异常检测的制作方法
1.本发明涉及异常检测,尤其涉及用于异常检测的方法、计算机程序和设备。
背景技术:
2.在过去几年中,在智能交通系统(its)和先进的车辆技术中看到了发展。来自学术界和工业界等的主要研究组一直专注于联网汽车和自主驾驶车辆。现代汽车现在装备有许多车载传感器,以便感测关于其环境和通信链路的信息,从而与其他实体交换数据。移动性增强的应用和服务的快速出现导致了前所未有的网络安全漏洞和对隐私的威胁。
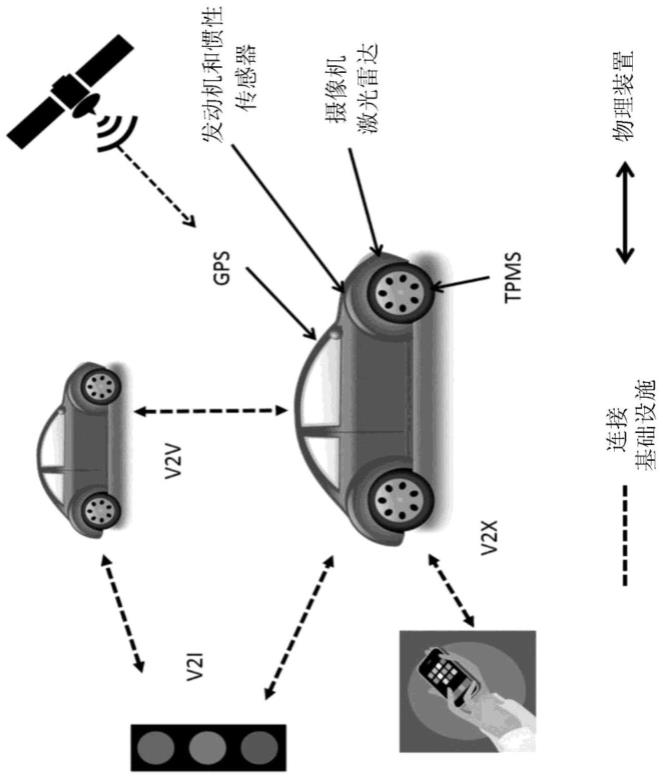
3.图1表示针对联网汽车的最常见的攻击面(其表示网络上对手可能试图进入信息系统的点)的概观图。图1示出了作为可能的攻击点的v2i(车辆与诸如基础设施的路侧装备(例如,交通信号灯)之间的连接)、v2v(车辆与其他车辆之间的连接)、gps(车辆与gps(全球定位系统)装置之间的连接,例如,从gps装置接收的信号)、车辆中的发动机和惯性传感器以及其他装置(例如,摄像机、激光雷达(光检测和测距)装置以及tpms(轮胎压力和监测系统)装置)和v2x(车辆与移动装置之间的连接)。图1并不详尽。
4.需要被主动保护的最敏感的信息中的一些信息与通过gps获得的车辆的物理定位/位置有关。大多数移动应用(例如,涉及实时交通状况、导航和信息娱乐服务的应用)依赖于车辆的位置信息。如果位置信息不准确,则大多数移动服务将因此不能正常工作。此外,错误或者受损的位置信息可能导致事故,该事故可能导致经济损失和/或甚至威胁乘客的安全(如在以下文献中所述:lim,k.等人的“detecting location spoofing using adas sensors in vanets”,2019 16th ieee annual consumer communications and networking conference,ccnc 2019,第1-4页,可以在https://doi.org/10.1109/ccnc.2019.8651763获得)。
5.gps已经彻底改变了现代its和移动系统。然而,这导致了针对位置信息的攻击的更高威胁。这些类型的攻击可以包括发送虚假gps信息(gps欺骗)(如在以下文献中所述:moser,d.等人的“investigation of multi-device location spoofing attacks on air traffic control and possible countermeasures”,proceedings of the annual international conference on mobile computing and networking,mobicom,0(1),第375-386页,可以在https://doi.org/10.1145/2973750.2973763获得)。
6.图2示出了gps欺骗攻击的可能结果,其中恶意对手(攻击者)2执行有针对性的网络攻击以改变车辆1的轨迹。例如,其他可能的结果包括在针对半自主辅助驾驶车辆进行攻击的情况下,使选择的车辆偏离其预期的路线,例如,以耗尽燃料资源、偷窃此类车辆或者将其撞毁(如在以下文献中所述:oligeri,g.等人的“drive me not:gps spoofing detection via cellular network(architectures,models,and experiments)”,wisec 2019-proceedings of the 2019conference on security and privacy in wireless and mobile networks,第12-22页,可以在https://doi.org/10.1145/3317549.3319719获得)。因此,针对这样的攻击实施适当的对策对于保护易受攻击的资产是必要的。
7.为了防止位置欺骗攻击,已经提出了各种方法。一种方法是通过包括从不同的来源/接收器取得定位(位置信息)的位置差异方案来检测欺骗信号(在以下文献中进行描述:k.jansen等人的“multi-receiver gps spoofing detection:error models and realization”,proceedings of the 32nd annual conference on computer security applications(acsac’16),第237-250页)。涉及密码学的另一种方法是使用公钥基础设施(pki)方案来检测并立即撤销恶意节点使用的证书。另一种方法是部署入侵检测和预防系统(ids)。后一种方法涉及监测和分析入侵迹象的事件(在以下文献中进行描述:van der heijden等人的“survey on misbehaviour detection in cooperative intelligent transportation systems”,ieee communications surveys and tutorials,21(1),第779-811页,可以在https://doi.org/10.1109/comst.2018.2873088获得)。
8.ids是监测网络或者系统的恶意活动或者政策违规的装置或者软件应用。任何入侵活动或者违规通常会被报告给it管理员或者通过安全信息和事件管理(siem)系统被集中收集。siem系统组合源自多个来源的输出,并且使用特殊的过滤技术来区分恶意活动和错误警报。
9.通常,有两种基本的ids方法:(i)基于签名的检测和(ii)基于异常的检测。
