低碳大数据人工智能方法和医康养生态系统
1.本发明涉及人工智能技术领域,特别是涉及一种低碳大数据人工智能方法和医康养生态系统。
背景技术:
2.在实现本发明过程中,发明人发现现有技术中至少存在如下问题:现有的系统资源利用率低,很多时候服务器在空转,同时又有些任务得不到及时执行,对电力消耗大,特别是医康养等这种规模大的业务系统。
3.因此,现有技术还有待于改进和发展。
技术实现要素:
4.基于此,有必要针对现有技术的缺陷或不足,提供低碳大数据人工智能方法和医康养生态系统,以解决现有系统资源利用率不高的技术问题,使得任务可以被更为及时地执行,同时提高资源的利用率,进而降低碳排放。
5.第一方面,本发明实施例提供一种人工智能方法,所述方法包括:
6.任务预测深度学习模型构建步骤:获取n对t0i至t0i+tttask1内的所有类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务(i=1~n),将t0i至t0i+tttask1内的所有类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到任务预测深度学习模型;tttask2为预测时长;
7.任务预测步骤:获取当前时间tx,将tx-tttask1至tx内的所有类型的任务作为任务预测深度学习模型的输入,将任务预测深度学习模型的输出作为tx至tx+tttask2内的所述预设类型的任务;
8.任务预先执行步骤:如果当前时间没有超过tx+tttask2且所述预设类型的任务符合执行的条件且存在空闲的资源执行所述预设类型的任务,则调度执行所述预设类型的任务;
9.任务预测深度学习模型进化步骤:获取执行当前任务预先执行步骤之前的任务执行效率ptask1,执行当前任务预先执行步骤之后的任务执行效率ptask2,如果ptask1大于ptask2,则按照预设增减量减小tttask2,增加深度学习模型训练的样本量,如果ptask1小于ptask2,则按照预设增减量增大tttask2;经过第一预设时间后,重新执行任务预测深度学习模型构建步骤、任务预测步骤、任务预先执行步骤;
10.碳排放优化任务步骤:获取测试集中的测试任务,计算执行任务预先执行步骤之前执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第一碳排放量,计算执行任务预先执行步骤之后执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第二碳排放量,如果第一碳排放量小于第二碳排放量,则说明预测有好的效果,按照预设增减量增大预测时长;如果第一碳排放量大于或等于第二碳排放量,则说明预测效
果不好,按照预设增减量减小预测时长,增加深度学习模型训练的样本量;经过第一预设时间后,重新执行任务预测深度学习模型构建步骤、任务预测步骤、任务预先执行步骤。
11.优选地,所述方法包括:
12.资源预测深度学习模型构建步骤:获取n对t0i至t0i+ttresource1内的所有类型的任务、所有类型资源的占用率、t0i+ttresource1至t0i+ttresource1+ttresource2内的所述预设类型资源的占用率(i=1~n),将t0i至t0i+ttresource1内的所有类型的任务、所有类型资源的占用率、t0i+ttresource1至t0i+ttresource1+ttresource2内的所述预设类型资源的占用率分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到资源预测深度学习模型;ttresource2为预测时长;
13.资源预测步骤:获取当前时间tx,将tx-ttresource1至tx内的所有类型的任务、所有类型资源的占用率作为任务预测深度学习模型的输入,将资源预测深度学习模型的输出作为tx至tx+ttresource2内的所述预设类型资源的占用率;
14.任务预先调到资源的步骤:如果tx至tx+ttresource2内的所述预设类型资源的占用率满足预设调度条件,则将与所述预设类型资源对应的待执行的预设类型的任务调度到所述预设类型资源的待执行队列中;
15.资源预测深度学习模型进化步骤:获取执行当前任务预先调到资源的步骤之前的任务执行效率presource1,执行当前任务预先调到资源的步骤之后的任务执行效率presource2,如果presource1大于presource2,则按照预设增减量减小ttresource2,增加深度学习模型训练的样本量,如果presource1小于presource2,则按照预设增减量增大ttresource2;经过第一预设时间后,重新执行资源预测深度学习模型构建步骤、资源预测步骤、任务预先调到资源的步骤;
