基于伪孪生网络的虚假新闻检测方法
1.本发明属于虚假新闻检测技术领域,具体涉及一种基于伪孪生网络的虚假新闻检测方法。
背景技术:
2.社交媒体的发展使得人们获取信息越来越方便,社交平台鼓励用户积极地参与讨论新闻事件和社会热点话题,为用户提供了分享、评论、点赞等丰富的社交功能,这带来了巨大的潜在政治利益和经济利益,但是也促使了虚假新闻的传播。在一定程度上,虚假新闻往往比真实新闻在社交网络上传播得更快、更远、更广泛。
3.为了减缓虚假新闻对社会造成的负面影响,一些早期的研究者利用机器学习技术实现了虚假新闻的自动检测,他们将人工设计好的新闻特征作为机器学习模型的输入,以此来检测虚假新闻,但这样的方法往往具有一定的局限性:根据某一领域新闻设计的特征可能无法迁移到其他领域新闻,因为不同领域新闻的写作风格、内容、词汇等分布往往是不同的。新闻内容是动态变化的,一些早期人工设计的特征可能并不适用于之后出现的新闻,且虚假新闻制造者极容易利用人工设计的特征来逃避模型的检测。
4.由于深度神经网络在捕获数据复杂特征方面具有明显优势,现在很多研究者都使用深度学习技术对虚假新闻进行检测。然而,大多数深度学习方法。尽管在特定领域的数据集上有良好的效果,但是并不能在跨领域数据中有效识别出虚假新闻,原因如下:1)供研究者使用的数据集新闻领域过于单一,如fakenewsnet数据集仅包含政治和娱乐新闻,而现实中的新闻包含多个领域;2)特定领域新闻的语言风格与传播模式存在明显差异,现有的模型并不能适应这种差异。因此,如何利用现有领域的新闻数据检测其他跨领域新闻是一个重要而具有挑战性的问题。
5.有鉴于此,有必要提供一种新的虚假新闻检测方法。
技术实现要素:
6.本发明的目的在于克服现有技术中存在的至少一个上述问题,提供一种基于伪孪生网络的虚假新闻检测方法,利用不同模态数据的匹配程度来检测虚假新闻,克服了以往的方法只能检测特定领域虚假新闻的弊端,使得多模态虚假新闻检测模型的领域适用性更强。
7.为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
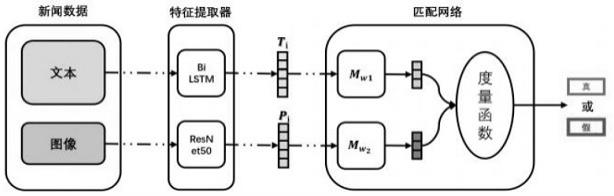
8.本发明提供一种基于伪孪生网络的虚假新闻检测方法,该方法的模型主要包括特征提取器和匹配网络,该方法具体步骤如下:
9.1)对于输入的新闻数据,分别将文本数据和图像数据输入对应的特征提取器,获取文本和图像两个层次的特征;
10.2)将学习到的文本和图像特征作为匹配网络的输入,匹配网络把它们映射到一个新的目标空间中,使用一个匹配度量函数进一步衡量两个特征在语义上的匹配程度;
11.3)根据匹配网络的输出,进而预测新闻内容的真实性。
12.进一步地,如上所述的虚假新闻检测方法,将同一篇新闻中两种模态的数据作为匹配网络的两个输入,对于第i条新闻数据xi,其文本特征和图像特征分别用ti和pi来表示;用x={x1,x2,x3...xn}代表一个新闻集合,其中n是新闻的数量,每一条新闻数据xi由文本内容ti和图像内容pi构成,yi表示xi对应的新闻真实性标签,匹配网络根据新闻数据xi的文本内容ti和图像内容pi分析出xi是真实新闻(yi=0)或是虚假新闻(yi=1)的概率。
13.进一步地,如上所述的虚假新闻检测方法,特征提取器中的文本特征表示:每条新闻数据的文本内容ti是由m个词语构成的: t1={w1,w2,w3...wm},每个词语wi∈w使用词嵌入向量表示,每个词嵌入向量是由一个在大型语料库数据集上进行无监督预训练的深度神经网络获得,使用glove获取词语的词嵌入表示;
14.由于双向长短时记忆网(bi-directional long short-termmemory,bilstm) 在获取文本特征方面有着极其出色的表现,所以使用bilstm来获取文本特征表示;bilstm在是lstm的基础上结合了输入序列在前向和后向两个方上的信息;对于t时刻的输出,前向lstm层具有输入序列中t时刻以及之前时刻的信息,而后向lstm层中具有输入序列中t时刻以及之后时刻的信息;在第t时间bilstm执行的操作表达式如下:
