一种基于域适应和超分辨率的遥感图像双向语义分割方法
1.本公开属于遥感图像分割技术领域,具体涉及一种基于域适应和超分辨率的遥感图像双向语义分割方法。
背景技术:
2.利用有像素级标签的大数据集训练的深度神经网络推动了遥感图像语义分割的发展,但是像素级标签的标注工作需耗费大量时间与人力。无监督域适应(unsupervised domain adaptation,uda)是处理标签不足问题的有效方法之一,它通过缩小源域和目标域数据之间的特征差异,将从有标签的源域中学习得到的语义分割模型迁移应用到没有标签的目标域中。但是,不同来源的遥感图像因其空间分辨率存在差异,受不同成像地区、成像条件和成像时间的影响,往往具有不同的空间分辨率和特征分布。现有的无监督域适应方法大多是针对普通光学图像提出的,且由于遥感图像来源多,其空间分辨率存在差异,受不同成像地区、成像条件和成像时间的影响,其在光谱特征上存在较大差异,因此将无监督域适应方法直接应用于遥感图像往往效果不佳。
3.针对遥感图像的无监督域适应方法不仅要缩小源域和目标域之间的特征差异,而且要解决不同空间分辨率的问题。现有方法中,可通过使用简单的插值方法统一源域和目标域的空间分辨率大小,然后通过在特征空间中对齐源域数据和目标数据的特征分布来消除域差异,这种方法虽然在一定程度上消除了图像分辨率差异,但其在纹理特征等细节信息上处理不够完善,重建结果偏向于平滑。
4.此外,基于卷积神经网络的超分辨率方法能够极大提升超分辨效果,但是,由于不同来源的遥感图像的源域和目标域往往具有明显的视觉风格差异,不同于一般的超分辨率方法只需重建低分辨率源域图像自身的细节信息,应用于域适应领域的超分辨率方法需要学习到高分辨率目标域图像的特征,才能更好地实现模型的迁移应用。
5.近年来,基于生成对抗网络的图像翻译模型和深度域适应方法结合的研究取得了长足进展,其利用图像风格翻译得到的具有目标域风格的源域合成图像训练语义分割模型,然后通过对抗性域适应方法进一步解决真实图像(目标域)和合成图像(源域)之间的特征差异问题。但是,目前还未见将超分辨率方法与上述图像翻译方法相结合的研究。
技术实现要素:
6.针对现有技术中的不足,本公开的目的在于提供一种基于域适应和超分辨率的遥感图像双向语义分割方法,该方法综合了深度语义分割模型和域适应技术,解决了从低分辨率源域数据到高分辨率目标域数据的语义分割迁移学习任务。
7.为实现上述目的,本公开提供以下技术方案:
8.一种基于域适应和超分辨率的遥感图像双向语义分割方法,包括如下步骤:
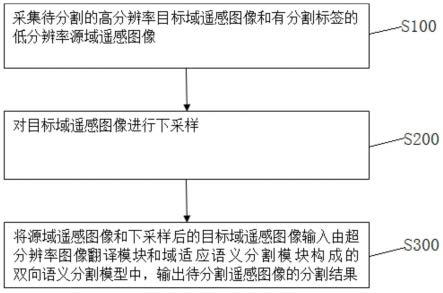
9.s100:采集待分割的高空间分辨率目标域遥感图像和有分割标签的低空间分辨率源域遥感图像;
10.s200:对目标域遥感图像进行下采样;
11.s300:将源域遥感图像和下采样后的目标域遥感图像输入由超分辨率图像翻译模块和域适应语义分割模块构成的双向语义分割模型中,输出待分割图像的分割结果。
12.优选的,所述超分辨率图像翻译模块包括:
13.特征提取网络,用于对源域遥感图像和下采样后的目标域遥感图像进行特征提取,获得低分辨率的特征图;
14.高分辨率图像生成网络,用于将低分辨率的特征图恢复为高分辨率的特征图;
15.像素级域判别器,通过和高分辨率图像生成网络进行生成对抗训练,以将高分辨率的特征图生成具有目标域风格的源域高分辨率合成图像。
16.优选的,所述高分辨率图像生成网络包括:两个亚像素卷积层和一个上采样层,且每个亚像素卷积层连接一个relu激活函数。
17.优选的,所述像素级域判别器包括:4层卷积核大小为4
×
4的二维卷积层。
18.优选的,所述域适应语义分割模块包括:
19.语义分割解码器网络,用于通过二维卷积操作和softmax操作将由特征提取网络提取的低分辨率的特征图输出为源域和目标域遥感图像的分割预测结果图;
20.输出空间级判别器,用于对由语义分割解码器网络输出的分割预测结果图进行对抗性域适应学习。
