互联网大数据的信息推荐方法以及AI系统与流程
互联网大数据的信息推荐方法以及ai系统
技术领域
1.本发明涉及互联网大数据信息技术领域,尤其涉及一种互联网大数据的信息推荐方法以及ai系统。
背景技术:
2.大数据(big data),指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。随着互联网的发展,网络信息爆炸式增长,这些网络信息具有一定的使用价值,为了充分利用这些网络信息,大数据技术运用而生。
3.大数据技术是以任何系统的全部数据资源为对象并从中发现数据之间表现的相关性关系的信息处理技术,目前已经广泛应用于互联网的流程优化、目标化消息及广告推送、用户个性化服务与改善等方面。目前,大数据信息是一次性地从互联网获取得到,这些数据信息针对性不强而且容易获得大量的垃圾信息。
技术实现要素:
4.鉴于此,为了在一定程度上解决相关技术中的技术问题之一,有必要提供一种互联网大数据的信息推荐方法以及ai系统,提高获取的大数据信息的准确性。
5.本发明第一方面提供一种互联网大数据的信息推荐方法,所述方法包括:
6.手机持续监听手机用户的输入信息;
7.当所述手机监听到的输入信息中包括预设内容时,所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容;
8.所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息;
9.所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度;
10.若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息;
11.所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息;
12.所述大数据服务器对所述大数据信息进行预处理;
13.所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
14.在一个优选的实施方式中,所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息之后,所述方法还包括:
15.判断获取的所述大数据信息的条目数是否达到设定值;
16.若所述大数据信息的条目数未达到设定值,则获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息;其中,其他用户的信息获取请求包括所述预设内容;
17.将基于其他用户的请求所获取的大数据信息并入到本次获取的大数据信息中以便于所述大数据服务器对合并后的大数据信息进行预处理。
18.在一个优选的实施方式中,所述方法还包括:
19.所述大数据服务器分析所述用户针对所述预设内容的偏好;
20.根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类;
21.所述获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息,包括:
22.获取具有相同偏好的其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息。
23.在一个优选的实施方式中,所述大数据服务器分析所述用户针对所述预设内容的偏好,根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类,包括:
24.根据所述输入信息识别出输入信息所包括的预设内容的结构句中所包括的肯定/否定词和句尾词;
25.根据所述肯定/否定词和所述句尾词识别所述输入信息中针对所述预设内容属于肯定还是属于否定;
26.将针对所述预设内容属于肯定的用户归为同类;
27.将针对所述预设内容属于否定的用户归为不同类。
28.在一个优选的实施方式中,所述大数据服务器分析所述用户针对所述预设内容的偏好,根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类,包括:
29.分析所述手机在过去第一预设时间段内监听到所述用户输入的所述预设内容的次数;
30.将过去第一预设时间段内监听到输入的所述预设内容的次数不小于第二预设值的用户归为同类;
31.将过去第一预设时间段内监听到输入的所述预设内容的次数小于第二预设值的用户归为不同类。
32.在一个优选的实施方式中,所述方法还包括:
33.所述手机收集所述用户在过去第二预设时间段内与所述其他用户的沟通内容,判断所述沟通内容与所述预设内容是否具有关联性;
34.若所述沟通内容与所述输入信息具有关联性,则将所述其他用户设定为关联用户,以便于当所述大数据信息的条目数未达到设定值时,获取所述其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息。
35.在一个优选的实施方式中,所述大数据服务器对所述大数据信息中除所述预设内容外的其他字段进行统计分析,将带有相同字段的数据信息合并得到数据集合,每一个数据集合带有相应的字段标识;
36.所述若所述大数据信息的条目数未达到设定值,则获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息,包括:
37.若所述大数据信息的条目数未达到设定值,则查询所述用户在过去第三预设时间段内与所述其他用户的沟通内容;
38.确定所述沟通内容中所包括除所述预设内容之外的字段;
39.获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息的数据集合,所述数据集合为带有对应字段标识的集合。
40.本发明第二方面提供一种互联网大数据的信息推荐ai系统,所述系统包括手机以及大数据服务器,所述系统能够实现所述的互联网大数据的信息推荐方法。
