一种基于多模态信息的跨外观行人重识别方法
1.本发明属于神经网络技术领域,特别涉及一种基于多模态信息的跨外观行人重识别方法。
背景技术:
2.行人重识别,也称为行人检索,其目标是解决跨时间、跨摄像头、跨场景的行人匹配问题。当给定一个感兴趣的行人目标之后,理想的行人重识别系统应该识别出不同时间、不同地点、不同设备中再次出现的该目标行人。现有的行人重识别任务主要集中于短时间内的同外观行人重识别,具备衣着、配饰等外观变化的长时间、跨外观行人重识别相关方法严重缺乏。事实上,跨外观行人重识别的应用极为普遍:长时间走失人员的对比识别、顾客的商业行为分析等。
3.目前监控环境中采集的跨外观行人重识别公开数据集主要包含nkup+和prcc,分别包含40217和33698张行人图像。而对于跨外观行人重识别研究,其中一部分工作专注于研究行人图像中不同部位之间的关联,如人脸、上衣、裤子等,通过调节不同部位局部特征与全局特征的特征融合形成鲁棒的跨外观特征,其典型方法比如ccan、2s-ide、3apf等。另一部分工作则尝试在网络中引入对外观变化鲁棒的轮廓、姿态等先验信息,其典型方法有spt、fsam等。如spt算法通过将行人的轮廓图以人体中心为原点,从笛卡尔坐标系采样并转换到极坐标系中以获取更加精细的轮廓特征,最后加之ase注意力机制就获得了较为完整鲁棒的行人身份特征。现有的行人重识别模型往往将注意力集中于衣着颜色、纹理等行人外观信息,模型的识别能力不够理想。
技术实现要素:
4.本发明针对现有技术中存在的技术问题,提供一种基于多模态信息的跨外观行人重识别方法,通过降低模型对传统特征的依赖性来提升跨外观行人的可辨识度,并在网络中引入了经预训练网络提取的行人边缘和部件语义先验信息,三种不同模态的信息使得模型综合学习了视觉图像中的细节信息和对外观鲁棒的高层语义信息,有效地缓解了网络过于关注行人外观信息的问题,提升了跨外观行人重识别模型的检索性能。
5.本发明采用的技术方案是:一种基于多模态信息的跨外观行人重识别方法,包括以下步骤:
6.步骤1:利用数据增强策略预处理跨外观行人重识别数据集;数据增强策略包含:缩放、随机水平翻转、填充、随机裁切、减均值除方差和随机擦除。
7.步骤2:使用经过公开数据集预训练的轮廓识别网络和语义分割网络分别从预处理过的图像中获取行人的轮廓图像与部件语义图像。
8.使用预训练的轮廓识别网络和语义分割网络分别从预处理过的行人的视觉图像中分别提取出轮廓图像和部件语义图像,三种不同模态的图像均使用rgb彩色图像进行表示。
9.步骤3:利用三个非共享权重的轮廓特征提取网络模型、视觉特征提取网络模型和语义特征提取网络模型分别对应从轮廓图像、视觉图像和部件语义图像提取出行人的高维轮廓特征矩阵、高维视觉特征矩阵和高维语义特征矩阵。表现为将数据输入特征提取网络模型,获取网络模型分类层之前输出的特征图。
10.步骤4:将高维轮廓特征矩阵、高维视觉特征矩阵、高维语义特征矩阵拼接为融合特征矩阵。使用拼接(concatenate)的方式对不同模态信息的特征进行融合,在没有添加诸如注意力机制等方法所需的额外参数以及训练时间的同时,即可融合不同模态特征在不同侧重方向的检索特点,综合提升模型的跨外观检索能力。
11.融合特征矩阵融合了多种对外观变化鲁棒的先验信息。对于长时间、跨外观的行人重识别问题而言,往往由于视觉图像中关于衣着、配饰等外观敏感的信息过多导致跨外观行人匹配失败。而行人的轮廓信息实际主要表现为行人的边缘信息,由于行人的体态一般不会发生剧烈变化,因此具有一定的鲁棒性。同时,人体部件语义信息可以获取细粒度的行人区域信息,以避免颜色、问题对提取跨外观行人特征的影响。本发明中综合考虑了图像中对行人外观变化鲁棒的轮廓和部件语义等先验知识,并改进了以往网络中仅使用单一视觉模态信息的问题,使得网络端到端地学习三种不同模态特征之间的关联性,提升跨外观的行人检索效果。