10.基于签名的检测基于误用检测技术,并且使用众所周知的攻击模式来匹配和识别已知的入侵。基于签名的检测在任何捕获的事件(潜在攻击)与已知的攻击签名之间进行模式匹配。如果检测到匹配,则可以生成警报。基于签名的检测的优点在于其可以准确地检测已知攻击的实例。然而,基于签名的检测可能无法检测到新的入侵或者零日攻击(zero-day attacks)(如在以下文献中所述:syarif,i等人的“unsupervised clustering approach for network anomaly detection”,communications in computer and information science,293part 1,第63-77页,可以在https://doi.org/10.1007/978-3-642-30507-8获得)。
11.基于异常的检测专注于识别不“正常”的行为来检测攻击。更详细地,绘制构成“正常”行为的内容的基线模型,然后与先前建立的基线的任何偏差可以生成警告(如在以下文献中所述:kleber,s.等人的“message type identification of binary network protocols using continuous segment similarity”,proceedings-ieee infocom,2020年7月,第2243-2252页,可以在https://doi.org/10.1109/infocom41043.2020.9155275获得)。先前定义的基线表示用作建立什么是“正常”活动的参考的行为数据的集合,最终将对其进行分析和彻底研究,以便帮助安全分析员识别指示存在威胁的异常。当利用丰富的上下文细节进行分析时,基线使得威胁检测更快且更准确,使用统计测试来确定观察到的行为(例如,交易)是否偏离正常配置文件。在特定示例中,通过ids将分数分配给配置文件偏离正常的每个交易。如果分数达到先前设定的阈值(例如,基于特定时间段内的事故次数),则发出警报。
12.与基于签名的模型相比,基于异常的检测的优点在于不需要关于入侵的先前知识。因此,基于异常的检测可以用于检测“新的”入侵或者攻击。基于异常的检测的缺点在于,其缺少对构成攻击的内容的适当描述,并且在一些实现中可能具有高误报率(如在以下文献中所述:meng,c.等人的“intrusion detection method based on improved k-means algorithm”,journal of physics:conference series,1302(3),第429-433页,可以在
https://doi.org/10.1088/1742-6596/1302/3/032011获得)。
13.用于异常检测的现有工具分为两种不同的方法:(i)有监督检测和(ii)无监督检测(也称为无监督分类或者用于异常检测的无监督分类)。每种方法都有一些局限性。每种方法面临的主要低效率和挑战总结如下。
14.有监督检测方法:
15.这种方法需要访问相关的标记数据以便正常工作。此外,可用于训练的数据的质量和大小可能对整体性能有很大影响。差的数据质量可能导致非常低的检测率。例如,如果只有少量的或者有限的数据可用于训练,则检测性能将受到影响。然而,大量的数据将需要相当多的计算和存储资源用于训练。
16.有监督检测方法的另一限制与以下事实有关,即在没有正确注释和/或标记的数据的情况下,则可能无法应用这样的方法。在许多情况下,由于技术挑战,后一方面可能展现严重的问题。
17.用于异常检测的无监督分类:
18.用于异常检测的无监督分类解决方案不需要标记的数据访问,然而它们仍然面临一些限制。例如,无监督分类解决方案可能需要来自人类专家的详细输入以便执行检测,这可能导致仅反映主题专家对攻击的理解的问题(其中,对于高度复杂的攻击可能特别难以理解)。因此,当缺乏对异常的性质的充分理解时,可能无法正确地采用这样的检测工具。此外,大多数先前的工具主要专注于有限的离散事件来发现和/或推断数据之间的相关性。因此,它们不能实现和/或考虑对异常的大规模理解。
19.一般而言,实现异常分析和检测工具的主要挑战之一与数据集访问问题有关。由于若干限制(例如,出于隐私原因的访问相关的限制或者免费提供数据的低经济激励),难以从现实世界的应用获取相关的异常数据。此外,缺陷和/或异常事件在生产环境中可能极为罕见。这些挑战意味着当处理由于未标记的、不完整的或者缺失的数据引起的数据访问限制时,无监督学习方法是最合适的。
20.数字化转型(dxr)操作在潜在应用方面经历了快速激增。由于不断增加的网络威胁和复杂的新网络攻击,这对于新兴的网络安全解决方案和隐私保护服务尤其如此。
技术实现要素:
21.根据上述内容,期望提供改进的异常检测。
22.根据第一方面的实施方式,本文公开了计算机实现的方法,该方法包括:提供距离、时间和速率中的至少一个的数据作为至少一个轨迹特征,所述数据定义多个车辆轨迹;通过基于数据计算每个车辆轨迹的至少一个轨迹特征中的至少一个轨迹特征的最大值、平均值和标准差中的至少一个来针对每个车辆轨迹计算多个元特征,使得每个车辆轨迹由元特征空间中的点表示,该点由多个元特征定义;对点实施聚类算法,并且基于聚类算法的结果选择至少一个点作为异常;以及选择对应于至少一个点的至少一个车辆轨迹作为至少一个异常车辆轨迹。
23.这种方法可以通过从多个车辆轨迹中检测异常的车辆轨迹并且因此检测潜在的危险事件来实现较早地检测到网络攻击。使用特定的元特征(如上面所描述的)作为高级异常检测算法的新实现的条目得到准确和快速获得的结果。例如,与例如人工操作员查看数
据日志并且试图识别异常相比,更快速地获得结果。此外,这样的人工操作员将需要用广泛的专业知识进行高度训练,然而该工具需要相对少的训练。
24.这种方法适合于识别关于任何联网车辆的异常轨迹(并且因此识别攻击)。合适的车辆可以具有不同的自主级别,范围从辅助汽车到自动驾驶汽车再到其中人工操作员完全控制汽车(并且使用定位(即,gps)信息来做出关于其轨迹的决定)的汽车,并且可以依赖于gps信息进行其决策制定。
