一种基于分离度的小样本半监督聚类方法
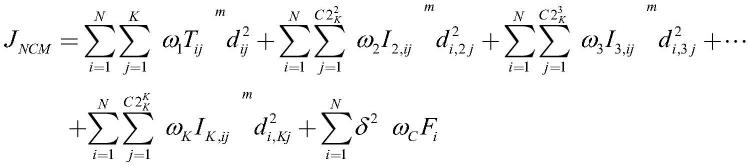
1.本发明属于计算机仿真与方法优化技术领域,尤其涉及一种基于分离度的小样本半监督聚类方法。
背景技术:
2.目标检测和目标分类一直是人们研究的重点问题,当目标先验知识少、信息一致性低和干扰信息严重等问题时,基于学习类的方法并不适用。
3.在此种条件下,当目标与非目标纹理、结构等特征相似度较高时,传统的目标分类和目标鉴别方法并不能很好的将目标分离出来,也就造成了目标的检测性能低下等问题。
4.在无训练情况下,目标检测通常采用自相似比较方法或无监督/半监督分类算法。
5.采用基于欧式空间距离的负指数函数作为相似性度量,对浓密计算尺度不变特征进行判定,实现对汽车、人脸和一般目标的检测。采用矩阵余弦相似度基于单样本在待检测图像中寻找相似性匹配项,实现目标检测。
6.聚类算法是无监督学习的典型案例,其目的是把相似的东西聚在一起。常用的聚类算法有基于距离的模糊c均值(fuzzy c-means,fcm)聚类算法、证据c均值(evidential c-means,ecm)聚类算法、中智模糊(neutrosophic c-means,ncm)聚类算法和基于密度的dbscan聚类算法等。聚类算法无需训练、技术简单,但sar图像中存在与目标纹理非常相似的杂波等干扰信息,直接使用聚类算法实现目标的自动分类,性能不高。
7.半监督学习主要基于聚类模型和流形模型来建立未知样本、目标和已知样本之间的联系。聚类假设与人的直观认识相符合,因此出现了很多基于聚类假设的分类算法。如tsvm算法通过迭代方法为未标记样本找到合适的分类标记。聚类假设主要关注整体特性,流形假设主要考虑模型的局部特性。如基于核范数的二维局部保持投影(nuclear norm-based two-dimensional locality preserving projections,nn-2dlpp)方法通过低阶学习恢复噪声数据矩阵去除数据中的噪声,然后将学习到的干净数据点投影到新的子空间上,并在此投影子空间中尽可能地保持同一类数据点之间的距离。
8.目前上述大部分方法的研究都是基于无噪声干扰的数据,直接在基于特征的目标分类中使用,目标检测性能较低。
技术实现要素:
9.本发明目的在于提供一种基于分离度的小样本半监督聚类方法,以解决上述的技术问题。
10.为解决上述技术问题,本发明的一种基于分离度的小样本半监督聚类方法的具体技术方案如下:
11.一种基于分离度的小样本半监督聚类方法,包括如下步骤:
12.步骤1:聚类中心计算:采用ncm算法进行聚类中心计算;
13.步骤2:分离度计算:在ncm聚类计算过程中调整两个类别的聚类中心,增强目标与
非目标的可分离性;
14.步骤3:非目标聚类中心确定:根据步骤1初步计算样本聚类中心,并在潜在目标中计算特征与样本聚类中心的分离度,将分离度最大的特征作为初始非目标聚类中心;
15.步骤4:参数计算:计算[t,i,f]元组的值,并更新目标与非目标的聚类中心;
[0016]
步骤5:类中心迁移:在参数迭代的过程中,将潜在目标聚类中心像样本聚类中心迁移,将远离样本中心的潜在目标作为非目标;
[0017]
步骤6:迭代计算:对于步骤3到步骤5进行迭代计算;
[0018]
步骤7:目标分离:根据样本中心,确定潜在目标是属于目标集群的确定度,与不属于目标集群的确定都f的比值来最终判定潜在目标是否为目标。进一步地,所述步骤1包括如下具体步骤:
[0019]
ncm使用一个元组[t,i,f]来描述成员值,其中t是属于一个集群的对象的确定度,f是不属于集群的对象的确定度,i是一个对象到边界集群的不确定度,ncm算法的目标函数表达式为:
[0020][0021]
其中,c={cj,j=1,2,
…
,k}是集群的集合,cj是集群j的中心,d
i,kj
表示从对象xi到所考虑的k簇中心的距离,ωi是加权系数,δ是检测非目标的给定距离,只选择最近的两个确定性聚类来考虑最大隶属度值,简化为:
[0022][0023]
其中,是从对象xi到两个簇中心的距离,这两个簇是距离中心最近的和第二近的簇,上式满足:
[0024][0025]
对象xi的成员元组[t
ij
,ii,fi]在迭代中更新并使得j
ncm
最小化,当成员值达到收敛时,迭代将中断,
[0026][0027]
其中,[t,i,f]三个成员值按如下方式迭代更新:
[0028][0029][0030]
