基于自适应权重损失函数的风电机组叶片结冰检测方法
1.本发明属于风电机组状态检测领域,具体涉及一种基于自适应权重损失函数的风电机组叶片结冰检测方法。
背景技术:
2.叶片是风电机组能量转换的关键部件。在实际风电场中,由于风电机组为了更多的捕获风能而多分布在高海拔、高纬度等气候相对寒冷的地区,因而风电机组叶片易受降雪等低温天气的影响而出现结冰现象。叶片结冰会改变叶片的翼型从而降低风能捕获能力同时会增大叶片转动所需的能量,造成功率损耗。此外叶片结冰所产生的附冰层会改变叶片的模态参数,若不及时进行除冰作业会诱发叶片的断裂,因而及时准确的对风电机组叶片进行结冰状态检测对于风电机组的健康运行具有重要意义。
3.由于叶片结冰状态检测的重要性,研究人员提出了多种状态检测方案,包括声发射监测、超声波检测以及数据采集与监视控制(scada)系统监测等。其中scada系统利用在风电机组装机时就布置在各处的传感器实时的收集风电机组多尺度运行状态信息,因而可以对包括叶片在内的各子系统的关键部件进行系统的、全面的状态监测,此外由于scada系统在风电机组装机时随机组一同安装,因而具有运行成本低的优点。但是,利用scada系统实现风电机组叶片结冰状态检测仍存在一些难点,其中之一在于,对于一个已经投入运营的风电机组,其包括叶片在内的各部件正常运行时段必定远远长于其结冰状态时段,所以scada系统通过传感器所收集到的风电机组叶片运行数据集中结冰数据占比较小,正常数据占比较高,具有典型的类别不平衡性,增加了相关状态检测模型从数据集中较为准确地对结冰数据进行分类的难度。为了降低利用scada系统进行叶片结冰状态检测的难度,需对scada系统的不平衡数据集采取合适的应对策略以增强模型的分类性能。目前不平衡数据集的应对策略主要包括数据层面的重采样和模型层面的重加权,其中数据层面的重采样的思想是对数据集本身的分布进行改变,降低不平衡性,具体方法包括欠采样和过采样等,欠采样是仅取用scada数据集中的一部分而丢弃另一部分,这种方式易造成关键信息的丢失,过采样则是针对少数类别数据进行重采样处理以降低不平衡性,这种方式会造成信息冗余,增加模型训练难度。模型层面的重加权是指通过在模型的训练阶段,设计损失函数以调整数据集中不同类别数据被分配的权重以增强对某一类数据的识别能力,传统的损失函数包括标准交叉熵、平衡交叉熵、focal_loss以及代价敏感损失函数等。
4.由于损失函数可以在不对scada系统的原始运行数据进行过采样和欠采样处理的前提下增强状态检测模型对于少数类样本的识别,因而也越来越多的被应用在风电机组叶片结冰状态检测领域。但是传统的损失函数诸如平衡交叉熵、focal_loss等,需要手动设置超参数为各类数据分配权重,且对于不同的结冰状态检测模型,为了达到更好的分类效果需要不断的更改超参数,这增大了模型优化难度;此外,标准交叉熵和代价敏感损失函数在叶片结冰状态检测中对于模型的优化效果往往不够理想。为了降低模型优化难度,同时增强状态检测模型对于scada系统不平衡数据集的分类效果,应当设计一种不需手动设置超
参数,而是自适应的为各类数据分配权重且能达到较优的分类效果的损失函数。
技术实现要素:
5.针对上述传统的损失函数的缺点以及对于新的损失函数相关要求,本发明要设计出一种可以根据scada系统叶片结冰数据集中结冰数据和正常数据的不同占比自适应的为相应数据分配权重的损失函数,改善叶片结冰检测模型对具有显著不平衡性的数据集的分类性能,进而评价叶片结冰状态。
6.为了达到上述目的,本发明是通过以下方案实现的:基于自适应权重损失函数的风电机组叶片结冰检测方法。该方案包括如下内容:
7.步骤一:scada系统获取风电机组叶片结冰数据,并根据数据不同类别标记标签,其中正常数据标记为标签0、结冰数据标记为标签1、无效数据标记为标签-1。其中,所述无效数据为机组在停机维护期间scada系统所记录的数据,将其直接从叶片结冰数据集中剔除,剔除无效数据后的结冰数据集称为结冰检测数据集。进一步,将结冰检测数据集划分为训练集、验证集和测试集。
