一种模型训练方法及其装置与流程
本技术涉及人工智能领域,尤其涉及一种模型训练方法及其装置。
背景技术:
1、语言模型(language model)是指能够根据一部分给定的语义片段,预测句子中的未知词的模型。例如:给定的自然语言序列片段“华为__很不错。”,语言模型可以根据该片段生成未知的词语,如该例子中语言模型可基于给定片段生成“手机”一词,进而得到句子为“华为手机很不错。”。
2、语言模型的预训练是指通过海量的语言序列语料,训练对应的语言模型,使得语言模型具备预测某个位置某个语言单位出现概率的能力。
3、程序合成指的是由一定的软件程序来自动合成具有指定功能或者结构的指定程序语言序列,简而言之就是由程序来生成程序,总体上分为程序合成(代码生成)以及代码补全两种。程序合成,即从无到有,可以按一定的自然语言描述或预设的功能描述,生成对应的代码。代码补全,即在已有的代码序列上文基础上,继续生成下文代码序列。
4、随着深度学习技术的发展,利用深度学习进行序列生成已经被广泛应用在自然语言序列生成的场景上,特别是预训练语言生成模型技术的出现,使得语言生成能力有了质的提升。近年来,类似生成式预训练模型(generative pre-training,gpt)、t5、bart等生成模型也开始逐渐被引入代码生成或者补全中。该技术以transformer为基础部件,搭件解码器或者,编码-解码器模型架构,再用大量的代码数据进行训练,得到可以根据上文输出相应代码下文的能力,从而进行代码补全或者生成。
5、现有的技术沿用自然语言处理的生成方式,根据原始的代码进行训练,当前这种方式能够根据已有上下文进行代码的续写,但是针对函数级代码的生成这个场景,代码生成的质量还有待提升。
技术实现思路
1、本技术提供了一种模型训练方法,可以降低训练难度,提高代码的生成质量。
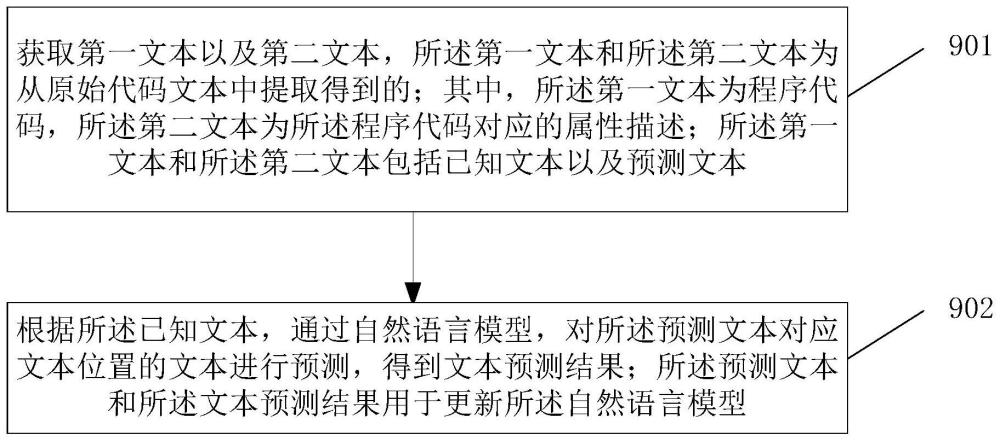
2、第一方面,本技术提供了一种模型训练方法,包括:获取第一文本以及第二文本,所述第一文本和所述第二文本为从原始代码文本中提取得到的;其中,所述第一文本为程序代码,所述第二文本为所述程序代码对应的属性描述;所述第一文本和所述第二文本包括已知文本以及预测文本;根据所述已知文本,通过自然语言模型,对所述预测文本对应文本位置的文本进行预测,得到文本预测结果;所述预测文本和所述文本预测结果用于更新所述自然语言模型。
3、在一种可能的实现中,所述属性描述包括所述程序代码功能描述或者所述程序代码的实现原理(或者称之为该程序代码的解释)。
4、在一种可能的实现中,原始代码文本可以为已有的程序语言语料及自然语言语料。可选的,可以通过网络(或者其他方式)获取已有的程序语言语料及自然语言语料,该语料包括混合程序语言及自然语言的代码文件、程序语言的代码文件、自然语言的文件。其中,收集的自然语言可以是任意人类语言,程序语言可以是任意编程语言,本技术并不限定。
5、在一种可能的实现中,所述第一文本和所述第二文本为从原始代码文本中提取得到的;其中,所述第一文本为程序代码,所述第二文本为所述程序代码对应的属性描述。第二文本可以为自然语言,且第二文本可以是任意的人类沟通时使用的语言,程序代码可以是任意编程语言,本技术并不限定。
6、在一种可能的实现中,在识别出第一文本和第二文本之后,可以建立第一文本以及第二文本之间的对应关系,以形成“自然语言描述-函数实现代码”(description-function)的句对形式样本。可选的,可以在每组自然语言-程序语言前使用表示字符组合来表示接下来的序列为文本语言序列或者具体的代码语言序列,并在样本之后添加样本结束符,进而可以表示出第一文本和第二文本为一对样本。
7、本技术实施例中,在构建程序合成的训练样本时,从原始的程序代码中提取代码文本和对应的属性描述并作为一对样本,相比现有技术中直接将原始的程序文件作为训练样本,帮助自然语言模型在训练时可以将代码文本和对应的属性描述之间建立关联,而无需在训练过程中从样本中学习到识别这种关联的能力,降低了训练难度,提高了模型的预测精度。