21.优选的,所述语义分割解码器网络包括:两个卷积核为3x3的二维卷积层,一个卷积核为9x9、步长为2的二维卷积层和soffmax分类层。
22.优选的,所述输出空间级判别器包括:5个卷积核大小为4
×
4的二维卷积层,每个卷积层连接一个leakyrelu激活函数。
23.优选的,所述双向语义分割模型的训练过程包括:
24.s1、对超分辨率图像翻译模块进行预训练,当超分辨率图像翻译模块收敛且损失降到最低且稳定不变时,训练完成;
25.s2、基于预训练好的超分辨率图像翻译模块对域适应语义分割模块进行预训练,当域适应语义分割模块收敛且损失降到最低且稳定不变时,训练完成;
26.s3、基于预训练好的域适应语义分割模块对目标域训练集图像生成伪标签a
t*
;
27.s4、通过预训练好的语义分割模块生成的合成图像分割结果和源域标签为源域合成图像生成矫正标签as′
;
28.s5、基于伪标签a
t*
和矫正标签as′
分别对源域合成图像和目标域图像的分割结果计算交叉熵损失l
cel
;
29.s6、重复执行步骤s3至步骤s5,直至双向语义分割模型收敛,若不收敛,则进行调参或增加训练次数直至收敛。
30.优选的,基于预训练好的超分辨率图像翻译模块通过双向学习方法对域适应语义分割模块进行预训练。
31.优选的,所述双向学习方法包括正向促进学习和反向促进学习。
32.与现有技术相比,本公开带来的有益效果为:
33.(1)本公开设计了一个用于遥感图像域适应的超分辨率图像翻译模块,将低分辨率源域图像生成具有目标域风格的高分辨率合成图像,再利用细节信息更完整、更易于迁
移学习的合成图像及矫正过的合成图像标签训练语义分割模块,应对源域低空间分辨率数据训练得到的语义分割模型不能很好迁移应用于高分辨率目标域数据的问题。
34.(2)提出了一个结合超分辨率和域适应的双向语义分割方法bssm-srda,在正向,fa-loss利用具有更多细节信息的高分辨率图像提高语义分割的性能;在反向,提出一种新的感知损失,通过标签矫正方法修正合成图像引入的误差,促进超分辨率图像翻译模块的进一步学习。
35.(3)结合自监督学习ssl为bssm-srda设计了一种新的双向学习算法,使得超分辨率图像翻译模块和域适应语义分割模块能更好地相互激励学习。
附图说明
36.图1是本公开提出的一种基于域适应和超分辨率的遥感图像双向语义分割方法的流程图;
37.图2是双向语义分割模型的结构示意图;
38.图3是输入超分辨率图像翻译模块的源域遥感图像;
39.图4是输入超分辨率图像翻译模块的下采样的目标域遥感图像;
40.图5是高分辨率图像生成网络输出的目标域高分辨率图像;
41.图6是超分辨率图像翻译模块输出的高分辨率源域合成图像;
42.图7是源域分割预测结果图;
43.图8是目标域分割预测结果图;
44.图9是待分割的高分辨率目标域测试集遥感图像;
45.图10是待分割的高分辨率目标域测试集遥感图像的标签;
46.图11是采用adaptsegnet获得的分割结果;
47.图12是采用fcan获得的分割结果;
48.图13是采用bdl获得的分割结果;
49.图14是采用srda获得的分割结果;
50.图15是采用scaleda获得的分割结果;
51.图16是采用本公开所述方法获得的分割结果。
具体实施方式
52.下面将参照附图1至图16详细地描述本公开的具体实施例。虽然附图中显示了本公开的具体实施例,然而应当理解,可以通过各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
53.需要说明的是,在说明书及权利要求当中使用了某些词汇来指称特定组件。本领域技术人员应可以理解,技术人员可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名词的差异作为区分组件的方式,而是以组件在功能上的差异作为区分的准则。如在通篇说明书及权利要求当中所提及的“包含”或“包括”为一开放式用语,故应解释成“包含但不限定于”。说明书后续描述为实施本公开的较佳实施方式,然所述描述乃以说明书的一般原则为目的,并非用以限定本公开的范围。本公开的保护范围当视所附权利要