15.i
t
=σ(wi·
x
t
+ui·ht-1
)
16.f
t
=σ(wf·
x
t
+uf·ht-1
)
17.o
t
=σ(wo·
x
t
+uo·ht-1
)
[0018][0019][0020][0021]
其中,wi,wf,wo,wc,ui,uf,uo,uc是权重矩阵;x
t
,h
t
是在t时间的输入状态和隐状态;σ是sigmoid函数,表示按元素乘积;
[0022]
最终的文本特征向量t,表示为t时刻隐状态的平均值:
[0023][0024]
其中,m是微博文本的长度。
[0025]
进一步地,如上所述的虚假新闻检测方法,m=75。
[0026]
进一步地,如上所述的虚假新闻检测方法,特征提取器中的图像特征表示:研究表明,虚假新闻的图像与真实新闻的图像在语义层面上具有不同的特征,这表明新闻的图像特征在虚假新闻的检测中发挥着重要作用,一方面,新闻的图像特征本身会带有一些跟新闻真实性相关的信息,例如,虚假新闻的图像往往更具有视觉冲击力;另一方面,在匹配网络中利用文本特征与图像特征的语义匹配程度进一步衡量了新闻的真实性,因此,在fnps模型的多模态特征提取器中使用一个预训练的 resnet50来获取图像的特征;将预训练模型全连接层的最后一层替换,然后将输入图像pi的大小调整为448
×
448并划分为14
×
14个区域;对于每一个区域ij=(j=1,2,...,196),都通过resnet50模型来获取区域的特征向量vj=resnet(ij);
[0027]
将区域的特征向量进行平均得到图像的特征向量p:
[0028][0029]
其中,nr代表区域的数量。
[0030]
进一步地,如上所述的虚假新闻检测方法,匹配网络的目标是从数据中学习两个映射函数和这两个映射函数能够将输入的特征映射到一个新的目标空间,使目标空间中特征之间的欧氏距离与原空间中特征之间的“语义距离”相近,将其表示为:
[0031][0032]
这个映射函数可以用来映射以前未见过的新样本(例如,训练期间未见过的领域新闻);如果在目标空间中特征之间的欧式距离小于设定的阈值ε,说明xi的文本内容与图像内容在语义上是高度匹配的,即说明xi的真实性较高,反之亦然;上述过程用公式表示为:
[0033][0034]
其中,ε为超参数;
[0035]
在模型训练过程中,通过最小化对比损失(contrastive loss)来优化匹配网络,对比损失可以有效处理孪生网络中成对的数据关系,它的表达式如下:
[0036][0037]
其中,n表示数据量,yi为新闻的标签;di指代s(ti,pi)。
[0038]
进一步地,如上所述的虚假新闻检测方法,设定的阈值ε=0.65。
[0039]
进一步地,如上所述的虚假新闻检测方法,观察上述损失函数表达式可知,若yi=0,di越大,则损失越大,即原本是真实新闻的样本,其映射后的文本特征与图像特征在特征空间中的欧氏距离较大,说明模型效果不好;同理,若yi=1,di越大,则损失越小,说明模型效果越好。
[0040]
本发明的有益效果是:
[0041]
本发明专注于由文本及图像组成的虚假新闻内容,受计算机视觉领域任务的启发,将虚假新闻的检测视为多模态语义匹配问题。在现实世界中,绝大部分虚假新闻的文本及其所附图像内容的语义并不匹配,基于此,提出了基于伪孪生网络的虚假新闻检测方法——fnps,具体地说,首先将虚假新闻的多模态数据从原始空间映射到新的目标空间,其次在目标空间进一步衡量了文本与图像的语义匹配程度,从而整体提高了模型在检测跨领域虚假新闻的效果。实验结果表明,所提出的模型fnps优于其他的多模态虚假新闻检测模型。
[0042]
当然,实施本发明的任一产品并不一定需要同时达到以上的所有优点。
附图说明
[0043]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0044]
图1为本发明检测方法的模型框架示意图;