8、在一种可能的实现中,为了提高训练语料的质量,可以对函数级代码片段(例如代码程序)根据其代码语料的统计特性,去除代码语料中自然语言描述部分过短的语料、代码部分过长的语料或者两者长度相差过大的语料,以提升训练语料质量。
9、在一种可能的实现中,所述属性描述包括所述程序代码功能描述或者所述程序代码的实现原理。
10、在一种可能的实现中,所述第一文本为通过程序代码识别方法从原始代码文本中识别得到的,所述第二文本为通过属性描述识别方法从原始代码文本中识别得到的。
11、在一种可能的实现中,可以识别原始代码文本中的函数代码段作为第一文本:例如,可以使用一定规则(例如可以使用代码抽象语法树(ast)等程序代码识别方法)识别原始代码文本中的函数代码段。
12、在一种可能的实现中,可以使用的一定的规则,例如通过注释规则,语言字符规则等属性描述识别方法进行识别抽取。
13、示例性的,可以进行代码抽象语法树(ast)分析,对代码进行分析得到对应代码的语法树,通过语法树分析截取对应的函数级代码片段对应的自然语言描述。
14、示例性的,可以使用自然语言处理自动识别的方法进行代码段抽取,例如序列标注的方法,训练函数标注器标注出所有函数级代码对应的自然语言描述。
15、在一种可能的实现中,所述程序代码为一个或多个函数的完整代码。
16、在一种可能的实现中,为了训练能够用于进行程序生成功能的模型(也就是本技术实施例中的自然语言模型),可以将训练样本中的部分文本单元作为已知文本,另一部分文本作为待预测的文本,并基于已知文本来预测待预测的文本所在的文本位置的文本。
17、由于第一文本和第二文本为不同类型的文本(第一文本为计算机编译语言,第二文本为自然语言),可以针对于第一文本和第二文本通过不同的训练目标进行文本预测过程。
18、例如,针对于第一文本,可以采用clm、mlm、mclm以及nolm四种训练目标中的一种进行文本预测过程。
19、例如,针对于第二文本,可以采用clm、mlm以及mclm三种训练目标中的一种进行模型训练过程。
20、在优化自然语言描述部分时,可选clm、mlm、mclm、nolm四种训练目标中的一种。在优化程序语言函数代码部分时,可选clm、mlm、mclm三种训练目标中的一种,注意此处可以不包括nolm训练目标。自然语言描述部分和程序语言函数代码部分训练目标可自由组合。
21、在一种可能的实现中,在对所述第一文本中的文本进行预测时,可以通过第一方式,从所述第一文本中确定所述预测文本对应的文本位置;在对所述第二文本中的文本进行预测时,可以通过第二方式,从所述第二文本中确定所述预测文本对应的文本位置;所述第一方式和所述第二方式不同。
22、在一种可能的实现中,所述第一方式和所述第二方式分别为如下预测方式的一种:
23、对所述第一文本或所述第二文本的部分或全部文本的文本位置中采样掩码位置,所述掩码位置作为所述预测文本对应的文本位置(也就是mlm);
24、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本(也就是clm);
25、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本中未被掩码的文本(也就是mclm)。
26、在一种可能的实现中,还可以在不对第二文本中的文本进行预测的情况下(也就是nolm),通过如下预测方式的一种确定所述预测文本对应的文本位置:
27、对所述第一文本的部分或全部文本的文本位置中采样掩码位置,所述掩码位置作为所述预测文本对应的文本位置(也就是mlm);
28、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本(也就是clm);
29、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本中未被掩码的文本(也就是mclm)。
30、关于clm:
31、在模型训练的前馈过程中,自然语言模型可以沿着预设的上下文预测方向,依次进行文本的预测,也就是说,自然语言模型已经预测出的词的全部可以作为已知文本,且已知文本用于作为位置文本的上文来进行预测文本所在文本位置的文本预测,例如,可以沿着由上文到下文的顺序(也就是从文本开头到文本末尾的顺序)进行预测,每次可以预测一个文本单元,并在下次预测时基于已经预测出的文本单元继续进行预测。
