测中的表达能力,形成特征数据集;
11.步骤4:将catboost作为前级模型,radam-lstm作为后级模型,利用瀑布融合法构建功率预测模型,对功率预测模型训练并测试;
12.步骤4.1:将catboost作为前级模型,采用k折交叉验证方法划分特征数据集,并输入catboost进行预测;
13.步骤4.2:将catboost的输出结果作为新特征,结合步骤3得到的特征集,共同作为radam-lstm的输入,利用radam-lstm得到光伏发电功率的预测数据;
14.步骤4.3:调节超参数,对功率预测模型重复进行训练并测试,直至满足精度要求;
15.步骤5:将利用训练好的功率预测模型用于光伏发电功率短期预测。
16.步骤1中,所述对特征数据进行预处理,包括对特征数据中的异常值、非数nan进行处理以及对特征数据进行归一化。
17.采用最大最小标准化将特征数据的原始值映射到区间[0,1]之间,计算式如下:
[0018][0019]
式中x表示原始数据,x
min
、x
max
对应该特征数据的最小值以及最大值,x
′
为归一化后的数据。
[0020]
步骤2包括以下子步骤:
[0021]
1)数据标准化,标准化之后的特征数据时间序列为xi′
=(xi′
(1),xi′
(2),
…
,xi′
(m)),其中xi′
(m)表示第i个特征、第m个元素标准化的结果;
[0022]
2)求所有特征数据时间序列与目标特征时间序列的差值,计算式如下:
[0023]
δi(k)=|x
obj
′
(k)-xi′
(k)|
[0024]
式中x
obj
′
(k)表示目标特征第k个元素标准化后的结果,xi′
(k)表示其它特征第k个元素标准化后的结果,δi(k)表示第i个特征的第k个元素标准化之后的差值,i=2,3,
…
,n,k=1,2,
…
,m;
[0025]
3)计算关联系数,
[0026][0027]
式中ci(k)为第i个特征第k个元素的关联系数,m表示双重最大值,即m表示双重最小值,即ρ为分辨系数;
[0028]
4)计算改进灰色关联度,计算式如下:
[0029][0030]
式中表示灰色关联度大小;λi(k)表示第i个特征第k个元素的权重系数,该权重系数基于欧式距离计算得到,即计算出目标特征与其他特征之间的距离,离目标距离越近,
权重系数越大,计算式如下:
[0031][0032]
5)根据计算得到的改进灰色关联度,将改进灰色关联度不小于0.7的特征确定为关联性大的特征。
[0033]
步骤4中,所述k折交叉验证方法划分特征数据,具体过程包括:
[0034]
1)将全部数据样本划分成k个大小相等的样本子集;
[0035]
2)依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行预测模型的训练和评估;
[0036]
3)最后把k次评估指标的平均值作为预测模型最终的评估指标。
[0037]
优选地,步骤5中,所述对功率预测模型进行训练并测试,采用radam优化器。
[0038]
相比现有技术,本发明的有益效果包括:
[0039]
1)本发明采用stacking框架和瀑布融合法,将catboost和radam-lstm集成、融合,显著提高了功率预测模型的预测性能,得到的功率预测模型稳定性、准确性更好,泛化能力更强,能有效防止预测模型过拟合。
[0040]
2)本发明针对传统灰色关联度分析法改进,改进的灰色关联度分析法能区分特征的重要程度,从原始特征集中筛选出与目标特征关联性大的特征用于光伏发电功率的预测,减小原始特征数据采集量,降低处理原始数据的计算量,省时省力。
[0041]
3)本发明基于变量特征衍生方法衍生出与时间特征相关的新特征,增加了特征时间序列在光伏预测中的表达能力,进一步提高了模型预测性能。
[0042]
4)本发明在预测模型的训练、测试过程中采用radam优化器反向更新模型参数,加快了预测模型的学习效率,提高了预测模型的稳定性以及预测的准确性。
附图说明
[0043]
下面结合附图和实施例对本发明作进一步说明。
[0044]
图1为本发明实施例利用变量特征衍生方法产生新特征的示意图。
[0045]
图2为本发明实施例的5折交叉验证划分数据集的原理图。
[0046]
图3a为rnn单元的结构示意图。
[0047]
图3b为lstm单元的结构示意图。
[0048]
图4为本发明实施例的光伏发电功率预测方法的流程示意图。
[0049]
图5为本发明实施例计算得到的各个特征的改进灰色关联度的示意图。
[0050]
图6为光伏发电功率随时间季节变化的示意图。
[0051]
图7a为采用adam优化算法更新参数得到的lstm预测模型的预测效果示意图。
[0052]
图7b为采用sgd优化算法更新参数得到的lstm预测模型的预测效果示意图。