25.全球定位系统广泛用于不同的环境中,所述不同的环境覆盖了可能应用的重要范围(陆地、空中和水路)其中,精确的物理位置至关重要。本发明可以应用于任何车辆,例如,陆地车辆,包括装备有用于与其环境中的其他实体或者与远程设置的系统通信的通信能力的所有内陆移动车辆。这些(联网)车辆的范围可以从需要精确定位以有效地在其环境中进行导航的具有高度自主性的高度自主自动驾驶汽车到将位置跟踪用于广告相关服务但不专门用于导航的仅具有例如简单的信息娱乐系统的汽车。这样的(联网)车辆包括例如卡车和公共汽车,例如,装备有gps并且使用该信息来规划和决定其轨迹的卡车和公共汽车。
26.本公开内容涉及将分析处理与高级机器学习api(应用程序编程接口)进行组合,以便在高度发展的、多样的和异构的环境中确保数据访问的安全。关键目标是通过自动分析和异常检测来提高安全性要求。
27.实施聚类算法可以包括(例如,通过以下操作对点实施k均值聚类算法):选择多个随机点作为质心;针对其他点中的每个点,计算该点与每个质心之间的元特征空间中的距离;以及将每个点分配给其最近的质心。
28.选择至少一个点作为异常可以包括:比较每个点距其最近的质心的元特征空间中的距离,并且选择在元特征空间中距其最近的质心具有最大距离的至少一个点作为异常。
29.实施聚类算法可以包括:在将点分配给其最近的质心之后,执行重新计算步骤/处理,包括:将每个质心(在元特征空间中的位置)重新计算为分配给该质心的点的平均值;计算每个点与每个质心之间的元特征空间中的距离;以及将每个点分配给其最近的质心。
30.该方法可以包括:重复重新计算步骤/处理,直到质心(在元特征空间中的位置)不改变。
31.重新计算步骤之后的每个质心(或者每个质心在元特征空间中的位置)可以通过向量来定义,该向量对于每个元特征包括分配给质心的点的对应计算的元特征的平均值。
32.将每个点分配给其最近的质心可以包括:对于每个点,将该点分配给其最近的质心,并且然后将质心(在元特征空间中的位置)重新计算为分配给该质心的点的平均值。
33.该方法可以包括:重复将每个点分配给其最近的质心,包括重新计算质心,直到质心(在元特征空间中的位置)不改变。
34.重新计算之后的所述质心(例如,所述质心在元特征空间中的位置)可以通过向量来定义,该向量对于每个元特征包括分配给质心的点的对应计算的元特征的平均值。在元特征空间中的距离可以是欧几里得距离。
35.选择多个随机点作为质心可以包括选择k个随机点作为质心,其中,k≤10或者k≤5或者k=2或者k=3。
36.该方法可以包括:接收距离、时间和速率中的至少一个的数据,以及选择接收到的数据的距离、时间和速率中的至少一个作为至少一个轨迹特征。
37.该方法可以包括:在计算元特征之前,确定要计算哪些元特征。
38.至少一个轨迹特征的选择和/或要计算哪些元特征的确定可以基于用户(专家或者主题专家)输入和/或使用不同轨迹特征和/或元特征的聚类算法的先前迭代的评估。
39.该方法可以包括接收速率的数据。针对每个轨迹计算多个元特征可以包括:基于数据计算每个轨迹的速率的最大值、平均值和标准差。
40.多个车辆轨迹可以包括至少一个车辆的至少一个轨迹。多个车辆轨迹可以包括至少一个陆基车辆(例如,汽车)的至少一个轨迹。
41.距离的轨迹特征可以是与车辆轨迹相关的车辆所行驶的距离,和/或速率的轨迹特征可以是与车辆轨迹相关的车辆的速率。
42.至少一个车辆可以是至少一个自主或者半自主或者自动驾驶或者辅助驾驶车辆。
43.该方法可以包括:在计算元特征之前,跨不同的数据属性对数据进行归一化。
44.不同的数据属性可以包括gps坐标、时间戳和速度测量中的至少一个。
45.对数据进行归一化可以包括将不同的数据属性转换成通用尺度,例如,具有预定义的平均值,可选地具有预定义的标准差。预定义的平均值可以是零以及/或者预定义的标准差可以是一。
46.数据可以针对每个车辆轨迹定义多个事件。每个事件可以由至少一个轨迹特征定义。对于每个至少一个轨迹特征,数据可以包括与连续的所述事件对应的至少一个轨迹特征的值之间的绝对差的集合。
47.数据可以针对每个车辆轨迹定义多个事件,每个事件由与车辆轨迹相关的(该)车辆的速率定义。数据可以包括与连续的所述事件对应的速率的值之间的绝对差的集合。
48.数据可以针对每个车辆轨迹定义多个事件,每个事件由与车辆轨迹相关的(该)车辆所行驶的距离定义。数据可以包括与连续的所述事件对应的距离的值之间的绝对差的集合。
49.数据可以针对每个车辆轨迹定义多个事件,每个事件由事件发生的时间定义。数据可以包括与连续的所述事件对应的时间的值之间的绝对差的集合。
50.数据可以针对每个车辆轨迹定义:与车辆轨迹相关的车辆的速率的多个值;和/或与车辆轨迹相关的车辆所行驶的距离的多个值。
51.数据可以针对每个车辆轨迹定义:与车辆轨迹相关的车辆的速率的多个值的连续值之间的绝对差的集合;和/或与车辆轨迹相关的车辆所行驶的距离的多个值的连续值之间的绝对差的集合。
52.速率的值和/或距离的值可以是规则时间间隔的值。
53.针对每个轨迹计算多个元特征可以包括:基于数据计算每个轨迹的绝对差的集合的最大值、平均值和标准差。
54.例如,该方法可以包括:输出指示至少一个异常车辆轨迹的选择的信息作为警告和/或在显示器上输出指示至少一个异常车辆轨迹的选择的信息。
55.该方法可以包括:针对每个车辆轨迹输出指示对应点到其最近的质心的元特征空间中的距离的信息。
56.该方法可以包括:基于对应点到其最近的质心的元特征空间中的距离来输出指示每个车辆轨迹的优先级的信息。在元特征空间中的较大的所述距离可以对应于较高的优先
级。
57.根据第二方面的实施方式,本文公开了根据第一方面的方法在车辆安全系统中的使用。