求所界定者为准。
54.为便于对本公开实施例的理解,下面将结合附图以具体实施例为例做进一步的解释说明,且各个附图并不构成对本公开实施例的限定。
55.一个实施例中,如图1所示,本公开提供一种基于域适应和超分辨率的遥感图像双向语义分割方法,包括如下步骤:
56.s100:采集待分割的高空间分辨率目标域遥感图像和有分割标签的低空间分辨率源域遥感图像;
57.s200:计算源域和目标域遥感图像空间分辨率之间的倍数关系获得倍数值(由于遥感数据集都会提供数据的空间分辨率大小,通过简单除法即可得到源域和目标域数据集的空间分辨率倍数关系),以倍数值为下采样因子,对目标域遥感图像进行下采样,使得目标域遥感图像与源域遥感图像的空间分辨率相同;
58.s300:将源域遥感图像和下采样后的目标域遥感图像输入如图2所示的由超分辨率图像翻译模块和域适应语义分割模块构成的双向语义分割模型中,输出待分割遥感图像的分割结果。
59.本实施例所述方法综合了深度语义分割模型和域适应技术,解决从低分辨率源域数据到高分辨率目标域数据的语义分割迁移学习任务。并且构建了由超分辨率图像翻译模块和域适应语义分割模块构成的双向语义分割模型,前者将超分辨率方法融合到图像翻译中,后者结合对抗性域适应方法在输出级进一步缩小域差异,从而缩小源域和目标域之间的空间分辨率差异和特征分布差异,使得在源域上训练的模型可以更好地完成来源不同、分辨率不同的目标域图像语义分割任务。
60.另一个实施例中,所述超分辨率图像翻译模块包括:
61.特征提取网络,采用空洞空间卷积池化金字塔网络对源域遥感图像(如图3所示)和下采样后的目标域遥感图像(如图4所示)以具有不同采样率的空洞卷积(空洞卷积本质上也是二维卷积,但是较一般的二维卷积有不同的填充值和膨胀值)并行采样,即以多个比例捕捉图像的上下文信息,较于标准的卷积具有更大的感受野,更有助于捕捉不同尺寸的分割目标。特征提取网络输出通道数为256、分辨率大小为源域遥感图像和下采样后的目标域遥感图像1/2的低分辨率特征图;
62.高分辨率图像生成网络,用于将由特征提取网络输出的低分辨率的特征图先通过二维卷积获得通道数为r2的低分辨率特征图,然后通过不同通道的信息来填充得到放大r倍的高分辨率图像(如图5所示),其中,r为上采样因子(还可通过双线性插值法获得高分辨率特征图,具体实现方法是计算四个周围像素的加权平均值,并将其填补于扩大分辨率后的空白像素点)。
63.像素级域判别器,通过和高分辨率图像生成网络进行生成对抗训练,将由高分辨率图像生成网络输出的特征图生成具有目标域风格的高分辨率源域合成图像(如图6所示)。训练时,将目标域高分辨率图像标记为真样本(记为1),将生成的源域合成图像标记为假样本(记为0)。固定高分辨率图像生成网络参数不变,先对像素级判别器进行训练,即给定一个生成图像,使判别器判别其是真还是假。模型训练初始时生成的合成图像很容易就能被判别器认定为假样本,即判别器的损失趋近于1。因此完成判别器的训练后,固定像素级判别器的参数不变,对高分辨率图像生成网络进行训练(根据该网络的损失函数对它的
参数进行更新),生成具有真样本特征的合成图像。完成生成网络的训练后,将再次固定其参数对判别器进行训练。通过不断重复上述过程,直到判别器不能分出真假样本为止(此时判别器的损失将稳定在0.5左右)。
64.需要说明的是,像素级域判别器判别合成图像的不同区域来自源域还是目标域,通过生成器和判别器的迭代训练,当判别器无法分清该区域的域类时,表示生成的源域高分辨率合成图像已经学习到目标域的风格。
65.本实施例中,特征提取网络包括三层卷积核为3x3的二维卷积层、一个最大池化层和一个空洞空间卷积池化金字塔结构组成,其中每一个二维卷积层后都接一层leakyrelu层。空洞空间卷积池化金字塔结构由一个卷积核为1x1的二维卷积层和三个膨胀率和填充率分别为1、4、8的二维卷积层并列组成,将这四层卷积得到的特征图拼接,再通过一层卷积核为1x1的二维卷积层,得到最终的低分辨率特征图。