进一步地,所述步骤2包括如下具体步骤:
[0031]
设目标x与非目标y的分离度s
xy
,在ncm聚类计算过程中调整两个类别的聚类中心,
增强目标与非目标的可分离性,分离度s
xy
为:
[0032][0033]
其中,d
xy
为类x和类y的类间方差;d(x)和d(y)为类内方差。
[0034]
进一步地,所述步骤4包括如下具体步骤:
[0035]
计算[t,i,f]元组的值,并更新目标与非目标的聚类中心
[0036][0037][0038]
进一步地,所述步骤5包括如下具体步骤:
[0039]
在参数迭代的过程中,将潜在目标聚类中心像样本聚类中心迁移,将远离样本中心的潜在目标作为非目标,其中,潜在目标与样本聚类中心的直接的距离通过分离度来计算,在类中心迁移过程中不计算离散点,并将其对应的潜在目标区域认定为非目标。
[0040]
进一步地,所述步骤6包括如下具体步骤:
[0041]
对于步骤3到步骤5进行迭代计算,当[t,i,f]满足下式要求式,判定达到达到收敛点,迭代停止,
[0042][0043]
进一步地,所述步骤6在迭代过程中,引入一个新的变量f
dp
作为离散点判断的基础,并迭代过程中计算出消除离散点后新对象集的聚类中心,此时,目标函数表达式和约束条件可以表示为:
[0044][0045][0046]
本发明的一种基于分离度的小样本半监督聚类方法具有以下优点:本发明针对传统无监督聚类和半监督聚类在目标分类、鉴别性能不佳的问题,发明了一种基于目标分离度的小样本半监督聚类方法,设定目标与非目标的分离度,并基于已知小样本在分离度的基础上进行迭代运算,实现了相似度较高的目标于非目标的精确分离,本发明采用了新型的算法框架提高了目标分类、鉴别的精确性。
附图说明
[0047]
图1为本发明的ncm聚类中心示意图;
[0048]
图2为本发明的将离散点分离后的计算所得聚类中心示意图;
[0049]
图3(a)为本发明实施例1的原始图;
[0050]
图3(b)为实施例1用圆圈标记潜在目标的sar潜在目标区域示意图;
[0051]
图4(a)为实施例1的ecm分类结果图;
[0052]
图4(b)为实施例1的fcm分类结果图;
[0053]
图4(c)为实施例1的ncm分类结果图;
[0054]
图4(d)为实施例1的本发明方法分类结果图;
[0055]
图5(a)为本发明实施例2的原始图;
[0056]
图5(b)为实施例2用圆圈标记潜在目标的sar潜在目标区域示意图;
[0057]
图6(a)为实施例2的ecm分类结果图;
[0058]
图6(b)为实施例2的fcm分类结果图;
[0059]
图6(c)为实施例2的ncm分类结果图;
[0060]
图6(d)为实施例2的本发明方法分类结果图。
具体实施方式
[0061]
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种基于分离度的小样本半监督聚类方法做进一步详细的描述。
[0062]
本发明采用基于分离的半监督聚类算法解决相似度较高的目标于非目标分类、鉴别等问题,方案步骤如下:
[0063]
步骤1:聚类中心计算。
[0064]
ncm使用一个元组[t,i,f]来描述成员值,其中t是属于一个集群的对象的确定度,f是不属于集群的对象的确定度,i是一个对象到边界集群的不确定度。ncm算法的目标函数表达式为:
[0065][0066]
其中,c={cj,j=1,2,
…
,k}是集群的集合,cj是集群j的中心。d
i,kj
表示从对象xi到所考虑的k簇中心的距离。ωi是加权系数,δ是检测非目标的给定距离。然而,随着集群数量的增加,需要大量的运算,时间消耗非常大。为了解决这个问题,建议只选择最近的两个确定性聚类来考虑最大隶属度值。因此,上式简化为:
[0067][0068]
其中,是从对象xi到两个簇中心的距离,这两个簇是距离中心最近的和第二近的簇。上式满足:
[0069][0070]
对象xi的成员元组[t
ij
,ii,fi]在迭代中更新并使得j
ncm
最小化。当成员值达到收敛时,迭代将中断。
[0071][0072]
其中,[t,i,f]三个成员值按如下方式迭代更新:
[0073][0074][0075]
步骤2:分离度计算。
[0076]
设目标x与非目标y的分离度s
xy
,在ncm聚类计算过程中调整两个类别的聚类中心,增强目标与非目标的可分离性。分离度s
xy
为:
[0077][0078]
其中,d
xy
