一种基于深度特征进行鲁棒点云配准的无监督方法
1.本发明涉及物体三维重建和定位,具体是一种基于深度特征进行鲁棒点云配准的无监督方法。
背景技术:
2.点云配准是估计两个点云对齐的刚性变换的问题。它在自动驾驶、运动和姿态估计、三维重建、同时定位和映射(slam)以及增强现实等各个领域都有许多应用。
3.最近,一些基于深度学习(deep learning,简称dl)的方法被提出来处理大旋转角度。(y.wang and j.m.solomon,“deep closest point:learning representations for point cloud registration,”in proceedings of the ieee international conference on computer vision(iccv),2019,pp.3523
–
3532.)(y.aoki,h.goforth,r.a.srivatsan,and s.lucey,“pointnetlk:robust&efficient point cloud registration using pointnet,”in proceedings of the ieee conference on computer vision and pattern recognition(cvpr),2019,pp.7163
–
7172)(v.sarode,x.li,h.goforth,y.aoki,r.a.srivatsan,s.lucey,and h.choset,“pcrnet:point cloud registration network using pointnet encoding,”arxiv preprint arxiv:1908.07906,2019.)(x.huang,g.mei,and j.zhang,“feature-metric registration:a fast semi-supervised approach for robust point cloud registration without correspondences,”in proceedings of the ieee conference on computer vision and pattern recognition(cvpr),2020,pp.11 366
–
11 374.)
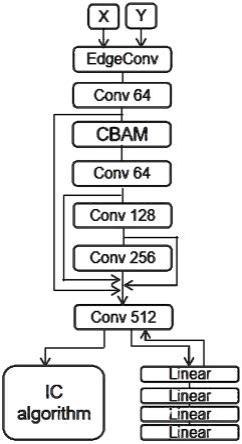
4.粗略地说,它们可以分为两类:依赖于基本事实对应或类别标签的监督方法和非监督方法。深度最近点(deep nearest point,简称dcp)通过奇异值分解(singular value decomposition,简称svd)计算刚性变换,其中通过学习软匹配映射构建对应关系。pointnetlk使用经典的对齐技术,如lucas-kanade(lk)算法来对齐pointnet特征,对训练中看不到的形状产生良好的泛化能力。然而,它们依赖于大量的配准标签数据,这使得该算法不实用,因为3d配准标签非常消耗劳动力。相比之下,从没有地面真实对应的未标记点云数据实现配准是一个重大的挑战。pcrnet通过用多层感知器替换lucas-kanade模块,缓解了pointnetlk中所示的姿态偏差。pcrnet直接从源点云和目标点云的串联全局描述符中恢复转换参数。fmr-net采用编码器-解码器任务实现无监督框架,同时通过最小化特征度量投影误差来实现配准。虽然这些方法展示了无监督学习的更突出的优势,但它们主要依赖全局表示的深度特征,而忽略了局部表示的深度特征。从而没有完全充分利用点云的深度特征进行配准,没有让配准效果达到完美。
技术实现要素:
5.本发明的目的是针对现有技术中存在的不足,而提供一种基于深度特征进行鲁棒点云配准的无监督方法。这种方法是一种无监督网络,通过结合全局和局部的高级特征来
学习提取深度特征,以无监督的方式训练配准框架,并且这个方法不需要对点对应进行昂贵的计算,在精度、初始化鲁棒性和计算效率方面具有很大的优势。
6.实现本发明目的的技术方案是:
7.一种基于深度特征进行鲁棒点云配准的无监督方法,包括如下步骤:
8.1)获取点云数据:获取待配准的点云数据,在点云表面均匀采样1024个点数据;
9.2)转换:将得到的两幅点云的采样数据类型转换为张量,张量大小为1024
×
3,然后输入到深度学习框架中;
10.3)特征提取:深度学习框架中编码器模块对输入的张量进行点云深度特征提取,最终输出表示点云深度特征的一维张量,具体过程如下:
11.3-1)对输入的张量1024
×
3经过edgeconv模块,将每一点作为中心点来表征其与各个邻点的边特征,再将这些特征聚合从而获得该点的新表征,即通过构建每个顶点的领域获取点云的局部特征,具体步骤为:
12.h
θ
(xi,xj)=h
θ
(xi,x
j-xi)
ꢀꢀꢀꢀ
(1),
13.其中xi在顶点集合x={x1,...xn}∈rf中,f表示神经网络某一层输出的点的特征空间维度信息,接着再送入一个感知机得到边特征:
14.e'
ijm
=relu(θm·
(x
j-xi)+φm·
xi)
ꢀꢀꢀꢀ
(2),
15.其中:
16.θ=(θ1,...,θm,φ1...,φm)
ꢀꢀꢀꢀ
(3),
17.θ为可学习参数,接着聚合各邻边的特征:
[0018][0019]
其中表示聚合操作,ω表示以点xi为中心的构成邻边的点对集合,具体聚合操作为:
[0020][0021]
最后在edgeconv模块输出张量的大小为6
×
1024
×
20并输入下一卷积层;
[0022]
3-2)对得到局部特征的张量进行五次卷积,第一次卷积经过64个二维大小为1的卷积核的卷积层输出张量大小为64
×
1024
×
20;
[0023]
3-3)受注意力机制对深度学习效果提升显著的特点启发,将第一层的输出结果接入cbam注意力模块,对各通道以及空间的重要性进行加权,并同理依次经过64,128,256大小的卷积层;
[0024]
3-4)将前四层的输出张量拼接且修改张量大小为512
×
1024
×
1,再进入512个二维大小为1的卷积核进行卷积并修改维度得到张量大小为512
×
1024,使用flatten函数将张量打平输出张量大小为512,由此得到包含了局部与全局描述符的深度特征;
[0025]
4)点云配准:对两幅点云进行配准,即求出一个刚性变换矩阵g∈se(3),分为旋转矩阵r∈so(3)与平移矩阵t∈r3,然后求解出最小化目标函数f(g(r,t)):
[0026][0027]
其中ψ:r3×n→rk
为encoder学习到的特征提取函数,k是特征维度;
[0028]
4-1)g(r,t)看作一个特殊李群,用指数映射表示如下:
[0029][0030]
其中,t是指数映射g的生成器,ε是一个李代数,通过指数映射到变换矩阵g上;
[0031]
4-2)点云配准问题描述为φ(pt)=φ(g
·
pt),求解矩阵g即为通过对李代数ε求导得到g的导数,从而直接调整李代数ε来间接的优化最佳变换矩阵g和最小化两点云的特征空间投影误差进行点云配准任务,受(ic)公式的启发,先对φ(pt)=φ(g
·
pt)进行逆变换并将其右侧线性化:
[0032][0033]
4-3)转换估计迭代运行计算增量ε,通过运行逆合成(ic)算法来估计每个步骤的ε:
[0034]
ε=(j
t
j)-1
(j
t
δ)
ꢀꢀꢀꢀ
(9),
[0035]
其中δ=φ(ps)-φ(p
t
)为两点云特征空间投影误差,是投影误差δ相对于变换参数ε的雅可比矩阵;
[0036]
4-4)为了有效的计算雅克比矩阵,采用了不同的有限梯度替代传统的随机梯度法来计算雅克比矩阵:
[0037][0038]
其中ti为计算期间变换参数的无穷小扰动,当ti设定为固定值时会得到比较好的效果,为ti设置了三个角参数用于旋转和三个扰动参数用于平移,将ti大小设置为2*e-2
;
[0039]
4-5)通过迭代运算公式(9),对变换矩阵进行优化缩短源点云在特征空间上与样板点云的投影距离:
[0040]
δg
·
ps→
psꢀꢀꢀꢀ
(11),
[0041]
其中为公式(9)计算出变换参数ε得到的变换矩阵,经过多次迭代,不断变换ps与p
t
配准,最终输出最佳变换矩阵g
est
:
[0042]gest
=δgn·
...