16.碳排放优化资源调度步骤:获取测试集中的测试任务,计算执行任务预先调到资源的步骤之前执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第一碳排放量,计算执行任务预先调到资源的步骤之后执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第二碳排放量,如果第一碳排放量小于第二碳排放量,则说明预测有好的效果,按照预设增减量增大预测时长;如果第一碳排放量大于或等于第二碳排放量,则说明预测效果不好,按照预设增减量减小预测时长,增加深度学习模型训练的样本量;经过第一预设时间后,重新执行资源预测深度学习模型构建步骤、资源预测步骤、任务预先调到资源的步骤。
17.优选地,所述方法还包括:
18.预先休眠的步骤:所述预设类型的任务为数据休眠任务;
19.预先计算的步骤:所述预设类型的任务为计算任务;
20.预先数据读取的步骤:所述预设类型的任务为数据读取任务;
21.预先数据传输的步骤:所述预设类型的任务为数据传输任务。
22.优选地,所述方法包括:
23.存储资源预测的步骤:预设调度条件为高于预设值;所述预设类型的资源为存储资源;
24.所述预设类型的任务为数据休眠任务;
25.计算资源预测调度的步骤:预设调度条件为低于预设值;所述预设类型的资源为
计算资
26.源;所述预设类型的任务为计算任务;
27.i/o资源预测调度的步骤:预设调度条件为低于预设值;所述预设类型的资源为i/o资源;所述预设类型的任务为数据读取任务;
28.网络资源预测调度的步骤:预设调度条件为低于预设值;所述预设类型的资源为网络资源;所述预设类型的任务为数据传输任务。
29.第二方面,本发明实施例提供一种人工智能系统,所述系统包括:
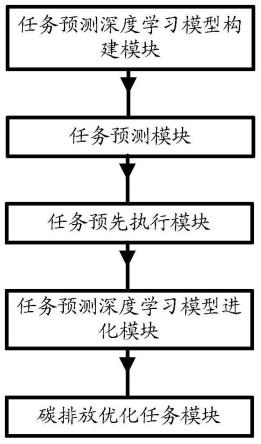
30.任务预测深度学习模型构建模块:获取n对t0i至t0i+tttask1内的所有类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务(i=1~n),将t0i至t0i+tttask1内的所有类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到任务预测深度学习模型;tttask2为预测时长;
31.任务预测模块:获取当前时间tx,将tx-tttask1至tx内的所有类型的任务作为任务预测深度学习模型的输入,将任务预测深度学习模型的输出作为tx至tx+tttask2内的所述预设类型的任务;
32.任务预先执行模块:如果当前时间没有超过tx+tttask2且所述预设类型的任务符合执行的条件且存在空闲的资源执行所述预设类型的任务,则调度执行所述预设类型的任务;
33.任务预测深度学习模型进化模块:获取执行当前任务预先执行模块之前的任务执行效率ptask1,执行当前任务预先执行模块之后的任务执行效率ptask2,如果ptask1大于ptask2,则按照预设增减量减小tttask2,增加深度学习模型训练的样本量,如果ptask1小于ptask2,则按照预设增减量增大tttask2;经过第一预设时间后,重新执行任务预测深度学习模型构建模块、任务预测模块、任务预先执行模块;
34.碳排放优化任务模块:获取测试集中的测试任务,计算执行任务预先执行模块之前执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第一碳排放量,计算执行任务预先执行模块之后执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第二碳排放量,如果第一碳排放量小于第二碳排放量,则说明预测有好的效果,按照预设增减量增大预测时长;如果第一碳排放量大于或等于第二碳排放量,则说明预测效果不好,按照预设增减量减小预测时长,增加深度学习模型训练的样本量;经过第一预设时间后,重新执行任务预测深度学习模型构建模块、任务预测模块、任务预先执行模块。
35.优选地,所述系统包括:
36.资源预测深度学习模型构建模块:获取n对t0i至t0i+ttresource1内的所有类型的任务、所有类型资源的占用率、t0i+ttresource1至t0i+ttresource1+ttresource2内的所述预设类型资源的占用率(i=1~n),将t0i至t0i+ttresource1内的所有类型的任务、所有类型资源的占用率、t0i+ttresource1至t0i+ttresource1+ttresource2内的所述预设类型资源的占用率分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到资源预测深度学习模型;ttresource2为预测时长;
37.资源预测模块:获取当前时间tx,将tx-ttresource1至tx内的所有类型的任务、所有类型资源的占用率作为任务预测深度学习模型的输入,将资源预测深度学习模型的输出
作为tx至tx+ttresource2内的所述预设类型资源的占用率;
38.任务预先调到资源的模块:如果tx至tx+ttresource2内的所述预设类型资源的占用率满足预设调度条件,则将与所述预设类型资源对应的待执行的预设类型的任务调度到所述预设类型资源的待执行队列中;
39.资源预测深度学习模型进化模块:获取执行当前任务预先调到资源的模块之前的任务执行效率presource1,执行当前任务预先调到资源的模块之后的任务执行效率presource2,如果presource1大于presource2,则按照预设增减量减小ttresource2,增加深度学习模型训练的样本量,如果presource1小于presource2,则按照预设增减量增大ttresource2;经过第一预设时间后,重新执行资源预测深度学习模型构建模块、资源预测模块、任务预先调到资源的模块;
40.碳排放优化资源调度模块:获取测试集中的测试任务,计算执行任务预先调到资源的模块之前执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第一碳排放量,计算执行任务预先调到资源的模块之后执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第二碳排放量,如果第一碳排放量小于第二碳排放量,则说明预测有好的效果,按照预设增减量增大预测时长;如果第一碳排放量大于或等于第二碳排放量,则说明预测效果不好,按照预设增减量减小预测时长,增加深度学习模型训练的样本量;经过第一预设时间后,重新执行资源预测深度学习模型构建模块、资源预测模块、任务预先调到资源的模块。
41.优选地,所述系统还包括:
42.预先休眠的模块:所述预设类型的任务为数据休眠任务;
43.预先计算的模块:所述预设类型的任务为计算任务;
44.预先数据读取的模块:所述预设类型的任务为数据读取任务;
45.预先数据传输的模块:所述预设类型的任务为数据传输任务。
46.优选地,所述系统包括:
47.存储资源预测的模块:预设调度条件为高于预设值;所述预设类型的资源为存储资源;
48.所述预设类型的任务为数据休眠任务;
49.计算资源预测调度的模块:预设调度条件为低于预设值;所述预设类型的资源为计算资
50.源;所述预设类型的任务为计算任务;
51.i/o资源预测调度的模块:预设调度条件为低于预设值;所述预设类型的资源为i/o资源;所述预设类型的任务为数据读取任务;
52.网络资源预测调度的模块:预设调度条件为低于预设值;所述预设类型的资源为网络资源;所述预设类型的任务为数据传输任务。
53.第三方面,本发明实施例提供一种医康养生态化系统,包括医康养系统,其特征在于,所述医康养系统执行权利要求1-4任意一项所述方法的步骤。
54.第四方面,本发明实施例提供一种人工智能装置,所述系统包括第二方面实施例任意一项所述模块的装置。
55.第五方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,
其特征在于,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
56.第六方面,本发明实施例提供一种机器人系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,其特征在于,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
57.本实施例提供的低碳大数据人工智能方法和医康养生态系统,包括:任务预测深度学习模型构建步骤;任务预测步骤;任务预先执行步骤;任务预测深度学习模型进化步骤;碳排放优化任务步骤。上述方法、系统和机器人,通过深度学习模型预测将来可能需要执行的任务,这样可以提前利用空闲资源来执行任务,从而提高资源的利用率,资源的利用率提高了,那么同样多的任务消耗的资源就少了,从而减少了碳排放。
