基于Transformer的眼动事件检测方法
基于transformer的眼动事件检测方法
技术领域
1.本发明属于眼动事件检测技术领域,涉及一种基于transformer的眼动事件检测方法。
背景技术:
2.眼动事件检测(eye movement event detection)的目的是从眼动仪的原始观测视频中准确鲁棒地提取注视、眼跳、平稳追踪等眼睛运动事件。长期以来,有两类算法应用在此方向上,一类是基于速度的算法,一类是基于离散度的算法。velocity-threshold identification(i-vt)由bahill等人(1981)提出,其原理可以追溯到1960年代的boyce算法,通过设定速度阈值,将高于阈值的归类为眼跳,低于阈值的归类为注视。dispersion-threshold identification(i-dt)由salvucci等人(2000)提出,其原理是用跨越连续样本点的移动窗口来检测潜在的注视,由于注视的低速特点会使其样本点倾向于紧密聚集,所以将窗口内低于离散度阈值的事件归类为注视。这两种方法依赖于手工设计的眼动特征(眼睛位置、速度、加速度等),且很难找到针对不同受试者的普适阈值,检测性能不仅受限于特征提取方法的准确性,而且难以处理多种眼动事件的同时提取。
3.近年来机器学习方法已被初步应用于基于视线位置的眼动事件检测,pekkanen(2017)等人提出了一种朴素分段线性回归方法同时对视线位置时间序列进行去噪和分割,然后采用隐马尔可夫分类器将眼动事件分为四类(注视、眼跳、平稳追踪和眼跳后振荡)。zemblys(2018)等人首先从原始视线位置时间序列提取了14种特征(不同特征利用的数据长度不同),然后使用随机森林分类器对每个采样点进行了多分类,最后基于规则对分类结果进行整合,实现眼动事件检测和分类。以上两种方法采用的仍然是手工设计特征,只不过在分类器设计上使用了机器学习方法。
4.随着深度学习方法的迅速发展,hoppe和bulling(2016)提出了一种基于卷积神经网络的端到端模型从连续的眼动序列中同时检测出不同的眼动事件,其模型性能优于i-vt和i-dt算法。startsev等人(2018)提出了一个1d-cnn-blstm网络,在gazecom数据集上进行了评估并与12个参考算法进行了比较,实验结果表明其性能优于其他算法。zemblys等人(2019)进一步提出了基于深度学习的端到端的眼动事件检测方法(gazenet),该方法首先使用两个一维卷积层提取原始视线位置时间序列的特征,然后采用三层双向长短时记忆网络(long short term memory network,lstm)加一层全连接层对每个采样点进行分类。
5.目前基于深度学习的眼动事件检测方法普遍以lstm及其变体为主干网络,而lstm中当前时刻的观测仅强烈影响下一时刻的特征表示,在几个时间步长之后其影响就很快消失,因此lstm不能有效地建立长序列上不同时刻观测之间的长期依赖关系;另外,lstm是顺序模型,这意味着样本点是按顺序处理的,不能实现序列处理的高度并行化。
技术实现要素:
6.本发明的目的是提供一种基于transformer的眼动事件检测方法,解决了现有基
于lstm的眼动事件检测深度方法中lstm不能有效地建立长序列上不同时刻观测之间的长期依赖关系且不能实现序列处理的高度并行化对检测算法性能的限制。
7.本发明所采用的技术方案是:
8.基于transformer的眼动事件检测方法,包括以下步骤:
9.步骤1、输入数据为公开眼动事件检测数据集,对原始视线位置序列数据进行预处理,得到差分视线位置序列;
10.步骤2、将差分视线位置序列送入cnn网络中进行特征提取,cnn网络的输出作为字向量word embedding;
11.步骤3、对视线位置序列进行位置编码positional encoding,以表征视线位置序列的前后位置信息;
12.步骤4、将字向量与位置编码相加之后得到f
t
送入transformer的encoder层,经过n层encoder之后学习到涵盖序列全局的信息,最后经过线性全连接层和softmax将眼动序列中每一时刻的样本点分类为注视、眼跳和眼跳后震荡,实现眼动事件检测;
13.步骤5、使用事件级cohen’s kappa来对分类后的三种眼动事件进行性能评估。
14.本发明的特点还在于:
15.步骤1预处理具体包括:
16.步骤1.1,对于输入的数据集剔除除注视、眼跳、眼跳后震荡之外的其它眼动事件;
17.步骤1.2,然后将以像素表示的视线位置(x,y)转换为以空间角度表示的视线位置(xs,ys);
18.步骤1.3,对输入的视线位置序列进行差分操作,用后一时刻的位置减去前一时刻的位置得到视线位置的差分序列来作为cnn网络的输入。
