一种利用梯度下降的学习索引
1.本发明属于数据库索引领域,涉及利用机器学习优化传统索引的技术,具体涉及一种利用梯度下降算法拟合数据的索引优化方法。
背景技术:
2.索引是数据库中提升数据读取性能的技术之一。在传统索引技术中基于树结构的索引运用最为广泛,它们通过将数据的键组织成一棵树而减少查询的次数,从而提高查询的速度,但随着数据量的不断增加,树的体积会越来越大。所以近几年来,研究人员也通过各种不同的方式减少索引的结构大小,例如前/后缀截断、哈夫曼编码等技术。但是这些方式随着数据量的爆发式增加也失去了效果,因为数据量的暴增,不仅键的数量会增加,同时键本身的长度也会增加,从而导致传统索引的开销也随之线性增加。由于最近几年人工智能和数据库得到了广泛地研究,进而有研究人员将人工智能和数据库结合起来,利用人工智能技术解决传统数据库无法满足大规模数据库实例等问题。而索引就是其中一个方面,近年有人提出了“学习索引”的概念,将机器学习引入索引技术,有效地解决了索引空间开销问题,同时也提高了查询性能。
3.学习索引通过机器学习技术学习数据分布规律,通过模型拟合数据,将传统索引的间接查询优化为函数计算的直接查询,从而使查询的效率要优于b+树等传统索引的性能。而且,学习索引只需要存储模型的参数即可,所以在空间代价上,学习索引也要优于传统索引。
4.但是当前的学习索引还存在许多问题,如下:
5.(1)拟合效果差:目前大多数学习索引模型都是通过欧几里得距离作为相似度进行数据划分,但是欧几里得距离体现的是个体数值的绝对差异,多用于需要从维度的数值大小中体现差异的分析中;而对于学习索引中的数据拟合,更多的是需要把在同一条线段附近的数据划分在一起,其中更重要的是方向上的差异,所以这导致线段拟合误差较大,从而导致进行本地搜索的时候花费更多的时间。
6.(2)上层结构开销大:大多数现有学习索引模型的上层结构还是使用常见的数据结构组织,例如树、哈希表等,这些传统的数据结构的最大缺点就是它们的空间开销还是会随着数据量的暴增而增大,进而导致整个索引结构依旧会有很大的空间开销,降低了查询性能。
7.(3)不支持插入:因为大量新数据的插入会破坏数据分布规律,导致模型失效,从而要重新训练模型,而模型重训练的成本是很大的,所以学习索引模型只针对静态数据。
技术实现要素:
8.针对现有技术存在的问题和改进需求,本发明提供了一种利用梯度下降算法的学习索引模型,该模型先利用余弦相似度进行数据划分,再利用梯度下降算法更好地拟合数据,减少拟合误差,缩短本地查找的时间,同时递归调用数据划分算法和数据拟合算法,充
分利用键的分布规律,构建上层结构,避免索引结构随着数据量而增大。另外,利用链表解决学习索引不支持数据插入的问题。
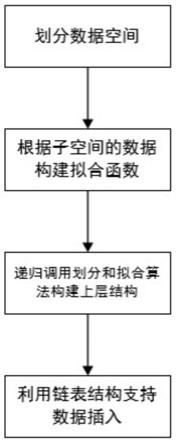
9.一种利用梯度下降的学习索引模型,包括了如下步骤:
10.(1)对数据集进行划分,使每个划分所得的子数据集中的数据无重叠部分,且子数据集中的数据分布尽可能一致;
11.(2)利用每个子数据集中的数据分布规律构建每个子数据集对应的线段模型;
12.(3)递归调用数据划分算法和数据拟合算法,构建上层结构;
13.(4)利用链表结构存储新插入的数据。
14.进一步地,所述步骤(1)的具体实现方式为:在源数据集上利用余弦相似度对数据集进行划分,预先设定一个阈值,若添加的点与它前面的两个点形成的向量夹角余弦值小于设定的阈值,则将该点作为分段点。通过余弦相似度的划分方式将分布在同一条线段附近的数据划分在同一个子集中,并且子集之间保证无数据重复。
15.进一步地,所述步骤(2)的具体实现方式为:在每个子数据集中调用梯度下降算法,训练子数据集对应的线段模型,使其损失函数值尽可能的小。在本发明中选择的线段模型是低阶函数,因为高阶函数训练代价较高。