附图说明
58.图1为本发明的实施例提供的人工智能系统的模块图;
59.图2为本发明的实施例提供的人工智能系统的模块图;
60.图3为本发明的实施例提供的人工智能系统的模块图;
61.图4为本发明的实施例提供的人工智能系统的模块图。
具体实施方式
62.下面结合本发明实施方式,对本发明实施例中的技术方案进行详细地描述。
63.一、本发明的基本实施例
64.第一方面,本发明实施例提供一种人工智能方法,所述方法包括:任务预测深度学习模型构建步骤;任务预测步骤;任务预先执行步骤;任务预测深度学习模型进化步骤;碳排放优化任务步骤。技术效果:通过深度学习模型预测将来可能需要执行的任务,这样可以提前利用空闲资源来执行任务,从而提高资源的利用率,资源的利用率提高了,那么同样多的任务消耗的资源就少了,从而减少了碳排放。同时,通过进化可以不断提高预测的准确率。
65.在一个优选的实施例中,所述方法包括:资源预测深度学习模型构建步骤;资源预测步骤;任务预先调到资源的步骤;资源预测深度学习模型进化步骤;碳排放优化资源调度步骤。技术效果:通过深度学习模型预测将来资源的占用率,这样可以提前将任务调度道将来可能空闲的资源上等待执行,从而提高资源的利用率,资源的利用率提高了,那么同样多的任务消耗的资源就少了,从而减少了碳排放。通过进化可以不断提高预测的准确率。
66.在一个优选的实施例中,所述方法还包括:预先休眠的步骤;预先计算的步骤;预先数据读取的步骤;预先数据传输的步骤。技术效果:在存储、计算、数据等方面提高任务的执行效率。
67.在一个优选的实施例中,所述方法包括:存储资源预测的步骤;计算资源预测调度的步骤;i/o资源预测调度的步骤;网络资源预测调度的步骤。技术效果:在存储、计算、数据等方面提高资源利用率。
68.第二方面,本发明实施例提供一种人工智能系统,如图1所示,所述系统包括:任务预测深度学习模型构建模块;任务预测模块;任务预先执行模块;任务预测深度学习模型进化模块;碳排放优化任务模块。
69.在一个优选的实施例中,如图2所示,所述系统包括:资源预测深度学习模型构建模块;资源预测模块;任务预先调到资源的模块;资源预测深度学习模型进化模块;碳排放优化资源调度模块。
70.在一个优选的实施例中,如图3所示,所述系统还包括:预先休眠的模块;预先计算的模块;预先数据读取的模块;预先数据传输的模块。
71.在一个优选的实施例中,如图4所示,所述系统包括:存储资源预测的模块;计算资源预测调度的模块;i/o资源预测调度的模块;网络资源预测调度的模块。
72.第三方面,本发明实施例提供一种医康养生态化系统,包括医康养系统,其特征在于,所述医康养系统执行第一方面实施例任意一项所述方法的步骤。技术效果:通过任务和资源预测、预先执行任务、预先进行资源的调度,能够使得医康养系统更为节省资源、更为绿色化、生态化。
73.第四方面,本发明实施例提供一种人工智能装置,所述系统包括第二方面实施例任意一项所述系统的模块。
74.第五方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
75.第六方面,本发明实施例提供一种机器人系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,其特征在于,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
76.二、本发明的第一优选实施例
77.1任务预先完成步骤
78.方案1(通过某类任务预测某类任务):
79.任务预测深度学习模型构建步骤:获取n对t0i至t0i+tttask1内的预设类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务(i=1~n),将t0i至t0i+tttask1内的所述预设类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到任务预测深度学习模型;tttask2为预测时长;
80.任务预测步骤:获取当前时间tx,将tx-tttask1至tx内的所述预设类型的任务作为任务预测深度学习模型的输入,将任务预测深度学习模型的输出作为tx至tx+tttask2内的所述预设类型的任务;
81.任务预先执行步骤:如果当前时间没有超过tx+tttask2且所述预设类型的任务符合执行的条件且存在空闲的资源执行所述预设类型的任务,则调度执行所述预设类型的任务;