[0053]
图7c为采用radam优化算法更新参数得到的lstm预测模型的预测效果示意图。
[0054]
图8为本发明实施例的catboost和radam-lstm集成模型的预测效果示意图。
[0055]
图9为单个catboost预测模型的预测效果示意图。
具体实施方式
[0056]
如图4所示,基于catboost和radam-lstm的光伏发电功率预测方法,包括以下步骤:
[0057]
步骤1:获取用于光伏发电功率预测的特征数据,对特征数据进行预处理;
[0058]
根据数据源的基本特性,特征数据预处理包括对异常值、非数(not a number,nan)的处理,对数据进行归一化操作。将异常值删除,将nan赋0,然后对数据进行归一化处理,以消除特征数据之间的量纲影响,进而提高预测的准确性,本发明采用最大最小标准化将原始值映射到区间[0,1]之间,计算公式为:
[0059][0060]
式中x表示原始数据,x
min
、x
max
对应该特征数据的最小值以及最大值,x
′
为归一化后的数据。
[0061]
实施例采用dka太阳能中心(the desert knowledge australia solar centre,dka)的数据,对数据进行预处理,包括对缺失值、异常值的处理以及对数据进行归一化。使用python语言.dropna()函数将缺失和异常的数据删除,使用.dropna()函数将非数nan删除,随后采用式(1)进行数据归一化。
[0062]
步骤2:利用改进灰色关联度分析计算各个气象特征以及电气特征与目标特征之间的灰色关联度大小,剔除关联度小的特征;
[0063]
分析光伏电站提供的气象数据对发电功率的影响程度,进一步筛选出关键特征。
[0064]
传统灰色关联度分析是将所有特征重要性平等看待,无法很好地区分特征之间的影响程度。因此,本发明采用改进灰色关联度分析计算各个气象特征数据与发电功率数据之间相似程度以衡量特征间的影响程度,进而筛选出主要的特征进行模型的训练。
[0065]
对于一个m
×
n维的数据集,n为特征的数量,m表示特征的元素的数量,以x
obj
表示目标特征序列,xi表示第i个特征的特征数据序列,i=2,3,
…
,n,传统灰色关联分析的计算过程如下:
[0066]
1)数据标准化。根据式(1),标准化之后的特征序列为xi′
=(xi′
(1),xi′
(2),
…
,xi′
(m)),其中xi′
(m)表示第i个特征的第m个元素标准化的结果。
[0067]
2)求特征序列经过标准化之后的差值,计算式如下:
[0068]
δi(k)=|x
obj
′
(k)-xi′
(k)|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0069]
式中x
obj
′
(k)表示目标特征第k个元素标准化后的结果,xi′
(k)表示第i个特征第k个元素标准化后的结果,δi(k)表示第i个特征的第k个标准化之后的差值,i=2,3,
…
,n,k=1,2,
…
,m。
[0070]
3)计算关联系数,计算式如下:
[0071][0072]
式中ci(k)表示第i个特征的第k个元素的关联系数,m表示双重最大值,即m表示双重最小值,即ρ为分辨系数,通常取
0.5。
[0073]
4)计算灰色关联度,计算式如下:
[0074][0075]
式中ri为第i个特征的灰色关联度大小,i=1,2,3,
…
,n。
[0076]
式(4)无法反映各个特征数据的重要程度,因此基于距离分析法对各特征进行加权处理进而对灰色关联度分析做出改进,改进后的公式为:
[0077][0078]
式中表示改进后的灰色关联度大小,λi(k)表示第i个特征的第k个元素的权重系数,该权重系数基于欧式距离计算得到,即计算出目标特征与其他特征之间的距离,离目标距离越近,权重系数越大,计算式如下:
[0079][0080]
计算改进后的灰色关联度,当其他特征与目标特征的关联度大小在区间[0.7,1.0]时为强关联,在区间[0.4,0.7)时为弱相关,在[0,0.4)时为极弱相关或无关联。
[0081]
实施例的数据集的特征如表1所示。
[0082]
表1 特征信息表
[0083][0084]
利用改进灰色关联度分析对上述特征进行关联度的计算,关联度计算结果如图5所示,根据图中灰色关联度大小,平均电流ac、总倾角辐射rgt、总水平辐射ghr、水平扩散辐射dhr、倾角扩散辐射rdt、降雨量rain以及风速ws的改进灰色关联度大于0.7,都是与输出特征关联度强的特征。为保证气象信息的完整性,同时减少冗余信息对预测模型产生的负面影响,选取上述这6个特征作为预测模型的输入特征,以光伏发电功率作为预测模型输出的目标特征。
[0085]