58.根据第三方面的实施方式,本文公开了一种计算机程序,当在计算机上运行时,该计算机程序使计算机:使用距离、时间和速率中的至少一个的数据作为至少一个轨迹特征,所述数据定义多个车辆轨迹,通过基于数据计算每个车辆轨迹的至少一个轨迹特征中的至少一个轨迹特征的最大值、平均值和标准差中的至少一个来针对每个车辆轨迹计算多个元特征,使得每个车辆轨迹由元特征空间中的点表示,该点由多个元特征定义;对点实施聚类算法,并且基于聚类算法的结果选择至少一个点作为异常;以及选择对应于至少一个点的至少一个车辆轨迹作为至少一个异常车辆轨迹。
59.计算机程序还可以使计算机输出指示至少一个异常车辆轨迹的选择的信息。
60.根据第四方面的实施方式,本文公开了一种信息处理设备,该信息处理设备包括存储器和连接至存储器的处理器,其中,处理器被配置成:使用距离、时间和速率中的至少一个的数据作为至少一个轨迹特征,所述数据定义多个车辆轨迹,通过基于数据计算每个车辆轨迹的至少一个轨迹特征中的至少一个轨迹特征的最大值、平均值和标准差中的至少一个来针对每个车辆轨迹计算多个元特征,使得每个车辆轨迹由元特征空间中的点表示,该点由多个元特征定义;对点实施聚类算法,并且基于聚类算法的结果选择至少一个点作为异常;以及选择对应于至少一个点的至少一个车辆轨迹作为至少一个异常车辆轨迹。
61.处理器可以被配置成输出/显示指示至少一个异常车辆轨迹的选择的信息。
62.涉及任何方面/实施方式的特征可以应用于任何其他方面/实施方式。
附图说明
63.现在将通过示例的方式参照附图,在附图中:
64.图1是示出可能的攻击的图;
65.图2是示出gps欺骗攻击的图;
66.图3是用于理解本公开内容的流程图;
67.图4是异常检测方法的流程图;
68.图5是用于理解本公开内容的流程图;
69.图6是用于理解本公开内容的流程图;
70.图7示出了说明聚类算法的结果的图表;
71.图8是异常检测方法的流程图;
72.图9是示出聚类算法的结果的一对图表;
73.图10是示出聚类算法的结果的图表;
74.图11是示出聚类算法的结果的图表;以及
75.图12是设备的示意图。
具体实施方式
76.本公开内容专注于为联网车辆提供生产后的安全措施,这由于诸如wp.29,iso/sae 21434的规定和标准而变得更加重要。可以通过自动分析能力和it服务管理工具来克
服潜在的安全挑战。本文公开的方法涉及:收集和仔细检查在这种高度复杂的异构环境中生成和使用的大量数据,致力于检测异常和可疑行为,并且最终在可能的攻击出现时,即在攻击的结果之前,例如,在车辆到达其将被盗的目的地之前,识别可能的攻击。
77.本文公开了用于异常检测的基于元特征选择的无监督分类解决方案,包括使用专门设计的适用于异常分类的元特征。该方法主要适用于大规模异常事故检测。
78.图3是示出作为比较示例的用于异常检测的方法的流程图。作为比较示例的图3所示的方法包括:在步骤s10中接收数据的输入,在步骤s12和步骤s14中探索数据以从数据中提取特征,在步骤s16中进行异常检测处理,以及在步骤s18中输出异常检测处理的结果。
79.用于异常检测的一组特征(在步骤s14处提取的特征)对检测算法的性能(即,对步骤s16中的异常检测处理,以及对图3所示的作为整体的方法)具有显著影响。使用相关特征将导致更少的冗余和/或噪声数据被用于检测,因此降低了过度拟合的风险,并且替代地提高了模型(即,方法)的整体准确性。使用不相关特征或者冗余特征可能对图3所示的方法的性能产生不利影响。如图3所示,比较示例的方法依赖于特征提取方法来找到要用于检测异常和攻击中的最相关的特征。
80.本文将具体更详细地描述根据实施方式的用于异常检测的方法的以下特征:
81.i.设计和使用基于从数据中提取的特征的特定元特征,以便对异常事故进行分类和检测。
82.ii.实施聚类算法,例如,无监督k均值算法,以用于基于新创建的元特征对异常事故进行分类。
83.iii.用于计算加权参数的距离测量,以便对异常事故进行优先级排序(例如,进行优先级排序以供人工操作员进一步处理)。
84.图4示出了用于异常检测的方法。该方法包括:在步骤s20中接收数据的输入,在步骤s22和步骤s24中探索数据以从数据中提取特征,在步骤s25中选择和生成元特征,在步骤s26中进行异常检测处理,以及在步骤s28中输出异常检测处理的结果。
85.图5提供了图4所示的方法所涵盖的一些步骤的概述。首先,从不同的异构来源收集和生成的数据被用作方法的输入。图5示出了aegis数据集的使用。aegis数据集是通过aegis(用于公共安全和个人安全的高级大数据价值链)欧洲项目提供的开放数据集,该aegis欧洲项目是ec h2020创新行动,旨在创建互连的“公共安全和个人安全”数据价值链,并且旨在提供用于大数据管理、集成、分析和智能共享的新颖平台(更多细节可以参见https://www.aegis-bigdata.eu/)。然后,从aegis数据集生成所有可用数据的综合列表,并且将其引入基于ai的工具中用于异常检测。该数据列表可以包括(数百万个)车载和ict(信息通信技术)事件日志。
86.系统的输出可以是异常事故的完整列表。这些异常事故可能包括例如不合理的位置改变、大量车辆消息或者车辆上的可疑活动。可以基于与先前检测到的(异常和非异常)事故的相似性分析来针对每个异常事故计算优先级分数,并且该优先级分数可以包括在输出中。根据检测算法的具体实现(即,步骤s26的异常检测处理),可以引入不同的测量和/或度量,以便计算优先级分数的值。
87.方法的输出(例如,显示所有事故或者事故中的一些事故的优先级分数,或者可选地利用它们的优先级分数来显示异常事故的指示)可以例如帮助人工操作员响应可能的攻
击,例如,通过首先处理被识别为异常和/或具有高优先级分数的事故。然后,根据情况,处理较低级别的事故(例如,具有低优先级的事故)可以被推迟或者完全舍弃。该方法可以通过例如加速异常的处理时间来提高v-soc(车辆安全操作中心——组织内的集中式实体,其采用人员、处理和技术来连续地监测和改进组织的安全状况,同时防止、检测、分析和响应以联网汽车为中心的网络安全事故)操作员的反应性和效率。