12.步骤5:对高维轮廓特征矩阵、高维视觉特征矩阵、高维语义特征矩阵和融合特征矩阵,分别进行池化下采样获取高维轮廓特征、高维视觉特征、高维语义特征和融合特征;使用广义均值池化对不同模态及其融合特征进行下采样操作,其融合了最大池化与平均池化的优点,使模型得以在不同模态图像中聚焦于显著特征,提升模型的检索效果。
13.步骤6:对高维轮廓特征、高维视觉特征、高维语义特征和融合特征,分别使用批次归一化和全连接层获取高维轮廓分类特征、高维视觉分类特征、高维语义分类特征和融合分类特征。
14.步骤7:分别计算高维轮廓特征、高维视觉特征、高维语义特征和融合特征的最难三元损失,再分别计算高维轮廓分类特征、高维视觉分类特征、高维语义分类特征和融合分类特征的身份分类损失,然后加权求和得到总损失。
15.其中,最难三元损失:
[0016][0017]
其中,α表示间隔参数,d表示距离度量,表示批次中第p个人的第k张图像的高维特征,1≤p≤p,1≤k≤k,p
′
为第p
′
个人的,k
′
为第k
′
张图像;
[0018]
身份分类损失:
[0019][0020]
其中xi、yi分别表示图像及其身份类别,p(yi|xi)表示图像xi被模型识别为身份类
别yi的概率,1≤i≤n。
[0021]
多模态网络模型端到端地计算视觉、轮廓、部件语义、融合特征各个分支的损失,其中每一个分支均计算最难三元损失和身份分类损失。分支损失:
[0022]
l=λ1l
hardtri
+λ2l
id
[0023]
其中,λ1和λ2分别表示最难三元损失和身份分类损失的权重参数;λ1和λ2均为 1.0。
[0024]
总损失为轮廓、视觉、部件语义和融合特征的四个分支损失的和。
[0025]
对行人的高维视觉、轮廓、部件语义特征和融合特征均计算行人身份分类损失和度量学习损失,从而强化损失函数对于不同分支特征的指导学习,使得每一种分支特征均具有一定的表征能力,并最终提升融合特征的鲁棒检索效果。
[0026]
步骤8:损失层梯度反向传播,更新三个不共享权重的轮廓特征提取网络模型、视觉特征提取网络模型和语义特征提取网络模型及其全连接层的权值参数。轮廓识别网络和语义分割网络不参与权重更新。
[0027]
步骤9:重复步骤2-8,直至轮廓特征提取网络模型、视觉特征提取网络模型和语义特征提取网络模型收敛,或者达到最大迭代次数,完成模型训练。
[0028]
步骤10:查询图像和图库图像输入完成训练的模型中,使用融合推理特征作为行人特征表示进行检索,融合推理特征由融合特征使用批次归一化获取。完成行人重识别的评测和可视化,并计算前1、5、10位命中率(rank1、rank5、rank10)和平均检索精度map,证明多模态信息对行人检索的促进作用。
[0029]
与现有技术相比,本发明所具有的有益效果是:本发明提出的融合多模态先验信息策略可以降低单一视觉rgb图像中外观敏感型信息在特征中的权重,融合的两种对外观变化相对鲁棒的模态信息则可以促进网络学习对于外观鲁棒的行人特征, 最终促进模型在跨外观场景下的行人检索性能。
附图说明
[0030]
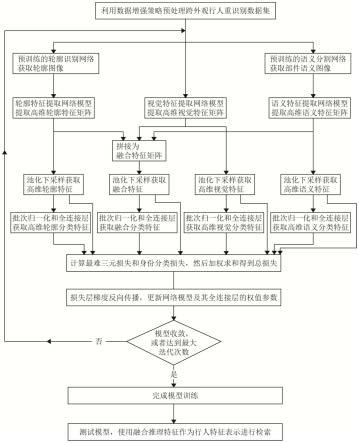
图1为本发明实施例的流程图;
[0031]
图2为本发明实施例的融合分支损失的网络结构图;
[0032]
图3为本发明实施例的测试时的流程图;
[0033]
图4为本发明实施例中使用的三种不同模态的图像的展示示意图;
[0034]
图5为本发明实施例的基准网络在nkup+上的部分行人前十位检索结果示意图;