66.高分辨率图像生成网络中所述的二维卷积公式如下:
[0067][0068]
其中,x
2d
为输入,y
2d
为输出,(x+h,y+w)为输入数据中的位置,(x,y)为对应的输出数据的位置。表示二维卷积核k
2d
在位置(h,w)处的值,h和w分别表示二维卷积核k
2d
的高度和宽度,且h∈h,0≤h<h,w∈w,0≤w<w。
[0069]
另一个实施例中,所述高分辨率图像生成网络包括:两个亚像素卷积层和一个上采样层,且每个亚像素卷积层连接一个relu激活函数。
[0070]
另一个实施例中,所述像素级域判别器包括:4层卷积核大小为4
×
4的二维卷积层。
[0071]
本实施例中,通过四层二维卷积操作将输入映射为一个矩阵,矩阵中的每个值代表图像中某区域为真样本的概率,对最后输出的矩阵中的数值求平均,得到像素级域判别器的最终输出。
[0072]
另一个实施例中,所述域适应语义分割模块包括:
[0073]
语义分割解码器网络,用于通过二维卷积操作和softmax操作将由特征提取网络提取的低分辨率的特征图输出为源域分割预测结果图(如图7所示)和目标域分割预测结果图(如图8所示),分割预测结果图的分辨率大小和高空间分辨率目标域遥感图像相同;
[0074]
输出空间级判别器,用于对由语义分割解码器网络输出的分割预测结果图进行对抗性域适应学习,以减小源域和目标域的域间特征差异。
[0075]
需要说明的是,当输出空间级判别器无法分清分割预测结果的每个像素来自源域还是目标域时,表示义分割网络已经能提取得到源域和目标域的域不变性特征。
[0076]
本实施例中,语义分割解码器网络中所述的二维卷积操作表示如下:
[0077][0078]
其中,x
2d
表示输入,y
2d
表示输出,(x+h,y+w)表示输入数据中的位置,(x,y)为对应的输出数据的位置,表示二维卷积核k
2d
在位置(h,w)处的值,h和w分别表示二维卷积
核k
2d
的高度和宽度,且h∈h,0≤h<h,w∈w,0≤w<w。
[0079]
softmax函数表达式如下:
[0080]
softmax(xi)=p(y=c|xi)
[0081][0082]
其中,xi表示输入的特征像素,p(y=c|xi)表示该像素属于第c类的概率。
[0083]
另一个实施例中,所述语义分割解码器网络包括:两个卷积核为3x3的二维卷积层,一个卷积核为9x9、步长为2的二维卷积层和softmax分类层。
[0084]
另一个实施例中,所述输出空间级判别器包括:5个卷积核大小为4
×
4的二维卷积层,每个卷积层连接一个leakyrelu激活函数。
[0085]
另一个实施例中,所述双向语义分割模型的训练过程包括:
[0086]
s1、对超分辨率图像翻译模块r进行预训练,当超分辨率图像翻译模块收敛且损失降到最低且稳定不变时,训练完成;
[0087]
该步骤中,超分辨率图像翻译模块r的输入为源域图像is和下采样到源域分辨率的目标域图像
↓it
,输出为源域合成图像is′
,对具有高低分辨率图像对的目标域计算超分辨率领域广泛使用的均方误差损失l
mse
,对源域的低分辨率原图和高分辨率合成图像计算感知损失l
per-nor
,超分辨率图像翻译模块的损失lr和像素级判别器的损失l
pdd
为:lr=l
mse
(r(
↓it
),i
t
)+l
per_nor
(is′
,
↑is
)
[0088][0089]
其中,d
pdd
为像素级判别器,p
data
(*)表示数据的分布,表示分布函数的期望值,log(d
pdd
(i
t
))表示判别器将目标域数据判定为真的概率,log(1-d
pdd
(is′
))表示判别器将合成图像判定为假的概率,
↓
表述下采样操作,个表示上采样操作。生成器希望合成图像被判定为假的概率越低越好,被判定为真的概率越大越好,即最大化损失函数l
pdd