41.通过以上方案可知,本发明通过持续监听用户的输入信息,并且当输入信息包括预设内容时,通过大数据服务器获取相关的大数据信息,所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息,若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息,然后所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息,最终所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。本发明优选依据所述预设内容从第一信息渠道获取初始信息,所述大数据服务器对初始信息进行筛选,筛选出具有关联的筛选信息,从而从第一信息渠道得到新增的有用信息,然后依据所述筛选信息和所述预设信息再从第二信息渠道获取大数据信息,如此将从第二信息渠道得到相关性较高的大数据信息,可以提高获取的大数据信息的准确性。
附图说明
42.图1为本发明的第一实施例的方法流程示意图。
43.图2为本发明的第二实施例的方法流程示意图。
44.图3为本发明的第三实施例的方法流程示意图。
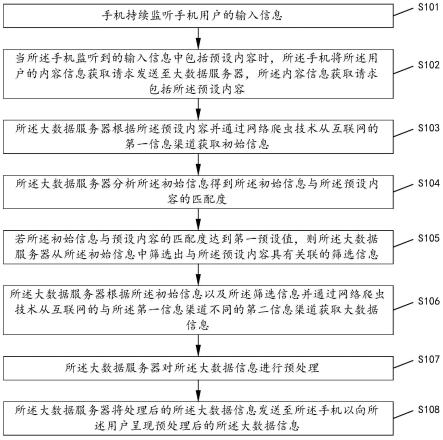
45.图4为本发明的第四实施例的方法流程示意图。
46.图5为本发明的第五实施例的方法流程示意图。
47.如下具体实施方式将结合上述附图进一步说明本发明。
具体实施方式
48.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得所有其他实施例,都属于本发明的保护范围。可以理解的是,附图仅仅提供参考与说明用,并非用来对本发明加以限制。
49.如图1所示,图1为本发明的第一实施例的方法流程图。本发明第一实施例提供的一种互联网大数据的信息推荐方法,所述方法包括以下步骤。
50.s101:手机持续监听手机用户的输入信息。
51.所述手机可以通过监听用户输入的声音信息或者用户触摸输入的文字信息。用户可以授权手机以让手机能够监听其输入信息。
52.s102:当所述手机监听到的输入信息中包括预设内容时,所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容。
53.当手机监听到输入的信息中包括预设内容时,将触发大数据信息获取流程,此时手机将向大数据服务器发送获取内容信息获取请求,所述大数据服务器将接收到所述请求。
54.以一个简单的示例,当所述手机监听到输入信息中包括购买衣服时,所述手机向所述大数据服务发送内容信息获取请求。
55.s103:所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息。
56.s104:所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度。
57.s105:若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息。
58.s106:所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息。
59.s107:所述大数据服务器对所述大数据信息进行预处理。
60.s108:所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
61.所述第一信息渠道和所述第二信息渠道为不同的渠道,所述第一信息渠道为感兴趣的专业渠道,所述第二信息渠道为目标渠道。
62.以上述简单的示例,大数据服务器会构造“购买衣服”在第一信息渠道的访问链接,通过网络爬虫技术,从第一信息渠道获取初始信息。所述第一信息渠道示例地如衣服论坛,所述初始信息简单示例,可以为“去天猫购买很好看的衣服”,“去学衣服穿搭”,“去旅游前购买衣服攻略”。
63.所述大数据将分析所述初始信息得到所述初始信息与所述预设内容的匹配度,筛选出匹配度达到第一预设值的所述初始信息。
64.以上简单示例,“去天猫购买很好看的衣服”以及“去旅游前购买衣服攻略”与所述预设内容匹配度高于第一预设值,而“去小红书学衣服穿搭”与所述预设内容匹配度低于第一预设值,则以“去天猫购买很好看的衣服”以及“去旅游前购买衣服攻略”作为有用的初始信息,而“去学衣服穿搭”则视为无用的初始信息。
65.所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息,以上示例性的,可以从有用的初始信息中筛选出“天猫”以及“旅游”。
66.所述大数据服务器则可以根据所述初始信息以及所述筛选信息构造在第二信息渠道的访问链接。示例性的,第二信息渠道是与衣服论坛不同的小红书网页,为目标渠道,通过网络爬虫技术从小红书网页获取大数据信息。如此,将获得具有与所述预设内容更大的相关性的大数据信息。
67.通过所述大数据服务器对所述大数据信息进行预处理,预处理方式可以按照预设方式进行,然后向手机发送,以向所述用户呈现预处理后的所述大数据信息。示例性的,所述预处理方式可以为统计处理,经过统计处理后,用户可以了解有关“购买衣服”在小红书
网页上的信息分布情况。以上仅仅是示例性的,当所述预设内容的设定方式可以更为复杂。
68.本实施例所提供的互联网大数据的信息推荐方法,从一个现实的感兴趣的信息渠道自动获得与所述预设内容具有关联的筛选信息,这些筛选信息已存在于第一信息渠道当中,这些筛选信息不是通过ai自动拓展所得,获得到的筛选信息更符合互联网实际,以此在第二信息渠道构造访问链接时,以更符合互联网实际的方式从第二信息渠道获取大数据信息。特别是,从第一信息渠道可以获得当前新兴的数据信息,以当前新兴的数据信息在第二信息渠道构造访问链接时,得到的大数据更超前,使得大数据信息与预设内容更符合实际、关联性更大。