[0045]
图2为ε对模型性能的影响示意图;
[0046]
图3为词嵌入维度对模型性能的影响示意图;
[0047]
图4为匹配维度对模型性能的影响示意图。
具体实施方式
[0048]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0049]
本发明受到了孪生网络思想的启发,在监督学习范式下,孪生网络会最大化不同样本的特征差距,并最小化相同样本的特征差距。在自监督或无监督学习范式下,孪生网络可以最小化原输入和干扰输入 (例如原始图像和加入噪声的图像)间的特征差距。孪生网络可以进行小样本学习(few-shot learning)或单样本学习(one-shot learning),且不容易被错误样本干扰,因此可用于对容错率要求严格的模式识别问题,例如人脸识别、指纹识别、目标追踪等。
[0050]
狭义的孪生网络由两个结构相同,且权值共享的子网络构成,每个子网络各自接收一个输入,将其映射至目标特征空间。网络的最顶层由一个度量函数构成,它负责计算两个输入特征的距离,例如欧式距离,余弦距离,从而比较两个输入的相似程度。孪生网络的权值共享保证了两个极其相似的输入不会被各自的网络映射到特征空间的不同位置。在本发明中,发明人使用广义的孪生网络,其特点是子网络的结构不同且权值不共享,许多研究者称之为伪孪生网络。
[0051]
本发明提供一种基于伪孪生网络的虚假新闻检测方法,如图1所示,该方法的模型主要包括特征提取器和匹配网络,该方法具体步骤如下:
[0052]
1)对于输入的新闻数据,分别将文本数据和图像数据输入对应的特征提取器,获取文本和图像两个层次的特征;
[0053]
2)将学习到的文本和图像特征作为匹配网络的输入,匹配网络把它们映射到一个新的目标空间中,使用一个匹配度量函数进一步衡量两个特征在语义上的匹配程度;
[0054]
3)根据匹配网络的输出,进而预测新闻内容的真实性。
[0055]
本发明中,将同一篇新闻中两种模态的数据作为匹配网络的两个输入,对于第i条新闻数据xi,其文本特征和图像特征分别用ti和pi来表示;用x={x1,x2,x3...xn}代表一个新闻集合,其中n是新闻的数量,每一条新闻数据xi由文本内容ti和图像内容pi构成,yi表示xi对应的新闻真实性标签,匹配网络根据新闻数据xi的文本内容ti和图像内容pi分析出xi是真实新闻(yi=0)或是虚假新闻(yi=1)的概率。
[0056]
本发明中,特征提取器中的文本特征表示:每条新闻数据的文本内容ti是由m个词语构成的:t1={w1,w2,w3...wm},每个词语wi∈w使用词嵌入向量表示,每个词嵌入向量是由一个在大型语料库数据集上进行无监督预训练的深度神经网络获得,使用glove获取词语的词嵌入表示;
[0057]
由于双向长短时记忆网(bi-directional long short-termmemory,bilstm) 在获取文本特征方面有着极其出色的表现,所以使用bilstm来获取文本特征表示;bilstm在是lstm的基础上结合了输入序列在前向和后向两个方上的信息;对于t时刻的输出,前向lstm层具有输入序列中t时刻以及之前时刻的信息,而后向lstm层中具有输入序列中t时刻以及之后时刻的信息;在第t时间bilstm执行的操作表达式如下:
[0058]it
=σ(wi·
x
t
+ui·ht-1
)
[0059]ft
=σ(wf·
x
t
+uf·ht-1
)
[0060]ot
=σ(wo·
x
t
+uo·ht-1
)
[0061][0062][0063][0064]
其中,wi,wf,wo,wc,ui,uf,uo,uc是权重矩阵;x
t
,h
t
是在t时间的输入状态和隐状态;σ是sigmoid函数,表示按元素乘积;
[0065]
最终的文本特征向量t,表示为t时刻隐状态的平均值:
[0066][0067]
其中,m是微博文本的长度,m=75。
[0068]
