一种统一时空融合的环视鸟瞰图感知方法
1.本发明属于图像处理领域,具体涉及一种统一时空融合的环视鸟瞰图感知方法。
背景技术:
2.近些年来,基于鸟瞰图(bird’s-eye-view,bev)的自动驾驶环视感知系统逐渐成为主流的感知范式。基于鸟瞰图的感知表达其核心意涵为将采集到的环视图像映射到基于当前自身车辆位置的鸟瞰图bev空间中。这种空间融合方式能够组成一个统一的鸟瞰图bev空间,并且能够极大地减少环视多摄像头融合时的难度。除此之外,这种鸟瞰图bev空间融合天然地与其他感知模态,如激光雷达等,具有一致的3d空间位置,从而简便了视觉系统与激光雷达系统的融合。因此,基于鸟瞰图的自动驾驶环视感知系统具有统一的,便于其他模态处理的表达能力。然而,面对自动驾驶过程中长时间、长时序下的环视图像,如何实现环视鸟瞰图感知,是目前亟待解决的技术问题之一。
技术实现要素:
3.本发明的目的在于解决现有技术中自动驾驶过程中长时间、长时序下的环视图像难以高效融合进而导致感知效果不佳的问题,并提供一种统一时空融合的环视鸟瞰图感知方法。
4.为实现上述目的,本发明所采用的具体技术方案如下:
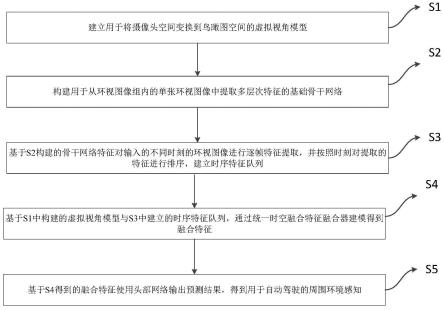
5.一种统一时空融合的环视鸟瞰图感知方法,其包括以下步骤:
6.s1、建立用于将摄像头空间变换到bev空间的虚拟视角模型;
7.s2、构建用于从环视图像组内的单张环视图像中提取多层次特征的基础骨干网络;
8.s3、基于s2构建的骨干网络特征对输入的不同时刻的环视图像进行逐帧特征提取,并按照时刻对提取的特征进行排序,建立时序特征队列;
9.s4、基于s1中构建的虚拟视角模型与s3中建立的时序特征队列,通过统一时空融合特征融合器建模得到融合特征;
10.s5、基于s4得到的融合特征使用头部网络输出预测结果,得到用于自动驾驶的周围环境感知。
11.作为优选,所述基础骨干网络、统一时空融合特征融合器和头部网络组成的环视鸟瞰图感知网络框架,预先经过用于环视鸟瞰图感知的图像数据集进行训练,图像数据集中的环视图像样本由多方向摄像头采集的环视图像、各摄像头对应的相机内外参信息和各图像对应的标注信息组成。
12.作为优选,所述用于环视鸟瞰图感知的图像数据集包括图像组作为优选,所述用于环视鸟瞰图感知的图像数据集包括图像组其中ii为第i组环视图像,每组环视图像包含n张分别由不同方向摄像头拍摄的图像,n为车辆上朝向不同方向的摄像头总数;infoi为第i组环视图像所对应的相机内外参信息,包含旋转矩阵和平移矩阵;ti为第i组环视图像整组对应的真实3d世界标注信
息,包括以该组环视图像为中心的地图信息,和/或以该组环视图像为中心的周围世界3d车辆的标注信息;m为图像数据集中的环视图像组数。
13.作为优选,步骤s1中,建立虚拟视角模型的方法如下:
14.s11、对于每组环视图像ii所对应的相机内外参信息infoi,定义其包含的旋转矩阵为平移矩阵为对于旋转矩阵r,定义rc为当前时刻的旋转矩阵,r
p
为过去时刻的旋转矩阵,r
i,j
为第i组环视图像中第j张图像对应的摄像头采用的旋转矩阵,i∈{1,
…
,m},j∈{1,
…
,n};对于平移矩阵t,定义tc为当前时刻的平移矩阵,t
p
为过去时刻的平移矩阵,t
i,j
为第i组环视图像中第j张图像对应的摄像头采用的平移矩阵;
15.s12、定义如下虚拟视角模型变换:
[0016][0017][0018]
其中为第i组环视图像中第j张图像对应的摄像头的虚拟旋转矩阵,为第i组环视图像中第j张图像对应的摄像头的虚拟平移矩阵;
[0019]
s13、对于s12中得到的虚拟视角模型变换,按照如下公式建立用于将摄像头空间变换到bev空间的虚拟视角模型:
[0020][0021]
其中p
bev
为bev空间中的坐标点,p
img
为图像空间中的坐标点,k
i,j
为第i组环视图像中第j张图像对应的摄像头的相机内参。
[0022]
作为优选,所述步骤s2中,构建的基础骨干网络如下:
[0023]
选择resnet、swin-tiny、vovnet中的一种作为骨干网络,对于所有输入的环视图像均使用同一个选定的骨干网络进行特征提取,使不同摄像头拍摄的图像之间共享骨干网络;对于层次数目为l的骨干网络,在提取多层次特征时,需对骨干网络每一个层(stage)提取的特征均进行保留,最终得到l个层次的多层次特征。
[0024]
作为优选,所述步骤s3中,建立时序特征队列方法如下:
[0025]