82.任务预测深度学习模型进化步骤:获取执行当前任务预先执行步骤之前的任务执行效率ptask1,执行当前任务预先执行步骤之后的任务执行效率ptask2,如果ptask1大于ptask2,则按照预设增减量减小tttask2,增加深度学习模型训练的样本量,如果ptask1小于ptask2,则按照预设增减量增大tttask2;经过第一预设时间后,重新执行任务预测深度学习模型构建步骤、任务预测步骤、任务预先执行步骤。
83.方案2(通过所有任务预测某类任务):因为各类任务之间相互关联,所以通过所有任务来预测某类任务更为精准
84.任务预测深度学习模型构建步骤:获取n对t0i至t0i+tttask1内的所有类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务(i=1~n),将t0i至t0i+tttask1内的所有类型的任务、t0i+tttask1至t0i+tttask1+tttask2内的所述预设类型的任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到任务预测深度学习模型;tttask2为预测时长;
85.任务预测步骤:获取当前时间tx,将tx-tttask1至tx内的所有类型的任务作为任务预测深度学习模型的输入,将任务预测深度学习模型的输出作为tx至tx+tttask2内的所述预设类型的任务;
86.任务预先执行步骤:如果当前时间没有超过tx+tttask2且所述预设类型的任务符合执行的条件且存在空闲的资源执行所述预设类型的任务,则调度执行所述预设类型的任务;
87.任务预测深度学习模型进化步骤:获取执行当前任务预先执行步骤之前的任务执行效率ptask1,执行当前任务预先执行步骤之后的任务执行效率ptask2,如果ptask1大于ptask2,则按照预设增减量减小tttask2,增加深度学习模型训练的样本量,如果ptask1小于ptask2,则按照预设增减量增大tttask2;经过第一预设时间后,重新执行任务预测深度学习模型构建步骤、任务预测步骤、任务预先执行步骤。
88.碳排放计算步骤
89.碳排放优化步骤:获取测试集中的测试任务,计算执行任务预先执行步骤之前执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第一碳排放量,计算执行任务预先执行步骤之后执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第二碳排放量,如果第一碳排放量小于第二碳排放量,则说明预测有好的效果,按照预设增减量增大预测时长;如果第一碳排放量大于或等于第二碳排放量,则说明预测效果不好,按照预设增减量减小预测时长,增加深度学习模型训练的样本量;经过第一预设时间后,重新执行任务预测深度学习模型构建步骤、任务预测步骤、任务预先执行步骤。
90.预先休眠的步骤
91.所述预设类型的任务为数据休眠任务。
92.预先计算的步骤
93.所述预设类型的任务为计算任务。
94.预先数据读取的步骤
95.所述预设类型的任务为数据读取任务。
96.预先数据传输的步骤
97.所述预设类型的任务为数据传输任务。
98.2资源预测步骤:预设类型的资源与所有类型的任务和所有类型的资源都相关。
99.资源预测深度学习模型构建步骤:获取n对t0i至t0i+ttresource1内的所有类型的任务、所有类型资源的占用率、t0i+ttresource1至t0i+ttresource1+ttresource2内的所述预设类型资源的占用率(i=1~n),将t0i至t0i+ttresource1内的所有类型的任务、所有类型资源的占用率、t0i+ttresource1至t0i+ttresource1+ttresource2内的所述预设类型资源的占用率分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到资源预测深度学习模型;ttresource2为预测时长;
100.资源预测步骤:获取当前时间tx,将tx-ttresource1至tx内的所有类型的任务、所有类型资源的占用率作为任务预测深度学习模型的输入,将资源预测深度学习模型的输出作为tx至tx+ttresource2内的所述预设类型资源的占用率;
101.任务预先调到资源的步骤:如果tx至tx+ttresource2内的所述预设类型资源的占用率满足预设调度条件,则将与所述预设类型资源对应的待执行的预设类型的任务调度到所述预设类型资源的待执行队列中;优选地,如果tx至tx+ttresource2内的所述预设类型资源的占用率满足预设调度条件,则将通过任务预先执行步骤预测得到的预设类型的任务调度到所述预设类型资源的待执行队列中,所述预设类型的任务与所述预设类型资源对应;