88.在图4所示的方法(即,步骤s25)中使用基于先前选择的特征的专门设计的元特征,以便对异常行为的发生进行分类和检测(以检测异常事故)。当设计/考虑新的元特征时,可以遵循迭代处理来创建最适当的元特征。新生成的用于检测异常的存在的元特征的质量和重要性将有助于决定在方法的未来“数据探索”阶段期间要包括哪些数据属性以及要忽略哪些数据属性(如从步骤s25(元特征选择)到步骤s22(数据探索)的箭头所示)。
89.例如,如上面和本文所使用的数据属性是数据的不同的来源,例如gps数据和来自车辆的速度计的数据。数据属性也可以用于表示不同格式的数据,即使它们源自相同的来源。哪些元特征(的子集)与异常检测处理/算法(步骤s26)中的使用最相关,可以基于方法的整体性能(例如,在检测准确性、误报和/或漏报的数量/比率等方面)周期性地改变或者连续地调整(如由从步骤s26(异常检测)到步骤s25(元特征选择)的箭头所示)。还可以考虑来自主题专家的外部反馈来选择要包括的最相关的元特征。
90.即,来自“主题专家”的输入可以帮助确定要在异常检测处理/算法(步骤s26)中使用的最佳/最适当的特征和元特征。例如,主题专家可以分析来自反馈回路(图4中使用的两个箭头)的结果。主题专家可以是理解数据与决策制定之间的相互关联关系的用户。
91.图4中所示的方法包括反馈回路,并且将措辞“元特征选择”用于步骤s25,然而这只是为了说明所使用的特征和元特征的可能的连续调整。相反,步骤s25可以被认为是对已经确定的元特征的计算,其中连续调整是单独的步骤和处理,即,当在检测异常中使用该方法时,可以不存在图4所示的反馈回路。虽然用于异常检测的方法用于自动检测数据中的异常,但是来自主题专家的反馈在方法的质量(精度、准确度等)的评估中可能是有用的。此外,图4所示的反馈回路和/或输入主题专家的输入可以在使用方法之前的“系统设计”阶段(即,测试和设置用于执行方法的系统)中实现,或者作为调整方法的处理实现,并且例如不在用于异常检测的方法的通常操作中实现。
92.图6示出了在设计异常检测方法时所遵循的步骤。以下特别讨论的步骤被强调。
93.i.数据预处理:
94.可以用作训练和测试检测工具的基准的入侵数据集(包括异常事故的记录的数据集,即,入侵和/或网络攻击的踪迹)包括异构来源和数据类型,并且可以包括范围广泛的属性,这些属性可以具有不同的尺度和不同的分布。具体地,例如,一些属性可以具有范围广泛的值,而其他属性可能分布非常狭窄。例如,两个不同的属性可以是gps位置信息和速度计信息。数据分布中的这些差异可能使得难以测量数据集中的变量/类别之间的相似性或者显著差异。将数据归一化和缩放成相同尺度的操作用于解决这个问题。具体地,数据被转换成“标准”形式。归一化(或者标准化)是用于将所有可用的不同属性转换成通用尺度的最常用的方法,例如,该通用尺度平均值为零且标准差等于一。
95.当处理具有不可比较单位(例如,时间、距离、速度、加速度等)的属性时,归一化可能是有用的。即使数据属性共用相同的单位但显示出非常不同的方差,值的归一化也可能
是有用的。否则,与具有较小方差的属性相比,具有较高方差的属性将对决策制定处理(即,对异常事故的识别)具有较大影响。这相当于在决策制定方面对具有较大方差的属性施加更大的权重,避免这种情况是有用的。
96.归一化不是必需的。此外,针对异常检测方法输入的数据可以被归一化。
97.ii.特征工程:
98.特征工程是将输入数据(初始属性)变换成特定特征(新创建的属性)的处理,其目的是提供对数据中基础值的更好理解和更具体的表示。特征工程也可以被视为从原始(初始)数据导出的数据的不同表示,以便更好地描述其隐藏特性并且解决手头的问题。在处理循环的这个阶段,主题专家的特定领域知识和主动参与在特征工程处理中可能是有用的。通过他们对所选择的用例的潜在复杂性和可能的攻击的广泛了解,主题专家可以帮助:(i)识别最相关的属性,(ii)选择将在检测算法中使用的有用的元特征,以及(iii)确保用于异常检测的整体方法正常工作,并且正确地应用/适配算法。
99.如上面所提及的,来自主题专家的输入可以用于“系统设计”阶段或者用作调整处理的一部分,而不一定在图4所示的方法的通常操作期间使用。即,可以对实现方法的系统编程,以选择哪些元特征/属性(例如,作为可选地结合主题专家的输入的系统设计阶段的结果)。
100.iii.基于ai的异常分析和优先级划分:
101.运行异常检测算法后,输出结果。输出被显示给用户(以全面的方式),例如,提醒用户任何异常事故,可选地还指示每个异常事故的优先级。这可以帮助用户做出关于需要实现以处理任何异常事故的最适当动作的决定。
102.图7示出了对于不同的簇使用不同形状的点来运行聚类算法的结果的典型示例。聚类在入侵检测领域是有用的(如在以下文献中所述:patcha,a.等人的“an overview of anomaly detection techniques:existing solutions and latest technological trends”,computer networks,第51卷,第12期,2007年8月22日,第3448-3470页;以及chandola,v等人的“anomaly detection:a survey”,acm computing survey journal,第41卷第3期)。使用聚类算法的优点是它们能够在没有明确描述异常的签名的情况下学习和检测数据中的异常,否则异常的签名的描述通常需要由经过高度训练的安全专家来提供。