本发明中,特征提取器中的图像特征表示:研究表明,虚假新闻的图像与真实新闻的图像在语义层面上具有不同的特征,这表明新闻的图像特征在虚假新闻的检测中发挥着重要作用,一方面,新闻的图像特征本身会带有一些跟新闻真实性相关的信息,例如,虚假新闻的图像往往更具有视觉冲击力;另一方面,在匹配网络中利用文本特征与图像特征的语义匹配程度进一步衡量了新闻的真实性,因此,在fnps模型的多模态特征提取器中使用一个预训练的resnet50来获取图像的特征;将预训练模型全连接层的最后一层替换,然后将输入图像pi的大小调整为 448
×
448并划分为14
×
14个区域;对于每一个区域ij=(j=1,2,...,196),都通过resnet50模型来获取区域的特征向量vj=resnet(ij);
[0069]
将区域的特征向量进行平均得到图像的特征向量p:
[0070][0071]
其中,nr代表区域的数量。
[0072]
进一步地,如上所述的虚假新闻检测方法,匹配网络的目标是从数据中学习两个映射函数和这两个映射函数能够将输入的特征映射到一个新的目标空间,使目标空间中特征之间的欧氏距离与原空间中特征之间的“语义距离”相近,将其表示
为:
[0073][0074]
这个映射函数可以用来映射以前未见过的新样本(例如,训练期间未见过的领域新闻);如果在目标空间中特征之间的距离小于设定的阈值ε,说明xi的文本内容与图像内容在语义上是高度匹配的,即说明xi的真实性较高,反之亦然;上述过程用公式表示为:
[0075][0076]
其中,ε为超参数,ε=0.65;
[0077]
在模型训练过程中,通过最小化对比损失(contrastive loss)来优化匹配网络,对比损失可以有效处理孪生网络中成对的数据关系,它的表达式如下:
[0078][0079]
其中,n表示数据量,yi为新闻的标签。观察上述损失函数表达式可知,若yi=0,di越大,则损失越大,即原本是真实新闻的样本,其映射后的文本特征与图像特征在特征空间中的欧氏距离较大,说明模型效果不好;同理,若yi=1,di越大,则损失越小,说明模型效果越好。
[0080]
本发明通过引入孪生网络架构来检测跨领域新闻。最早的孪生网络被用于美国支票上的签名验证,即验证支票上的签名与银行预留签名是否一致。随着深度学习的发展,孪生网络被用在越来越多的计算机视觉任务上,例如,人脸验证,关键点描述学习,此外,它还被用于单样本字符识别以及一些图像检索任务。然而,到目前为止,孪生网络还未被应用于虚假新闻检测任务。
[0081]
本发明的具体实施例如下
[0082]
一、数据集和预处理
[0083]
考虑到基于多媒体内容的虚假新闻检测研究并不多,目前仅有几个标准的多模态虚假新闻数据集可用。两个使用最广泛的数据集是文献[boididou c,papadopoulos s,dang-nguyen d, etal.verifying multimedia use at mediaeval 2016[c]//mediaeval2016workshop.2016]提出的twitter数据集和文献[]jin z,cao j, guo h,et al.multimodal fusion with recurrent neural networks forrumor detection on microblogs[c]//proceedings of the 25th acminternational conference on multimedia.2017:795-816]中建立的微博数据集。然而,在twitter数据集中有很多重复的图片,导致有特色的图片数量少于500张,这使得twitter数据集太小,无法支持所提出的模型的训练。因此,在本实施例中,发明人仅对微博数据集进行了实施例,以评估所提出的模型的有效性。接下来,发明人将提供所使用的数据集的详细信息。
[0084]