[0035]
图6为本发明实施例的在nkup+上的部分行人前十位检索结果示意图。
具体实施方式
[0036]
为使本领域技术人员更好的理解本发明的技术方案,下面结合附图和具体实施例对本发明作详细说明。
[0037]
本发明的实施例提供了一种基于多模态信息的跨外观行人重识别方法,如图1 所示,其包括以下步骤:
[0038]
步骤1:预处理跨外观行人重识别数据集,对于训练集的图像需经数据增强策略处理、归一化之后作为网络的输入,其预处理顺序依次为:1)调整图像尺寸为网络输入尺寸
(256*128);2)以50%的概率随机对图像进行水平翻转;3)在图像周围填充10个值为0的像素;4)从图像中随机裁切出网络输入尺寸(256*128)的图像;
[0039]
5)对图像进行减均值除方差以归一化输入图像,其中使用imagenet中图像的均值 (0.485,0.456,0.406)和方差(0.229,0.224,0.225);6)以50%的概率随机抹去图像中2%至40%面积大小的区域。而在模型测试时,仅使用上述操作1)和操作5) 对模型集的图像进行处理。
[0040]
跨外观行人重识别数据集主要包含nkup+和prcc,分别包含40217和33698张行人图像。
[0041]
表1 nkup+数据集属性统计表
[0042][0043]
表2 prcc数据集属性统计表
[0044][0045]
步骤2:使用公开轮廓识别数据集(bsds500)和行人语义分割数据集(lip)训练的轮廓识别网络r(rcf net)和语义分割网络p(psp net)从行人的视觉图像x
rgb
中分别提取出轮廓图像xc和部件语义图像x
p
,三种不同模态的图像均使用rgb彩色图像进行表示,因此具有相同的维度,不同模态的示例图像如图4所示。
[0046]
xc=r(x
rgb
),x
p
=p(x
rgb
)
[0047]
步骤3:使用在公开数据集(imagenet)训练的三个非共享权重的特征提取densenet121网络模型:轮廓特征提取网络模型nc、视觉特征提取网络模型n
rgb
和语义特征提取网络模型n
p
分别从轮廓图像、视觉图像和部件语义图像提取行人视觉、轮廓和部件语义三种不同模态信息的高维特征矩阵:高维轮廓特征矩阵高维视觉特征矩阵和高维语义特征矩阵
[0048][0049]
步骤4:将行人视觉、轮廓和部件语义三种不同模态信息的高维特征矩阵拼接 (concatenate)为融合特征矩阵
[0050][0051]
步骤5:基于广义均值池化(generalized mean pooling,gem pooling)将高维轮廓特征矩阵高维视觉特征矩阵高维语义特征矩阵和融合特征矩阵下采样为相应的高维特征:高维轮廓特征高维视觉特征高维语义特征和融合特征
[0052][0053][0054]
步骤6:对行人的高维轮廓特征高维视觉特征高维语义特征和融合特征分别首先采用批次归一化(batch normalization,bn)获取推理特征:
[0055]
高维轮廓推理特征高维视觉推理特征高维语义推理特征和融合推理特征然后使用全连接层(fully connected layer,fc)获取身份分类特征:高维轮廓分类特征高维视觉分类特征高维语义分类特征和融合分类特征
[0056][0057][0058]
步骤7:计算视觉、轮廓、部件语义、融合特征各自的整体分支损失l
rgb
、lc、 l
p
、lf,然后对不同分支损失求和得到最终的总损失l
all
。
[0059][0060][0061][0062][0063]
l
all
=l
rgb
+lc+l
p
+lf[0064]
其中,λ1和λ2分别表示最难三元损失和身份分类损失的权重参数;λ1和λ2均为 1.0。