103.两种不同类别的聚类工具可以用于异常检测:有监督和无监督。虽然第一类(有监督模型)需要使用标记数据的训练,以便建立正常和异常事故/行为的配置文件,但是第二类(无监督模型)更灵活。无监督类的聚类工具使用包括正常事故和不正常(即,异常)事故二者的未标记数据来训练,并且基于异常或者攻击数据形成总数据的一小部分的假设来操作,并且因此可以基于簇的大小来检测异常和攻击,使得当绘制数据时,大的数据簇对应于正常数据(即,非异常事故)并且作为异常值的其余数据点对应于攻击/异常事故(也如以下文献中所述:patcha,a.等人的“an overview of anomaly detection techniques:existing solutions and latest technological trends”,computer networks,第51卷,第12期,2007年8月22日,第3448-3470页;以及chandola,v等人的“anomaly detection:asurvey”,acm computing survey journal,第41卷第3期)。
104.k均值算法(或者k均值聚类算法)是无监督的聚类算法,并且可以用于自动识别数据中类似事故/实例/项目/对象/点的组/簇。k均值聚类算法将由数据定义的事故分类为预
定义数目(k)的簇(其中例如,k由用户指定)。
105.图8是示出用于异常检测的方法的流程图。该方法可以用于识别异常车辆轨迹。即,数据可以包括/定义车辆轨迹(一个车辆的多个轨迹,或者来自多个车辆中的每个车辆的一个轨迹,或者来自多个车辆中的每个车辆的至少一个轨迹/一个或更多个轨迹)。这样的车辆轨迹可以包括关于车辆行驶的距离和/或车辆在不同时间的速度/速率的信息。稍后更详细地描述车辆轨迹。
106.图8所示的方法可以在对可用数据执行初始预处理操作(分析、归一化等)之后发生。即,方法可以在开始时被提供已经被归一化的数据。在步骤s31处,从数据中提取特征。从数据中提取的特征可以被称为轨迹特征。例如,轨迹特征可以是距离、时间或者速度/速率的数据。可以从数据中提取至少一个轨迹特征。该步骤可以替代地结合到预处理阶段中,并且替代地,方法可以被认为在步骤s32处开始并且提供所提取的特征。或者,步骤s31可以替代地被认为包括接收距离、时间和速率中的至少一个的数据作为至少一个轨迹特征,该数据定义多个车辆轨迹。
107.步骤s32包括使用统计测量(最大值、平均值和标准差)从轨迹特征生成/计算/提取元特征。即,步骤s32包括通过基于数据计算每个车辆轨迹的至少一个轨迹特征中的至少一个的最大值、平均值和标准差中的至少一个来为每个车辆轨迹计算多个元特征,使得每个车辆轨迹由在元特征空间中的点表示,该点由多个元特征定义。在图8中示出了步骤s32的子步骤,其中对使用哪些元特征进行选择。该子步骤不是必需的,并且例如,可以在“系统设计”阶段被考虑,并且可以在初始化阶段利用来自主题专家的输入来进行。稍后将描述关于选择的更多细节(即,关于在以下方法步骤中可以使用哪些轨迹特征和哪些元特征)。
108.步骤s33包括选择要用于聚类算法的k个簇。该步骤可以省略,并且可以是“系统设计”阶段(或者如先前所描述的调整处理)的一部分。步骤s34包括随机地选择/选取k个“实例”的集合作为质心(簇的中心),通常针对每个簇选择一个彼此尽可能远的质心。这种情况下的“实例”是在元特征空间中的点,每个点表示车辆轨迹。
109.接下来,聚类算法继续从数据集中读取每个实例并且将其分配给最近的簇。即,步骤s35包括计算每个点到其最近的质心的元特征空间中的距离,并且步骤s36包括将每个点分配给其最近的质心。存在不同的方法来测量每个实例与质心之间的距离,例如,欧几里得距离、最大最小距离、余弦相似度、杰卡德相似度、编辑距离等。(例如,如在以下文献中所述:visalakshi,n.k.等人的“k-means clustering using max-min distance measure”,annual conference of the north american fuzzy information processing society(nafips),可以在https://doi.org/10.1109/nafips.2009.5156398获得;以及visalakshi,n.k.等人的“impact of normalization in distributed k-means clustering”,international journal of soft computing(第4卷,第4期,第168-172页),可以在https://medwelljournals.com/abstract/?doi=ijscomp.2009.168.172获得)。在特定实现中,欧几里得距离被用作距离测量。
110.在每次插入实例后(即,在已经分配了所有点/实例后)重新计算簇质心,直到质心(在元特征空间中)不改变位置。即,通过向量定义重新计算后的簇质心,该向量对于每个变量(或者分析的维度)包括该簇内所有不同观察结果的平均值(即,每个质心是分配给该质心的所有点的平均值,特别是对于在元特征空间中的每个元特征包括分配给质心的所有点
的该元特征的值的平均值的向量)。重复该处理(步骤s34至步骤s37)直到不再进行改变。这由步骤s37示出,步骤s37包括基于重新计算确定是否不存在质心的移动。也可以在每次将点/实例分配给每个簇质心时重新计算每个簇质心。
111.该方法可以包括以下步骤:基于聚类选择至少一个点作为异常,以及选择对应于该至少一个点的至少一个车辆轨迹作为异常轨迹。该方法可以包括:输出至少一个异常车辆轨迹的确定和/或指示至少一个异常车辆轨迹的警告和/或车辆轨迹的列表及其对应的优先级(优先级基于每个点到其最近的质心的距离)。
112.在方法中使用的k均值算法在以下伪码中进行解释:
113.1.计算元特征(最大值、平均值、标准差)。
114.2.选择元特征。
115.3.选择簇的总数(k)。
116.4.选择k个随机点并设置为质心。
117.5.使用欧几里得方法计算从每个实例/点到所有质心的距离。