将不同时刻的环视图像组输入所述骨干网络中,由骨干网络逐帧提取单帧多层次特征,并按照图像采集的时间顺序将多层次特征保存在时序特征队列中。
[0026]
作为优选,所述步骤s4中,得到融合特征的方法如下:
[0027]
s41、基于s3中得到的时序特征队列,获取最新的长度为p个时刻的时序特征组;
[0028]
s42、建立bev空间表达,以表达整个bev空间;其中,q
x,y
为bev的查询(query),表示在bev空间位置(x,y)处的特征信息;c为特征维度,x和y为bev空间的长和宽;对于每个bev空间位置(x,y),在高度z上从-3m到5m进行均匀采样获取z个高度点,从而得到一组对应bev空间位置(x,y)的3d坐标{(x,y,z)|z∈[-3,5]};对于每个bev空间位置(x,y),进一步通过s23中建立的虚拟视角模型对采样得到的3d坐标{(x,y,z)|z∈[-3,5进行变换,将bev空间下的3d坐标{(x,y,z)|z∈[-3,5转换至摄像头空间,得到其在图像空间中的位置p
img
,从而建立了bev空间中位置点与图像空间中位置点的映射关系;根据所述映射关系,将时序特征组中图像空间下的多层次特征映射至bev空间中;
[0029]
s43、建立统一时空融合特征融合器,其包含由浅到深级联的自注意力层、第一归一化层、互注意力层、第二归一化层、前馈网络层和第三归一化层;其中自注意力层使用可变形注意力方法,所述第一归一化层、第二归一化层和第三归一化层均使用层归一化方法(layernorm),所述前馈网络由一个全连接网络组成,所述互注意力层则由以下公式定义:
[0030][0031][0032]
其中为所述时序特征组中第p个时刻第l个层次的特征被虚拟视角模型映射至bev空间后在bev空间位置(x,y,z)处所对应的特征;为叠加位置编码(positional embedding,pe)后的结果;为互注意力权重,其计算式中的q
x,y
是原始bev空间表达中的q
x,y
经过了自注意力层和第一归一化层后的输出结果;
[0033]
s44、将s41中的时序特征组输入s43中建立的统一时空融合特征融合器中,获得统一时空融合特征融合器的输出特征。
[0034]
作为优选,所述步骤s5中,过程如下:
[0035]
s51、使用erfnet作为头部网络,对s44中得到的输出特征,经过erfnet头部网络后得到自动驾驶环视地图感知输出;
[0036]
s52、使用centerpoint作为头部网络,对s44中得到的输出特征,经过centerpoint头部网络后得到自动驾驶3d目标检测感知输出。
[0037]
s53、整合s51与s52得到的感知输出结果,最终得到自动驾驶周围环境感知。
[0038]
本发明提供了一种统一时空融合的环视鸟瞰图感知方法,相比于现有的环视鸟瞰图感知方法,具有以下有益效果:
[0039]
首先,本发明的时空融合方案能够有效地同时融合环视图像的空间关系,同时能够融合不同时刻环视图像的时序关系。
[0040]
其次,本发明的融合方法能够实现长时间、长时序下的融合,并且融合性能随着视角增加单调递增。
[0041]
最后,本发明的能够动态地融合不同时序步,并且具有效果更好,速度更快的特点。
附图说明
[0042]
图1为一种统一时空融合的环视鸟瞰图感知方法的步骤流程图。
具体实施方式
[0043]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不
违背本发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施例的限制。本发明各个实施例中的技术特征在没有相互冲突的前提下,均可进行相应组合。
[0044]
在本发明的描述中,需要理解的是,术语“第一”、“第二”仅用于区分描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。
[0045]
在本发明的一个较佳实施例中,提供了一种统一时空融合的环视鸟瞰图感知方法,该方法用于基于自动驾驶车辆上不同方向的摄像头采集的环视图像,感知该组环视图像所对应的真实3d世界,如地图感知、3d物体感知等,其包括以下步骤:
[0046]
s1、建立用于将摄像头空间变换到鸟瞰图空间(be空间)的虚拟视角模型。
[0047]
在本实施例中,上述步骤s1中建立虚拟视角模型的具体方法如下:
[0048]
s11、对于每组环视图像ii所对应的相机内外参信息infoi,定义其包含的旋转矩阵为平移矩阵为对于旋转矩阵r,定义rc为当前时刻的旋转矩阵,r