·
δg1δg0ꢀꢀꢀꢀ
(12),
[0043]
5)训练:为了实现该深度学习框架以无监督的方式进行训练,引入了一个由四个全连接层组成的解码器;同时选择了relu作为前三层的激活函数,tanh函数为第四层的激活函数;
[0044]
5-1)在无监督的情况下,利用变换后的源点云和目标点云之间的对齐误差而不是地面真值变换来进行模型训练,采用一个鲁棒的损失函数:
[0045][0046]
其中,p
t
∈θ是从单位平方[0,1]2中采样的一组点,x是点云特征,是卷积层参数中的第i个分量,φ是原始输入的三维点。
[0047]
这种方法精度、计算效率高,初始化鲁棒性强,不需要对点对应进行昂贵的计算。
附图说明
[0048]
图1为实施例中点云配准网络架构示意图;
[0049]
图2为实施例进行瓶子的三维点云配准的示意与效果图;
[0050]
图3为实施例进行马桶的三维点云配准的示意与效果图;
[0051]
图4为实施例进行有噪声手机的三维点云配准的示意与效果图;
[0052]
图5为实施例进行真实室内场景的三维点云配准的示意与效果图;
[0053]
图6为实施例进行斯坦福3dmatch中armadillo的点云配准的示意与效果图。
具体实施方式
[0054]
下面结合附图及具体实施例对发明作进一步的详细描述,但不是对本发明的限定。
[0055]
实施例:
[0056]
参照图1,一种基于深度特征进行鲁棒点云配准的无监督方法,包括如下步骤:
[0057]
1)获取点云数据:获取待配准的点云数据,在点云表面均匀采样1024个点数据;
[0058]
2)转换:将得到的两幅点云的采样数据类型转换为张量,大小为1024
×
3,然后输入到深度学习框架中;
[0059]
3)特征提取:深度学习框架中编码器模块对输入的张量进行点云深度特征提取,最终输出表示点云深度特征的一维张量,具体过程如下:
[0060]
3-1)与其他依靠全局描述符的无监督方法不同的是,本例方法再无监督训练方式的基础上继续关注局部特征,对输入的张量1024
×
3经过edgeconv模块,将每一点作为中心点来表征其与各个邻点的边特征,再将这些特征聚合从而获得该点的新表征,即通过构建每个顶点的领域获取点云的局部特征,具体步骤为:
[0061]hθ
(xi,xj)=h
θ
(xi,x
j-xi)
ꢀꢀꢀꢀ
(1),
[0062]
其中xi在顶点集合x={x1,...xn}∈rf中,f表示神经网络某一层输出的点的特征空间维度信息,接着再送入一个感知机得到边特征:
[0063]
e'
ijm
=relu(θm·
(x
j-xi)+φm·
xi)
ꢀꢀꢀꢀ
(2),
[0064]
其中:
[0065]
θ=(θ1,...,θm,φ1...,φm)
ꢀꢀꢀꢀ
(3),
[0066]
θ为可学习参数,接着聚合各邻边的特征:
[0067][0068]
其中表示聚合操作,ω表示以点xi为中心的构成邻边的点对集合,具体聚合操作为:
[0069][0070]
最后在edgeconv模块输出张量的大小为6
×
1024
×
20并输入下一卷积层;
[0071]
3-2)对得到局部特征的张量进行五次卷积,第一次卷积经过64个二维大小为1的卷积核的卷积层输出张量大小为64
×
1024
×
20;
[0072]
3-3)受注意力机制对深度学习效果提升显著的特点启发,将第一层的输出结果接入cbam注意力模块,对各通道以及空间的重要性进行加权,并同理依次经过64,128,256大
小的卷积层;
[0073]
3-4)将前四层的输出张量拼接且修改张量大小为512
×
1024
×
1,再进入512个二维大小为1的卷积核进行卷积并修改维度得到张量大小为512
×
1024,使用flatten函数将张量打平输出张量大小为512,由此得到包含了局部与全局描述符的深度特征;
[0074]