102.资源预测深度学习模型进化步骤:获取执行当前任务预先调到资源的步骤之前的任务执行效率presource1,执行当前任务预先调到资源的步骤之后的任务执行效率presource2,如果presource1大于presource2,则按照预设增减量减小ttresource2,增加深度学习模型训练的样本量,如果presource1小于presource2,则按照预设增减量增大ttresource2;经过第一预设时间后,重新执行资源预测深度学习模型构建步骤、资源预测步骤、任务预先调到资源的步骤。
103.碳排放计算步骤
104.碳排放优化步骤:获取测试集中的测试任务,计算执行任务预先调到资源的步骤之前执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第一碳排放量,计算执行任务预先调到资源的步骤之后执行测试任务所消耗的电量,根据所消耗的电量计算碳排放量,得到第二碳排放量,如果第一碳排放量小于第二碳排放量,则说明预测有好的效果,按照预设增减量增大预测时长;如果第一碳排放量大于或等于第二碳排放量,则说明预测效果不好,按照预设增减量减小预测时长,增加深度学习模型训练的样本量;经过第一预设时间后,重新执行资源预测深度学习模型构建步骤、资源预测步骤、任务预先调到资源的步骤。
105.存储资源预测的步骤
106.预设调度条件为高于预设值。所述预设类型的资源为存储资源。所述预设类型的任务为数据休眠任务。
107.计算资源预测调度的步骤
108.预设调度条件为低于预设值。所述预设类型的资源为计算资源。所述预设类型的任务为计算任务。
109.i/o资源预测调度的步骤
110.预设调度条件为低于预设值。所述预设类型的资源为i/o资源。所述预设类型的任务为数据读取任务。
111.网络资源预测调度的步骤
112.预设调度条件为低于预设值。所述预设类型的资源为网络资源。所述预设类型的任务为数据传输任务。
113.3医康养生态系统
114.医康养系统生态化步骤:医康养系统执行任务时采用上述步骤,则形成医康养生态系统。
115.4现代服务业生态系统
116.现代服务业系统生态化步骤:现代服务业系统执行任务时采用上述步骤,则形成现代服务业生态系统。
117.三、本发明的第二优选实施例
118.低碳的大数据人工智能方法解决了数据量越大消耗的存储和计算资源越多,进而消耗的电量越多的问题。低碳的大数据首先采用需求驱动的处理策略,有用才处理,无用就休眠;其次采用预先计算技术,利用空闲资源对未来可能用得到的数据进行提前处理。
119.预先休眠的步骤:(1)训练和测试过程。获取多对有一定时间间隔的相邻时间段内的数据休眠任务,例如时间间隔预设为ttsleep1、ttsleep2,ttsleep1、ttsleep2大于或者等于0,n对t0i至t0i+ttsleep1内的数据休眠任务、t0i+ttsleep1至t0i+ttsleep1+ttsleep2内的数据休眠任务(i=1~n),将t0i至t0i+ttsleep1内的数据休眠任务、t0i+ttsleep1至t0i+ttsleep1+ttsleep2内的数据休眠任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到数据休眠任务预测深度学习模型。(2)数据休眠过程。获取当前时间tx,将tx-ttsleep1至tx内的数据休眠任务作为数据休眠任务预测深度学习模型的输入,将数据休眠任务预测深度学习模型的输出作为tx至tx+ttsleep2内的数据休眠任务。如果当前时间没有超过tx+ttsleep2且所述数据休眠任务涉及到的数据不在使用状态且存在空闲的资源可以执行所述数据休眠任务,则调度执行所述数据休眠任务。数据休眠指的是将数据从内存移入外存,从而可以释放内存用于更为活跃的数据。
120.获取采用当前预先休眠方法之前的数据存取效率psleep1,当前预先休眠方法之后的数据存取效率psleep2,如果psleep1大于或等于psleep2,则按照预设增减量减小ttsleep2,如果psleep1小于psleep2,则按照预设增减量增大ttsleep2。