p
为过去时刻的旋转矩阵,r
i,j
为第i组环视图像中第j张图像对应的摄像头采用的旋转矩阵,i∈{1,
…
,m},j∈{1,
…
,n};对于平移矩阵t,定义tc为当前时刻的平移矩阵,t
p
为过去时刻的平移矩阵,t
i,j
为第i组环视图像中第j张图像对应的摄像头采用的平移矩阵。
[0049]
在本实施例中,在本实施例中n=6,即每组环视图像包含6张不同方向的图片,分别由6个不同方向的摄像头采集得到。
[0050]
s12、定义如下虚拟视角模型变换:
[0051][0052][0053]
其中为第i组环视图像中第j张图像对应的摄像头的虚拟旋转矩阵,为第i组环视图像中第j张图像对应的摄像头的虚拟平移矩阵。
[0054]
s13、对于s12中得到的虚拟视角模型变换,按照如下公式建立用于将摄像头空间变换到鸟瞰图空间的虚拟视角模型:
[0055][0056]
其中p
bev
为鸟瞰图空间中的坐标点,p
img
为图像空间中的坐标点,k
i,j
为第i组环视图像中第j张图像对应的摄像头的相机内参。
[0057]
s2、构建用于从环视图像组内的单张环视图像中提取多层次特征的基础骨干网络。
[0058]
在本实施例中,上述步骤s2中,构建的基础骨干网络如下:
[0059]
选择resnet、swin-tiny、vovnet中的一种作为骨干网络,对于所有输入的环视图像均使用同一个选定的骨干网络进行特征提取,使不同摄像头拍摄的图像之间共享骨干网络;对于层次数目为l的骨干网络,在提取多层次特征时,需对骨干网络每一个层(stage)提取的特征均进行保留,即保留所有中间特征和最终的特征,最终得到l个层次的多层次特征。
[0060]
s3、基于s2构建的骨干网络特征对输入的不同时刻的环视图像进行逐帧特征提取,并按照时刻对提取的特征进行排序,建立时序特征队列。
[0061]
在本实施例中,上述步骤s3中,建立时序特征队列方法如下:
[0062]
将不同时刻的环视图像组输入所述骨干网络中,由骨干网络逐帧提取单帧多层次特征,并按照图像采集的时间顺序将多层次特征保存在时序特征队列中。
[0063]
s4、基于s1中构建的虚拟视角模型与s3中建立的时序特征队列,通过统一时空融合特征融合器建模得到融合特征。
[0064]
在本实施例中,上述步骤s4中,得到融合特征的方法如下:
[0065]
s41、基于s3中得到的时序特征队列,获取最新的长度为p个时刻的时序特征组。
[0066]
需要注意的是,p是一个需要进行优化调整的超参数。在获取融合特征时,需利用时序特征队列中保存的从最新的p个时刻的环视图像组中提取的时序特征组成时序特征组,从而实现对外部世界的实时感知。因此,该时序特征队列相当于一个长度为p的先进先出序列,通过该序列即可保持最新的时序特征组。
[0067]
s42、建立鸟瞰图空间表达,以表达整个鸟瞰图空间;其中,q
x,y
为鸟瞰图的查询(query),表示在鸟瞰图空间位置(x,y)处的特征信息;c为特征维度,x和y为鸟瞰图空间的长和宽;对于每个鸟瞰图空间位置(x,y),在高度z上从-3m到5m进行均匀采样获取z个高度点,从而得到一组对应鸟瞰图空间位置(x,y)的3d坐标{(x,y,z)|z∈[-3,5]};对于每个鸟瞰图空间位置(x,y),进一步通过s23中建立的虚拟视角模型对采样得到的3d坐标{(x,y,z)|z∈[-3,5]}进行变换,将鸟瞰图空间下的3d坐标{(x,y,z)|z∈[-3,5]}转换至摄像头空间,得到其在图像空间中的位置p
img
,从而建立了鸟瞰图空间中位置点与图像空间中位置点的映射关系;根据所述映射关系,将时序特征组中图像空间下的多层次特征映射至鸟瞰图空间中。
[0068]
s43、建立统一时空融合特征融合器,其包含由浅到深级联的自注意力层、第一归一化层、互注意力层、第二归一化层、前馈网络层和第三归一化层;其中自注意力层使用可变形注意力方法,所述第一归一化层、第二归一化层和第三归一化层均使用层归一化方法(layernorm),所述前馈网络由一个全连接网络组成,所述互注意力层则由以下公式定义:
[0069][0070][0071]
其中为所述时序特征组中第p个时刻第l个层次的特征被虚拟视角模型映射至鸟瞰图空间后在鸟瞰图空间位置(x,y,z)处所对应的特征,p=1,2,
…
,p;l=1,2,
…
,l;z一共有z个,具体根据均匀采样获取的z个高度点确定;为叠加位置编码(positional embedding,pe)后的结果;为互注意力权重,其计算式中的q
x,y