4)点云配准:对两幅点云进行配准,即求出一个刚性变换矩阵g∈se(3),分为旋转矩阵r∈so(3)与平移矩阵t∈r3,然后求解出最小化目标函数f(g(r,t)):
[0075][0076]
其中ψ:r3×n→rk
为encoder学习到的特征提取函数,k是特征维度;
[0077]
4-1)g(r,t)看作一个特殊李群,用指数映射表示如下:
[0078][0079]
其中,t是指数映射g的生成器,ε是一个李代数,通过指数映射到变换矩阵g上;
[0080]
4-2)点云配准问题描述为φ(pt)=φ(g
·
pt),求解矩阵g即为通过对李代数ε求导得到g的导数,从而直接调整李代数ε来间接的优化最佳变换矩阵g和最小化两点云的特征空间投影误差进行点云配准任务,受(ic)公式的启发,先对φ(pt)=φ(g
·
pt)进行逆变换并将其右侧线性化:
[0081][0082]
4-3)转换估计迭代运行计算增量ε,通过运行逆合成(ic)算法来估计每个步骤的ε:
[0083]
ε=(j
t
j)-1
(j
t
δ)
ꢀꢀꢀꢀ
(9),
[0084]
其中δ=φ(ps)-φ(p
t
)为两点云特征空间投影误差,是投影误差δ相对于变换
[0085]
参数ε的雅可比矩阵;
[0086]
4-4)为了有效的计算雅克比矩阵,采用了不同的有限梯度替代传统的随机梯度法来计算雅克比矩阵:
[0087][0088]
其中ti为计算期间变换参数的无穷小扰动,当ti设定为固定值时会得到比较好的效果,为ti设置了三个角参数用于旋转和三个扰动参数用于平移,将ti大小设置为2*e-2
;
[0089]
4-5)通过迭代运算公式(9),对变换矩阵进行优化缩短源点云在特征空间上与样板点云的投影距离:
[0090]
δg
·
ps→
psꢀꢀꢀꢀ
(11),
[0091]
其中为公式(9)计算出变换参数ε得到的变换矩阵,经过多次迭代,不断变换ps与p
t
配准,最终输出最佳变换矩阵g
est
:
[0092]gest
=δgn·
...
·
δg1δg0ꢀꢀꢀꢀ
(12),
[0093]
5)训练:为了实现该深度学习框架以无监督的方式进行训练,引入了一个由四个全连接层组成的解码器;同时选择了relu作为前三层的激活函数,tanh函数为第四层的激活函数,层数如图1所示;
[0094]
5-1)在无监督的情况下,利用变换后的源点云和目标点云之间的对齐误差而不是地面真值变换来进行模型训练,采用一个鲁棒的损失函数:
[0095][0096]
其中,p
t
∈θ是从单位平方[0,1]2中采样的一组点,x是点云特征,是卷积层参数中的第i个分量,φ是原始输入的三维点。
[0097]
为了说明该深度学习框架的有效性,采用应用最为广泛的modelnet40作为预训练集,modelnet40是一个具有12311个cad模型且包含40个对象类别的数据集,将该深度学习框架在modelnet40前20类别进行训练,并在后20个类别进行测试。在训练与测试过程中,通过随机生成刚性变换矩阵g得到地面真值变换矩阵g
gt
,同时使得源点云经过g生成目标点云。任意选择轴,将g中的旋转分量取值在[0,45]度范围内,平移分量在[-0.5,0.5]范围内初始化,以真实旋转平移矩阵g
gt
和预测旋转平移矩阵g
est
之间的旋转分量与平移分量的均方误差(mean squared error,简称mse),均方根误差(root mean squard error,简称rmse)和绝对平均误差(mean absolute error,简称mae)作为评价指标,他们的值越小代表配准的精度越高。同时实验中角度的度量单位为度,运行配准时间的单位为秒。结果如下表所示:
[0098][0099]
具体实例如图2-图6所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1