用于训练神经网络的方法与流程
1.本发明一般涉及人工神经网络领域。更具体地说,本发明涉及使用多个不同激活函数训练卷积神经网络的一种方法。
背景技术:
2.深度学习和神经网络是目前最先进的机器学习解决方案,用于许多不同输入领域的各项任务,包括视觉、音频和时间序列数据的处理。激活函数通常用于将非线性引入神经网络。
3.目前,最流行的激活函数是relu(修正线性单元)激活,它被定义为y=max(0、x),即把输入负值剪切为零。还有其他的relu(修正线性单元)演变形式,例如relu6将数值最大限度地剪切为6。
4.大多数现代gpu(图形处理单元)/tpu(张量处理单元)/cpu(中央处理单元)芯片都提供硬件支持,以有效计算不同的流行激活函数。然而,在嵌入式系统中,支持激活函数的数量非常有限(通常只支持relu(修正线性单元)或其演变形式)。另一方面,与使用最近提出的最先进激活函数(如gelu(高斯误差线性单元)激活函数、elu(指数线性单元)激活函数、swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)等)的网络相比,这些激活函数通常性能较差。可惜,这些最先进激活函数的硬件支持是非常有限的,嵌入式芯片中是完全缺失的。
5.因此,使用最先进激活函数的神经网络在大多数嵌入式系统上不能有效执行,因为这些激活函数不被硬件支持,因为在大多数情况下,只有一些relu(修正线性单元)演变形式得到支持。
技术实现要素:
6.本发明实施方式的一项任务是公布训练神经网络的一种方法,即使在目标硬件仅为有限数量的激活函数提供硬件支持的情况下,所述方法作为训练结果也能提供高效的神经网络。
7.该任务通过独立权利要求的特征解决。优选实施方式在从属权利要求中给出。如果没有其他的明确指出,本发明实施方式可彼此自由组合。
8.根据一观点,本发明涉及的是用于训练人工神经网络的一种方法。所述方法包括以下步骤:
9.首先,提供待训练的神经网络。在训练后,该神经网络待基于第一激活函数进行操作。换句话说,在生产阶段神经网络使用第一激活函数,将非线性引入神经网络。神经网络在生产阶段基于下文中被称为目标硬件的嵌入式硬件运行,目标硬件为所述第一激活函数提供硬件支持。
10.神经网络的初始训练是基于第二激活函数执行的。第二激活函数不同于第一激活函数,即第一激活函数和第二激活函数具有不同的传递函数。
11.执行初始训练后,在过渡阶段执行进一步的训练。在所述过渡阶段,执行进一步的训练步骤,其中,使用第一激活函数和至少一个第二激活函数的组合对神经网络进行训练。在进一步的训练步骤中,训练函数的组合随时间变化,以使过渡阶段开始时至少一个第二激活函数的加权在过渡阶段结束时向第一激活函数的加权变化。换句话说,由于第一激活函数和至少一个第二激活函数的组合的时间变化,第二激活函数的影响在过渡阶段逐渐减少,第一激活函数的影响逐渐增加,以此获得从第二激活函数到第一激活函数的平稳过渡。
12.最后,基于第一激活函数执行最后的训练步骤。
13.所提出的训练方法是有益的,因为在开始时使用最先进的激活函数进行神经网络训练,并通过第一激活函数和至少一个第二激活函数的组合随时间变化使总激活函数加以改变,从而转向另一可通过目标硬件支持的激活函数,由此可获得更好的训练结果,从而提高训练后神经网络的效率。值得一提的是,从目标硬件的角度看,这类性能改进是免费的,因为只有模型训练受到影响,但网络架构保持不变。
14.所提出的方法优选可用于训练汽车应用领域中致力于图像处理任务的神经网络。除了目标识别、车道识别和语义分割等最常见的深度学习任务外,所提出的方法也可用于训练致力于例如基于单目摄像装置的深度估计、表面法线估计、用于例如人的姿势估计的关键点检测等其他二维图像处理任务的神经网络。
15.根据一示例性实施方式,所述组合是第一激活函数和至少一个第二激活函数的线性组合,其中,所述线性组合可通过一调谐因子加以改变。通过适当选择调谐因子,可改变第一激活函数和至少一个第二激活函数对训练神经网络的总激活函数的影响。