是原始鸟瞰图空间表达中的q
x,y
经过了自注意力层和第一归一化层后的输出结果。
[0072]
需要注意的是,上述自注意力层、第一归一化层、互注意力层、第二归一化层、前馈网络层和第三归一化层是逐层级联的,上一层的输出作为下一层的输入,第三归一化层的输出作为整个融合器的输出。在该网络结构中,q
x,y
可以视为是一个不断迭代更新的参数,
自注意力层的输入为原始鸟瞰图空间表达中的q
x,y
,输出为更新后的q
x,y
,更新后的q
x,y
经过第一归一化层中的层归一化操作后,在输入互注意力层,依次类推。
[0073]
需要说明的是,自注意力层使用可变形注意力方法即deformable detr,属于现有技术,具体原理可参见现有技术文献:zhu,xizhou,weijie su,lewei lu,bin li,xiaogang wang,and jifeng dai."deformable detr:deformable transformers for end-to-end object detection."arxiv preprint arxiv:2010.04159(2020).
[0074]
s44、将s41中的时序特征组输入s43中建立的统一时空融合特征融合器中,获得统一时空融合特征融合器的输出特征。
[0075]
s5、基于s4得到的融合特征使用头部网络输出预测结果,得到用于自动驾驶的周围环境感知。
[0076]
在本实施例中,上述步骤s5中,过程如下:
[0077]
s51、使用erfnet作为头部网络,对s44中得到的输出特征,经过erfnet头部网络后得到自动驾驶环视地图感知输出,即得到以该组环视图像为中心的地图信息;
[0078]
s52、使用centerpoint作为头部网络,对s44中得到的输出特征,经过centerpoint头部网络后得到自动驾驶3d目标检测感知输出,即得到以该组环视图像为中心的周围世界3d目标(如车辆)信息。
[0079]
s53、整合s51与s52得到的感知输出结果,最终得到自动驾驶周围环境感知。
[0080]
需要说明的是,在上述s1~s5的步骤框架中,基础骨干网络、统一时空融合特征融合器和头部网络组成了环视鸟瞰图感知网络框架。但是该环视鸟瞰图感知网络框架在用于实际预测感知之前,需要预先经过用于环视鸟瞰图感知的图像数据集进行训练,图像数据集中的环视图像样本由多方向摄像头采集的环视图像、各摄像头对应的相机内外参信息和各图像对应的标注信息组成。
[0081]
在本实施例中,用于环视鸟瞰图感知的图像数据集包括图像组在本实施例中,用于环视鸟瞰图感知的图像数据集包括图像组其中ii为第i组环视图像,每组环视图像包含n张分别由不同方向摄像头拍摄的图像,n为车辆上朝向不同方向的摄像头总数;infoi为第i组环视图像所对应的相机内外参信息,包含旋转矩阵和平移矩阵;ti为第i组环视图像整组对应的真实3d世界标注信息,包括两类标注,第一类是以该组环视图像为中心的地图信息,第二类是以该组环视图像为中心的周围世界3d车辆的标注信息;m为图像数据集中的环视图像组数。
[0082]
利用图像数据集对环视鸟瞰图感知网络框架进行训练的具体做法,属于现有技术,对此不再赘述。
[0083]
下面将上述s1~s5所描述的统一时空融合的环视鸟瞰图感知方法应用于一个具体实例中,以展示其技术效果。
[0084]
实施例
[0085]
本实施例的实现方法如前所述,不再详细阐述具体的步骤,下面仅针对案例数据展示其效果。本发明在具有真值标注的数据集上实施,详细信息如下:
[0086]
nuscenes数据集[1]:该数据集包含28130组环视训练图片组与6019组环视测试图片组,每组图片均包含bev空间标注、相机内外参。
[0087]
本实施例主要在nuscenes数据集上进行bev地图分割任务评估。
[0088]
表1本实施例在nuscenes数据集上各评价指标对比(100m x 100m范围)
[0089]
methodroad mioulane mioulss[2]72.920.0vpn[3]76.919.4m2bev[4]77.2-bevformer[5]80.125.7本发明方法85.431.0
[0090]
表1本实施例在nuscenes数据集上各评价指标对比(60m x 30m范围)
[0091]
methoddividerped crossingboundaryalllss[2]38.314.939.330.8vpn[3]36.515.835.629.3bevsegformer[6]51.132.650.044.6beverse[7]56.144.958.753.2本发明方法60.649.062.557.4