1)weiboa:该数据集来自datafountain网站(datafountain.cn) ,是由北京市经济和信息化局、中国计算机学会大数据专家委员提供的多模态数据集,每条数据均从微博平台(weibo.com)采集,包括微博正文、评论、图像、所属领域等多个字段,标签由人工进行标注,分为三种类别,分别是无需判断,虚假新闻和真实新闻,本实施例仅使用其中的虚假
新闻和真实新闻数据,为了更准确的训练和评估模型,发明人手动检查了训练集和测试集,以确保标签的准确性。由于微博口语化严重,发明人对数据进行了清洗,仅保留了微博正文中的汉字部分,去除了表情、符号、等无实际意义的内容。为了确保数据集的质量,发明人还去除了重复和低质量的图像,为了确保每条微博都有图像与之对应,纯文本的微博被删除,对于有多张图像的微博只保留一张图像。处理之后的数据共计17848条。领域分为八个:财经、社会、娱乐、健康、科技、政治、军事、教育,其中后四个领域由于数据量较少,所以发明人将其划分为测试集a,共计1431条,前四个领域的数据划分为训练集(90%)和验证集(10%) ,共计16417条。
[0085]
weibob:该数据集首次出现在文献[jin z,cao j,guo h,et al. multimodal fusion with recurrent neural networks for rumordetection on microblogs[c]//proceedings of the 25th acminternational conference on multimedia.2017:795-81]中用于虚假新闻检测任务。其中,真实新闻来自中国权威新闻来源,如新华社。虚假新闻是从2012年5月到2016年1月抓取的,并由微博的官方辟谣系统进行验证。该系统鼓励普通用户举报可疑的帖子,并由受信任的用户组成的委员会对可疑的帖子进行审查。根据以前的工作,这个系统也作为收集谣言新闻的权威来源。每条数据的内容都是由博文及一张配图构成,发明人使用与weiboa数据集相同的方法对该数据集进行预处理。处理后的数据共计5361条,其中虚假新闻4311条,真实新闻1050条,因为数据没有进行领域标注,所以发明人将其作为测试集b。
[0086]
数据集的详细信息如下表1所示:
[0087]
表1数据集统计
[0088][0089]
二、实施例参数设置
[0090]
对于词嵌入,首先使用jieba分词器将中文文本分割为词语,然后使用预训练的glove模型对词语进行嵌入表示,嵌入维度为 32。预训练的bilstm模型与resnet50模型可在线获得。文本特征提取器和图像特征提取器的输出维度都是128。被匹配网络映射至目标空间的匹配维度为32,设置为0.65。在整个训练过程中,数据的批大小设置为64,学习率为0.001,模型使用relu作为激活函数,为了寻求模型的最佳参数,发明人使用adam优化器来优化损失函数。其他具体参数在表2中列出:
[0091]
表2
[0092]
超参数值ε0.65
批大小64学习率0.001词嵌入维度32匹配网络匹配维度32resnet50全连接层大小128lstm隐藏层大小128激活函数relu优化器adam
[0093]
本文使用虚假新闻检测任务中常用的精度(precision)、召回率(recall)、准确率(accurac)、以及f1值(f1-score)作为主要评估指标。
[0094]
三、基线模型
[0095]
为了验证本发明所提出方法的有效性,发明人选取了五种有代表性的方法进行性能比较。其中包括两种单模态模型和三种多模态模型。
[0096]
1)单模态模型
[0097]
txt:bilstm是解决许多文本分类问题的最流行方法之一。txt利用bilstm网络来学习文本特征,然后使用带有softmax层的全连接网络来进行预测。
[0098]
img:视觉特征是由resnet50获得的。经过池化层的处理,视觉特征被送入全连接网络进行最终预测,发明人只更新全连接网络的参数。
[0099]
2)多模态模型
[0100]
txtimg:发明人将文本特征和图像特征串联起来作为全连接网络的输入,并预测结果。
[0101]