16.根据一示例性实施方式,由第一激活函数和第二激活函数的线性组合体现的总激活函数f
act,overall
构建如下:
17.f
act,overall
=α
·fact,1
+(1-α)
·fact,2
18.其中,α:调谐因子,其中,α∈[0、1];
[0019]fact,1
:第一激活函数;
[0020]fact,2
:第二激活函数;
[0021]
根据一示例性实施方式,调度器在过渡阶段调整适配调谐因子,以使第一激活函数在过渡阶段的加权逐渐提高。因此,激活函数在过渡阶段逐渐地自动调向第一激活函数,以便在训练结束时获得一个适合只使用第一激活函数的神经网络。
[0022]
根据一示例性实施方式,在过渡阶段,调谐因子线性或非线性地加以改变。根据待训练的神经网络,调谐因子的线性或非线性的变化会导致神经网络更好的性能。因此,调谐因子的线性或非线性变化可根据神经网络以及根据待由神经网络执行的任务加以选择。
[0023]
根据一示例性实施方式,所述组合是第一激活函数或至少一个第二激活函数的随机选择。通过随机选择第一和第二激活函数,也可达到从初始训练阶段仅使用第二激活函数到最终训练阶段仅使用第一激活函数的适当过渡。
[0024]
根据一示例性实施方式,随机选择第一激活函数或至少一个第二激活函数的概率可借助调谐因子加以改变。换句话说,随机选择受调谐因子的影响,并可基于调谐因子,改变第一或第二激活函数的频率比。因此,根据调谐因子,可以如下方式对第一激活函数或至少一个第二激活函数进行随机选择:即,使得在过渡阶段开始时总是或主要地选择第二激活函数,并且在过渡阶段结束时,总是或主要地选择第一激活函数。
[0025]
根据一示例性实施方式,调度器在过渡阶段调整适配调谐因子,以使第一激活函数在过渡阶段的加权逐渐提高。因此,激活函数在过渡阶段逐渐自动调向第一激活函数,以便在训练结束时获得一个只使用第一激活函数的神经网络。
[0026]
根据一示例性实施方式,在过渡阶段开始时,选择第二激活函数的概率为1或基本为1,在过渡阶段结束时,选择第二激活函数的概率降低到0或基本为0。由此,实现了从仅使用第二激活函数到仅使用第一激活函数的平稳过渡。
[0027]
根据一示例性实施方式,在过渡阶段,选择第一或第二激活函数的概率以及影响所述概率的调谐因子分别被线性或非线性地改变。根据待训练的神经网络,概率的线性或非线性变化会导致神经网络更好的性能。因此,可根据神经网络并根据待由神经网络执行的任务选择概率的线性或非线性变化。
[0028]
根据一示例性实施方式,基于随机数发生器和提供可改变决策阈值的一调度器进行随机选择。随机数发生器可提供0和1之间的随机值,而可改变的决策阈值可定义在0和1之间应选择第一或第二激活函数的阈值。因此,可改变的决策阈值可构成调谐因子。
[0029]
根据一示例性实施方式,神经网络包括多层,第一激活函数和至少一个第二激活函数的组合被应用于神经网络的每一层。
[0030]
根据一示例性实施方式,每层独立于其他层进行由第一激活函数或至少一个第二激活函数的随机选择而实现的激活函数组合。换句话说,在第一层的特定训练步骤中选择特定激活函数对神经网络的第二层的同一训练步骤中激活函数的选择不会有影响。
[0031]
根据一示例性实施方式,第一激活函数是relu(修正线性单元)激活函数,它通过下列公式描述:
[0032]
y(x)=max(0、x)。
[0033]
作为替代选择,第一激活函数可以是relu(修正线性单元)激活函数的演变形式,例如具有特定量化的relu(修正线性单元)激活函数(例如relu6、relu8等)或leaky relu(带遗漏单元的修正线性单元)激活函数/参数化relu(修正线性单元)激活函数。
[0034]