69.如图2所示,图2为本发明的第二实施例的方法流程图。本发明第二实施例提供的一种互联网大数据的信息推荐方法,所述方法包括以下步骤。
70.s201:手机持续监听手机用户的输入信息。
71.s202:当所述手机监听到的输入信息中包括预设内容时,所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容。
72.s203:所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息。
73.s204:所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度。
74.s205:若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息。
75.s206:所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息。
76.s207:判断获取的所述大数据信息的条目数是否达到设定值,若所述大数据信息的条目数未达到设定值,则执行步骤s208。
77.s208:获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息;其中,其他用户的信息获取请求包括所述预设内容。
78.s209:将基于其他用户的请求所获取的大数据信息并入到本次获取的大数据信息中。
79.合并处理时,可以将重复的数据信息剔除,保留不同的数据信息。
80.s210:所述大数据服务器对合并后的所述大数据信息进行预处理。
81.s211:所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
82.在一些特定的情况下,从第二信息渠道所获取的大数据信息的条目数可能较少,无法有效地进行数据分析和统计,另外,当前通过大数据服务器获取大数据时,一些之前的有效链接可能已被删除,当前无法获取该链接的数据信息,这些有用数据会被丢失,数据丢失会导致数据不全或有遗漏。
83.此时,可以获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息。
84.其他用户在之前的某个时间点向大数据服务器发送信息获取请求后,所述大数据服务器将按照第一实施例的方式获取大数据信息,这些大数据信息将存储在大数据服务器
中,当前用户可以获取到已被删除的数据信息,实现数据的更有效、更全面的分析和统计。
85.如图3所示,图3为本发明的第三实施例的方法流程图。本发明第三实施例提供的一种互联网大数据的信息推荐方法,所述方法包括以下步骤。
86.s301:手机持续监听手机用户的输入信息。
87.s302:当所述手机监听到的输入信息中包括预设内容时,所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容。
88.s303:所述大数据服务器分析所述用户针对所述预设内容的偏好。
89.s304:根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类。
90.s305:所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息。
91.s306:所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度。
92.s307:若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息。
93.s308:所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息。
94.s309:判断获取的所述大数据信息的条目数是否达到设定值,若所述大数据信息的条目数未达到设定值,则执行步骤s310。
95.s310:获取具有相同偏好的其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息;其中,其他用户的信息获取请求包括所述预设内容。
96.s311:将基于其他用户的请求所获取的大数据信息并入到本次获取的大数据信息中。
97.s312:所述大数据服务器对合并后的所述大数据信息进行预处理。
98.s313:所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
99.相较于第二实施例而言,本实施例对所述用户的偏好进行分析,具有相同偏好的用户归为同类,如此,当通过第二信息渠道获得的大数据条目数未达到设定值时,大数据服务器将从数据库中调取具有相同偏好的其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息,同类用户偏好相同,获得大数据信息倾向性更为一致,最终相关性更高,可以减少垃圾数据。
100.在一具体实施方式中,所述大数据服务器分析所述用户针对所述预设内容的偏好,根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类,包括:
101.根据所述输入信息识别出输入信息所包括的预设内容的结构句中所包括的肯定/否定词和句尾词。
102.根据所述肯定/否定词和所述句尾词识别所述输入信息中针对所述预设内容属于肯定还是属于否定。
103.将针对所述预设内容属于肯定的用户归为同类,将针对所述预设内容属于否定的用户归为不同类。
104.本实施方式以针对所述预设内容属于肯定还是属于否定来确定用户是否属于同类。
105.在另一具体实施方式中,所述大数据服务器分析所述用户针对所述预设内容的偏好,根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类,包括:
106.分析所述手机在过去第一预设时间段内监听到所述用户输入的所述预设内容的次数。
107.将过去第一预设时间段内监听到输入的所述预设内容的次数不小于第二预设值的用户归为同类,将过去第一预设时间段内监听到输入的所述预设内容的次数小于第二预设值的用户归为不同类。
108.如图4所示,图4为本发明的第四实施例的方法流程图。本发明第四实施例提供的一种互联网大数据的信息推荐方法,所述方法包括以下步骤。
109.s401:手机持续监听手机用户的输入信息。
110.s402:当所述手机监听到的输入信息中包括预设内容时,所述手机收集所述用户在过去第二预设时间段内与所述其他用户的沟通内容。
111.s403:判断所述沟通内容与所述预设内容是否具有关联性,若所述沟通内容与所述输入信息具有关联性,则执行步骤s403。
112.s404:将所述其他用户设定为关联用户。
113.s405:所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容以及关联信息。
114.s406:所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息。
115.s407:所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度。
116.s408:若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息。
117.s409:所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息。
118.s410:判断获取的所述大数据信息的条目数是否达到设定值,若所述大数据信息的条目数未达到设定值,则执行步骤s210。
119.s411:获取关联的其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息;其中,其他用户的信息获取请求包括所述预设内容。
120.s412:将基于其他用户的请求所获取的大数据信息并入到本次获取的大数据信息中。
121.s413:所述大数据服务器对合并后的所述大数据信息进行预处理。
122.s414:所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
123.本实施例中,通过判断所述沟通内容与所述预设内容是否具有关联性来确定其他用户是否为关联用户,如果所述沟通内容与所述预设内容具有关联性,则可以视为两个用户对所述预设内容具有相同的兴趣,通过获取其他用户通过爬虫技术所获得的大数据信息
更符合当前用户的实际需求,得到的数据关联性进一步加强。
124.如图5所示,图5为本发明的第五实施例的方法流程图。本发明第五实施例提供的一种互联网大数据的信息推荐方法,所述方法包括以下步骤。
125.s501:手机持续监听手机用户的输入信息。
126.s502:当所述手机监听到的输入信息中包括预设内容时,所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容。
127.s503:所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息。
128.s504:所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度。
129.s505:若所述初始信息与预设内容的匹配度达到第一预设值,则所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息。
130.s506:所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息。
131.在当前用户请求获取大数据信息之前,所述大数据服务器将对其他用户请求获取的所述大数据信息中除所述预设内容外的其他字段进行统计分析,将带有相同字段的数据信息合并得到数据集合,每一个数据集合带有相应的字段标识。
132.以简单的示例,其他用户请求获取关于“购买衣服”的大数据信息,大数据服务器依据第一实施例的方式获取到大数据信息,大数据服务器剔除预设内容,对大数据信息进行统计分析,最终统计得出这些大数据信息中频率最高的字段为“天猫”,频率次之的为“旅游”等,将带有“天猫”字段的数据信息合并到一个数据集合,这个数据集合带有“天猫”字段标识,将带有“旅游”字段的数据信息合并到另一个数据集合,这个数据集合带有“旅游”字段标识。
133.s507:判断获取的所述大数据信息的条目数是否达到设定值,若所述大数据信息的条目数未达到设定值,则执行步骤s210。
134.s508:查询所述用户在过去第三预设时间段内与所述其他用户的沟通内容。
135.s509:确定所述沟通内容中所包括除所述预设内容之外的字段。
136.s510:获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息的数据集合,其中,所述数据集合为带有对应字段标识的集合,其他用户的信息获取请求包括所述预设内容。
137.s511:将所述数据集合并入到本次获取的大数据信息中。
138.s512:所述大数据服务器对合并后的所述大数据信息进行预处理。
139.s513:所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
140.本实施例对用户获取的大数据信息进行了统计分析,剔除预设内容后,将带有相同字段的数据信息合并得到数据集合,每一个数据集合带有相应的字段标识。
141.当当前用户基于所述预设内容请求所获得的大数据信息的条目数未达到设定值时,查询所述用户在过去第三预设时间段内与所述其他用户的沟通内容,并确定所述沟通内容中所包括除所述预设内容之外的字段,然后获取其他用户曾经向所述大数据服务器发