8.步骤二:建立基于时空注意力网络的叶片结冰状态检测模型,所述的时空注意力网络是指以全卷积网络(fcnn)和长短时记忆网络(lstm)的并联结构为基础的模型。
9.步骤三:构建自适应权重损失函数,对步骤二得到的叶片结冰状态检测模型进行训练。利用构建的损失函数为训练集中结冰数据和正常数据所分别自适应分配的权重,增强模型对于结冰数据的分类能力,从而提升模型在测试集上的总体分类性能。
10.步骤四:利用结冰检测数据集的测试集,对步骤三中训练好的模型分类效果进行评估。
11.步骤二包括如下子步骤。
12.(2.1)搭建时间注意力模块,该模块包含有全局平均池化层、门控循环神经网络(gru)网络以及全连接层,计算结冰检测数据集各采样时刻所对应数据的权重。
13.(2.2)搭建空间注意力模块,该模块由全局平均池化层、多层卷积和最大池化层以及全连接层组成,计算结冰检测数据集各空间变量的权重。
14.(2.3)构建lstm和fcnn并联的网络,将时空注意力机制的运算结果输入到该并联网络,分别提取结冰检测数据集的时间相关性和空间相关性,然后将并联网络的运算结果进行拼接后利用softmax分类器进行分类输出。
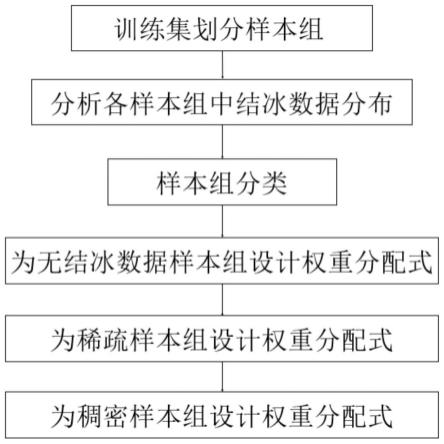
15.进一步的,将所述步骤三分为如下子步骤。
16.(3.1)将结冰检测数据集的训练集划分成多个批次的数据,划分出的批次称为样本组。将训练集按样本组导入模型进行训练。
17.(3.2)分析各样本组中的结冰数据分布,对于包含有结冰数据的样本组,求取单个样本组中结冰数据个数的平均值,具体为:
[0018][0019]
式中x为所有包含结冰数据的样本组中该类数据的总数,n为含有结冰数据样本组的组数。
[0020]
(3.3)将样本组根据其所包含的结冰数据个数进行分类,共分为无结冰数据样本
组、稀疏样本组以及稠密样本组等3类。其中无结冰数据冰样本组仅含正常数据,稀疏样本组包含结冰数据个数小于步骤(3.2)中所计算的平均值a,稠密样本组包含的结冰数据个数高于平均值a。
[0021]
(3.4)为无结冰数据样本组设计权重分配式,具体为:
[0022][0023]
式中,m表示单个样本组中正常数据的个数。
[0024]
将β代入到损失函数的公式,具体为:
[0025]
loss=-βlog(p
t
)
ꢀꢀ
(3)
[0026]
p
t
的表达式为:
[0027][0028]
式中p表示数据被预测为结冰状态的概率。
[0029]
(3.5)为稀疏样本组设计权重分配式,具体为:
[0030][0031]
式中,m和n分别表示单个样本组中正常数据和结冰数据的个数,损失函数的公式同(3)。
[0032]
(3.6)为稠密样本组设计权重分配式。
[0033]
引入自适应调节系数λ和γ,具体表达式为:
[0034][0035][0036]
m和n分别表示单个样本组中正常数据和结冰数据的个数。
[0037]
稠密样本组的权重分配公式为:
[0038][0039]
式中,λ和γ为自适应调节系数,损失函数的公式同(3)。
[0040]
由于采用如上步骤设计方案,本发明相较于传统的损失函数有如下优势:
[0041]
该损失函数根据结冰状态检测模型在训练时对训练集所划分出的样本组自适应的为不同类别数据赋予权重,不需手动设置超参数,降低了模型的优化难度。由于为结冰类别数据自适应的分配了较高的权重,因而该损失函数对结冰数据的识别性能高于传统的损失函数。自适应的为不同类数据分配不同的权重的方案使得该损失函数对于不同的状态检测模型不必重新调整超参数,自适应性较好。
附图说明
[0042]
图1为引入注意力机制的fcnn和lstm并联网络结构示意图;
[0043]
图2为构建自适应权重损失函数的流程图;
[0044]
图3为在模型训练时叶片结冰数据集的训练集所划分出的各样本组结冰数据分布;
[0045]
图4为在测试集上,利用本发明所涉及的自适应权重损失函数对叶片结冰状态检测模型的优化效果同其他传统的损失函数相比较示意图。