根据一示例性实施方式,第二激活函数从以下激活函数的列表中选择:swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)、gelu(高斯误差线性单元)激活函数、elu(指数线性单元)激活函数。基于所述激活函数,可获得更好的训练结果。
[0035]
根据一示例性实施方式,用于训练神经网络的训练环境包括不同于生产阶段所用生产硬件的计算硬件。为训练神经网络,可使用比生产硬件更多的、对多个激活函数提供硬件支持的,尤其是对用于汽车应用的嵌入式硬件提供硬件支持的训练环境。训练环境的扩展可能性可用于通过使用最先进的激活函数确定神经网络改进的加权因子。
[0036]
根据一示例性实施方式,训练环境包括对swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)、gelu(高斯误差线性单元)激活函数和/或elu(指数线性单元)激活函数的硬件支持,而生产硬件包括对relu(修正线性单元)激活函数的硬件支持,但不支持swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)、gelu(高斯误差线性单元)激活函数和/或elu(指数线性单元)激活函数。因此,有可能在训练开始时使用swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)、gelu(高斯误差线性单元)激活函数和/或elu(指数线性单元)激活
函数,并使用逐渐调整适配relu(修正线性单元)激活函数的组合激活函数,以确定训练后的神经网络,其效率高于仅基于relu(修正线性单元)激活函数的神经网络训练。
[0037]
根据另一观点,本发明涉及用于训练人工神经网络的一种计算机程序。所述计算机程序包括指令,当计算机执行所述程序时,所述指令使计算机执行以下步骤:
[0038]-接收与待训练的神经网络有关的信息,训练后,该神经网络待基于第一激活函数进行操作;
[0039]-基于至少一个第二激活函数执行神经网络的初始训练,其中,至少一个第二激活函数不同于第一激活函数;
[0040]-在过渡阶段,执行进一步的训练步骤,其中,使用第一激活函数和至少一个第二激活函数的组合训练神经网络,其中,训练函数的组合随时间变化,以使过渡阶段开始时第二激活函数的加权向过渡阶段结束时第一激活函数的加权变化;
[0041]-基于第一激活函数执行最后的训练步骤。
[0042]
在本发明中使用的术语“车辆”可指汽车、卡车、巴士、有轨车辆或任意其他交通工具。
[0043]
本发明中使用的术语“基本上”或“大约”是指与精确值偏差+/-10%,优选+/-5%和/或变化形式对功能和/或对交通规则不重要的偏差。
附图说明
[0044]
从以下详细描述和附图中更容易理解本发明的不同观点,包括其特定特征和优点,其中:
[0045]
图1示出了用于训练神经网络的训练策略的示意图;
[0046]
图2示意性地示出了用于训练神经网络的训练环境示例,该环境实现多个激活函数的线性组合;
[0047]
图3示意性地示出了用于训练神经网络的训练环境的另一实施方式,所述环境通过随机选择不同的激活函数实现多个激活函数的组合;
[0048]
图4示意性地示出了用于训练神经网络的训练环境的又一实施方式,所述环境通过随机选择不同的激活函数实现多个激活函数的组合;
[0049]
图5示出了一示意性框图,它展示了基于第一和一第二激活函数训练神经网络的方法步骤。
具体实施方式
[0050]
现参照展示示例性实施方式的附图对本发明进行更详细的描述。附图中的实施方式涉及优选实施方式,同时,已结合实施方式描述的所有要素和特征可尽可能与本文讨论的任何其他实施方式和特征结合使用,尤其是与上面进一步讨论的任何其他实施方式相关联。然而,本发明不应被解释为限于这里所述的实施方式。在后面所有描述中,如果适用的话,相似的参考号用于表示相似的要素、部分、项目或特征。
[0051]
