一种资源受限下基于CUDA的序列碰撞快速搜索方法及系统
一种资源受限下基于cuda的序列碰撞快速搜索方法及系统
技术领域
1.本发明涉及技术领域信息安全,具体涉及一种资源受限下基于cuda的序列碰撞快速搜索方法及系统。
背景技术:
2.随着信息技术的发展,密码系统的应用需求越发广泛,而现代密码系统的安全性与随机数发生器(rng)输出随机数的质量密切相关。随机性统计检验被广泛应用于rng随机性测试,以检验其产生的随机数的均匀随机性。多个国家和组织都已出台各自的随机数检测标准规范,例如美国的nist标准、德国的ais标准、我国的随机数检测规范等等,以更好地服务信息产业的发展。在各种随机数检测标准中,对于固定长度的模板的检测始终占有重要的地位,主要包括有:不相交检测,非重叠模板匹配检测,重叠模板匹配检测,近似熵检测,序列检测等等。其中非重叠模板匹配检测和重叠模板匹配检测是对固定模板的频数检测,近似熵检测和序列检测是对所有模板的频数检测,而不相交检测是以非重叠方式检测模板碰撞性的检测,即任意一个模板在检测序列中是否重复出现。本发明主要关注以重叠方式查找长模板的碰撞性。
3.碰撞性是随机序列的一种统计指标,且是杂凑函数的重要技术指标,比较著名的是“生日碰撞问题”,后发展为密码分析中常见的生日攻击或碰撞攻击。首先,需要明确碰撞的相关定义。
4.碰撞:当从大小为n的总体中进行有放回取样时,定义碰撞数为取样数n与样本中不同元素个数n1的差,即碰撞数=n-n1。具体在长序列查重中,设有n个m比特模板,不同的模板数有n1个,则该长序列碰撞数=n-n1。
5.重复对数:当从大小为n的总体中进行有放回取样时,定义重复对数为n个样本互相相等的个数,即其中具体在长序列查重中,设有n个m比特模板,则该
6.非重叠统计:在长序列模板统计中不允许模板相互重叠,设n比特序列,则有个m比特模板,即按m比特分割该长序列进行统计。
7.重叠统计:在长序列模板统计中允许各模板重叠,设n比特序列,则有n=n-m+1个m比特模板,即按m比特宽度依次后移1比特对该长序列进行统计。
8.非平凡碰撞:在长序列模板统计中,若存在两个模板形成碰撞,且这两个模板起始位置之前的1比特和终点位置之后的1比特都不相等,则称为非平凡碰撞。
9.可以通过一个实例来解释这几个定义。设有12比特序列110110101101,则该序列有3个4比特非重叠模板:1101,1010,1101;9个4比特重叠模板:1101,1011,0110,1101,1010,0101,1011,0110,1101;其中非重叠统计存在1个碰撞和1个重复对数,重叠统计存在4个碰撞,5个重复对数,其中有2个4比特非平凡碰撞和1个6比特非平凡碰撞。
10.这里介绍现有标准中的一种非重叠查重检测——不相交检测,即将生成序列以非重叠方式统计进行碰撞性检测,其数学模型是基于生日碰撞原理得到出现重复的概率,进行小概率事件的拒绝判断。
11.生日碰撞模型如下:
12.设有m个球,随机取出n个出现碰撞的概率:
[0013][0014]
其中m
(n)
=n(n-1)
…
(n-r+1)。当且m
→
∞,则p可做如下近似
[0015][0016]
在ais31提出的不相交检测中,测试随机比特串x,其长度为n,随机数比特位宽b,测试是否通过非重叠碰撞性检测。采用参数m=2b=2
48
,则出现重复的概率为p=1-exp(-2-17
)≈2-17
。可以看到在2
16
*48比特长的随机比特串中,将其分割为以48比特为单位模板的随机串,共2
16
个,出现48比特串模板重复的概率为2-17
,属于小概率事件,如果出现则拒绝其为随机串的假设。总结不相交检测(非重叠查重)的检测策略为:
[0017]
不相交检测模型:n比特长序列,检测模板长度为m比特,重复概率为
[0018][0019]
不相交检测策略示例:
[0020]
表1
[0021][0022]
通过生日问题可以延伸出6种经典碰撞问题,同时基于重叠及非重叠方式的查询可以得到更加丰富的统计检验方法。有了非重叠查重,自然想要考虑力度更大的重叠碰撞,即以重叠方式检测模板碰撞性。以n长4比特为例,非重叠方式有n/4个模板,重叠方式则有n-3个4比特模板。
[0023]
首先,对于n比特长序列,检测模板长度为m比特,可以很轻松得到重复对数(≥碰撞数)的期望:
[0024][0025]
根据此公式可得下表(列:待检序列长度;行:固定长度模板的长度;值:出现重复的概率估计的对数值
[0026]
表2
[0027][0028]
本发明主要关注序列中长比特长度(可选长度范围)的重叠碰撞搜索方法。