步骤3:从已有特征数据时间序列中衍生出新的特征,对特征数据时间序列进行扩展,以增加特征数据时间序列在光伏发电功率预测中的表达能力,形成特征数据集;
[0086]
每个特征都可视为一个随时间序列变化的变量,为了从时间序列中挖掘出有用的新特征,采用单变量特征衍生方法从时间序列特征中提取新特征信息,即利用已有的时间序列特征%y-%m-%d %h:%m,从中提取出%y、%m、%d、%h、%m等新特征,其中%y为年份特征信息,%m为月份特征信息,%d为日期特征信息,%h为时辰特征信息,%m为分钟特征信息。在此基础上,根据月份%m,按照当地季节划分情况,可衍生出春、夏、秋、冬四个新特征;采用多变量特征衍生方法是从两个及两个以上的特征变量中衍生出新特征,即使用二阶多项式的形式构造对应的组合特征,如两个特征变量a和b,利用二阶多项式(a+b)2=a2+2ab+b2,可衍生出a2、ab、b2三个新的特征,通过多个变量特征之间不同组合,以增强有用特征的维度,充分为预测模型提供有价值的特征信息,特征衍生过程如图1所示,图中t表示时间序列,ap表示光伏发电功率特征数据。
[0087]
光伏夜间出力为0,故从数据集中选取时间段为5:00~20:00的数据,画出光伏发电功率随时间变化的曲线,如图6所示,图6反映了光伏发电功率具有的时间周期变化规律,澳洲的春、夏、秋、冬四个季节分别为9-11月、12-2月、3-5月以及6-8月。从图6中不难看出,光伏发电功率具有季节特性,随着季节的不同,发电起始时间以及跨度各不相同。
[0088]
考虑到不同季节下不同时间段光伏发电的功率输出情况,采用单变量特征衍生方法从时间序列中衍生出与时间相关的新特征,进而代入预测模型训练以提高预测模型的预测效果。表2给出了特征衍生结果,表2中年、月、日、小时以及分钟以数值形式表示,季节性特征采用独热编码(one-hot)的形式进行表示。
[0089]
将改进灰色关联度分析方法选择出的6个特征和变量特征衍生出的6个特征一起作为预测模型的输入特征用作预测模型的训练。
[0090]
表2 衍生的新特征信息表
[0091][0092]
步骤4:将catboost作为前级模型,radam-lstm作为后级模型,利用瀑布融合法构建功率预测模型,对功率预测模型训练并测试;
[0093]
步骤4.1:将catboost作为前级模型,采用k折交叉验证方法划分特征数据集,并输入catboost进行预测;
[0094]
步骤4.2:将catboost的输出结果作为新特征,结合步骤3得到的特征集,共同作为radam-lstm的输入,利用radam-lstm得到光伏发电功率的预测数据;
[0095]
步骤4.3:调节超参数,对功率预测模型重复进行训练并测试,直至满足精度要求;
[0096]
在神经网络模型的训练过程中,模型输出值和真实标签值间的差异用损失函数
loss来衡量,优化器获取学习参数的梯度并采用一定的策略更新参数,降低损失loss,优化学习率,从而减小模型输出值和真实标签值间的差值。
[0097]
神经网络模型参数优化方法的基础是随机梯度下降法(stochastic gradient descent,sgd),随后延伸出了adam优化算法以及radam优化算法,本发明采用radam优化神经网络参数,radam优化器是经典adam优化器的新变种,adam优化算法的核心是用指数滑动平均去估计梯度每个分量的一阶矩和二阶矩,二阶矩即为自适应学习率,并用二阶矩去标准化一阶矩,得到每一步的更新量:
[0098]mt
=β1m
t-1
+(1-β1)g
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0099][0100][0101][0102]
式中m
t-1
、m
t
分别表示t-1、t时刻的一阶矩,即动量;υ
t-1
、υ
t
分别表示t-1、t时刻的二阶矩,即自适应学习率,η是学习率,c
t
是偏差修正项,ε是控制更新量的最大步长,δθ是参数更新量;β1和β2是指数滑动平均的超参数,越小说明越倾向于局部平均。
[0103]
radam优化算法实则是采用adam优化算法的神经网络模型在训练初期将更新方法强制回退到带有动量的sgd算法,这样做的目的在于可避免训练初期v
t
的方差趋于无穷大带来的adam优化算法更新参数失效的问题;另一方面,radam优化器在adam优化器的基础上做了一个学习率预热的改进,即它在训练开始的时候先选择使用一个较小的学习率,事先优化一些训练参数后,再修改为预先设置的学习来进行训练,这样做的目的在于避免选择一个较大的学习率可能带来的模型不稳定,而从小的学习率着手可以使得模型慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