在说明、权利要求、实施例和/或附图中公布的本发明特征既可单独,也可任意组合成各种形式,用于实现本发明。
[0052]
图1示出了用于为神经网络提供改进的训练的基本训练过程的框图,所述神经网
络在生产阶段中必须在目标硬件上操作运行,所述硬件不提供对swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)、gelu(高斯误差线性单元)激活函数和elu(指数线性单元)激活函数等最先进的激活函数的硬件支持。
[0053]
值得一提的是,用于训练神经网络的计算硬件不同于生产阶段中运行神经网络的、下文中被称为目标硬件的计算硬件。因此,可能出现的情况是,用于训练神经网络的计算硬件提供对swish激活函数(搜索激活函数)、mish激活函数(一种自正则化的非单调激活函数)、gelu(高斯误差线性单元)激活函数和/或elu(指数线性单元)激活函数等多种不同激活函数的硬件支持,而目标硬件只提供对例如relu(修正线性单元)激活函数等特定激活函数的有限硬件支持。目标硬件是例如用于汽车应用的嵌入式计算系统。
[0054]
如图1所示,训练被分成多个训练阶段,即初始训练阶段、过渡阶段和最终阶段。这类经分割的训练的目的是,训练开始时使用在目标硬件上不可获得硬件支持的第二激活函数,在过渡阶段中基于第一和第二激活函数随时间变化的组合对神经网络进行训练,其中,随时间变化的组合的执行方式是,在训练阶段开始时,主要或完全基于第二激活函数进行训练,在过渡阶段中,第二激活函数对训练的影响越来越小,第一激活函数对训练的影响逐渐增加。最后,神经网络基于在目标硬件上可获得硬件支持的第一激活函数进行训练。
[0055]
更详细地说,在第一训练阶段,神经网络基于第二激活函数进行训练。第二激活函数不同于目标硬件上有硬件支持的第一激活函数。为了改善神经网络的训练,但又能在不为第二激活函数提供任何硬件支持的目标硬件上运行神经网络,在过渡阶段中,增加使用第一激活函数,减少使用第二训练函数。因此,换句话说,在过渡阶段的训练期间使用的激活函数逐步从第二激活函数转移到第一激活函数。由此,在最后的训练阶段中,神经网络可基于第一激活函数进行训练,以获得训练后经改进的神经网络,该神经网络可在为第一激活函数提供硬件支持但不为第二激活函数提供支持的目标硬件上运行。
[0056]
第一和至少一个第二激活函数随时间变化的组合可通过不同的方式实现。
[0057]
在第一示例性实施方式中,实施第一和至少一个第二激活函数的线性组合。在过渡阶段,可使用由第一和至少一个第二激活函数的线性组合构成的总激活函数。在总激活函数中,第一和至少一个第二激活函数的加权可根据一调谐因子改变。通过过渡阶段时对调谐因子的调整适配,第一和至少一个第二激活函数的加权可从过渡阶段开始时第二激活函数的加权向过渡阶段结束时第一激活函数的加权改变。在过渡阶段开始时,第一和至少一个第二激活函数的组合的选择方式优选是,使得总激活函数等于或基本等于第二激活函数,在过渡阶段结束时,第一和至少一个第二激活函数的组合的选择方式优选是,使得总激活函数等于或基本等于第一激活函数。
[0058]
值得一提的是,第一和至少一个第二激活函数的线性组合优选可应用于神经网络的所有层。所有层中激活函数的调谐因子可都具有相同的值,并可同时调谐。
[0059]
在第二示例性实施方式中,过渡阶段中的第一和至少一个第二激活函数的组合是通过随机选择第一和第二激活函数来实施的。所述随机选择可受到影响选择第一或至少一个第二激活函数的概率的调谐因子的影响。通过过渡阶段时对调谐因子的调整适配,选择第一或至少一个第二激活函数的概率可从过渡阶段开始时选择第二激活函数的加权改变为在过渡阶段结束时选择第一激活函数的加权。在过渡阶段开始时,第一和至少一个第二激活函数的随机选择方式优选为,选择第二激活函数的概率是1或基本是1,在过渡阶段结
束时,第一和至少一个第二激活函数的随机选择方式优选是,选择第二激活函数的概率是0或基本是0,即在过渡阶段结束时,主要选择第一激活函数。