[0092]
上述nuscenes数据集的来源以及各对比方法可参见如下现有技术文献:
[0093]
[1]caesar,holger,varun bankiti,alex h.lang,sourabh vora,venice erin liong,qiang xu,anush krishnan,yu pan,giancarlo baldan,and oscar beijbom."nuscenes:a multimodal dataset for autonomous driving."in proceedings of the ieee/cvf conference on computer vision and pattern recognition,pp.11621-11631.2020.
[0094]
[2]philion,jonah,and sanja fidler."lift,splat,shoot:encoding images from arbitrary camera rigs by implicitly unprojecting to 3d."in european conference on computer vision,pp.194-210.springer,cham,2020.
[0095]
[3]pan,bowen,jiankai sun,ho yin tiga leung,alex andonian,and bolei zhou."cross-view semantic segmentation for sensing surroundings."ieee robotics and automation letters 5,no.3(2020):4867-4873.
[0096]
[4]xie,enze,zhiding yu,daquan zhou,jonah philion,anima anandkumar,sanja fidler,ping luo,and jose m.alvarez."m^2bev:multi-camera joint 3d detection and segmentation with unified birds-eye view representation."arxiv preprint arxiv:2204.05088(2022).
[0097]
[5]li,zhiqi,wenhai wang,hongyang li,enze xie,chonghao sima,tong lu,qiao yu,and jifeng dai."bevformer:learning bird's-eye-view representation from multi-camera images via spatiotemporal transformers."arxiv preprint arxiv:2203.17270(2022).
[0098]
[6]peng,lang,zhirong chen,zhangjie fu,pengpeng liang,and erkang cheng."bevsegformer:bird's eye view semantic segmentation from arbitrary camera rigs."arxiv preprint arxiv:2203.04050(2022).
[0099]
[7]zhang,yunpeng,zheng zhu,wenzhao zheng,junjie huang,guan huang,jie zhou,and jiwen lu."beverse:unified perception and prediction in birds-eye-view for vision-centric autonomous driving."arxiv preprint arxiv:2205.09743
(2022).
[0100]
上述结果表明,本发明相比于现有技术中的其他感知模型,能够有效地同时融合环视图像的空间关系,同时能够融合不同时刻环视图像的时序关系,通过更好地融合不同时序步取得了更好的感知效果和更快的感知速度。
[0101]
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1