[0104]
本发明采用radam优化算法反向更新神经网络的权重以及偏置参数,相比于sgd优化算法、adam优化算法,radam优化算法优化的lstm神经网络稳定性高,既能保证收敛速度快,也能很好地规避陷入局部最优解的问题。
[0105]
实施例的catboost模型参照2017年在期刊《eprint arxiv》刊登的prokhorenkova等人的论文“catboost:unbiased boosting with categorical features”公开的catboost模型,它是一种基于梯度提升决策树(gradient boosting decision tree,gbdt)的机器学习框架,该模型对梯度估计方式进行改进,以解决梯度偏差及预测偏移的问题,从而减少过拟合的发生,提高模型预测的准确性和泛化能力。
[0106]
在gbdt的每一轮迭代训练过程中,损失函数使用相同的数据集求解每个样本的负梯度作为残差的近似值,从而求解下一轮的决策树,这将导致估计梯度在特征空间的任何域中的分布相对于该域中梯度的真实分布产生偏移,从而导致过拟合,为了解决上述问题,catboost采用排序提升的方式来减小梯度偏差,即用一个不包含第i个样本的数据集来求解第i个样本所对应的负梯度。
[0107]
对训练集进行随机排序,其中xk表示输入特征数据,yk表示输出特征数据,记排序结果为σ,σ=(σ
(1)
,σ
(2)
,
…
,σ
(n)
),对每一个样本,初始化该样本的模型mi,i=1,2,
…
,n,进而在每一轮迭代时计算样本的无偏梯度估计:
[0108]ri
=y
i-m
σ(i)-1
(xi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0109]
式中ri表示第i个样本的无偏梯度估计;m
σ(i)-1
(xi)表示基于排序σ
(i)-1
对样本xi的预测结果;
[0110]
对每一个样本xi,使用该样本在序列i之前的训练集(xj,rj),σ(j)≤i训练下一个决策树δm,模型更新公式为:m
i+1
=mi+δm,迭代完成后输出模型mn作为最终的模型。
[0111]
catboost模型训练过程采用k折交叉验证,其具体的处理步骤为:
[0112]
1)首先,将全部样本划分成k个大小相等的样本子集;
[0113]
2)依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
[0114]
3)最后把k次评估指标的平均值作为最终的评估指标。
[0115]
k折交叉验证避免为了追求高准确率而在训练集上产生过拟合,从而使得模型在样本外的数据上具有较高的预测准确率,本发明采用5折交叉验证,如图2所示。
[0116]
lstm是一种特殊形式的rnn网络,rnn网络通过使用自反馈的神经元,能处理任意长度的时序数据。简单rnn网络单元如图3a所示,rnn网络使用三个权重矩阵u、v、w,其中u、v、w分别表示输入层到隐藏层、隐藏层到输出层、前一时刻隐藏层对当前隐藏层贡献的权重值。
[0117]
记rnn网络在t时刻输入层的值是x
t
,隐藏层的输出值是h
t
,输出层的值是o
t
,根据网络结构原理,h
t
的值同时取决于x
t
和h
t-1
,数学表达式如下:
[0118]ot
=g(v
·ht
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0119]ht
=f[u
·
(x
t
+w
·ht
)]=f(u
·
x
t
+h
t-1
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0120]
式中g表示输出层的激活函数,f表示隐藏层的激活函数。
[0121]
由式(12)和式(13)可知,输出结果会受到每一级的影响,随着网络级数的增加,可能产生梯度爆炸或者梯度消失使得网络模型无法从训练数据中获得更新而使得最终的网络模型预测效果差。为了降低梯度问题的影响,提出了lstm模型,图3b所示为其循环单元结构。相比rnn,lstm引入了一个新的内部状态c
t
专门进行线性的循环信息传递,同时非线性地输出信息给隐藏层的外部状态,图3b所示的lstm循环单元的数学模型如下:
[0122]
z=tanh[w(x
t h
t-1
)
t
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0123]
zf=σ[wf(x
t h
t-1
)
t
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0124]
zi=σ[wi(x
t h
t-1
)
t