为类x和类y的类间方差;d(x)和d(y)为类内方差。
[0079]
步骤3:非目标聚类中心确定。
[0080]
根据步骤1初步计算样本聚类中心,并在潜在目标中计算特征与样本聚类中心的分离度。将分离度最大的特征作为初始非目标聚类中心。
[0081]
由于有的非目标并不是一共类型,其中可能包含多样性的杂波,因此,在计算过程会犯下使得这两类样本点不参与聚类中心的计算,但是由于sar图像中杂波的多样性,“杂波”对聚类算法影响较大。如果直接对“目标-杂波”进行二分类,聚类中心偏差较大。如图1所示,无论将“目标-杂波”看作两类,或者将所有对象看作一类进行计算时,都存在聚类中心偏移问题。
[0082]
步骤4:参数计算。
[0083]
计算[t,i,f]元组的值,并更新目标与非目标的聚类中心
[0084][0085][0086]
步骤5:类中心迁移。
[0087]
在参数迭代的过程中,将潜在目标聚类中心像样本聚类中心迁移,将远离样本中心的潜在目标作为非目标。其中,潜在目标与样本聚类中心的直接的距离通过分离度来计算。在类中心迁移过程中不计算离散点,并将其对应的潜在目标区域认定为非目标。该方法使得聚类中心逐渐向目标迁移,并在聚类过程中逐步剔除潜在目标中杂波等非目标。
[0088]
步骤6:迭代计算。
[0089]
对于步骤3到步骤5进行迭代计算,当[t,i,f]满足下式要求式,判定达到达到收敛点,迭代停止。
[0090][0091]
需要注意的是,在迭代过程中,引入了一个新的变量f
dp
作为离散点判断的基础。并迭代过程中计算出消除离散点后新对象集的聚类中心。从图2可以看出,将离散点分离后的计算所得聚类中心相较于ncm方法更换为准确。
[0092]
此时,目标函数表达式和约束条件可以表示为:
[0093][0094][0095]
步骤7:目标分离。
[0096]
根据样本中心,确定潜在目标是属于目标集群的确定度,与不属于目标集群的确定都f的比值来最终判定潜在目标是否为目标。
[0097]
本发明技术方案的具体实施例
[0098]
为验证本发明所提出的基于分离度的半监督聚类算法的有效性,进行仿真验证。
[0099]
实施例一:坦克目标鉴别
[0100]
如图3(a)所示,实验场景包含13个坦克目标和一些灰度值较高的非目标。首先,基于全局cfar算法确定sar图像中灰度相对较高的潜在目标区域。在初步检测之后,如图3(b)所示,用圆圈标记包括总共26个潜在目标的sar潜在目标区域。
[0101]
根据cfar检测结果确定特征点后,分别使用fcm、ecm、ncm和本发明算法对潜在目标的特征向量进行分类。图4(a)-4(d)显示了这些聚类算法的分类结果,其中目标用圆圈标记。
[0102]
当使用ecm算法对潜在目标特征进行分类时,检测结果中存在漏报目标和虚警目标(见图4(a));当使用fcm算法对潜在目标特征进行分类时,检测结果中存在被检测为目标的非目标(见图4(b));当使用ncm算法进行目标检测时,参数k设置为1,即图像中只有一种目标,其他都是离散点,但结果中仍有漏检目标和虚警目标(见图4(c));当使用本发明方法进行分类时,检测结果优于ecm、fcm和ncm聚类算法,可以获得更准确的检测结果(见图4(d))。表1显示了具体的对比试验结果。
[0103]
表1不同方法的分类结果
[0104][0105]
实验表明,本发明方法能有效区分杂波等目标和非目标,在sar图像的目标检测中取得了良好的效果。
[0106]
实施例二:飞机目标鉴别
[0107]
本实验目标如图5(a)所示,原始sar图像的背景也包含许多高亮区域。初步检测结果包含15个突出显示的区域,使用cfar检测和尺寸特征检测,如图5(b)所示。
[0108]
本发明算法用于对潜在sar目标的特征进行聚类,并对飞机目标进行自动检测,如图6(a)-6(d)所示。当使用ecm、fcm和ncm算法对潜在目标特征进行分类时,检测结果中存在漏检目标和虚警目标(见图6(a)、6(b)、6(c));当使用ncm-1k方法进行分类时,检测结果优于ecm、fcm和ncm聚类算法,可以获得更准确的检测结果(见图6(d))。实验结果表明,在sar图像目标检测中,本发明提出的方法能够有效区分目标和非目标。
[0109]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱
离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1