具体实施方式
[0046]
为使本领域的相关技术人员更好的理解该发明以及其优势,以下结合附图和具体叶片结冰数据集对本发明的实现方式做进一步阐述。此处所描述的具体数据集仅仅用以解释本发明,并不用于限定本发明。
[0047]
本发明的具体实现步骤如下:
[0048]
步骤一:scada系统获取风电机组叶片结冰数据,并根据数据不同类别标记标签,其中正常数据标记为标签0、结冰数据标记为标签1、无效数据标记为标签-1。其中,所述无效数据为机组在停机维护期间scada系统所记录的数据,将其直接从叶片结冰数据集中剔除,剔除无效数据后的结冰数据集称为结冰检测数据集。进一步,将结冰检测数据集划分为训练集、验证集和测试集。
[0049]
步骤二:建立基于时空注意力网络的叶片结冰状态检测模型,所述的时空注意力网络是指以全卷积网络(fcnn)和长短时记忆网络(lstm)的并联结构为基础的模型。该步骤包含有如下子步骤:
[0050]
(2.1)搭建时间注意力模块,该模块包含有全局平均池化层、门控循环神经网络(gru)网络以及全连接层,计算结冰检测数据集各采样时刻所对应数据的权重。
[0051]
(2.2)搭建空间注意力模块,该模块由全局平均池化层、多层卷积和最大池化层以及全连接层组成,计算结冰检测数据集各空间变量的权重。
[0052]
(2.3)构建lstm和fcnn并联的网络,将时空注意力机制的运算结果输入到该并联网络,分别提取结冰检测数据集的时间相关性和空间相关性,然后将并联网络的运算结果进行拼接后利用softmax分类器进行分类后输出。
[0053]
步骤三:构建自适应权重损失函数,对步骤二得到的叶片结冰状态检测模型进行训练。利用构建的损失函数为训练集中结冰数据和正常数据所分别自适应分配的权重,增强模型对于结冰数据的分类能力,从而提升模型在测试集上的总体分类性能。
[0054]
步骤三具体分为如下子步骤:
[0055]
(3.1)将结冰检测数据集的训练集划分成多个批次的数据,划分出的批次称为样本组。将训练集按样本组导入模型进行训练。
[0056]
(3.2)分析各样本组中的结冰数据分布,对于包含有结冰数据的样本组,求取单个样本组中结冰数据个数的平均值,具体为:
[0057][0058]
式中,x为所有包含结冰数据的样本组中该类数据的总数,n为所有包含有结冰数
据的样本组的组数。
[0059]
(3.3)将样本组根据其所包含的结冰数据个数进行分类,共分为无结冰样数据本组、稀疏样本组以及稠密样本组等3类。其中无结冰数据样本组仅含正常数据,稀疏样本组包含结冰数据个数小于步骤(3.2)中所计算的平均值a,稠密样本组包含的结冰数据个数高于平均值a。
[0060]
(3.4)为无结冰样数据本组设计权重分配式,具体为:
[0061][0062]
式中,m表示单个样本组中正常数据的个数。
[0063]
将β代入到损失函数的公式,具体为:
[0064]
loss=-βlog(p
t
)
ꢀꢀ
(3)
[0065]
其中p
t
表达式为:
[0066][0067]
式中p表示数据被预测为结冰状态的概率。
[0068]
(3.5)为稀疏样本组设计权重分配式,具体为:
[0069][0070]
式中,m和n分别表示单个样本组中正常数据和结冰数据的个数。损失函数的公式同(3)。
[0071]
(3.6)为稠密样本组设计权重分配式。
[0072]
引入自适应调节系数λ和γ,具体表达式为:
[0073][0074][0075]
m和n分别表示单个样本组中正常数据和结冰数据的个数。
[0076]
稠密样本组权重分配公式为:
[0077][0078]
式中,λ和γ为自适应调节系数,损失函数的公式同(3)。
[0079]
步骤四:利用结冰检测数据集的测试集,对步骤三中训练好的模型分类效果进行评估。
[0080]
实施例1
[0081]
结合具体的风电机组叶片结冰数据集验证本发明所涉及的损失函数的优势。该数据集是由中华人民共和国工业信息化部所提供的内蒙古某风电场中一台风电机组的叶片