19.步骤1.2的计算公式如下:
[0020][0021][0022]
其中,x是水平方向坐标,y是垂直方向坐标,pw是前景相机图像中显示器宽度方向的像素数,ph是前景相机图像中显示器高度方向的像素数,sw是屏幕宽度,sh是屏幕高度,d是眼睛相对屏幕的距离。
[0023]
步骤1.3中视线位置序列表示为:[(x
s1
,y
s1
),(x
s2
,y
s2
),(x
s3
,y
s3
),
…
,(x
sm
,y
sm
),(x
s(m+1)
,y
s(m+1)
)]共m+1个样本点,差分后的序列表示:共m个样本点,其中差分计算公式为:
[0024][0025]
[0026]
其中x
s(m+1)
和y
s(m+1)
表示原始视线位置序列第m+1时刻样本点的坐标值,x
sm
和y
sm
表示原始视线位置序列第m时刻样本点的坐标值,和表示差分后的序列第m时刻样本点的坐标值。
[0027]
步骤2的cnn网络采用的卷积核大小为2
×
11,以用来从输入数据中提取时空局部特征,并通过卷积抽象成高维特征,输出的特征向量作为眼动序列的字向量。
[0028]
步骤3的位置编码提供序列每个样本点的位置信息给transformer,识别出序列中的顺序关系,使用sin和cos函数的线性变换来提供给模型位置信息:
[0029][0030][0031]
其中pos指的是序列中某个样本点的位置,i指的是字向量的维度序号,d
model
指的是字向量的维度。
[0032]
步骤4的transformer层参数为4层encoder,每个encoder层分为两个子层,第一层使用self-attention机制,第二层使用一个前馈神经网络层,其中字向量的维度d
model
是64维,前馈神经网络的维度d
ff
是256维;
[0033]
其中self-attention机制定义了三个矩阵wq、wk、wv,使用这三个矩阵分别对所有的字向量进行三次线性变换,于是所有的字向量又衍生出三个新的向量q
t
、k
t
、v
t
,将所有的q
t
向量拼成一个大矩阵,记作查询矩阵q,所有的k
t
向量拼成一个大矩阵,记作键矩阵k,所有的v
t
向量拼成一个大矩阵,记作值矩阵v;接下来将q和k
t
相乘,然后除以经过softmax之后与v相乘得到self-attention的输出,具体公式实现如下:
[0034][0035]
其中z是self-attention的输出,q是查询矩阵,k是键矩阵,v是值矩阵,dk是键矩阵的维度。
[0036]
本发明的有益效果是:
[0037]
该方法采用了cnn和transformer来对眼动事件进行检测,综合了cnn和transformer的优点,cnn层用来学习眼动序列的时空局部特征,并通过卷积抽象成高维特征以作为transformer的输入字向量,transformer学习眼动序列的全局特征,相比现有使用基于lstm的方法,transformer以整个序列为输入单元实现处理的高度并行化,并通过self-attention机制建立当前观测与输入序列中不同时刻观测之间的依赖关系,使模型不仅关注当前观测与临近时刻观测的关系,而且关注到当前观测与序列中不同时刻观测之间的依赖关系。此外transformer的多头注意力机制和位置编码都提供了有关不同样本点之间关系的信息。
附图说明
[0038]
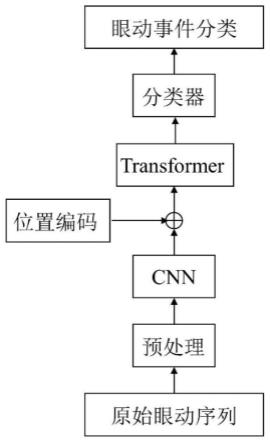
图1是本发明的总体框架流程图;
[0039]
图2是transformer的encoder层的网络结构图。
具体实施方式
[0040]
下面结合附图和具体实施方式对本发明进行详细说明。
[0041]
如图1所示,本发明实例提供的一种基于transformer的眼动事件检测方法包括如下步骤:
[0042]
步骤1,眼动序列的预处理。
[0043]
输入数据使用lund2013眼动数据集,数据集中包括时间戳timestamp、水平方向坐标x、垂直方向坐标y、眼动事件类型event、屏幕宽度sw、屏幕高度sh、前景相机图像中显示器宽度方向的像素数pw、前景相机图像中显示器高度方向的像素数ph以及眼睛相对屏幕距离d。首先需要剔除注视、眼跳和眼跳后震荡之外的其他眼动事件,使得训练数据仅包含注视、眼跳和眼跳后震荡三个事件以进行训练和测试,具体做法是首先对眼动事件类型event做处理,将需要检测的三个事件标记为true,其它事件标记为false,之后将标签为false的眼动序列样本点进行分段剔除,仅保留标记为true的眼动序列分段。
[0044]
然后将以像素表示的视线位置(x,y)转换为以空间角度表示的视线位置(xs,ys),转换公式如下:
[0045][0046][0047]