32、关于mlm:
33、在模型训练的前馈过程中,可以对文本(例如第二文本或者第一文本)中的文本单元进行掩码(例如可以为随机掩码),掩码后的文本单元可以作为预测文本,未被掩码的文本单元可以作为已知文本,自然语言模型可以基于未被掩码的文本单元(或者已经预测出的掩码后的文本单元),依次进行掩码后的文本单元所在文本位置的文本预测。
34、关于mclm:
35、在模型训练的前馈过程中,自然语言模型可以沿着预设的上下文预测方向,依次进行文本的预测,和clm不同的是,在clm中自然语言模型已经预测出的词的全部可以作为已知文本,且已知文本用于作为位置文本的上文来进行预测文本所在文本位置的文本预测,在mclm中,可以对mclm中自然语言模型已经预测出的词进行掩码,可以使用自然语言模型已经预测出的词中未被掩码的文本单元来进行预测文本所在文本位置的文本预测。
36、关于nolm:
37、在模型训练的前馈过程中,可以不对第二文本进行预测,而直接将第二文本作为已知文本,并将第一文本作为训练样本,进行第一文本中文本单元的预测。
38、在一种可能的实现中,可以将可选的4种训练目标(clm、mlm、mclm、nolm)分别应用在“描述-函数对”(description-function)的自然语言描述或函数代码上,组合形成12种训练目标。
39、在一种可能的实现中,为了提高训练语料的质量,可以对函数级代码片段(例如代码程序)根据其代码语料的统计特性,去除代码语料中自然语言描述部分过短的语料、代码部分过长的语料或者两者长度相差过大的语料,以提升训练语料质量。
40、在一种可能的实现中,由于训练样本通常难以获取到,也就是训练样本(第一文本和第二文本构成的文本对)的数量较少,可以对已获取训练样本进行数据增强,来得到更多的训练样本。
41、在一种可能的实现中,所述第一文本为根据从原始代码文本中提取得到的第一原始文本得到的;其中,所述第一文本为对所述第一原始文本中的部分文本单元进行修改得到的。
42、在一种可能的实现中,所述修改包括:删除、增加或者替换。
43、在一种可能的实现中,所述替换具体为相同语义的替换。例如可以基于反向翻译技术生成同义片段,或者可以是基于同义句生成技术生成同义片段。
44、例如,可以对代码文本中的变量名进行随机替换、(循环)代码段等价替换以及随机插入无效代码段等方式,大量获得高质量自动生成的训练数据,最终提升模型性能。
45、在一种可能的实现中,所述第二文本为根据从原始代码文本中提取得到的第二原始文本得到的;其中,所述第二文本为对所述第二原始文本中的部分文本单元进行修改得到的。
46、在一种可能的实现中,所述修改包括:删除、增加或者替换。
47、在一种可能的实现中,所述替换具体为相同语义的替换。例如可以基于反向翻译技术生成同义片段,或者可以是基于同义句生成技术生成同义片段。
48、例如,可以通过对自然语言描述中进行同义词替换,句式变换,或者使用自然语言处理技术中的复述生成模型或者方法,数据增广方法,数据加噪方法对自然语言描述进行增广,大量获得高质量自动生成的训练数据,最终提升模型性能。
49、在一种可能的实现中,在模型训练的不同阶段,可以对训练样本进行不同的处理,例如,在模型训练初期迭代阶段可以采用上述方式得到的第一文本以及第二文本,而在模型训练的微调阶段,可以从原始代码文本中提取出适配于所述程序代码的应用领域的文本(同样包括程序代码以及对应的代码属性描述)作为训练样本。
50、在一种可能的实现中,所述第一文本或所述第二文本为从原始代码文本中提取的适配于所述程序代码的应用领域的文本。在一种可能的实现中,所述适配于所述程序代码的应用领域,包括:文本长度或者单行文本长度小于阈值的文本;其中,所述阈值与所述程序代码的应用领域有关。或者,还可以采用除了长度之外的其他维度的信息来量化和程序代码的应用领域。
51、在一种可能的实现中,可以基于数据样本与函数级代码生成器的应用领域的数据样本的相似度来过滤样本。相似度计算方法,可以是自然语言描述之间的长度关系,可以是程序语言函数代码之间的长度关系,也可以是其他关系。
