数字档案分词检索系统的制作方法
1.本发明涉及数字档案技术领域,特别涉及一种基于elasticsearch中间件的数字档案分词检索系统。
背景技术:
2.电子档案管理系统通常存储有庞大数量级的数字化信息数据,然而,目前大部分电子档案管理系统对数据的检索存在用户搜索体验差、检索效率不高、结果质量差的问题。
3.目前常用的搜索引擎的主要有lucene、solr、es等。1)lucene搜索引擎是由apache软件提供,一套用于全文检索和搜寻的开源程序库,可以实现站内搜索。其需要大量的开发工作。索引库的维护及查询的优化等问题都需要用户自己来解决。一般通过api来对抽取的索引进行增、删、改、搜等各类操作。包含一般查询,词条查询,通配符查询等。2)solr搜索引擎是以lucene为内核,优化后的全文搜索引擎。solr搜索引擎是企业级的,快速的和高度可扩展的。使用solr构建的应用程序非常复杂,可提供高性能。solr是一个可扩展的,可部署搜索存储引擎,优化搜索大量以文本为中心的数据。虽然lucene搜索引擎功能强大,但是接入复杂。3)es(elasticsearch)搜索引擎虽然同solr搜索引擎一样也是基于lucene的搜索引擎,但是两者相比,es搜索引擎具有如下优势:solr建立索引时候,solr会产生io阻塞,查询性能较差,搜索效率下降,实时搜索效率不高,es实时搜索效率高;随着数据量的增加,solr的搜索效率会变得更低,而es却没有明显的变化;solr利用zookeeper进行分布式管理,而es自身带有分布式协调管理功能;solr官方提供的功能更多,而es本身更注重于核心功能,高级功能多有第三方插件提供;solr在传统的搜索应用中表现好于es,但在处理实时搜索应用时效率明显低于es;solr是传统搜索应用的有力解决方案,但es更适用于新兴的实时搜索应用。
4.鉴于上述档案室数字化数据检索的问题,本发明旨在从es搜索引擎着手,提供一种新的检索系统以解决上述检索难题。
技术实现要素:
5.本发明的目的在于提供一种基于elasticsearch中间件的数字档案分词检索系统,以解决档案室数字化数据检索存在的用户搜索体验差、检索效率不高、结果质量差的难题。
6.为实现达到上述目的,本发明采用如下技术方案:
7.本发明提供一种数字档案分词检索系统,其特征在于,包括:数据导入单元,利用logstash工具将mysql数据库中的标准化数据导入elasticsearch;数据索引单元,通过elasticsearch对标准化数据建立索引,并将索引信息存放到索引库;数据检索单元,获取用户发送的检索请求,springboot服务器通过javaapi接口调用elasticsearch实现检索,结果通过vue框架在用户端进行展示。
8.进一步,在本发明提供的数字档案分词检索系统中,其特征在于,还包括:数据缓
存单元,用于将用户信息、用户热搜资源、平台热搜资源存放至缓存数据库。
9.进一步,在本发明提供的数字档案分词检索系统中,还可以具有这样的特征:其中,缓存数据库为redis数据库。
10.进一步,在本发明提供的数字档案分词检索系统中,还可以具有这样的特征:其中,mysql数据库中的标准化数据是数字档案数据依次经过汇聚、清洗、筛选、标准化之后得到的数据。
11.进一步,在本发明提供的数字档案分词检索系统中,还可以具有这样的特征:其中,数据索引单元按照如下流程运行:步骤a1,从mysql数据库获取标准化数据;步骤a2,通过分词器将步骤a1获取的数据解析生成若干field对象;步骤a3,将field对象构建为document对象;步骤a4,利用indexwrite工具建立索引并将得到索引数据放入索引库。
12.进一步,在本发明提供的数字档案分词检索系统中,还可以具有这样的特征:其中,分词器包括ik-analyzer中文分词器,该ik-analyzer中文分词器通过如下步骤配置到elasticsearch中:步骤b1,下载ik-analyzer源码,接着执行命令mvncleanpackage,打包得到jar包文件;步骤b2,将ik-analyzer依赖包复制到elasticsear-ch/plugin/analysis-ik目录下;步骤b3,在elasticsearch的config目录下对ik-analyzer进行配置。
13.进一步,在本发明提供的数字档案分词检索系统中,还可以具有这样的特征:其中,数据检索单元运行查询关键词流程以及搜索联想流程,
14.查询关键词流程具体如下:
15.步骤c1,获取用户通过用户端发送的查询关键词请求,通过分词器对关键字进行分词,生成若干个field对象;
16.步骤c2,通过multifiledqueryparse工具生成query对象,然后在索引库的不同索引列上进行多个关键词的搜索;
17.步骤c3,创建indexsearcher对象实例,对elasticsearch的集群各节点进行索引检索,将符合条件的查询结果合并,然后经过相关性排序之后得到结果集,即将结果集返回给用户端;
18.搜索联想流程具体如下:
19.步骤d1,实时获取用户通过用户端在检索框中输入的内容,利用ajax请求数据接口异步地向springboot服务器发送搜索联想的请求;
20.步骤d2,springboot服务器将请求到的数据在elasticsearch中进行前缀匹配,利用elasticsearch搜索对应前缀的索引,然后通过elasticsearch的bool quer工具将多个前缀查询结果组合起来,最终所有前缀查询结果返回到用户端;