,最小化损失函数lr。
[0090]
s2、基于预训练好的超分辨率图像翻译模块对域适应语义分割模块s进行预训练,当域适应语义分割模块收敛且损失降到最低且稳定不变时,训练完成;
[0091]
该步骤中,域适应语义分割模块s的输入为源域图像is、源域合成图像is′
、源域分割标签as和目标域图像i
t
,输出为目标域分割分割预测结果。在对目标域进行自监督学习获得伪标签之前,域适应语义分割模块的损失ls为源域原图和合成图像的交叉熵损失l
cel
以及起到正向促进学习作用的特征相似性损失l
fa
,损失函数为:
[0092]
ls=l
cel
(s(is),
↑as
)+l
cel
(s(
↓is
′
),
↑as
)+l
fa
[0093]
输出空间级域判别器的损失l
odd
函数为:
[0094][0095]
其中,d
odd
是输出空间级域判别器,首先将源域和目标域图像经过分割模块输出的分割预测结果作为判别器的输入,然后判断输入样本的域类(源域或目标域),如果样本来自目标域,则z=0;如果样本来自源域,则z=1;h和w分别表示输入图像的高度和宽度。
[0096]
s3、在步骤s2的基础上,通过预训练好的语义分割模块对目标域训练集图像生成
伪标签。采用最大概率阈值法选择目标域分割预测概率中置信度较高的像素作为伪标签a
t*
。
[0097]
s4、在步骤s2的基础上,通过预训练好的域适应语义分割模块生成的合成图像分割结果和源域标签为源域合成图像生成矫正标签as′
。
[0098]
s5、结合步骤s3和s4生成的目标域伪标签a
t*
和源域合成图像矫正标签as′
,分别对合成图像和目标域图像的分割结果计算交叉熵损失l
cel
,达到进一步训练双向语义分割模型的目的。同时,对合成图像分割结果和源域标签计算新的感知损失l
per_new
,起到反向促进学习超分辨率图像翻译模块的作用。此时,双向语义分割模型的最终损失函数为:
[0099][0100]
类似于标准的生成对抗网络,双向语义分割模型的最终目的是最小化域适应语义分割模块s的损失ls和超分辨率图像翻译模块r的损失lr,同时最大化目标域在判别器(包括像素级判别器pdd和输出空间级判别器odd)中被判别为源域的概率。其中,ls为:
[0101]
ls=l
cel
(s(is),
↑as
)+l
cel
(s(
↓is
′
),as′
)+l
cel
(s(t
ssl
),a
t*
)+l
fa
[0102]
lr为:
[0103]
lr=l
mse
(r(
↓it
),i
t
)+l
per_nor
(is′
,
↑is
)+l
per_new
(s(
↓is
′
),
↑as
)
[0104]
s6、重复步骤s3至步骤s5,直至双向语义分割模型收敛,即模型训练的总损失值降到最低,且损失曲线的梯度在接下来一段时间内都为0或已接近0(损失值最低,可以通过步骤s5中所列损失函数的曲线来判断,当曲线的坡度逐渐放缓,其梯度值接近于0或者已经为0,就认为损失函数到达了一个极小值点),若不收敛,则进行调参或增加训练次数直至收敛。
[0105]
另一个实施例中,基于预训练好的超分辨率图像翻译模块通过双向学习方法对域适应语义分割模块进行预训练。
[0106]
本实施例中,域适应语义分割模块的深层提取得到的特征语义信息丰富而细节信息丢失,而超分辨率图像翻译模块的深层能恢复更多细节结构信息;基于生成对抗网络的超分辨率图像翻译模块生成的合成图像不可避免会引入噪声,而超分辨率图像翻译模块本身无法为其训练过程提供太多约束信息,但是通过域适应语义分割模块可以根据合成图像的分割结果和源域标签图来判断是否有内容不一致现象。根据以上两点,本实施例为域适应语义分割模块和超分辨率图像翻译模块设计了正向促进学习和反向促进学习。
[0107]
其中,正向促进学习通过计算超分辨率图像翻译模块第一层和语义分割解码器第一层的特征图上每对像素的相似度,作为特征相似性损失帮助训练语义分割模块,增强语义分割解码器特征图的细节结构信息,其具体步骤包括:
[0108]
步骤1、取超分辨率图像翻译模块第一层和域适应语义分割解码器第一层的特征图,通过1
×
1卷积层、batchnorm和relu层,进行特征维度变换。
[0109]
步骤2、计算得到每张特征图f的相似性矩阵c
ij
,c
ij
表示特征图上第i个和第j个像素之间的关系,计算公式如下:
[0110]
[0111]
步骤3、特征相似性损失l
fa
的目的是学习两个特征图相似性矩阵之间的距离,计算公式为:
[0112][0113]
其中,w
′×h′
表示空间维度,表示语义分割模块特征图的相似性矩阵,表示超分辨率模块特征图的相似性矩阵。
[0114]
反向促进学习是基于生成对抗网络生成的源域合成图像的视觉内容可能与源域标签不匹配,为避免给分割模型的训练带来干扰,反向促进学习包括对合成图像的标签矫正策略和一种新的感知损失约束图像翻译模块的进一步学习,其具体步骤包括:
[0115]
步骤1、将超分辨率图像翻译模块输出的合成图像is′
送入域适应语义分割模块得到分割结果,通过最大概率阈值法筛选分割结果中高置信度的像素作为合成图像的伪标签a
s*
。
[0116]
步骤2、通过标签矫正策略将源域标签as中低置信度的像素标签替换为伪标签a
s*
中的高置信度的标签,达到标签矫正的目的。定义矫正后的合成图像的标签as′
={as′
(i,j)
}(1≤i≤h,1≤j≤w)为:
[0117][0118]
其中,p(*)为分割模型预测的概率图,k和k*分别表示a
s(i,j)
和a
s*(i,j)
中的类别索引,δ为矫正率,h和w分别表示标签图的高度和宽度。
[0119]
综上,域适应语义分割模块的损失函数表示为:
[0120]
ls=l
cel
(s(is),
↑as
)+l
cel
(s(
↓is
′
),as′
)+l
cel
(s(t
ssl
),a
t*
)+l
fa
[0121]
超分辨率图像翻译模块的损失函数表示为:
[0122]
lr=l
mse
(r(
↓it
),i
t
)+l
per_nor
(is′
,
↑is
)+l
per_new
(s(
↓is
′
),
↑as
)
[0123]
步骤3、对合成图像的分割结果图和源域像素级标签图之间计算感知损失l
per_new
,通过最小化感知损失反过来进一步约束超分辨率图像翻译模块的训练。
[0124]
本实施例中,首先,预训练超分辨率图像翻译模块为后续语义分割模型的训练提供翻译良好的合成图像。然后,在预训练好的超分辨率图像翻译模块的基础上训练域适应语义分割模块,并且在ls中加入了特征相似性损失fa-loss,利用已经训练良好的r促进域适应语义分割模块的学习。最后,采用迭代的方式实现自监督学习,对双向语义分割模型进行n次迭代训练,在ls中加入目标域的自监督损失,在lr中加入新的感知损失。其中,在每一次对目标域自监督训练生成伪标签后,都对源域合成图像进行标签矫正。测试阶段,将目标域测试集数据输入训练好的双向语义分割模型,得到最终的分割预测结果。
[0125]
下面,本公开通过具体实施例对以上方案进行详细说明。
[0126]
1、准备数据集
[0127]
(1)vaih-pots:使用isprs提供的具有六个类别的vaihingen和potsdam两个遥感数据集进行多类域适应语义分割实验。将由33张空间分辨率为9cm的vaihingen数据集视为源域,将包括38张空间分辨率为5cm的potsdam数据集视为目标域。实验中将源域vaihingen
的所有图像作为训练集,将目标域potsdam标号从2-10到5-12的19幅图像划分为训练集,其他19幅图像作为测试集。由于源域与目标域数据的空间分辨率差异约为2倍,因此将vaihingen裁剪为180
×
180像素大小,将potsdam裁剪为360
×
360像素大小。
[0128]
(2)青藏高原数据集tpds-tpdt:自行制作的青藏高原数据集(tibet plateau dataset,tpd)选取1990年和2021年不同传感器拍摄的青藏高原地区遥感数据,源域tpds为两张8192