送信息获取请求后通过网络爬虫技术所获取的大数据信息的数据集合,以此方式获得的大数据信息将更为精准,更符合当前用户的需求。
142.本发明还提供一种互联网大数据的信息推荐ai系统,所述系统包括手机以及大数据服务器,所述系统能够实现如以上任一实施例中所述的互联网大数据的信息推荐方法。
143.本发明还提供一种互联网大数据的信息推荐装置,所述装置包括:
144.监听模块,用于手机持续监听手机用户的输入信息。
145.请求模块,用于当所述手机监听到的输入信息中包括预设内容时,所述手机将所述用户的内容信息获取请求发送至大数据服务器,所述内容信息获取请求包括所述预设内容。
146.第一获取模块,用于所述大数据服务器根据所述预设内容并通过网络爬虫技术从互联网的第一信息渠道获取初始信息。
147.匹配模块,用于所述大数据服务器分析所述初始信息得到所述初始信息与所述预设内容的匹配度。
148.筛选模块,用于当所述初始信息与预设内容的匹配度达到第一预设值时,所述大数据服务器从所述初始信息中筛选出与所述预设内容具有关联的筛选信息。
149.第二获取模块,用于所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息。
150.预处理模块,用于所述大数据服务器对所述大数据信息进行预处理。
151.发送模块,用于所述大数据服务器将处理后的所述大数据信息发送至所述手机以向所述用户呈现预处理后的所述大数据信息。
152.进一步的,所述装置还包括:
153.判断模块,用于在所述大数据服务器根据所述初始信息以及所述筛选信息并通过网络爬虫技术从互联网的与所述第一信息渠道不同的第二信息渠道获取大数据信息之后,判断获取的所述大数据信息的条目数是否达到设定值。
154.第三获取模块,用于当所述大数据信息的条目数未达到设定值时,获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息;其中,其他用户的信息获取请求包括所述预设内容。
155.合并模块,将基于其他用户的请求所获取的大数据信息并入到本次获取的大数据信息中以便于所述大数据服务器对合并后的大数据信息进行预处理。
156.进一步的,所述装置还包括:
157.分析模块,用于所述大数据服务器分析所述用户针对所述预设内容的偏好。
158.归类模块,用于根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类。
159.所述获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息,包括:
160.获取具有相同偏好的其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息。
161.进一步的,所述大数据服务器分析所述用户针对所述预设内容的偏好,根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类,包括:
162.根据所述输入信息识别出输入信息所包括的预设内容的结构句中所包括的肯定/否定词和句尾词;
163.根据所述肯定/否定词和所述句尾词识别所述输入信息中针对所述预设内容属于肯定还是属于否定;
164.将针对所述预设内容属于肯定的用户归为同类;
165.将针对所述预设内容属于否定的用户归为不同类。
166.进一步的,所述大数据服务器分析所述用户针对所述预设内容的偏好,根据所述偏好将所述用户进行归类处理,相同偏好的用户归为同类,包括:
167.分析所述手机在过去第一预设时间段内监听到所述用户输入的所述预设内容的次数;
168.将过去第一预设时间段内监听到输入的所述预设内容的次数不小于第二预设值的用户归为同类;
169.将过去第一预设时间段内监听到输入的所述预设内容的次数小于第二预设值的用户归为不同类。
170.进一步的,所述装置还包括:
171.收集模块,用于所述手机收集所述用户在过去第二预设时间段内与所述其他用户的沟通内容,判断所述沟通内容与所述预设内容是否具有关联性;
172.关联模块,用于当所述沟通内容与所述输入信息具有关联性时,将所述其他用户设定为关联用户,以便于当所述大数据信息的条目数未达到设定值时,获取所述其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息。
173.进一步的,所述大数据服务器对所述大数据信息中除所述预设内容外的其他字段进行统计分析,将带有相同字段的数据信息合并得到数据集合,每一个数据集合带有相应的字段标识;
174.所述若所述大数据信息的条目数未达到设定值,则获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息,包括:
175.若所述大数据信息的条目数未达到设定值,则查询所述用户在过去第三预设时间段内与所述其他用户的沟通内容;
176.确定所述沟通内容中所包括除所述预设内容之外的字段;
177.获取其他用户曾经向所述大数据服务器发送信息获取请求后通过网络爬虫技术所获取的大数据信息的数据集合,所述数据集合为带有对应字段标识的集合。
178.本技术的说明书和权利要求书中,词语“包括/包含”和词语“具有/包括”及其变形,用于指定所陈述的特征、数值、步骤或部件的存在,但不排除存在或添加一个或多个其他特征、数值、步骤、部件或它们的组合。
179.本发明的一些特征,为阐述清晰,分别在不同的实施例中描述,然而,这些特征也可以结合于单一实施例中描述。相反,本发明的一些特征,为简要起见,仅在单一实施例中描述,然而,这些特征也可以单独或以任何合适的组合于不同的实施例中描述。
180.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包括在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1