eann:事件对抗神经网络(eann)是一个多模态的虚假新闻检测模型,它的文本和视觉特征是利用基于cnn的文本特征提取器(textcnn)和vgg19网络分别获得。另外,在模型中还添加了一个额外的事件分类器来学习与新闻事件无关的共享特征。为了适应发明人的任务,发明人将其改写成学习与新闻领域无关的共享特征。
[0102]
mvae:最先进的方法之一,多模态变分自动编码器(mvae),是一个多模态融合的虚假新闻检测框架。该模型通过利用变分自动编码器从共享的潜在特征中重构文本和视觉特征特征来发现跨模态的相关性。mvae由编码器、解码器和分类器组成。
[0103]
四、实施例结果与分析
[0104]
发明人使用数据集weiboa的前4领域(财经、社会、娱乐、健康)进行模型的训练,并在weiboa的后4领域(科技、政治、军事、教育)以及weibob(领域未知)进行模型的测试。为避免实施例的偶然性,发明人将每组实施例重复5次并取平均结果。详细的实施例结果在表3中列出:
[0105]
表3
[0106][0107]
可以观察到,仅基于文本模态的模型效果并不如仅基于图像模态的模型。直观上,虚假新闻的领域信息主要集中在文本内容中,例如,在财经领域的新闻文本中存在大量经济学专业词汇,这就导致仅使用文本内容检测虚假新闻不能保证模型拥有良好的领域适用性。相反,图像中涉及的领域信息并不明显,例如,在娱乐领域、政治领域及社会领域的新闻图像中都可能包含人物。实施例数据恰好也证明了这一点:在单模态模型中, img优于txt,这说明图像特征对于检测跨领域虚假新闻有很大帮助。
[0108]
所有多模态模型都优于单模态模型,这证实了在检测虚假新闻任务中使用多模态信息的有效性。与其他多模态方法相比,所提出的模型fnps在大多数评估指标方面都取得了最佳结果,以f1值为衡量指标,在数据集weiboa上超出其他方法3个百分点以上,在数据集weibob上超出其他方法6个百分点以上。这一结果表明,在检测与训练数据领域差异性较大的跨领域新闻时,利用新闻不同模态数据间的语义匹配程度是非常有效的策略。 eann与mvae则是直接将多模态数据的特征作为分类器的输入,尽管在特征层次考虑到了模态之间的协同作用,然而却忽略了不同模态数据在语义层次的匹配作用。因此,eann与 mvae的分类准确率明显低于发明人的模型fnps。
[0109]
五、参数灵敏度实施例
[0110]
实施例过程中部分重要超参数对模型性能的影响在图2至图4中进行展示,所有实施例均在数据集weiboa上进行。
[0111]
如图2所示,ε是一个阈值,在匹配网络中使用,若文本特征与图像特征在目标空间中的欧氏距离大于,则说明两种模态数据的语义在一定程度上是不匹配的,即输入数据很有可能是虚假新闻。如图4所示,经多次实验,发明人将设置为0.65,此时fnps能达到最好效果。
[0112]
如图3所示,不少研究者对于词嵌入维度的选择似乎都颇为随意,然而,大量的研究表明,如果词嵌入维度选择得过小或过大都无法保证模型的最优性。如图2所示,在本发明中发明人通过实施例得出,词嵌入维度设置为32时模型表现最优。
[0113]
如图4所示,匹配网络的匹配维度也是一个影响模型性能的关键超参数,若匹配维度设置得过小,模型只能在有限的维度度量不同模态数据间的语义匹配程度;相反,若匹配维度设置得过大,特征中将包含更多无用的噪音,反而会抑制模型效果。经多次试验,发明人将匹配维度设置为32时,模型的表现更好。
[0114]
本发明研究了多模态虚假新闻检测问题,提出了一个基于伪孪生网络的虚假新闻
检测模型fnps。它利用新闻内容的主要成分(文本和图像)的语义匹配程度来衡量新闻的真实性。在真实数据集上的实施例结果表明,发明人所提出的模型fnps优于现有的多模态假新闻检测模型。由于fnps是一种多模态虚假新闻检测任务的通用方法,因此它可以很容易地扩展到更多模态模型。
[0115]
以上公开的本发明优选实施例只是利于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1