16.进一步地,所述步骤(3)的具体实现方式为:当步骤(2)中的模型全部训练完毕后,提取底层每个模型所覆盖的第一个数据,产生一个新的数据集,然后在该数据集上递归调用步骤(1)中的数据划分算法和步骤(2)中的数据拟合算法,形成上层模型,然后在每一层模型上递归此操作直至最后只产生一个模型,最后作为最上层。
17.进一步地,所述步骤(4)的具体实现方式为:当有新数据插入时,先通过模型计算出插入的位置,然后根据计算出的位置状态进行不同的操作。若位置为空则直接插入,若位置不为空,则会为小于它的最大键分配一个对应的链表,并将数据添加到该链表中,并且链表中的数据也保持有序。
附图说明
18.图1为本发明的实现步骤的示意图;
19.图2为根据余弦相似度进行数据划分的示意图;
20.图3为利用链表存储新插入的数据的示意图;
具体实施方式
21.为了更具体地描述本发明,下面将结合说明书附图,对本发明的具体实施方式进行清楚、完整地描述。
22.如图1所示,本发明主要包括以下几个步骤:
23.步骤1、利用余弦相似度进行数据划分。
24.如图2所示,当数据个数小于等于2的时候,无法形成夹角,所以也不进行余弦值的计算。当数据个数大于2时,每添加一个新的数据点时,会跟它前面的两个点形成两条向量,根据这两条向量可以计算它们夹角的余弦值,并拿计算出来的余弦值和预先设定的阈值进行比较,若计算出的余弦值小于阈值,表示这两条向量接近正交,那添加的这个点就作为分段点。图1中由于点p5和点p11与其前两个点形成的向量夹角余弦值小于预先设定的阈值,
所以作为两个分段点,将图3中的13个点分为了三个子区域,即三个子数据集s1={p1,p2,p3,p4},s2={p5,p6,p7,p8,p9,p10},s3={p11,p12,p13}。
25.步骤2、在子数据集上利用梯度下降算法拟合线段模型。
26.假设拟合线段的公式为:
27.h(x)=s*x+i
ꢀꢀꢀ
(1)
28.公式(1)的损失函数为:
29.loss=∑(h(x)-y)
ꢀꢀꢀ
(2)
30.公式(2)中y为数据的实际位置,而h(x)为函数预测的位置。
31.梯度下降算法的具体过程:
32.(1)先求损失函数的偏导数
[0033][0034][0035]
(2)将子数据集中的数据点依次带入公式(1)和公式(2)中更新参数s和i
[0036][0037][0038]
通过子数据集中的数据点可以计算出该数据集的拟合线段的参数斜率s和截距i。之后当要查询数据的时候,只要将传进来的键值带入到公式中就可以计算出数据的位置。
[0039]
步骤3、递归调用数据划分和数据拟合算法构建上层结构。
[0040]
当底层模型全部训练完毕后,提取底层每个模型所覆盖的第一个数据,产生一个新的数据集,然后在该数据集上递归调用步骤1数据划分算法和步骤2中的梯度下降算法,训练上层模型,然后在每一层模型上递归此操作直至最后只产生一个模型,最后作为最上层。
[0041]
步骤4、利用链表存储新插入的数据解决数据插入的问题。
[0042]
图3展示了本发明的数据插入过程。
[0043]
在图3中,当有新数据24要插入时,首先根据模型计算出它应存放的位置,然后根据位置的状态进行不同的操作。在图2中根据模型计算出的位置不为空,所以找到小于它的最大键19,看该键是否有对应的链表,若有直接插入到所对应的链表中,并且链表中数据保持有序。若键19没有对应的链表,则分配一个与存储条大小一致的链表,并将数据24插入到其中。通过链表存储数据可以大幅度减少模型重新训练的概率,而保持链表有序可以方便后面当插入的新数据量达到阈值引起模型重训练时可以快速合并原始数据集和新插入的数据,形成一个新的有序数据集,提高重训练的速度。
[0044]
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1