[0060]
图2展示用于训练神经网络的训练环境的示意性框图。所述训练环境实现第一和至少一个第二激活函数1、2的随时间变化的线性组合。由于所述随时间变化的线性组合,由所述线性组合得到的总激活函数可动态进行调整适配,以实现动态激活。
[0061]
图2展示基于第一和第二激活函数1、2的组合对单层神经网络的输入信息的处理。优选地,神经网络的所有层都由类似的激活函数构成。
[0062]
总传递函数是由目标激活函数的线性组合构成的,目标激活函数可以是第一激活函数1和课程激活函数。所述课程激活函数可由一个或多个第二激活函数2实现。
[0063]
目标激活函数的输出与系数c
t
相乘,课程激活函数的输出与系数cc相乘。将所述乘法的结果相加并作为输出提供。
[0064]
训练环境包括提供调谐系数α的调度器3,所述调谐系数可具有介于0和1之间的数值。系数cc可等于α,系数c
t
可等于(1-α)。在过渡阶段,调度器3修改调谐因子α的数值方法是,使得在过渡阶段开始时,课程激活函数被加权,而在过渡阶段结束时,目标激活函数被加权。
[0065]
总激活函数f
act,overall
可由以下公式定义:
[0066]fact,overall
=c
t
·fact,1
+cc·fact,2
[0067]
其中,c
t
:目标激活函数的系数;
[0068]cc
:课程激活函数的系数;
[0069]fact,1
:第一激活函数(目标激活函数);
[0070]fact,2
:第二激活函数(课程激活函数);
[0071]
更详细地说,调度器3可在过渡阶段开始时提供调谐系数α=1,所述调谐系数α可在过渡阶段结束时降低到α=0。
[0072]
根据一示例性实施方式,调度器3可线性地改变调谐因子α。根据另一示例性实施方式,调度器3可非线性地改变调谐因子α。
[0073]
根据一实施方式,在过渡阶段,可执行基于梯度下降的训练。在使用基于梯度下降的训练时,所提出方法可面临梯度冲突的问题。这是由于在同一层中平行使用梯度可能不同的多个激活引起的。请注意,这种现象取决于课程激活函数和目标激活函数的导数,如果有这种现象,那么可选择使用例如yu等人2020年提出的“gradient surgery for multi-task learning(用于多任务学习的梯度改变)”或2020年chen等人提出的的“just pick a sign:optimizing deep multitask models with gradient sign dropout(只需选择一个符号:使用梯度符号丢弃优化深度多任务模型)”中所述多任务学习领域的技术解决冲突。
[0074]
图3和图4展示用于训练神经网络的训练环境的示意性框图,所述训练环境通过随机选择第一或第二激活函数1、2作为当前激活函数来实现第一和至少一个第二激活函数1、2的随时间变化的组合。
[0075]
调度器3用于影响选择第一或第二激活函数1、2作为当前激活函数的概率。调度器3提供影响选择第一或第二激活函数1、2作为当前激活函数的概率的输出。在过渡阶段,调度器3的输出被改变,使得在过渡阶段开始时选择课程激活函数的加权逐渐提高,优选地,选择课程激活函数(第二激活函数2)的概率为1。在过渡阶段时,选择课程激活函数的概率
被降低并接近0,即在过渡阶段结束时,选择目标激活函数(第一激活函数1)的概率为1。
[0076]
根据图3所示实施方式,调度器3的输出是决策阈值p。随机数发生器3提供介于0和1之间的一个随机数r。
[0077]
根据随机数r和决策阈值p的数值,第一或第二激活函数1、2的选择可根据以下公式进行
[0078]
r≤p;
[0079]
其中,当不等式的结果为假(false)时,选择第一激活函数1,当不等式的结果为真(true)时,选择第二激活函数2。
[0080]
调度器3可采用过渡阶段开始时的p=1到过渡阶段结束时的p=0的决策阈值p,以便实现在过渡阶段结束时第一激活函数1影响的增加。