21.步骤d3,用户端利用ajax组件库中的jquery完成提示词展示。
22.本发明的作用与效果:
23.本发明提供的数字档案分词检索系统中,对e1asticsearch进行了大量开发,不仅具有全文搜索功能,还可以对所有字段都进行了编辑,所有字段都可进行搜索,提升了用户数字档案搜索体验,提高了检索质量。
24.本发明的系统中,在e1asticsearch中配置ik-analyzer中文分词器,提供实时分析功能,使得资源不但能部署在单台服务器上,还能横向扩展到上千台设备上,处理大数据级别的数据非常快,大大提升了检索效率,非常适合数字档案资源的存储和搜索。
25.此外,本发明的系统中引入了redis数据库,把经常被访问的用户信息、用户热搜资源和平台热搜资源数据通过springboot缓存在redis数据库,从而不用每次都访问mysql数据库,提升搜索联想词的性能。
附图说明
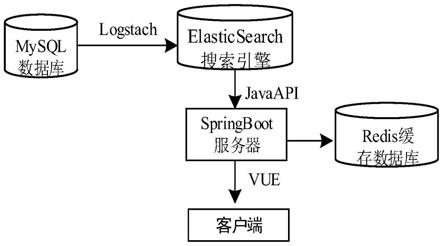
26.图1是本发明实施例中的数字档案分词检索系统的总体架构图;
27.图2是本发明实施例中的数字档案分词检索系统实现索引的流程图;
28.图3是本发明实施例中的数字档案分词检索系统实现检索的流程图;
29.图4是本发明实施例中的数字档案分词检索系统实现搜索联想的流程图;
30.图5是本发明实施例中的数字档案分词检索系统实现搜索联想的结果示意图。
具体实施方式
31.为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明的技术方案作具体阐述。
32.《实施例》
33.参阅如图1至图4,一种数字档案分词检索系统包括以下功能单元:数据导入单元、数据索引单元、数据检索单元、数据缓存单元。
34.参阅图1,在该系统中,数字档案数据依次经过汇聚、清洗、筛选、标准化之后存入mysql数据库。该系统中,elasticsearch搜索引擎是在现有elasticsearch搜索引擎的基础上经过开发得到。本发明在elasticsearch搜索引擎中配置了ik-analyzer中文分词器,该ik-analyzer中文分词器通过如下步骤配置到elasticsearch中:
35.步骤b1,下载ik-analyzer源码,接着执行命令mvncleanpackage,打包得到jar包文件;
36.步骤b2,将ik-analyzer依赖包复制到elasticsear-ch/plugin/analysis-ik目录下;
37.步骤b3,在elasticsearch的config目录下对ik-analyzer进行配置。
38.参阅图1,数据导入单元利用logstash工具将mysql数据库中的标准化数据同步导入elasticsearch。
39.参阅图2,数据索引单元通过elasticsearch对标准化数据建立索引,并将索引信息存放到索引库。数据索引单元具体按照如下流程运行:
40.步骤a1,从mysql数据库获取标准化数据;
41.步骤a2,通过分词器将步骤a1获取的数据解析生成若干field对象;
42.步骤a3,将field对象构建为document对象;
43.步骤a4,利用elasticsearch的indexwrite工具建立索引并将得到索引数据放入索引库。索引库包含文档号、词频、位置和偏移量等信息。
44.参阅图1,数据检索单元获取用户发送的搜索请求,springboot服务器通过javaapi接口调用elasticsearch实现检索,结果通过vue框架在用户端进行展示。数据检索单元运行查询关键词流程以及搜索联想流程。
45.参阅图3,查询关键词流程具体如下:
46.步骤c1,获取用户通过用户端发送的查询关键词请求,通过分词器对关键字进行分词,生成若干个field对象;
47.步骤c2,通过elasticsearch的multifiledqueryparse工具生成query对象,然后在索引库的不同索引列上进行多个关键词的搜索;
48.步骤c3,创建indexsearcher对象实例,对elasticsearch的集群各节点进行索引检索,将符合条件的查询结果合并,然后经过相关性排序之后得到结果集,即将结果集返回给用户端;
49.参阅图4,搜索联想流程具体如下:
50.步骤d1,实时获取用户通过用户端在检索框中输入的内容,利用ajax请求数据接口异步地向springboot服务器发送搜索联想的请求;
51.步骤d2,springboot服务器将请求到的数据在elasticsearch中进行前缀匹配,利用elasticsearch搜索对应前缀的索引,然后通过elasticsearch的bool quer工具将多个前缀查询结果组合起来,最终所有前缀查询结果返回到用户端;
52.步骤d3,用户端利用ajax组件库中的jquery完成提示词展示。参阅图5,例如,当用户在检索框中输入“非线性”时,在检索框的下方显示了“非线性微分方程边值问题”、“非线性最小二乘分析法”等多个搜索联想结果。
53.参阅图1,数据缓存单元用于将用户信息、用户热搜资源、平台热搜资源存放至redis数据库。
54.上述实施例仅为本发明的优选实施例,并不用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1