其中,x是水平方向坐标,y是垂直方向坐标,pw是前景相机图像中显示器宽度方向的像素数,ph是前景相机图像中显示器高度方向的像素数,sw是屏幕宽度,sh是屏幕高度,d是眼睛相对屏幕的距离。
[0048]
最后对输入的视线位置序列进行差分操作,用后一时刻的位置减去前一时刻的位置得到视线位置的差分序列来作为cnn网络的输入,原始视线位置序列表示为[(x
s1
,y
s1
),(x
s2
,y
s2
),(x
s3
,y
s3
),
…
,(x
sm
,y
sm
),(x
s(m+1)
,y
s(m+1)
)],共m+1个样本点,差分后的序列表示为)],共m+1个样本点,差分后的序列表示为共m个样本点,其中差分计算公式为:
[0049][0050][0051]
其中x
s(m+1)
和y
s(m+1)
表示原始视线位置序列第m+1时刻样本点的坐标值,x
sm
和y
sm
表示原始视线位置序列第m时刻样本点的坐标值,和表示差分后的序列第m时刻样本点的坐标值。
[0052]
步骤2,利用cnn网络对视线位置序列进行特征提取。
[0053]
cnn网络采用6层卷积核大小为2
×
11的卷积层,以用来从输入数据中提取时空局
部特征,并通过卷积抽象成高维特征,输出的特征向量作为眼动序列的字向量(word embedding),该字向量作为transformer的输入。
[0054]
步骤3,对视线位置序列进行位置编码(positional encoding)。
[0055]
使用位置编码是因为transformer模型没有循环神经网络的迭代操作,所以必须提供序列每个样本点的位置信息给transformer,这样才能识别出序列中的顺序关系。使用sin和cos函数的线性变换给模型提供位置信息:
[0056][0057][0058]
其中pe表示位置编码,pos指的是序列中某个样本点的位置,f指的是字向量的维度序号,d
model
指的是字向量的维度。
[0059]
步骤4、利用transformer来学习涵盖序列全局的信息。
[0060]
将字向量与位置编码相加之后得到f
t
送入transformer的encoder层,transformer的encoder层分为两个子层,如图2所示,第一层使用self-attention机制,使得编码器在编码某个特定样本点时,关注与其他样本点之间的关系,第二层使用一个前馈神经网络层。其中self-attention机制定义了三个矩阵wq、wk、wv,使用这三个矩阵分别对所有的字向量进行三次线性变换,于是所有的字向量又衍生出三个新的向量q
t
、k
t
、v
t
,将所有的q
t
向量拼成一个大矩阵,记作查询矩阵q,所有的k
t
向量拼成一个大矩阵,记作键矩阵k,所有的v
t
向量拼成一个大矩阵,记作值矩阵v。接下来将q和k
t
相乘,然后除以经过softmax之后与v相乘得到self-attention的输出,具体公式实现如下:
[0061][0062]
其中z是self-attention的输出,q是查询矩阵,k是键矩阵,v是值矩阵,dk是键矩阵的维度。
[0063]
进一步,self-attention的输出与输入f
t
进行残差连接,经过layernorm后输出给前馈神经网络层,最后该层encoder的输出作为下一个encoder层的输入。经过n层encoder之后学习到涵盖序列全局的信息,最后经过全连接层和softmax输出三种事件的概率,其中概率最大的事件即为预测的眼动事件类型,从而实现眼动事件检测。
[0064]
本发明采用的transformer层参数为4层encoder,d
model
是64维,前馈神经网络的维度d
ff
是256维,q、k、v三个矩阵的维度都是32维,多头注意力机制的n
heads
大小是2。
[0065]
步骤5、使用事件级cohen’s kappa来对分类后的三种眼动事件进行性能评估。
[0066]
实施例1
[0067]
本实施例1采用的测试集为lund2013数据集划分出来的22个眼动序列。执行上述步骤1~步骤5,最终在该测试集上注视、眼跳和眼跳后震荡的事件级cohen’s kappa分数分别为0.923,0.925和0.782。
[0068]
表1测试集上各个眼动序列的评估分数。
[0069][0070]
表1展示了测试集上各个眼动序列的评估得分,ke_fixation表示注视的事件级cohen’s kappa分数,ke_saccade表示眼跳的事件级cohen’s kappa分数,ke_psos表示眼跳后震荡的事件级cohen’s kappa分数。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1