结冰数据集。该数据集已被广泛的应用于叶片结冰状态检测领域,用于验证各种状态检测模型的分类性能。
[0082]
将上述叶片结冰数据集按照上述的步骤一进行标签标记、删除无效数据等预处理,将预处理后的数据集称为结冰检测数据集。进一步,将结冰检测数据集划分为训练集、验证集和测试集。
[0083]
引入注意力机制的fcnn和lstm并联网络的结构如图1所示,包括时间注意力机制模块、空间注意力机制模块以及主网络模块等。
[0084]
按照如图2所示的流程图构建自适应权重损失函数,利用该函数,在模型训练过程中增强模型对于结冰数据的分类能力,进而提升总体的分类性能。
[0085]
在模型训练时,对结冰检测数据集的训练集划分样本组,其包含的数据量设置为128,各样本组中结冰数据分布如图3所示,图中的平均值是指包含有结冰数据的样本组所含该类数据个数的平均值。
[0086]
图3中,除第1、7、12、16、18、19、22样本组中含有结冰数据外,其余样本组中仅包含有正常数据。根据具体实施方式所述,将不含有结冰数据的样本组归类为具体实施方式中所论述的无结冰数据样本组,所包含结冰数据个数远小于平均值的1、16、22样本组归类为稀疏样本组,结冰数据个数大于平均值的第7、12、19样本组归类为稠密样本组。此外针对第18号样本组,虽然其中的结冰数据个数略小于平均值但是数量差距仅为1/6,远小于样本组1、6、22结冰数据个数同平均值的数量差距,因而本方案也将18号样本组归为稠密样本组。
[0087]
为了验证本发明所涉及的损失函数的优势,在测试集上,将本损失函数对结冰状态检测模型的优化效果同其他几种传统的损失函数进行对比。这些传统的损失函数包括focal_loss、平衡交叉熵损失函数、代价敏感损失函数和标准交叉熵损失函数。
[0088]
对于损失函数focal_loss,需手动设置产参数α和β,其中超参数β设置为2、3、4,每一个β值对应的α取值范围为区间(0.05,0.95),步长为0.1,取上述不同超参数设置下focal_loss所能达到的最佳结果同本发明的损失函数作对比,经过验证,在β=2,α=0.65、β=3,α=0.05、β=4,α=0.15以及β=4,α=0.55时的优化效果在本损失函数的各组超参数中最佳。
[0089]
对于平衡交叉熵损失函数,需手动设置的超参数α,α的取值范围为区间(0.05~0.99),步长为0.05,取各超参数设置下该损失函数所能达到的最佳优化效果。经过验证,超参数α在取为0.25和0.6时的优化效果最佳。
[0090]
代价敏感和平衡交叉熵损失函数不含有超参数,直接取其优化效果进行对比。
[0091]
图4中,将各传统损失函数在测试集上对于模型的最佳优化效果同本发明所涉及的自适应权重损失函数进行对比,图中包括3个评价指标,其中结冰数据识别率反映模型对于数据集中叶片结冰数据的识别准确率,综合识别率是模型对于正常数据和结冰数据的识别准确率求和后取平均值,f1_score是风电机组状态检测领域中用于衡量模型分类效果的关键指标。由图可得,本发明所涉及的基于自适应权重损失函数的风电机组叶片结冰检测方法在结冰数据识别率、综合识别率以及f1_score上均优于其他损失函数在不同超参数下所能达到的最优指标,结冰数据识别率为0.76,综合识别率和f1_score分别为0.86和0.66。
[0092]
综上所述,本发明所提出的自适应权重损失函数相较于其他传统的损失函数可以更明显的增强模型对于具有典型不平衡性的风电机组叶片结冰数据集中的结冰类别数据
的识别,为处理不平衡数据提供了一种新的思路。
[0093]
本领域的相关技术人员可以理解,以上所述仅为结合具体数据集的优选实例,并不用于限制发明。尽管参照前述具体数据集对本发明做了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内所做的修改、等同替换等均应包含在发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1