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0125]zo
=σ[wo(x
t h
t-1
)
t
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0126]
式中z为候选状态,是经tanh激活函数转换成-1到1的数值。其中zf表示遗忘门的门控状态,用于控制上一个时刻的内部状态c
t-1
需要遗忘多少信息;zi表示输入门的门控状态,用于控制当前时刻的候选状态z有多少信息需要保存;zo表示输出门的门控状态,用于控制当前时刻的内部状态从c
t
有多少信息需要输出给外部状h
t
。
[0127]
内部状态c
t
以及外部状态h
t
的计算式为:
[0128]ct
=zf⊙ct-1
+zi⊙zꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0129]ht
=zo⊙
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)
[0130]
式中
⊙
表示向量元素乘积,通过lstm循环单元,整个网络可以建立较长距离的时序依赖关系。
[0131]
stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
[0132]
瀑布融合方法采用了将多个模型串联的方式,通过将不同模型前后衔接的方法来进行组合。
[0133]
本发明采用stacking框架和瀑布融合方法,将catboost作为第一层模型,将radam-lstm作为第二层模型,将catboost输出的新特征结合原来的特征一起作为radam-lstm的输入特征对其进行训练,得到catboost与radam-lstm集成的光伏发电功率预测模型。
[0134]
步骤5:将利用训练好的功率预测模型用于光伏发电功率短期预测。
[0135]
实施例中对sgd、adam、radam优化算法分别用于lstm网络的训练得到的预测模型的预测效果进行对比。
[0136]
取400个序列点进行预测,每个点间隔5分钟,分别利用sgd、adam以及radam三种优化器优化lstm模型,预测效果分别如图7a、7b和7c所示,利用评价指标均方误差mse、决定系数r2以及平均绝对值误差mae来评估预测模型的效果,
[0137][0138][0139][0140]
式中y(t)、y(t)和分别为预测值、真实值和真实平均值,n表示测试集长度。mse和mae评价方式相似,数值越小说明预测误差越小,r2是一种评估预测曲线与真实值曲线的相似程度的参数,其取值范围为(0,1),当r2越趋近于1,其相似度越高,即预测精度越高。三种优化器优化的lstm网络的评价指标结果如表3所示。
[0141]
表3 sgd、adam以及radam优化器分别优化的lstm模型的预测效果对比表
[0142][0143]
由表3可见,radam优化器优化的lstm模型即radam-lstm模型的各项指标都明显优于其他两种模型。
[0144]
实施例采用如图2所示的5折交叉验证方法将数据集划分为5份,其中4份作为训练集,另外1份作为测试集,经过5轮训练与测试后,将每次catboost模型输出的预测值拼接在一起作为一个新的特征,并与步骤3得到的12个特征组合成13个特征,作为radam-lstm模型的输入特征,对其进行训练,catboost与radam-lstm的集成模型的预测结果如图8所示。
[0145]
为验证本发明提出的catboost与radam-lstm集成模型的合理性和有效性,将该集成模型与单个radam-lstm模型以及catboost模型预测效果进行对比,并利用mse、rmse、r2等评价指标进行对比,结果表明本发明所提方法可有效提高预测精度,单个的catboost模型的预测效果如图9所示,评价指标如表4所示。
[0146]
表4 不同的预测模型的测效果对比表
[0147][0148]
由表4以及图7a、7b、7c和图8、图9可见,本发明的catboost与radam-lstm集成模型的各项评价指标以及预测效果都明显占优;另外,本发明通过新增的特征,进一步提高了预测精度以及时间序列特征在光伏发电功率预测中的表达能力。
[0149]
本发明利用catboost模型不易过拟合以及通用性强的特点,采用stacking和瀑布融合思想将两种模型进行集成,即利用catboost通过k折交叉验证产生的新特征作为radam-lstm模型的输入特征进行最终的训练预测。实施结果表明,两者的集成模型增加了整个模型不易过拟合以及稳定性强的优势,进一步提高了预测的性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1