[0029]
首先,最平凡的实现方法是:一般实现。直接将数据读入内存,按m比特重叠模板进行比较。复杂度为o(n2)。以1gb查72比特重复为例,该实现方式至少需要8
·
72gb内存;当数据量达到10gb时,则至少需要80
·
72gb内存;100gb时,至少需要800
·
72gb内存。显然这种实现方式需要超大内存,不适合通用计算机,且其本身逐对对比的复杂度也较高。
[0030]
为了加快实现速度,较为高效的方法是:快排实现。直接将数据读入内存,按m比特重叠模板快排再比较。复杂度o(nlogn)。相比一般实现的方式,该实现方式大大降低了复杂度,但所需内存依然不变,这种实现方式更适合高性能计算机,然则其对内存的极高需求也极大降低了高性能计算机的数据量适用范围。
[0031]
通过利用计算机的并行能力(cpu和gpu),显然可以极大加速搜索,然而这并没有改变计算资源的限制,从而极大限制了可检测数据量。因此,在实际工作中,为了兼顾计算资源和效率,急需高效的重叠碰撞搜索方法,而这无疑加大了搜索算法的设计难度。
技术实现要素:
[0032]
为了解决上述存在的计算资源受限和效率低的问题,即解决难以在计算资源受限下高效搜索重叠碰撞的问题,本发明提出一种资源受限下基于cuda的序列碰撞快速搜索方法及系统,能够在有限计算资源下进行重叠碰撞的高效搜索,极大提高检测数据量上限,从而更好地服务于rng随机数质量检测工作。
[0033]
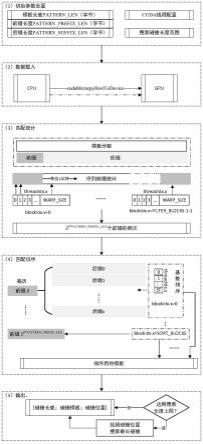
本发明所提出的一种资源受限下基于cuda的序列碰撞快速搜索方法,包括以下步骤:
[0034]
1)初始参数设置步骤:将检测模板分割为前缀和后缀,设定检查模板长度、前缀长度、后缀长度;设定cuda并行线程,该线程包括线程块和线程束;设定输出碰撞模板长度范围;
[0035]
2)数据载入步骤:将待检测数据加载到gpu设备;
[0036]
3)匹配统计步骤:进行碰撞快速搜索时,对所述待检测数据进行cuda并行匹配,得到所有前缀的频次;
[0037]
4)匹配排序步骤:利用cuda并行,遍历所有前缀,通过匹配前缀得到相应的所有后缀数据,并对其进行排序,得到所有满足长度要求的碰撞及其所出现位置和长度并作为结果;
[0038]
5)输出步骤:将上述结果传输到cpu端进行结果处理并输出{碰撞长度;碰撞模板;碰撞位置}。
[0039]
进一步地,初始参数设置步骤中,依据计算资源和重复对数的理论期望
将检测模板分割为前缀和后缀。
[0040]
进一步地,数据载入步骤中,首先通过cpu将待检数据读入,然后复制(cudamemcpyhosttodevice)到gpu设备。
[0041]
进一步地,数据载入步骤中,对于超出gpu显存负载的超大数据,通过cpu与gpu进行多次数据传输完成数据载入。
[0042]
进一步地,匹配排序步骤中,遍历前缀的方法为:依据前缀频次、设备显存大小和并行线程数,统筹一次处理(≥1)多个前缀对应的后缀数据的排序。
[0043]
进一步地,匹配排序步骤中,采用适合cuda并行的基数排序方法进行后缀排序,步骤包括:并行首字节或多字节(依并行线程分配而定),后逐字节块通过偏移量(offset)统计进行排序。
[0044]
进一步地,输出步骤中,若碰撞长度到达所设定搜索上限,则在cpu端对所属碰撞位置进行更长碰撞的判定搜索。对于搜索较大长度碰撞(例如120比特),考虑计算资源和实现效率限制,并不直接搜索,而是先搜索较小长度(同时该长度下理论期望值也较小)的碰撞(例如80比特),该较大长度和较小长度是依据计算资源确定;然后在此基础上利用得到的碰撞位置继续搜索得到更长碰撞长度的可能情况,最终完成全部长度碰撞搜索。例如,依据计算资源(显存)和效率考量,设定最长检测长度为110比特,但有180比特碰撞检测的需求,此时无需修改程序和设定,只需检测到110比特碰撞后,在此基础上继续进行搜索寻找是否有180比特碰撞。另一方面,如果直接检测180比特长度,会带来资源压力和效率降低,所以应先检测较小长度的碰撞,再在此基础上检测较长长度碰撞。
[0045]
进一步地,输出碰撞模板长度范围需根据计算资源进行设定,下限过小则不具意义,上限过大则影响算法效率和资源过度占用,上、下限的设定需要根据理论期望结果进行考虑。
[0046]
一种资源受限下基于cuda的序列碰撞快速搜索系统,包括存储器和处理器,在该存储器上存储有计算机程序,该处理器执行该程序时实现上述方法的步骤。
[0047]