×
8192像素大小的遥感图像,其空间分辨率为90m;目标域tpd_t为一张7651
×
7781像素大小的遥感图像,其空间分辨率为30m。我们人工标注得到此数据集标签,共分4类,分别为植被、裸地、水体和其他。由于源域和目标域的空间分辨率差异为3倍,因此将源域裁剪为86
×
86像素大小,将目标域裁剪为256
×
256像素大小。
[0129]
2、实验设置
[0130]
实验在24gb内存的nvidia geforce rtx
tm 3090 gpu以及深度学习框架pytorch上实现。使用adam优化器,动量为0.9。在实际训练过程中,预训练r时将所有样本训练20次,预训练bssm-srda0时将所有样本训练30次,循环训练bssm-srdai时将训练所有样本30次,每轮训练的前一半设置学习率为2
×
104,后一半的学习率逐次递减直至为0。实验中采用适用于多分类任务的miou和macro-f1作为评价指标。
[0131]
3、实验结果及分析
[0132]
3.1超参数实验
[0133]
本公开通过实验在vaih-pots数据集上对本方法中提到的超参数进行选择,包括自监督学习迭代次数n、选择伪标签的置信度阈值ε、标签矫正策略lcs的迭代次数和矫正率δ。
[0134]
(1)自监督学习迭代次数n和置信度阈值ε
[0135]
当自监督学习迭代次数n=1时,bssm-srda1在不同置信度阈值ε下选取伪标签进行训练后,得到的miou结果如表1所示。当阈值ε低于0.9时,一些错误的预测可能会成为伪标签,为语义分割模型的训练带来干扰;当阈值ε为0.95时,能使用的伪标签像素数量较少,bssm-srda1的训练效果反而降低了。因此,在后续的实验中,本文将选取伪标签的置信度阈值ε确定为0.9。
[0136]
表1不同阈值ε的影响
[0137][0138]
随着自监督学习迭代次数n的增加,本公开所提出的基于域适应和超分辨率的遥感图像双向语义分割方法(简称bssm-srda)为目标域更多高置信度的像素赋以伪标签,以增加目标域的训练样本数量,使bssm-srda向目标域数据更好地迁移学习。而一旦有伪标签的目标域数据集合t
ssl
停止增加,就说明对bssm-srda的学习已经收敛。当置信度阈值ε为0.9时,随着迭代次数n的增加,bssm-srda(不进行标签矫正)在vaih-pots数据集上的分割结果如表2所示。可以发现,随着n的增加,bssm-srda的性能越好,生成的伪标签中白色像素越少。当n=3时,miou值增加速度非常缓慢,仅增加了0.1%,考虑到n的增加会带来更多计
算量,因此在后续实验中选取迭代次数n为2。
[0139]
表2迭代次数n的影响
[0140][0141]
(2)标签矫正策略的矫正率δ和迭代次数
[0142]
bssm-srda通过标签校正策略确定合成图像的标签,以避免合成图像与源域原标签的内容不一致,干扰语义分割模块的学习。矫正率δ用来筛选源域原标签中需要被矫正的像素,表3显示了不同矫正率δ下bssm-srda1的miou精度,可以发现δ是一个不太敏感的超参数,在本文后续实验中设置为0.3。
[0143]
表3矫正率δ的影响
[0144][0145][0146]
从表4可见第一轮迭代训练完成后,标签矫正策略使bssm-srda1的miou提升了0.9%,第二轮训练后使bssm-srda2的miou提升0.6%,第三轮训练后使bssm-srda3的miou仅提升了0.1%。实验表明第二轮训练后bssm-srda的学习已经收敛,此结论与自监督学习迭代次数n的实验结论吻合,因此后续实验中设置标签矫正策略的迭代次数与n相同,均为2次。
[0147]
表4标签矫正策略迭代次数的影响
[0148][0149]
3.2在两个数据集上与最新方法的比较
[0150]