[0065]
最难三元损失:
[0066][0067]
其中,α表示间隔参数,d表示距离度量,表示批次中第p个人的第k张图像的高维特征,1≤p≤p,1≤k≤k,p
′
为第p
′
个人的,k
′
为第k
′
张图像;
[0068]
身份分类损失:
[0069][0070]
其中xi、yi分别表示图像及其身份类别,p(yi|xi)表示图像xi被模型识别为身份类别yi的概率,1≤i≤n。
[0071]
融合分支损失的网络结构如图2所示。视觉、轮廓、部件语义的分支损失的网络结构与之相似。
[0072]
步骤8:损失层的梯度反向传播,更新轮廓特征提取网络模型nc、视觉特征提取网络模型n
rgb
和语义特征提取网络模型n
p
,及其对应的全连接层的权值参数。
[0073]
步骤9:多模态模型在行人重识别数据集上优化训练120轮,网络初始学习率为 3.5
×
10-6
,在前10轮epoch网络学习率会从线性上升至3.5
×
10-4
,随后,学习率将在31、61、91轮分别衰减为当前值的0.1倍以微调网络权重。完成模型训练,得到训练好的多模态模型。
[0074]
步骤10:而对于网络的测试流程,如图3所示。将测试集中的所有查询图像和图库图像输入到多模态模型进行前向传播,并使用融合特征的归一化推理特征作为最终的行人特征向量表示。假定查询图像的特征表示为fq,候选图像的特征表示为 fg,使用欧式距离计算二者之间的距离d
q,g
=||f
q-fg||2,若其距离越小,则图像对之间的相似度越高,反之越低。计算每一张查询图像与所有的候选图像之间的距离并按照相似度从大到小进行排序,获得排序列表,最终计算前k位命中率rank-k和平均检索精度map。分别在nkup+和prcc数据集上做对比试验,证明多模态融合特征的鲁棒性。
[0075]
图5和图6展示了基准网络模型densenet121和多模态模型m2net在nkup+跨外观子集的部分行人重识别结果,每一行中展示了一个待检索行人的前十位检索结果。其中最左侧的为检索图像,查询图像按照相似度从高到低进行排列,黑色和灰色边界框分别表示正确与错误的检索结果。从图示可以看出,基准网络模型(densenet121) 的检索结果中行人的衣着、背包等外观信息极大程度影响了检索结果,而采用了多模态模型m2net之后,部分行人外观变化明显的图像也被检索出来,印证了多模态信息可以提升跨外观行人重识别模型性能。
[0076]
表3和表4中量化的列出了实验rank-k和map指标,该指标是行人重识别领域的两个重要评价标准。在图像数量相对较少、外观变化不大的prcc数据集中,多模态模型m2net提取特征分别提升了同/跨外观子集的0.7%/7.5%的rank1值和 1.7%/6.1%的map精度;而在图像数量较多、外观变化明显的nkup+数据集中,多模态网络m2net则在保持同外观检索能力基本不变的情况下,提升了跨外观子集上1.6%的rank1值和0.7%的map,证明了多模态特征对于跨外观行人的检索能力。
[0077]
表3各特征提取网络在prcc数据集检索指标对比表
[0078][0079]
表4各特征特征提取网络在nkup+数据集检索指标对比表
[0080][0081]
以上通过实施例对本发明进行了详细说明,但所述内容仅为本发明的示例性实施例,不能被认为用于限定本发明的实施范围。本发明的保护范围由权利要求书限定。凡利用本发明所述的技术方案,或本领域的技术人员在本发明技术方案的启发下,在本发明的实质和保护范围内,设计出类似的技术方案而达到上述技术效果的,或者对申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1