118.6.将每个实例/点分配给其最近的质心。
119.7.重新计算质心的位置。
120.8.重复步骤5至步骤7,直到质心(质心位置)不改变。
121.在示例中,可以使用例如通过aegis数据集可获得的位置数据作为输入数据来测试方法。因此,该实现方式可以通过确定位置的“不合理”改变来检测可能的攻击。数据包括来自33个不同汽车的具有不同长度的33个轨迹的踪迹。换句话说,数据定义多个车辆轨迹。数据为每个车辆轨迹中的每个事件定义:时间戳、行程id和gps坐标。
122.在初始预处理和分析之后,计算以下特征:时间改变、距离改变和速率改变。改变被定义为与连续事件对应的轨迹特征(距离、时间或者速率)的值之间的差的绝对值。替代地,方法可以被提供一组差作为轨迹特征,而不是作为方法的一部分来计算差。
123.例如,对于每个至少一个轨迹特征,数据可以包括与连续的所述事件对应的至少一个轨迹特征的值之间的绝对差的集合。即,如果轨迹特征是距离,则数据可以包括与连续的所述事件对应的距离的值之间的绝对差的集合。如果轨迹特征是速度/速率,则数据可以包括与连续的所述事件对应的速率/速度的值之间的绝对差的集合。如果轨迹特征是时间,则数据可以包括与连续的所述事件对应的时间的值之间的绝对差的集合。
124.事件可以是车辆在特定时间(例如,在预定义的时间、或者在从先前测量经过预定义的时间量之后、或者在随机选择的时间)的轨迹特征(例如,距离或者速度/速率)的测量。事件可以是由特定标准,例如当行驶了特定距离或者达到特定速度/速率或者达到特定加速度时,触发的时间的测量。代替使用连续事件的轨迹特征值的差,数据可以包括在(设定/预定义/预定)时间段内的每个至少一个轨迹特征的平均值,例如每2分钟或者每5分钟行驶的距离的平均值。
125.对于每个车辆轨迹,通过基于数据计算每个车辆轨迹的至少一个轨迹特征中的至少一个轨迹特征的最大值(max)、平均值(mean)和标准差(std)中的至少一个来计算多个元特征,使得每个车辆轨迹由元特征空间中的点表示,该点由多个元特征定义。元特征被用作聚类算法的输入。在方法中可以使用元特征和特征的各种组合。例如,可以使用两个或者三个或者更多个元特征,以使元特征空间为二维或者三维的或者具有更多维度。可以使用速
率(差)的平均值、最大值和标准差。或者可以使用速率(差)的平均值和最大值。或者可以使用速率(差)的平均值和距离(差)的平均值。或者可以使用速率(差)的最大值和距离(差)的平均值以及时间(差)的标准差。显然,存在用于方法中的轨迹特征和元特征的许多不同组合,并且此处不提供详尽的列表。
126.该方法可以包括仅接收必要特征并且仅计算将在聚类算法中使用的必要元特征,或者该方法可以包括接收比最终将在聚类算法中使用的更多的轨迹特征和/或计算比最终将在聚类算法中使用的更多的元特征,并且可以在特征和元特征之间进行选择(可选地利用来自主题专家的输入)。通过试错法测试和评估特征/元特征的不同可能组合的性能可以由执行确定使用哪些特征/元特征的方法的系统来实现。
127.图9示出了说明使用速率改变的平均值、最大值和标准差作为元特征对来自aegis数据集的数据执行如上面所描述的k均值聚类算法的结果的两个图表。左边的图表示出了k=2的结果,而右边的图表示出了k=3的结果。每个点所分配到的质心由点的形状指示。每个图表中的每个点对应于数据中的33个车辆轨迹中的一个。
128.在聚类之后计算每个点与其质心(簇中心)之间的在元特征空间中的距离,并且将所获得的值用于不同车辆轨迹的优先级排序。图10是示出针对k=2聚类结果的该计算和优先级排序的结果的图表。图11是示出针对k=3聚类结果的计算和优先级排序的结果的图表。可以通过该方法输出类似于图10和图11中所示的那些的图表,或者可以输出按照其优先级顺序的车辆轨迹的列表,或者可以输出在元特征空间中距其质心具有最大距离的至少一个车辆轨迹作为至少一个异常车辆轨迹。基于输出,用户能够基于优先级值或者基于至少一个异常车辆轨迹的确定来关注最相关的车辆轨迹。
129.新设计的检测工具(即,本文所公开的用于异常检测的方法)旨在通过从多个车辆轨迹中检测异常车辆轨迹并且因此检测潜在危险事件来实现较早地检测到网络攻击。即,通过工具使用/分析的数据可以是实时数据。这里的“较早地检测”也可以被认为意指与例如人工操作员试图寻找可能的攻击相比,基于数据检测攻击所花费的时间更少。此外,这样的人工操作员将需要用广泛的专业知识进行高度训练,然而该工具需要相对少的训练。
130.源自不同来源的数百万联网车辆的日志条目和警告可以用作数据。结果最终通过提醒用户异常的车辆轨迹或者通过输出每个车辆轨迹的优先级来帮助用户响应潜在的危险事件。此外,方法输出可以通过对事件处理进行优先级排序并且计算与先前已知的异常事件的相似性来帮助支持分类操作并且简化v-soc人工操作员的审计过程。例如,该方法可以使用在预定义时间段(例如,6小时、12小时或者24小时)期间获得的车辆轨迹,并且可以在每个时间段之后有规律地产生输出以连续地监测车辆以提醒用户潜在的攻击。
131.本公开内容的方法可以应用于任何其他场景中,其中适当的元特征可以被用作用于检测针对网络/系统的其他类型的网络攻击的条目。在一些情况下,为了评估任何新引入的元特征对聚类算法性能和一般整体异常检测性能的可能的影响,分析将是有用的。
132.通过引入和使用特定元特征作为基于例如无监督k均值聚类算法的高级异常检测算法的新实现的条目,产生了在整个公开内容中公开的益处。来自聚类算法的输出被用于计算每个车辆轨迹与其簇中心(质心)之间的(在元特征空间中的)特定距离度量,以便识别异常轨迹并且由此识别潜在的攻击和/或对用户进行的事件处理和处理进行优先级排序。
133.图12是诸如数据存储服务器的计算装置10的框图,该计算装置10体现了本发明并
且可以用于实现体现本发明的方法(例如,图4和/或图8所示的方法)的操作中的一些或者全部操作。计算装置是设备10的示例,并且可以用于实现本文所公开的方法步骤中的任何方法步骤。