本发明的主要优化资源占用和搜索效率两个方面:(1)将待检测数据进行分类匹配,再进行碰撞搜索,通过缩小搜索空间来减少资源占用;(2)利用基于计算机gpu的cuda并行技术,提高搜索效率。
[0048]
本发明方法与现有常用的针对重叠碰撞搜索方法相比,具有以下优点:
[0049]
1.本发明针对重叠碰撞搜索超大资源占用问题,创新性地提出了前缀分类匹配搜索的方法,即将模板分为前缀和后缀模板,匹配前缀数据对后缀数据进行碰撞搜索。假设设定前缀为b比特,则可实现搜索阶段资源占用至少降低1/2b倍,基本思想是牺牲复杂度,高度并行化;
[0050]
2.本发明针对搜索效率问题,创新性地提出用基数排序算法对后缀数据进行碰撞搜索,可有效利用cuda并行技术,实现高效的碰撞搜索,且利用该算法进行偏移统计的特点,同时记录碰撞长度;
[0051]
3.本发明对于超长碰撞并不直接进行搜索,而是依据计算资源和理论期望计算设定搜索长度上限,对于达到上限长度的碰撞再进行进一步的搜索,这样即可以极大降低超长模板重叠统计的资源占用(依据理论期望计算,会选则期望数较小的碰撞长度作为上限,
在此基础上继续搜索更长碰撞,增加的搜索时间极大概率意义下可忽略),又可以避免牺牲计算性能(在排序阶段超长模板排序会造成排序效率的降低,算法层面上增加了迭代深度)。
附图说明
[0052]
图1是本发明提出的一种资源受限下基于cuda的快速重叠碰撞搜索方法的流程图;
[0053]
图2是本发明实施例一的对10gb数据进行64~112比特重叠碰撞搜索的流程图。
具体实施方式
[0054]
下面结合附图和1个实施范例对本发明做进一步详细的说明,但不以任何方式限制本发明的范围。
[0055]
本发明主要针对超大数据规模的重叠碰撞搜索,可适用数据量范围为1gb~100gb以上(不限定数据量上限),满足在通用计算机上碰撞搜索的应用需求。下面以10gb待检测数据为例,搜索64~112比特碰撞模板、位置、长度等。注意到通过前表可知,对于1gb~100gb数据,64比特以上碰撞数理论期望值皆较小,属于合理范围。
[0056]
本实施例所用计算机配置为intel xeon金牌5218,16核,32线程,2.3主频,32gb内存,显卡rtx 3090 24gb,电源1400w。
[0057]
本实施例采用本发明提出的一种资源受限下基于cuda的序列碰撞快速搜索方法,对10gb待检测数据进行重叠碰撞搜索,如图1-2所示,其中图1是本发明方法的基本流程图,图2是本实施例具体处理的流程图,包括下列主要步骤:
[0058]
s1:初始参数设置。设定检查模板长度pattern_len为14(字节)、前缀长度pattern_prefix_len为2(字节)、后缀长度pattern_suffix_len为12(字节),pattern_len=pattern_prefix_len+pattern_suffix_len。设定cuda并行线程:1024个匹配线程块,每块含32个线程;256个排序线程块,每块含256个线程。设定输出碰撞模板长度范围:64~112比特。
[0059]
s2:数据载入。将10gb数据复制到gpu设备。
[0060]
s3:匹配统计。对数据进行cuda并行匹配(《《1024,32》》),得到2
16
个前缀的频次。
[0061]
s4:匹配排序。遍历第一个前缀字节(共256个),cuda并行排序(《《256,256》》),每个线程块针对一个第二前缀字节(共256个),用256个线程对后缀12字节数据集进行并行基数排序(具体流程为:首先统计后缀数据的第一字节的偏移情况,然后每个线程针对后缀数据后11字节串行实现基数排序)。
[0062]
s5:输出。将结果传输到cpu端进行结果处理并输出{碰撞长度;碰撞模板;碰撞位置}。
[0063]
具体实验效果为,通过程序实现本发明搜索方法,约在4200秒左右可以完成对10gb数据的所有64~112比特重叠碰撞模板及其位置和长度的输出,说明本发明提出的搜索方法可以在通用计算机上高效满足实际大数据检测需求。由此可见,一方面,现有方法对内存空间要求极大,只有在高性能计算集群中才有可能实现,在通用计算机上无法完成这些方法,而本发明的方法极大降低了计算资源要求,能够在通用计算机上满足实际检测需
求;另一方面,即使在高性能计算机上实现,也需要设计算法使其能够完成长序列的排序,现有方法直接对长序列排序,耗费时间过长,不可行,而利用本发明方法能够显著提高检测效率,能够满足实际需求。
[0064]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1