52、第二方面,本技术提供了一种模型训练装置,包括:
53、获取模块,用于获取第一文本以及第二文本,所述第一文本和所述第二文本为从原始代码文本中提取得到的;其中,所述第一文本为程序代码,所述第二文本为所述程序代码对应的属性描述;所述第一文本和所述第二文本包括已知文本以及预测文本;
54、预测模块,用于根据所述已知文本,通过自然语言模型,对所述预测文本对应文本位置的文本进行预测,得到文本预测结果;所述预测文本和所述文本预测结果用于更新所述自然语言模型。
55、在一种可能的实现中,所述属性描述包括所述程序代码功能描述或者所述程序代码的实现原理。
56、在一种可能的实现中,所述装置还包括:
57、文本位置确定模块,用于在对所述第一文本中的文本进行预测时,通过第一方式,从所述第一文本中确定所述预测文本对应的文本位置;
58、在对所述第二文本中的文本进行预测时,通过第二方式,从所述第二文本中确定所述预测文本对应的文本位置;所述第一方式和所述第二方式不同。
59、在一种可能的实现中,所述第一方式和所述第二方式分别为如下预测方式的一种:
60、对所述第一文本或所述第二文本的部分或全部文本的文本位置中采样掩码位置,所述掩码位置作为所述预测文本对应的文本位置;
61、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本;
62、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本中未被掩码的文本。
63、在一种可能的实现中,所述文本位置确定模块,还用于:在不对第二文本中的文本进行预测的情况下,通过如下预测方式的一种确定所述预测文本对应的文本位置:
64、对所述第一文本的部分或全部文本的文本位置中采样掩码位置,所述掩码位置作为所述预测文本对应的文本位置;
65、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本;
66、将所述已知文本的下文的文本位置作为所述预测文本对应的文本位置;其中,所述已知文本为所述自然语言模型已预测的全部文本中未被掩码的文本。
67、在一种可能的实现中,
68、所述第一文本为根据从原始代码文本中提取得到的第一原始文本得到的;其中,所述第一文本为对所述第一原始文本中的部分文本单元进行修改得到的;或者,
69、所述第二文本为根据从原始代码文本中提取得到的第二原始文本得到的;其中,所述第二文本为对所述第二原始文本中的部分文本单元进行修改得到的。
70、在一种可能的实现中,所述修改包括:删除、增加或者替换。
71、在一种可能的实现中,所述替换具体为相同语义的替换。
72、在一种可能的实现中,所述第一文本或所述第二文本为从原始代码文本中提取的适配于所述程序代码的应用领域的文本。
73、在一种可能的实现中,所述适配于所述程序代码的应用领域,包括:
74、文本长度或者单行文本长度小于阈值的文本;其中,所述阈值与所述程序代码的应用领域有关。
75、第三方面,本技术实施例提供了一种模型训练装置,可以包括存储器、处理器以及总线系统,其中,存储器用于存储程序,处理器用于执行存储器中的程序,以执行如上述第一方面及其任一可选的方法。
76、第四方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面及其任一可选的方法。
77、第五方面,本技术实施例提供了一种计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面及其任一可选的方法。
78、第六方面,本技术提供了一种芯片系统,该芯片系统包括处理器,用于支持执行设备或训练设备实现上述方面中所涉及的功能,例如,发送或处理上述方法中所涉及的数据;或,信息。在一种可能的设计中,所述芯片系统还包括存储器,所述存储器,用于保存执行设备或训练设备必要的程序指令和数据。该芯片系统,可以由芯片构成,也可以包括芯片和其他分立器件。
- 还没有人留言评论。精彩留言会获得点赞!