134.计算装置10包括处理器993和存储器994。可选地,计算装置还包括用于与其他这样的计算装置进行通信(例如,与对应于本发明实施方式的其他计算装置进行通信)的网络接口997。可选地,计算装置还包括诸如键盘和鼠标的一个或更多个输入机构996以及诸如一个或更多个监视器的显示单元995。这些部件可经由总线992相互连接。
135.存储器994可以包括计算机可读介质,该术语可以指被配置成携载诸如计算机程序代码形式的计算机可执行指令的单个介质或者多个介质(例如,集中式或者分布式数据库和/或相关联的高速缓存和服务器)。例如,计算机可执行指令可以包括可由通用计算机、专用计算机或者专用处理装置(例如,一个或更多个处理器)访问并且使其执行一个或更多个功能或者操作的指令和数据。例如,计算机可执行指令可以包括用于实现本文所公开的方法步骤(用于异常检测的方法,例如,图3和/或图4和/或图8所示的方法)的那些指令。因此,术语“计算机可读存储介质”还可以包括能够存储、编码或者携载用于由机器执行并且使机器执行本公开内容的方法中的任何一个或更多个方法的一组指令的任何介质。因此,术语“计算机可读存储介质”可以被认为包括但不限于固态存储器、光学介质和磁介质。作为示例而非限制,这样的计算机可读介质可以包括非暂态计算机可读存储介质,所述非暂态计算机可读存储介质包括随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、致密盘只读存储器(cd-rom)或者其他光盘存储装置、磁盘存储装置或者其他磁存储装置、闪存装置(例如,固态存储器装置)。
136.处理器993被配置成控制计算装置并且执行处理操作,例如,执行存储在存储器994中的计算机程序代码以实现本文所描述的方法中的任何方法。存储器994存储由处理器993读取和写入的数据,例如,车辆轨迹数据和/或异常轨迹。如本文中所提到的,处理器可以包括一个或更多个通用处理装置,例如,微处理器、中央处理单元等。处理器可以包括复杂指令集计算(cisc)微处理器、精简指令集计算(risc)微处理器、超长指令字(vliw)微处理器或者实现其他指令集的处理器或者实现指令集的组合的处理器。处理器还可以包括一个或更多个专用处理装置,例如,专用集成电路(asic)、现场可编程门阵列(fpga)、数字信号处理器(dsp)、网络处理器等。在一个或更多个实施方式中,处理器被配置成执行用于执行操作的指令以及本文所讨论的操作。
137.显示单元995可以显示由计算装置存储的数据的表示和/或本文所描述的方法的任何输出,例如,本文所描述的图表和/或列表中的任何图表和/或列表,和/或例如至少一个异常车辆轨迹的确定和/或指示上面所描述的至少一个异常车辆轨迹的警告,并且还可以显示光标和对话框以及屏幕,以实现用户与存储在计算装置上的程序和数据之间的交互。输入机构996可以使得用户能够向计算装置输入数据和指令,例如,来自主题专家的输入。显示单元995和/或输入机构996可以被认为是实现用户与计算装置和/或本文所描述的任何方法之间的交互的用户接口。
138.网络接口(网络i/f)997可以连接至诸如因特网的网络,并且可以经由网络连接至其他这样的计算装置。网络i/f 997可以经由网络控制来自其他设备的数据输入/到其他设备的数据输出。计算装置中可以包括其他外围装置,例如,麦克风、扬声器、打印机、电源单
元、风扇、外壳、扫描仪、轨迹球等。
139.体现本发明的方法可以在诸如图12中所示的计算装置/设备10上执行。这样的计算装置不需要具有图12中所示的每个部件,并且可以包括这些部件的子集。例如,设备10可以包括处理器993和连接至处理器993的存储器994。或者,设备10可以包括处理器993、连接至处理器993的存储器994和用于显示上面所描述的任何输出的显示器995。体现本发明的方法可以由经由网络与一个或更多个数据存储服务器进行通信的单个计算装置来执行。计算装置可以是本身存储数据的至少一部分的数据存储装置。
140.体现本发明的方法可以由彼此协作操作的多个计算装置来执行。多个计算装置中的一个或更多个计算装置可以是存储数据的至少一部分的数据存储服务器。
141.本发明可以以数字电子电路系统实现,或者以计算机硬件、固件、软件或者它们的组合实现。本发明可以被实现为用于由一个或更多个硬件模块执行或者控制一个或更多个硬件模块的操作的计算机程序或者计算机程序产品,即,有形地体现在非暂态信息载体中(例如,在机器可读存储装置中或者在传播的信号中)的计算机程序。
142.计算机程序可以是独立程序、计算机程序部分或者多于一个计算机程序的形式,并且可以以任何形式的编程语言(包括经编译语言或者解释语言)编写,并且其可以以任何形式部署,包括作为独立程序或者作为模块、部件、子例程或者适合用于数据处理环境中的其他单元。计算机程序可以被部署成在一个模块上或者在一个站点处或跨多个站点分布并通过通信网络互连的多个模块上执行。
143.本发明的方法步骤可以由执行计算机程序的一个或更多个可编程处理器来执行,以通过对输入数据进行操作并且生成输出来执行本发明的功能。本发明的设备可以被实现为编程硬件或者专用逻辑电路系统,包括例如fpga(现场可编程门阵列)或者asic(专用集成电路)。
144.适合于执行计算机程序的处理器包括例如通用微处理器和专用微处理器二者,以及任何种类的数字计算机的任意一个或更多个处理器。通常,处理器将从只读存储器或者随机存取存储器或者这二者接收指令和数据。计算机的基本元件是耦接至用于存储指令和数据的一个或更多个存储器装置的用于执行指令的处理器。
145.本发明的上述实施方式可以有利地独立于任何其他实施方式或者以与一个或更多个其他实施方式进行任何可行组合的方式来使用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1