本公开在对抗性域适应语义分割领域选取了包括adapsegnet、fcan、bdl、srda和sca1eda在内的五个具有可比性的最新方法进行了对比实验:从表5中可以看出每个对比实验所采用的方法。在图像翻译方面,fcan和bdl将图像翻译网络和域适应语义分割网络独立训练,而srda和bssm-srda将两者融合到一个网络中,bssm-srda通过一种新的感知损失保持图像翻译的视觉一致性;在自监督学习方面,bdl的自监督学习仅针对目标域的语义分割方法,bssm-srda结合自监督学习设计了双向学习算法,将源域合成图像的标签矫正策略融入自监督过程,促进语义分割和图像翻译模块的双向学习;在域间空间分辨率差异方面,srda在模型中使用简单的双线性插值将源域恢复到目标域分辨率大小,scaleda通过增加一个域间尺度判别器缩小空间分辨率差异带来的分割目标尺度差异,bssm-srda将超分辨率方法结合到图像翻译模块中,将源域图像的分辨率恢复到目标域大小。
[0151]
表5bssm-srda及五个对比实验采用的方法
[0152][0153]
(1)vaih-pots
[0154]
表6给出了在vaih-pots遥感数据集上最新方法与bssm-srda的比较结果,可见bssm-srda的性能达到了最高(bssm-srda的miou为48.8%,macro-f1为64.1%)。如表6所示,增加了图像翻译模型的fcan(miou为42.0%)较adapsegnet(miou为35.1%)在miou上获
得了6.9%的改进,结合自监督学习交替训练图像翻译模型和语义分割模型的bdl(miou为44.9%)较fcan获得了2.9%的改进,与之前最好的srda(miou为46.0%)相比,本文的bssm-srda同样将图像翻译与语义分割网络结合,但通过结合超分辨率和双向学习算法,将miou提高了2.8%。没有做图像翻译工作的scaleda(miou为43.4%)针对遥感图像空间分辨率差异问题设计了尺度判别器和尺度注意力,较adapsegnet的miou提高了8.3%,说明在遥感图像域适应领域解决空间分辨率差异是非常必要的。示例性的,图9给出了待分割的高分辨率目标域测试集遥感图像,图10给出了待分割的高分辨率目标域测试集遥感图像的标签,图11至图16分别显示了bssm-srda和五个对比方法的分割结果。通过图11至图16可以观察到,bssm-srda的分割结果在结构与细节上均优于adaptsegnet、fcan、bdl、srda和scaleda。
[0155]
表6 vaih-pots数据集上对比方法与bssm-srda的比较结果
[0156][0157]
(2)青藏高原数据集tpds-tpdt
[0158]
表7给出了在tpds-tpdt遥感数据集上最新方法与bssm-srda的比较结果,bssm-srda在所有类别及综合评价指标上都取得了最好的结果,miou为61.5%,macro-f1为73.1%,较之前最好的srda的miou提升了3.2%,macro-f1提升了3.9%。
[0159]
表7vaih-pots数据集上对比方法与tpds-tpdt的比较结果
[0160][0161]
相较于vaih-pots数据集,tpds和tpdt数据集之间具有更明显的视觉风格差异和特征差异,例如源域tpds数据中有大量小型的湖泊且植被类较少,而目标域tpdt数据中几乎没有小型湖泊且植被类较多。由于bssm-srda结合了超分辨率方法,其生成的图像分辨率更高且细节信息更丰富,通过双向促进学习算法更有助于语义分割模型的性能提升。
[0162]
以上对本公开进行了详细介绍,本文中应用了具体个例对本公开的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本公开的方法及其核心思想;同时,对于本领域技术人员,依据本公开的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本公开的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1