[0081]
根据图4所示实施方式,受调度器3影响的随机选择是借助伯努利分布b(p)加以解决的,所述伯努利分布受调度器3提供的决策阈值p的影响。因此,就像抛硬币一样,伯努利分布b(p)的输出r是0或1,其中,获得0或1的概率可变化。因此,过渡阶段开始时,r为1的概率最大,即为1,过渡阶段结束时减小到0。
[0082]
根据一示例性实施方式,调度器3可线性地改变决策阈值p。根据另一示例性实施方式,调度器3可非线性地改变决策阈值p。
[0083]
值得一提的是,神经网络可包括多层,并且所提出的第一和第二激活函数1、2的随机选择可与其他层无关,在每一层单独执行。
[0084]
第一激活函数1可是一relu激活函数(relu:修正线性单元),它由下列公式定义:
[0085]
y(x)=max(0、x)
ꢀꢀ
(公式1)
[0086]
relu(修正线性单元)激活函数被普通嵌入式硬件广泛地支持,尤其是受到汽车应用领域的嵌入式硬件的支持。
[0087]
关于relu(修正线性单元)激活函数请参考以下资料:2010年国际机器学习大会(icml)上nair和hinton发表的文章“rectified linear units improve restricted boltzmann machines(修正线性单元受限玻尔兹曼机)”。
[0088]
在下文中,提供第二激活函数2的可能实施示例。第二激活函数2例如可是以下激活函数之一:
[0089]-swish(2018年国际学习表征会议(iclr)上ramachandran等人提出的searching for activation functions(搜索激活函数);
[0090]-mish(2020年英国机器视觉会议(bmvc)上misra发表的论文“mish:a self regularized non-monotonic activation function(mish:一种自正则化的非单调激活函数)”;
[0091]-gelu(gelu:高斯误差线性单元)(2016年hendrycks等人提出的高斯误差线性单元(gelu));
[0092]-elu(elu:误差线性单元)(2016年国际学习表征会议(iclr)上clevert等人发表的文章“fast and accurate deep network learning by exponential linear units(elus)(通过指数线性单元(elu)快速准确的深度网络学习)”。
[0093]
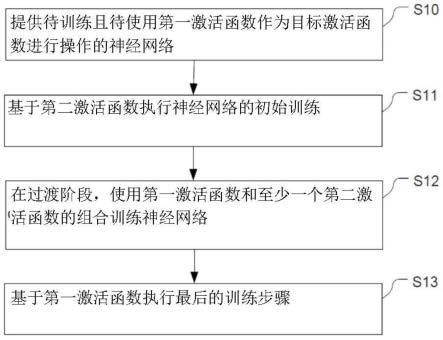
图5示出了用于训练人工神经网络的方法步骤的流程图。
[0094]
首先,提供待训练的神经网络,该神经网络在训练过程后待基于第一激活函数在
目标硬件上操作运行(s10)。
[0095]
随后,基于第二激活函数执行神经网络的初始训练(s11)。第二激活函数不同于第一激活函数。
[0096]
在执行初始训练后,在过渡阶段执行神经网络的进一步训练。在所述过渡阶段中,执行进一步的训练步骤,其中,使用一第一激活函数和至少一个第二激活函数的组合对神经网络进行训练,其中,训练函数的组合随时间变化的方式是,使得从在过渡阶段开始时至少一个第二激活函数的加权向在过渡阶段结束时第一激活函数的加权变化(s12)。
[0097]
最后,基于第一激活函数执行最后的训练步骤(s13)。
[0098]
应注意的是,描述和附图仅说明所提出本发明的原理。本领域的技术人员能实施在此没有明确描述或展示,但体现本发明原理的各种设置。
[0099]
附图标记列表
[0100]
1 第一激活函数
[0101]
2 第二激活函数
[0102]
3 调度器
[0103]
α 调谐因子
[0104]
p 决策阈值
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1