121.预先数据读取的步骤:(1)训练和测试过程。获取多对有一定时间间隔的相邻时间段内的数据读取任务,例如时间间隔预设为ttread1、ttread2,ttread1、ttread2大于或者等于0,n对t0i至t0i+ttread1内的数据读取任务、t0i+ttread1至t0i+ttread1+ttread2内的数据读取任务(i=1~n),将t0i至t0i+ttread1内的数据读取任务、t0i+ttread1至t0i+ttread1+ttread2内的数据读取任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到数据读取任务预测深度学习模型。(2)数据读取过程。获取当前时间tx,将tx-ttread1至tx内的数据读取任务作为数据读取任务预测深度学习模型的输入,将数据读取任务预测深度学习模型的输出作为tx至tx+ttread2内的数据读取任务。如果当前时间没有超过tx+ttread2且存在空闲的资源可以执行所述数据读取任务,则调度执行所述数据读取任务。
122.获取采用当前预先数据读取方法之前的数据存取效率pread1,当前预先数据读取方法之后的数据存取效率pread2,如果pread1大于或等于pread2,则按照预设增减量减小ttread2,如果pread1小于pread2,则按照预设增减量增大ttread2。
123.预先计算的步骤:(1)训练和测试过程。获取多对有一定时间间隔的相邻时间段内的数据计算任务,例如时间间隔预设为ttcompute1、ttcompute2,ttcompute1、ttcompute2大于或者等于0,n对t0i至t0i+ttcompute1内的计算任务、t0i+ttcompute1至t0i+ttcompute1+ttcompute2内的计算任务(i=1~n),将t0i至t0i+ttcompute1内的计算任务、t0i+ttcompute1至t0i+ttcompute1+ttcompute2内的计算任务分别作为深度学习模型的输
入和输出,对深度学习模型进行训练和测试,得到计算任务预测深度学习模型。(2)计算过程。获取当前时间tx,将tx-ttcompute1至tx内的计算任务作为计算任务预测深度学习模型的输入,将计算任务预测深度学习模型的输出作为tx至tx+ttcompute2内的计算任务。如果当前时间没有超过tx+ttcompute2且存在空闲的资源可以执行所述计算任务,则调度执行所述计算任务。
124.获取采用当前预先计算方法之前的数据存取效率pcompute1,当前预先计算方法之后的数据存取效率pcompute2,如果pcompute1大于或等于pcompute2,则按照预设增减量减小ttcompute2,如果pcompute1小于pcompute2,则按照预设增减量增大tcompute2。
125.预先数据传输的步骤(数据传输包括从网络传输):(1)训练和测试过程。获取多对有一定时间间隔的相邻时间段内的数据传输任务,例如时间间隔预设为tttrans1、tttrans2,tttrans1、tttrans2大于或者等于0,n对t0i至t0i+tttrans1内的数据传输任务、t0i+tttrans1至t0i+tttrans1+tttrans2内的数据传输任务(i=1~n),将t0i至t0i+tttrans1内的数据传输任务、t0i+tttrans1至t0i+tttrans1+tttrans2内的数据传输任务分别作为深度学习模型的输入和输出,对深度学习模型进行训练和测试,得到数据传输任务预测深度学习模型。(2)数据传输过程。获取当前时间tx,将tx-tttrans1至tx内的数据传输任务作为数据传输任务预测深度学习模型的输入,将数据传输任务预测深度学习模型的输出作为tx至tx+tttrans2内的数据传输任务。如果当前时间没有超过tx+tttrans2且存在空闲的资源可以执行所述数据传输任务,则调度执行所述数据传输任务。
126.获取采用当前预先数据传输方法之前的数据存取效率ptrans1,当前预先数据传输方法之后的数据存取效率ptrans2,如果ptrans1大于或等于ptrans2,则按照预设增减量减小tttrans2,如果ptrans1小于ptrans2,则按照预设增减量增大tttrans2s。
127.通过预先休眠、数据读取、计算、数据传输的方式,可以利用空闲资源尽早地执行将来可能需要执行的任务,这样有三方面的好处,第一个方面充分利用了当前的空闲资源,提高了资源的利用率,第二个方面能够提前完成将来任务,从而使得该任务在将来如果真的需要执行时,则可以直接得到结果,从而极大提高了将来任务的执行速度。
128.以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,则对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1